kafka工作流程| 命令行操作
1. 概述
数据层:结构化数据+非结构化数据+日志信息(大部分为结构化)
传输层:flume(采集日志--->存储性框架(如HDFS、kafka、Hive、Hbase))+sqoop(关系型数据性数据库里数据--->hadoop)+kafka(将实时日志在线--->sparkstream在数据进行实时处理分析)
存储层:HDFS+Hbase(非关系型数据库)+kafka(节点上默认存储1G数据)
资源调度层:Yarn
计算层:MapReduce+ Hive(计算+存储型框架:sql-->mapreduce)+ spark +Fink + stom
图表展现层:
消息队列原理
同步通信|
异步通信:
消费者只有一个即点对点(消费者主动拉取数据,消息收到后消息清除)
点对点模型通常是一个基于拉取或者轮询(轮询调度算法:每一次把来自用户的请求轮流分配给内部中的服务器,从1开始,直到N然后重新开始循环。轮(循环)着询问(访问)数据!)的消息传送模型,这种模型从队列中请求信息,而不是将消息推送到客户端。这个模型的特点是发送到队列的消息被一个且只有一个接收者接收处理,即使有多个消息监听者也是如此。
消费者有多个即发布/订阅模式(一对多)
发布订阅模型则是另一个消息传送模型。发布订阅模型可以有多种不同的订阅者,临时订阅者只在主动监听主题时才接收消息,而持久订阅者则监听主题的所有消息,即使当前订阅者不可用,处于离线状态。
kafka--->>分布式消息队列,把两种模式结合起来(点对点+ 发布)
消费者组中只有一个消费者--一对一;
多个消费者组中有多个消费者去消费同一个主题的数据,即发布/订阅模式;
拉模式:保证数据不至于丢失
消息队列好处:
发接消息解耦了;冗余(备份);扩展性;灵活性、峰值处理;可恢复性;有顺序的;缓冲

什么是Kafka
在流式计算中,Kafka一般用来缓存数据,Spark通过消费Kafka的数据进行计算。
Apache Kafka是一个开源消息系统,由Scala写成。为处理实时数据提供一个统一、高通量、低等待的平台;
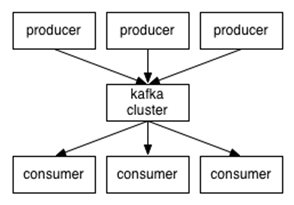
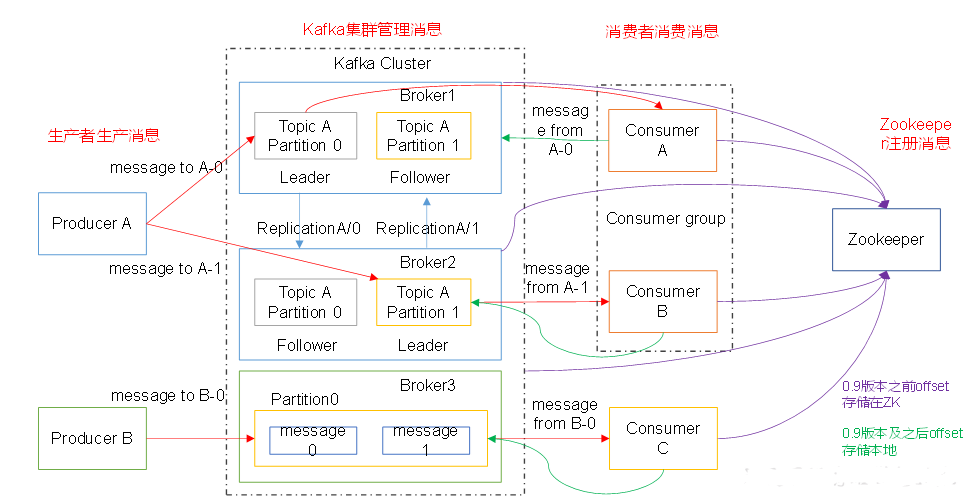
Kafka是一个分布式消息队列。Kafka对消息保存是根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)称为broker。
无论是kafka集群,还是consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性。
2. 架构
客户端:producer、cluster、consumer

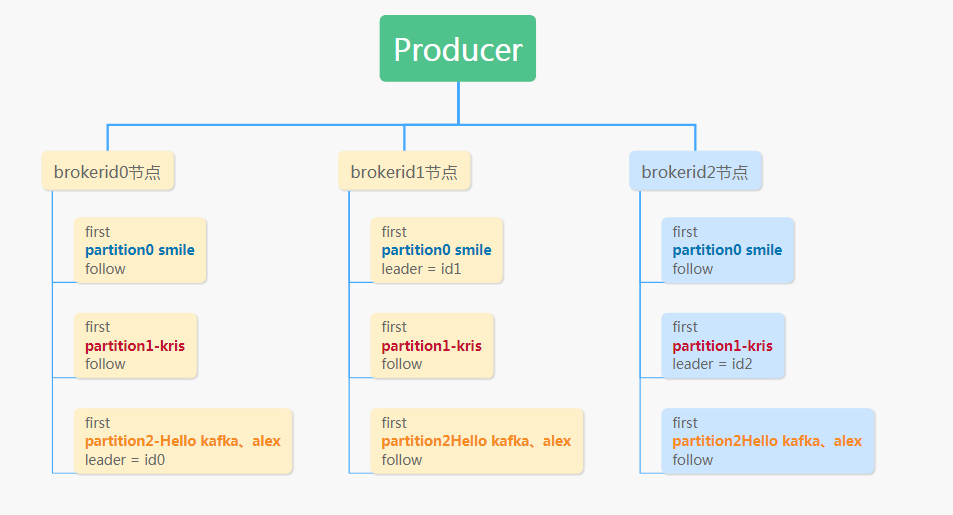
producer:-->TopicA在某个节点上,节点存储空间有限,主题中消息不能无限存储
可指定分区:消息的分布式存储,一个主题分成多个分区;一个分区即一个消息队列;分区中的消息要备份ReplicationA/0;一个分区中可能备份有多个,选出一个leader;
数据的一致性,其他节点去同步消息时速度可能不一样
Leader和Follower都是针对分区中的多个副本,分区下面有多个副本,在副本中选一个leader
leader接收发送数据,读写数据;follower只负责数据的备份
zk中的leader和follower是针对节点的
分区中的消息都是有序的,每一个消息要进行编号,即偏移量(从0开始编),如消费者读取到1号message,把1保存zk;下次读取时从1开始,防止数据被重复被消费;
有些消费者消费能力有限----引入--->消费者组(多个消费者)多个消费者去消费某一个主题
每一个消费者是消费主题下面的分区,而不能消费同一个分区的数据,相当于同时消费了;
分区数=消费者数,速度是最快的,才能保证资源的最大化利用;
分区:①实现对消息的分布式存储;②实现消费者消费消息时的并发且互不干扰,提高消费者消费的效率;
消费者只能去找leader(读写)去消费,follower只是作为存储备份数据;
zk-->①主题、节点分区信息都会存储在zk;②消费者消费消息的offset也会存在zk,但0.9版本之后偏移量offset存在本地;
Topic主题是对消息的分类;Topic主题中的容量>节点broker1容量时,会进行分区;
误区:并不是0分区满了就去存储到1分区,1分区满了就去存储到2分区;往分区里边生成数据是有规则的,见下;
数据的备份数<=节点数
创建主题是要创建分区,每个分区的leader要分到不同节点实现负载均衡;
消费者去进行消费时是一个一个分区来的;有先后顺序;而在消费者组中的消费者是并发去消费各个分区中的数据
3. 安装kafka集群
tar -zxvf kafka_2.11-0.11.0.0.tgz -C /opt/module/
[kris@hadoop101 module]$ mv kafka_2.11-0.11.0.0/ kafka
在/opt/module/kafka目录下创建logs文件夹
[kris@hadoop101 kafka]$ mkdir logs
[kris@hadoop101 kafka]$ cd config/
[kris@hadoop101 config]$ vim server.properties #修改配置文件
#broker的全局唯一编号,不能重复
broker.id=0
#删除topic功能使能
delete.topic.enable=true
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘IO的现成数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka运行日志存放的路径
log.dirs=/opt/module/kafka/logs
#topic在当前broker上的分区个数;
num.partitions=1
#用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
#segment文件保留的最长时间,超时将被删除
log.retention.hours=168
#配置连接Zookeeper集群地址
zookeeper.connect=hadoop101:2181,hadoop102:2181,hadoop103:2181
在创建主题时,要指定分区数,而在配置文件中已经配置了;如果主题不存在,它会自动创建主题,这时用的分区数即配置文件里边的分区数;
分发安装包
[kris@hadoop101 module]$ xsync kafka/
分别在hadoop102和hadoop103上修改配置文件/opt/module/kafka/config/server.properties中的broker.id=1、broker.id=2
注:broker.id不得重复
启动集群/ 要先启动zookeeper
依次在hadoop101、hadoop102、hadoop103节点上启动kafka
[kris@hadoop101 kafka]$ bin/kafka-server-start.sh config/server.properties & ##后台启动加&
[kris@hadoop102 kafka]$ bin/kafka-server-start.sh config/server.properties &
[kris@hadoop103 kafka]$ bin/kafka-server-start.sh config/server.properties &
关闭集群
[kris@hadoop101 kafka]$ bin/kafka-server-stop.sh stop
[kris@hadoop102 kafka]$ bin/kafka-server-stop.sh stop
[kris@hadoop103 kafka]$ bin/kafka-server-stop.sh stop
jps -l会显示进程的详细信息
[kris@hadoop101 ~]$ jps -l
3444 org.apache.zookeeper.server.quorum.QuorumPeerMain
3524 kafka.Kafka
3961 sun.tools.jps.Jps
4. Kafka命令行操作
zookeeper有三个端口:
2181:对cline端提供服务
3888:选举leader使用
2888:集群内机器通讯使用(Leader监听此端口)
zookeeper中的节点:
cluster(集群的版本,id)
brokers(ids节点信息如在哪个机器上,创建的topics主题/其中__consumer_offsets存储本地的offsets,每个主题下面有/partitions/各个分区的信息如它的leader、version、isr等信息
consumers(消费者组id/ids--subscription:订阅的主题:在哪个节点、version、pattern、timestamp/ owners--哪个主题,哪个分区/ offsets--哪个主题哪个分区--记录偏移量)
① 创建Topic主题
###创建Topics,指定名字,分区数,副本数
[kris@hadoop101 bin]$ ./kafka-topics.sh --zookeeper hadoop101:2181, hadoop102:2181, hadoop103:2181 --create --topic first --partitions 3 --replication-factor 3
Created topic "first". #创建主题
[kris@hadoop101 bin]$ ./kafka-topics.sh --zookeeper hadoop101:2181 --list ##查看有多少个主题
first
[zk: localhost:2181(CONNECTED) 1] ls /cluster ##cluster是有关集群版本version、id
[id]
[zk: localhost:2181(CONNECTED) 2] ls /cluster/id
[]
[zk: localhost:2181(CONNECTED) 3] get /cluster/id
{"version":"1","id":"ujFrs7F7SVuO2JwXw62vow"}
cZxid = 0x700000014
ctime = Wed Feb 27 11:51:23 CST 2019
mZxid = 0x700000014
mtime = Wed Feb 27 11:51:23 CST 2019
pZxid = 0x700000014
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 45
numChildren = 0
[zk: localhost:2181(CONNECTED) 4] ls /brokers #集群中节点信息存储在brokers
[ids, topics, seqid] ##集群中节点的ids;[0, 1, 2] 如节点1的机器名字、timestamp、port、version
[zk: localhost:2181(CONNECTED) 5] ls /brokers/topics
[first]
[zk: localhost:2181(CONNECTED) 15] ls /brokers/topics ##集群主题topics
[first, __consumer_offsets, second]
[zk: localhost:2181(CONNECTED) 6] ls /brokers/topics/first
[partitions]
[zk: localhost:2181(CONNECTED) 7] ls /brokers/topics/first/partitions
[0, 1, 2]
[zk: localhost:2181(CONNECTED) 8] ls /brokers/topics/first/partitions/0
[state]
[zk: localhost:2181(CONNECTED) 9] ls /prokers/topics/first/partitions/0/state ##
[ ]
[zk: localhost:2181(CONNECTED) 22] get /brokers/topics/first/partitions/0/state
{"controller_epoch":10,"leader":0,"version":1,"leader_epoch":8,"isr":[0,2,1]}
② 生产者生成| 消费者消费
控制台生产者执行脚本; --broker-list指定节点地址
[kris@hadoop101 bin]$ ./kafka-console-producer.sh --broker-list hadoop101:9092 --topic first
>Hello kafka!
>kris
>smile
① 控制台消费者 :默认从最大的offset消费开始消费,下次就是后边的数据,前边接收不到;再生产数据才能收到
[kris@hadoop101 bin]$ ./kafka-console-consumer.sh --zookeeper hadoop101:2181 --topic first
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].
alex
② 控制台消费者 --from-beginning 从头消费
[kris@hadoop101 bin]$ ./kafka-console-consumer.sh --zookeeper hadoop101:2181 --topic first --from-beginning
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].
smile
kris
Hello kafka!
alex
a消费者是对3个分区一个个分区消费的,所以总的顺序不一样
第一个消费者:从最大的offset开始消费
[zk: localhost:2181(CONNECTED) 12] ls /consumers 要保证消费者是在线的,因为偏移量是临时的,消费者一退出就看不到偏移量了;
[console-consumer-27938, console-consumer-90053] 控制台消费者id;ids、owners属于哪个主题哪个分区、
[zk: localhost:2181(CONNECTED) 13] ls /consumers/console-consumer-27938
[ids, owners, offsets]
[zk: localhost:2181(CONNECTED) 14] ls /consumers/console-consumer-27938/offsets
[first]
[zk: localhost:2181(CONNECTED) 15] ls /consumers/console-consumer-27938/offsets/first
[0, 1, 2]
[zk: localhost:2181(CONNECTED) 16] ls /consumers/console-consumer-27938/offsets/first/0
[]
[zk: localhost:2181(CONNECTED) 17] get /consumers/console-consumer-27938/offsets/first/0
1
cZxid = 0x80000003f
ctime = Wed Feb 27 18:26:11 CST 2019
mZxid = 0x80000003f
mtime = Wed Feb 27 18:26:11 CST 2019
pZxid = 0x80000003f
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 1
numChildren = 0
[zk: localhost:2181(CONNECTED) 18] get /consumers/console-consumer-27938/offsets/first/1
1
[zk: localhost:2181(CONNECTED) 19] get /consumers/console-consumer-27938/offsets/first/2
2
第二个消费者的情况:从头开始消费
[zk: localhost:2181(CONNECTED) 26] get /consumers/console-consumer-90053/offsets/first/0
1
[zk: localhost:2181(CONNECTED) 27] get /consumers/console-consumer-90053/offsets/first/1
1
[zk: localhost:2181(CONNECTED) 28] get /consumers/console-consumer-90053/offsets/first/2
2
如果是把offset存储在本地,加--bootstarp-server,就不会在zookeeper上的 /consumers上创建消费者组了;
③ 控制台消费者 偏移量存储在本地的消费者,不存储在zookeeper上就加--bootstrap-server; 存储在__consumer_offsets主题下面
[kris@hadoop101 bin]$ ./kafka-console-consumer.sh --bootstrap-server hadoop101:9092 --topic first --from-beginning
Hello kafka!
alex
kris
smile
--bootstrap-server是不再把偏移量存储在zookeeper上,而是存储在本地;数据还是存储在分区的first-0/first-1/first-2
drwxrwxr-x. 2 kris kris 4096 2月 27 19:02 __consumer_offsets-0
drwxrwxr-x. 2 kris kris 4096 2月 27 19:02 __consumer_offsets-12
drwxrwxr-x. 2 kris kris 4096 2月 27 19:02 __consumer_offsets-15
drwxrwxr-x. 2 kris kris 4096 2月 27 19:02 __consumer_offsets-18
drwxrwxr-x. 2 kris kris 4096 2月 27 19:02 __consumer_offsets-21
drwxrwxr-x. 2 kris kris 4096 2月 27 19:02 __consumer_offsets-24
drwxrwxr-x. 2 kris kris 4096 2月 27 19:02 __consumer_offsets-27
drwxrwxr-x. 2 kris kris 4096 2月 27 19:02 __consumer_offsets-3
drwxrwxr-x. 2 kris kris 4096 2月 27 19:02 __consumer_offsets-30
drwxrwxr-x. 2 kris kris 4096 2月 27 19:02 __consumer_offsets-33
drwxrwxr-x. 2 kris kris 4096 2月 27 19:02 __consumer_offsets-36
drwxrwxr-x. 2 kris kris 4096 2月 27 19:02 __consumer_offsets-39
drwxrwxr-x. 2 kris kris 4096 2月 27 19:02 __consumer_offsets-42
drwxrwxr-x. 2 kris kris 4096 2月 27 19:02 __consumer_offsets-45
drwxrwxr-x. 2 kris kris 4096 2月 27 19:02 __consumer_offsets-48
drwxrwxr-x. 2 kris kris 4096 2月 27 19:02 __consumer_offsets-6
drwxrwxr-x. 2 kris kris 4096 2月 27 19:02 __consumer_offsets-9
[kris@hadoop101 __consumer_offsets-0]$ ll
总用量 0
-rw-rw-r--. 1 kris kris 10485760 2月 27 19:02 00000000000000000000.index
-rw-rw-r--. 1 kris kris 0 2月 27 19:02 00000000000000000000.log
-rw-rw-r--. 1 kris kris 10485756 2月 27 19:02 00000000000000000000.timeindex
-rw-rw-r--. 1 kris kris 0 2月 27 19:02 leader-epoch-checkpoint
[kris@hadoop101 kafka]$ bin/kafka-topics.sh --zookeeper hadoop101:2181 --list
__consumer_offsets
first
[zk: localhost:2181(CONNECTED) 41] ls /brokers/topics
[first, __consumer_offsets]
[zk: localhost:2181(CONNECTED) 47] ls /brokers/topics/__consumer_offsets/partitions
[44, 45, 46, 47, 48, 49, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43]
[zk: localhost:2181(CONNECTED) 48] ls /brokers/topics/__consumer_offsets/partitions/0
[state]
[zk: localhost:2181(CONNECTED) 49] ls /brokers/topics/__consumer_offsets/partitions/0/state
[]
[zk: localhost:2181(CONNECTED) 50] get /brokers/topics/__consumer_offsets/partitions/0/state
{"controller_epoch":2,"leader":0,"version":1,"leader_epoch":0,"isr":[0]}
cZxid = 0x80000008c
ctime = Wed Feb 27 19:02:06 CST 2019
mZxid = 0x80000008c
mtime = Wed Feb 27 19:02:06 CST 2019
pZxid = 0x80000008c
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 72
numChildren = 0
生产者生产的数据是存储在logs里边的,命名是:主题名-分区号 ,不管是把offset存储在zookeeper还是存储在本地,它的数据都是存储在logs里边的主题名-分区号里边;
会有一个index,便于下次的查找;
主题topic是逻辑上的概念,分区是物理上的概念;
[kris@hadoop101 kafka]$ cd logs/
[kris@hadoop101 logs]$ ll
drwxrwxr-x. 2 kris kris 4096 2月 27 18:21 first-0
drwxrwxr-x. 2 kris kris 4096 2月 27 18:21 first-1
drwxrwxr-x. 2 kris kris 4096 2月 27 18:21 first-2
[kris@hadoop101 logs]$ cd first-0
[kris@hadoop101 first-0]$ ll
总用量 8
-rw-rw-r--. 1 kris kris 10485760 2月 27 18:07 00000000000000000000.index
-rw-rw-r--. 1 kris kris 73 2月 27 18:21 00000000000000000000.log
-rw-rw-r--. 1 kris kris 10485756 2月 27 18:07 00000000000000000000.timeindex
-rw-rw-r--. 1 kris kris 8 2月 27 18:21 leader-epoch-checkpoint
数据序列化到磁盘而不是内存first-0,索引
[kris@hadoop101 kafka]$ bin/kafka-topics.sh --zookeeper hadoop101:2181 --describe --topic first
Topic:first PartitionCount:3 ReplicationFactor:3 Configs:
Topic: first Partition: 0 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2 ##Isr是同步副本队列
Topic: first Partition: 1 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
Topic: first Partition: 2 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
测试Kafka集群一共3个节点,
Topic为first, 编号为0的Partition, Leader在broker.id=0这个节点上,副本在broker.id为0 1 2这3个节点,并且所有副本都存活,并跟broker.id=0这个节点同步
leader是在给出的所有partitons中负责读写的节点,每个节点都有可能成为leader
replicas 显示给定partiton所有副本所存储节点的节点列表,不管该节点是否是leader或者是否存活。
isr 副本都已同步的的节点集合,这个集合中的所有节点都是存活状态,并且跟leader同步;如果没有同步数据,则会从这个Isr中移除;
写入的顺序:
>Hello kafka!
>kris
>smile
>alex
节点0-broker.id=0, smile在分区first-0 1
节点1-broker.id=1, kris在分区first-1 1
节点2-broker.id=2, Hello kafka!和alex在分区first-2 2(在zk中get /consumers/console-consumer-90053/offsets/first/2)
同一个partition可能会有多个replication,而这时需要在这些replication之间选出一个leader,
producer和consumer只与这个leader交互,其它replication作为follower从leader 中复制数据。
5. 工作流程
见上架构流程
1)数据生产
写入方式
producer采用推(push)模式将消息发布到broker,每条消息都被追加(append)到分区(patition)中,属于顺序写磁盘(顺序写磁盘效率比随机写内存要高,保障kafka吞吐率)。
flume和kafka(它的消费者)都是进行拉数据;
不同消费者组中消费者可消费同一个分区数据;
消费者组只有一个消费者它消费数据是一个个分区依次进行消费的;而如果一个消费者组中有多个消费者,它们是并行的;
2)分区(Partition)
消息发送时都被发送到一个topic,其本质就是一个目录,而topic是由一些Partition Logs(分区日志)组成
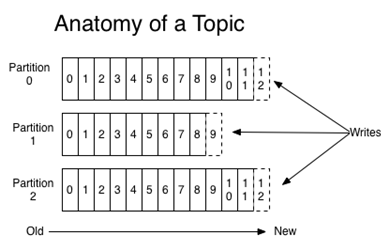
我们可以看到,每个Partition中的消息(以k,v的形式)都是有序的,生产的消息被不断追加到Partition log上,其中的每一个消息都被赋予了一个唯一的offset值。
1)分区的原因
(1)方便在集群中扩展,每个Partition可以通过调整以适应它所在的机器,而一个topic又可以有多个Partition组成,因此整个集群就可以适应任意大小的数据了;
(2)可以提高并发,因为可以以Partition为单位读写了。
2)分区的原则
(1)指定了patition,则直接使用;
(2)未指定patition但指定key,通过对key的value进行hash出一个patition; 对key的hashcode % 分区数,取余得到对应的分区;
(3)patition和key都未指定,使用轮询选出一个patition。
3) 副本(Replication)
同一个partition可能会有多个replication(对应server.properties 配置中的 default.replication.factor=N)。没有replication的情况下,一旦broker宕机,其上所有patition 的数据都不可被消费,同时producer也不能再将数据存于其上的patition。引入replication之后,同一个partition可能会有多个replication,而这时需要在这些replication之间选出一个leader,producer和consumer只与这个leader交互,其它replication作为follower从leader 中复制数据。
4) producer写入消息流程
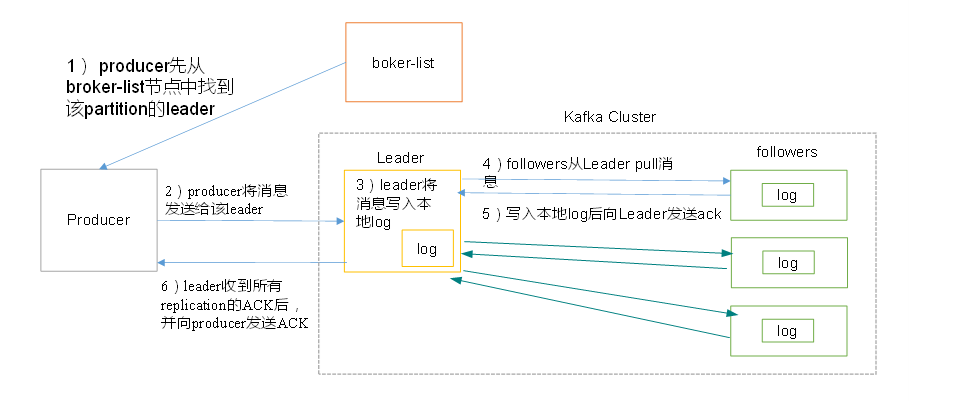
1)producer先从broker-list节点中找到该partition的leader;
2)producer将消息发送给该leader;
3)leader将消息写入本地log;
4)followers从leader pull消息,写入本地log后向leader发送ACK;
5)leader收到所有的replication的ACK后,向producer发送ACK。
kafka的ack机制(request.requred.acks):
0:producer不等待broker的ack,broker一接收到还没有写入磁盘就已经返回,当broker故障时有可能丢失数据;producer不等待节点返回的ack,它只管发
1:producer等待broker的ack,partition的leader落盘成功后返回ack,如果在follower同步成功之前leader故障,那么将会丢失数据;ack=1,leader落盘就返回ack给producer;
-1:producer等待broker的ack,partition的leader和follower全部落盘成功后才返回ack,数据一般不会丢失,延迟时间长但是可靠性高。leader收到所有的follow(都同步完数据)的ack后才向producer发送ack
数据持久化到磁盘而不是内存;kafka从本地读取磁盘数据比从内存还快,kafka做了优化
消息的保存以k,v对的形式
读取本地保存的offset
1)修改配置文件consumer.properties
exclude.internal.topics=false
2)读取offset
bin/kafka-console-consumer.sh --topic __consumer_offsets --zookeeper hadoop101:2181 --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --consumer.config config/consumer.properties --from-beginning
第二次执行时把--from-beging去掉;
偏移量以k,v对形式:
k(控制台消费者组id| 主题名| 分区),k(偏移量,提交时间,过期时间)
[console-consumer-81371,first,1]::[OffsetMetadata[1,NO_METADATA],CommitTime 1551272323753,ExpirationTime 1551358723753]
[console-consumer-81371,first,0]::[OffsetMetadata[1,NO_METADATA],CommitTime 1551272323753,ExpirationTime 1551358723753]
[console-consumer-81371,first,2]::[OffsetMetadata[2,NO_METADATA],CommitTime 1551272328754,ExpirationTime 1551358728754]
消费者组
[kris@hadoop101 config]$ vi consumer.properties group.id=kris 分发到其他机器: [kris@hadoop101 config]$ xsync consumer.properties ##启动一个生产者 [kris@hadoop101 kafka]$ bin/kafka-console-producer.sh --broker-list hadoop101:9092 --topic first 在hadoop102、hadoop103上分别启动消费者 [kris@hadoop103 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop101:9092 --topic first --consumer.config config/consumer.properties [kris@hadoop102 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop101:9092 --topic first --consumer.config config/consumer.properties 查看hadoop102和hadoop103的接收者。 同一时刻只有一个消费者接收到消息。
存储策略
无论消息是否被消费,kafka都会保留所有消息。有两种策略可以删除旧数据:
1)基于时间:log.retention.hours=168
2)基于大小:log.retention.bytes=1073741824
需要注意的是,因为Kafka读取特定消息的时间复杂度为O(1),即与文件大小无关,所以这里删除过期文件与提高 Kafka 性能无关。
kafka的balance是怎么做的?
整体的负载均衡;leader在3个节点平均分布
Kafka的数据是分区存储的。以集群形式运行的Kafka,这些分区是分布在不同的Kafka服务器中。当消费者消费的数据分布在不同的分区时,会访问不同的服务器,这样就完成了负载均衡。所以,Kafka的负载均衡是通过分区机制实现的。
Kafka的偏移量Offset存放在哪儿,为什么?
offset从zookeeper迁移到本地 , ZKClient的API写是很低效的
Kafka0.9版本以前,offset默认保存在Zookeeper中。从kafka-0.9版本及以后,kafka的消费者组和offset信息就不存zookeeper了,而是存到broker服务器上。
这个变动的原因在于:之前版本,Kafka其实存在一个比较大的隐患,就是利用 Zookeeper 来存储记录每个消费者/组的消费进度。虽然,在使用过程当中,JVM帮助我们完成了一些优化,但是消费者需要频繁的去与 Zookeeper 进行交互,而利用ZKClient的API操作Zookeeper频繁的Write其本身就是一个比较低效的Action,对于后期水平扩展也是一个比较头疼的问题。如果期间 Zookeeper 集群发生变化,那 Kafka 集群的吞吐量也跟着受影响。
为什么kafka可以实现高吞吐?( 吞:写,土:读)单节点kafka的吞吐量也比其他消息队列大,为什么?
分区机制提供它的高吞吐; 分布式存储,消费者组并发消费 ;
分区中的数据是顺序读取;Disk-->Read Buffer-->Socket Buffer-->NIC Buffer;senfile做了优化省去了中间的Application Buffer
磁盘--内核区 -用户区--内核区
日志分段读取:存储在小文件中,还有索引;
顺序读写:kafka的消息是不断追加到文件中的,这个特性使kafka可以充分利用磁盘的顺序读写性能,顺序读写不需要硬盘磁头的寻道时间,只需很少的扇区旋转时间,所以速度远快于随机读写。
零拷贝:在Linux kernel2.2 之后出现了一种叫做"零拷贝(zero-copy)"系统调用机制,就是跳过“用户缓冲区”的拷贝,建立一个磁盘空间和内存的直接映射,数据不再复制到“用户态缓冲区”,系统上下文切换减少为2次,可以提升一倍的性能。
文件分段:kafka的队列topic被分为了多个区partition,每个partition又分为多个段segment,所以一个队列中的消息实际上是保存在N多个片段文件中,通过分段的方式,每次文件操作都是对一个小文件的操作,非常轻便,同时也增加了并行处理能力
Kafka消费过的数据如何再消费?
再消费:低级API修改offset
auto_offset_reset_config
找不到之前存储的offset就从earliest(从最早的offset而不是从0,有局限性)中读取
key(主题,partition,组id)
更改消费者组id--高级API;
修改offset:Kafka消息队列中消费过的数据是用offset标记的。通过修改offset到以前消费过的位置,可以实现数据的重复消费。
通过使用不同的group来消费:Kafka中,不同的消费者组的offset是独立的,因此可以通过不同的消费者组实现数据的重复消费。
需要将ConsumerConfig.AUTO_OFFSET_RESET_CONFIG属性修改为"earliest"
kafka数据有序性? 分区有序
放在一个分区,k v.消息message是k v k一般不写,k可保证分到哪个区
kafka发送消息采用的是Deququ双端队列,两头都可以存取,若消息发送失败就放回头部,保证了数据的有序性;
存放数据时放到一个分区中,消息message是以k, v键值对形式,k相同放一个分区

 浙公网安备 33010602011771号
浙公网安备 33010602011771号