MySQL8中长sql多join的优化
业务场景问题
insert into W
select A.BUSNO, A.ORGCODE, A.FACETIME,A.FACERESULT,
B.b1
C.EQUTYPE,
D.d1,
E.e1,
E.e2
K.g1,
K.g2,
K.g3
from A
left join B on A.BUSNO = B.busno
left join C on A.MachID = C.machid
left join D on A.LIVEBNO = D.LIVEBNO
left ioin (SELECT * FROM F) E ON A.BUSNO = E.NUM_SEO and trandate = #{time}
left join (select g1, g2, g3 from
(select g1, g2,
g3 NUMBER() OVER(PARTITION BY g4 ORDER BY NUM JRN DESC) as g3
from G where TRANDATE=#{time}
) a
where a.NUM IRN = 1
) K on A.BUSNO = K.NUM_SEO
其中A表数据量6万多条,B、C表也2万多条,D表几十条,E、K表将近20万条,目前在线上插入时间已经超过了1个小时,监控已经报警。
分析业务场景
以A表为主表,BCDEK表都是取出相关联的字段。
排查sql语句查询缓慢原因
- 使用explain关键字查看发现,扫描的row数比较多,E , K两表每日的数据量比较大。
- 其次join关键字采用笛卡尔积的方式,这样需要拿主表中的记录与join表挨个比对。
- K采用窗口函数排序,这样explain的extra信息显示file sort,可见其排序完也是根据一个字段去重排序,取出重复字段的最小值,却需要给20万条记录排序,浪费时间。
优化方案
优化1,索引优化
将join之间的一些表中关联的非主键字段添加索引。
create index busno_idx on B(busno);
优化2,SQL语句优化
1. join本质上还是使用临时表,那么缩小join的查询范围,去除不必要的扫描
left ioin (SELECT * FROM F) E ON A.BUSNO = E.NUM_SEO and trandate = #{time}
==> 优化为:
left ioin (SELECT * FROM F where trandate = #{time}) E ON A.BUSNO = E.NUM_SEO
2. 优化排序子查询,取消无用的file sort排序
本质上就是为了去重取出最小的字段而已。
left join (select g1, g2, g3 from
(select g1, g2,
g3 NUMBER() OVER(PARTITION BY g4 ORDER BY NUM JRN DESC) as g3
from G where TRANDATE=#{time}
) a
where a.NUM IRN = 1
) K on bus.BUSNO = K.NUM_SEO
==> 优化为:
select g1, g2, min(g3) from G where TRANDATE=#{time}
group by g1, g2
问题,但是在上面这些简单的优化之后,查询依然很慢,本质上还是join的表是大数据表。
优化3,SQL语句改造为java程序
将一次多join的sql语句,转化为多次查询的sql语句,然后在java代码中取交并集。
将E、K两张20万的大表放到java的HashMap中,其中key为join关联的键BUSNO,而value为需要获取字段的对象。这样我们可以减少两个大表join,然后将查询的结果遍历,使用Map映射,获取对应的值对象。
注意,针对当前的jvm的参数配置,我们要先进行压力测试,防止出现线上OOM的情况。
优化4,foreach循环多次分批插入
- 原因:数据库拼接sql语句长度的限制。
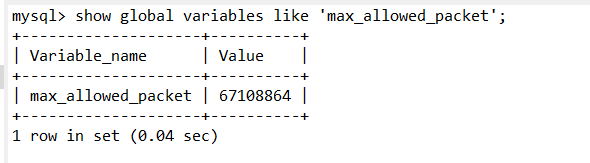
- 解决:
- dao层代码
使用foreach拼接sql语句
int insertForBatch(@Param("dataDTOList") List<DataDTO> dataDTOList);
<insert id="insertForBatch">
insert into W values
<foreach collection="dataDTOList" item="datDTO" separator=",">
(#{datDTO.busno}, #{datDTO.orgcode}, #{datDTO.facetime}, #{datDTO.faceresult},
#{datDTO.b1}, #{datDTO.equtype}, #{datDTO.d1}, #{datDTO.e1},
#{datDTO.e2}, #{datDTO.g1}, #{datDTO.g2}, #{datDTO.g3})
</foreach>
</insert>
- service层代码
将整体的List按照每段10000条记录切分成段,然后使用多线程批量插入
@Autowired
private ThreadPoolExecutor executor;
public void insertData(List<DataDTO> dataDTOList) {
// 总行数
int allNum = dataDTOList.size();
// 切分出来的份数
int partNum = allNum / 10000;
for (int i = 0 ; i < partNum ; i++) {
if (i == partNum - 1) {
List<DataDTO> dataDTOS = dataDTOList.subList(i * 10000, allNum);
insertTask(dataDTOS);
} else {
List<DataDTO> dataDTOS = dataDTOList.subList(i * 10000, (i + 1) * 10000);
insertTask(dataDTOS);
}
}
}
public void insertTask(List<DataDTO> dataDTOList) {
executor.execute(() -> {
menuMapper.insertForBatch(dataDTOList);
});
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号