

Python爬虫入门教程-2
1、Web请求全过程剖析... 1
2、浏览器工具的使用... 3
3、协议简单了解一下... 3
4、Requests模块入门... 4
5、获取豆瓣电影数据... 6
6、正则表达式... 7
7、实战1-爬取豆瓣top250电影... 9
8、实战2-爬取电影天堂热片... 11
9、HTML语法基础... 13
10、BS实战1-获取新发地菜价... 15
11、BS实战2-优化图库图片下载... 16
12、xpath解析... 18
13、xpath示例-猪八戒网址... 20
14、pyquery基础内容... 22
15、pyquery实战1-汽车之家购车信息... 24
16、requests进阶概述... 26
17、cookie-获取小说书架... 26
18、防盗链-下载梨视频... 28
9、HTML语法基础
Bs4解析比较简单,但是,首先需要了解一下基础的html只是,然后再去使用bs4去提取,逻辑和编写难度就会非常简单和清晰。

<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>我是标题</title> </head> <body bgcolor="pink"> <h1 align="right">我是中国人</h1> <p>刘德华是明星, 曾经是赌侠, 我特别佩服他。</p> <a href="www.baidu.com">刘德华的个人主页</a> <img src="abc.jpeg" width="60px" height="40px"> </body> </html> <!-- html基础语法: 1、<标签名 属性=“值”>被标记的内容</标签名> 2、<标签名 属性=“值” /> -->
BS基础练习
## 获取数据 # 安装bs4 # pip install bs4 from bs4 import BeautifulSoup html = """ <ul> <li><a href="shixiaolong.com">释小龙</a></li> <li id="abc"><a href="wuqilong.com">吴奇隆</a></li> <li><a href="lixunhuan.com">李寻欢</a></li> <li><a href="leizhenzi.com">雷震子</a></li> </ul> """ # 1、初始化BeautifulSoup对象 page = BeautifulSoup(html, "html.parser") #page.find("标签名", attrs={"属性": "值"}) #查找某个元素,只会找到一个结果 #page.find_all("标签名", attrs={"属性": "值"}) #查找某个元素,只会找到一个结果 # li = page.find("li", attrs={"id": "abc"}) # a = li.find("a") # print(a.text) # 拿文本 # print(a.get("href")) # 拿属性, get("属性名") li_list = page.find_all("li") for li in li_list: a = li.find("a") text = a.text href = a.get("href") print(text, href)
10、BS实战1-获取新发地菜价
新发地网页有变动,网页源代码上面不包含数据。不使用BS也能拿到数据。
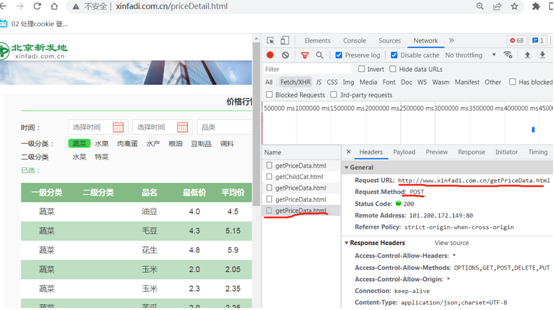
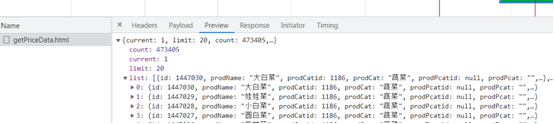
不使用BS拿数据。
import requests f = open("xfd.csv", mode="w", encoding='utf-8-sig') url = "http://www.xinfadi.com.cn/getPriceData.html" data1 = { "limit": "20", "current": "3" } resp = requests.post(url, params=data1) # print(type(resp.json())) dict = resp.json() list_all = dict['list'] for li in list_all: # print(li) kind = li['prodCat'] name = li['prodName'] low = li['lowPrice'] avg = li['avgPrice'] high = li['highPrice'] area = li['place'] unit = li['unitInfo'] datea = li['pubDate'] # print(kind, name, low, avg, high, area, unit, datea) f.write(f"{kind},{name},{low},{avg},{high},{area},{unit},{datea}\n") # break f.close() resp.close() print("北京新发地蔬菜第一页提取完毕.")
11、BS实战2-优化图库图片下载
网站有变化:https://www.umei.cc/bizhitupian/xiaoqingxinbizhi/
需求:下载图片
步骤:首页找到对应的href链接,子页面找到图片地址,然后下载下来。
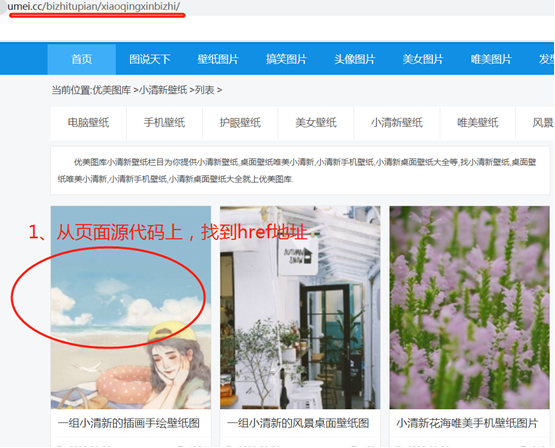

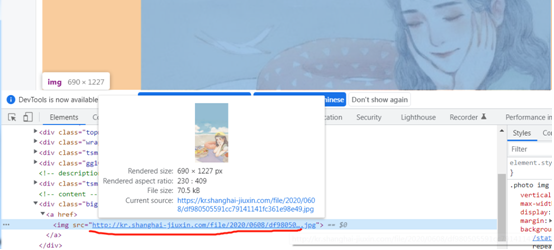
下载源代码如下,


import requests from bs4 import BeautifulSoup domain = "https://www.umei.cc" url = "https://www.umei.cc/bizhitupian/xiaoqingxinbizhi/" resp = requests.get(url) resp.encoding = "utf-8" # print(resp.text) n = 1 main_page = BeautifulSoup(resp.text, "html.parser") a_list = main_page.find_all("div", attrs={"class": "item_b clearfix"}) # 过滤全部的包含a标签的div for a in a_list: href_a = a.find_all("a")[0]["href"] # 提取a标签 # print(href_a) child_url = domain + href_a child_resp = requests.get(child_url) child_resp.encoding = "utf-8" # print(child_resp.text) # 子页面的bs对象 child_bs = BeautifulSoup(child_resp.text, "html.parser") div1 = child_bs.find_all("div", attrs={"class": "big-pic"}) img_src = div1[0].find_all("img")[0].get("src") # print(img_src) # 下载图片 img_resp = requests.get(img_src) with open(f"pic/{n}.jpg", mode="wb") as f: #wb不止写文本,还可以写图片 f.write(img_resp.content) # 把图片信息写入到文件中 print(f"第{n}个图片下载完毕.") n += 1
数据存储在当前pic目录下。
12、xpath解析
理论知识过
知识点梳理,直接用代码演示。
from lxml import etree xml = """ <book> <id>1</id> <name>野花遍地香</name> <price>1.23</price> <nick>臭豆腐</nick> <author> <nick id="10086">周大强</nick> <nick id="10010">谢大脚</nick> <nick class="joy">周杰伦</nick> <nick class="Jolin">蔡依林</nick> <div> <nick>哭了</nick> </div> </author> <partnet> <nick id="ppc">胖胖胖</nick> <nick id="ppbc">胖胖s胖</nick> </partnet> </book> """ et = etree.XML(xml) # result = et.xpath("/book") # 表示根节点 # result = et.xpath("/book/name") # 在xpath中间的/表示儿子 # result = et.xpath("/book/name/text()")[0] # text()拿文本 # result = et.xpath("/book//nick") # //表示所有的子孙后代 # result = et.xpath("/book/*/nick/text()") # /*/只拿表示孙子辈数据, *通配符,谁都行 # result = et.xpath("/book/author/nick[@class='joy']/text()") # []表示属性筛选,@属性名=值 result = et.xpath("/book/partnet/nick/@id") # 最后一个/表示拿到nick里面的id内容, @属性,可以直接拿到属性值 print(result)
html补充说明
htmla = """ <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>我是标题</title> </head> <body bgcolor="pink"> <ul> <li><a href="http://www.baidu.com">百度</a></li> <li><a href="http://www.google.com">谷歌</a></li> <li><a href="http://www.sogou.com">搜狗</a></li> </ul> <ol> <li><a href="feiji">飞机</a></li> <li><a href="dapao">大炮</a></li> <li><a href="huoche">火车</a></li> </ol> <div class="job">李嘉诚</div> <div class="common">胡辣汤</div> </body> </html> """ et = etree.HTML(htmla) # li_list = et.xpath("/html/body/ul/li/a/text()") # li_list = et.xpath("/html/body/ul/li[1]/a/text()") #数字表示第几个 li_list = et.xpath("//li") # 全局查询li标签 # print(li_list) for li in li_list: href = li.xpath("./a/@href")[0] # ./表示当前节点 text = li.xpath("./a/text()")[0] # ./表示当前节点 print(href, text)
13、xpath示例-猪八戒网址
需求:获取价格、名称和公司名称。
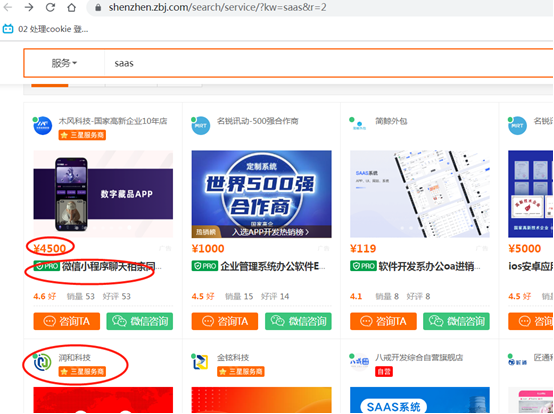
分析可以看到源代码,上面有需要的数据,直接拿 ,拷贝源代码到本地prcharm上面,
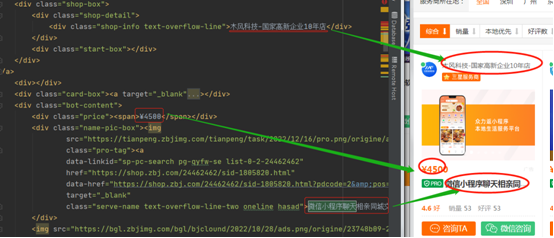

由于页面源代码较多,可以将源代码复制到pycharm上面,单独针对html文件提取数据。
源代码展示:
""" # 拿到页面源代码 # 从页面源代码中提取你需要的数据,价格,名称,公司名称。 """ import requests from lxml import etree url = "https://shenzhen.zbj.com/search/f/?type=new&kw=saas" resp = requests.get(url) resp.encoding = "utf-8" # print(resp.text) # 提取数据 et = etree.HTML(resp.text) divs = et.xpath("//div[@class='service-card-wrap']/div") for div in divs: # print(div) # 此时的div就是一条数据,对应一个商品信息 comany = div.xpath("./a/div[2]/div[1]/div/text()") price = div.xpath("./div[3]/div[1]/span/text()") name = div.xpath("./div[3]/div[2]/a/text()") # print(type(comany), len(comany)) comany = comany[0] if(len(comany)==1) else exit() # 这里是个疑问,源代码只能拿到前面6条数据。 print(comany, price[0], name[0]) # break
14、pyquery基础内容
理论知识过
from pyquery import PyQuery html = """ <li><a href="http://www.baidu.com">百度</a></li> """ p = PyQuery(html) # 加载html内容 # print(p) # print(type(p)) # a = p("a") # pyquery对象直接(css选择器) # print(a, type(a)) # 依然是pyquery对象 # b = p("li")("a") # 链式操作 # print(b.text()) # c = p("li a") # print(c) html1 = """ <ul> <li class="aaa"><a href="http://www.baidu.com">百度</a></li> <li class="aaa" id="gg"><a href="http://www.google.com">谷歌</a></li> <li class="bbb"><a href="http://www.sogou.com">搜狗</a></li> <li class="bbb"><a href="http://www.test.com">测试</a></li> </ul> """ p1 = PyQuery(html1) # a = p1(".aaa a") # class="aaa" # print(a) # a = p1("#gg a") # id="gg" # print(a.attr("href")) # 获取属性值 # print(a.text()) # 获取文本 # 来个坑操作:多个标签拿属性 # href = p1("li a").attr("href") # 多个标签拿属性,只能匹配到第一个 # print(href) # its = p1("li a").items() # for item in its: # href = item.attr("href") # 拿属性 # text = item.text() # 拿文本 # print(text, href) """ 总结: 1、pyquery(选择器) 2、items() 当选择器选择的内容很多的时候,需要一个个处理的时候使用 3、attr("属性名") 获取属性信息 4、text() 获取文本 """ # diva = """<div><span>热爱中国</span></div>""" # pa = PyQuery(diva) # html = pa("div").html() # 全部需要 # text = pa("div").text() # 只有文本,所有html标签不要 # print(html, text) # pyquery对html结构修改 html2 = """ <html> <div class="aaa">哒哒哒</div> <div class="bbb">嘿嘿嘿</div> </html> """ p2 = PyQuery(html2) # p2("div.aaa").after("""<div class="ccc">达到撒多</div>""") #在XXX后面添加XXX标签 # p2("div.aaa").append("""<span">达到撒多</span>""") # 插入XXX标签 # p2("div.bbb").attr("class", "aaa") # 修改XXX标签属性 p2("div.bbb").attr("id", "12308")# 新增XXX标签属性,有的话就是修改 p2("div.bbb").remove_attr("id")# 删除XXX标签属性 p2("div.bbb").remove()# 删除标签 print(p2)
15、pyquery实战1-汽车之家购车信息
思路,首看网页源代码,没有展示就F12看页面内容。
对方校验标签:F12->elements
链接地址有所变化:https://k.autohome.com.cn/146
地址:https://k.autohome.com.cn/146/index_6.html
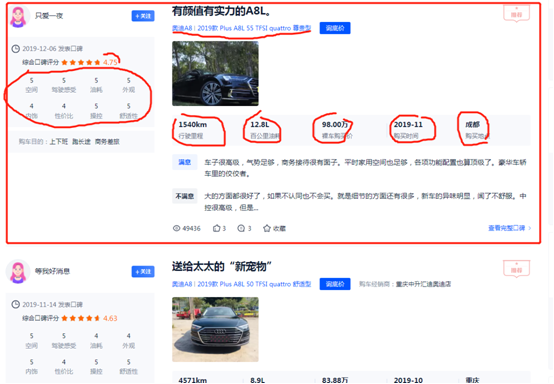
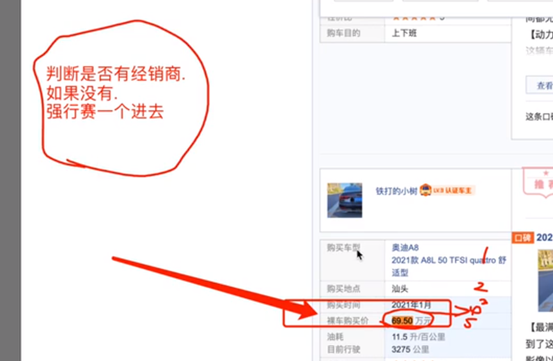

源代码展示,
""" 1. 提取页面源代码 2. 解析页面源代码, 提取数据 """ import requests # url = "https://k.autohome.com.cn/146/index_6.html" url = "https://koubeiipv6.app.autohome.com.cn/pc/series/list?pm=3&seriesId=146&pageIndex=6&pageSize=20&yearid=0&ge=0&seriesSummaryKey=0&order=0" # 1. 提取页面源代码 resp = requests.get(url) dict_resp = resp.json() # print(type(dict_resp)) dic_list = dict_resp['result'] # print(type(dic_list), dic_list) list_a = dic_list["list"] carname = "奥迪A8" for lis in list_a: # print(lis) # carname = lis['carname'] if('carname' in lis) else carname = "奥迪A8" specname = lis['specname'] # carname+specname, 车型 exinfolist = lis['exinfolist'] scoreList = lis['scoreList'] # 依次是空间、驾驶感受、油耗... # print(scoreList[0]['value'], scoreList[1]['value'],scoreList[2]['value'],scoreList[3]['value'],scoreList[4]['value'],scoreList[5]['value'],scoreList[6]['value'],scoreList[7]['value']) distance = exinfolist[0]['value'] # 行驶里程 actual_oil_consumption = exinfolist[1]['value'] # 百公里油耗 buyprice = exinfolist[2]['value'] # 裸车购买价 boughtDate = exinfolist[3]['value'] # 购买时间 buyplace = exinfolist[4]['value'] # 购买地点 # print(carname+' | '+specname) print(carname+' | '+specname,distance,actual_oil_consumption,buyprice,boughtDate,buyplace, scoreList[0]['value'], scoreList[1]['value'],scoreList[2]['value'],scoreList[3]['value'],scoreList[4]['value'],scoreList[5]['value'],scoreList[6]['value'],scoreList[7]['value']) # break
16、requests进阶概述
前期爬虫已经使用过headers,他是http协议中的请求头,一般存放一些和请求内容无关的数据,有时会存放一些安全验证信息,比如常见的user-agent、token、cookie等。
知识点:
模拟浏览器登录
防盗链处理->爬取梨视频数据
代理->防止被封IP
接入第三方代理
17、cookie-获取小说书架
Cookie示例:
注意:F12,看不到login信息,需要打开一些参数,参考链接:
https://www.cnblogs.com/Frank-guo/p/14004516.html
页面登录接口
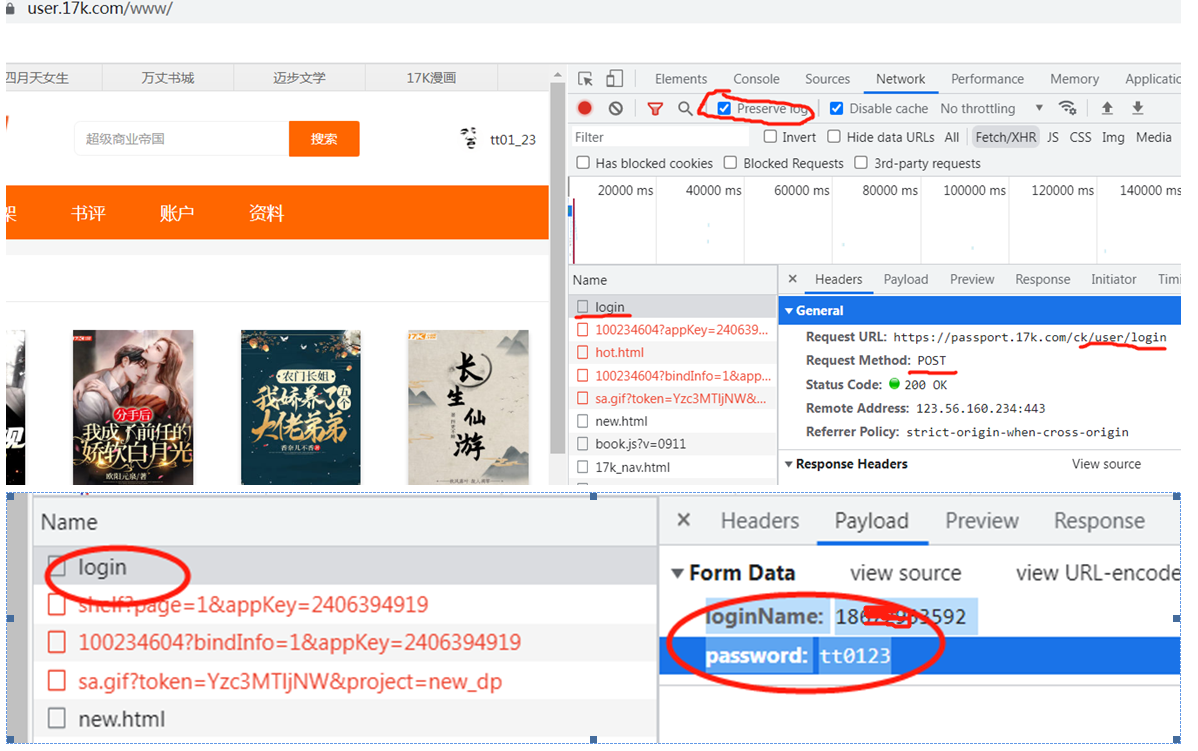
代码展示:
# 登录 -> 得到cookie # 带着cookie 去请求到书架url -> 书架上的内容 # 必须把上面的两个操作链接起来 # 可以使用session进行登录 ——》 session可以认为是一连串请求,整个过程cookie不会丢失 import requests # 会话 session = requests.session() data = { "loginName": "186XXX592", "password": "tt0123" } # 1.登录 url = "https://passport.17k.com/ck/user/login" resp = session.post(url, data=data) # print(resp.text) # print(resp.cookies) # 2.拿书架上的数据 resp1 = session.get("https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919") print(resp1.json()) """ # 骚操作,直接在浏览器上登录,然后拷贝cookie到程序 url = "https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919" aaa = { "Cookie": "GUID=26e5778f-f657-45bc-900e-30d9fadebb5c; sa…" } resp = requests.get(url, headers=aaa ) print(resp.text) """
以上两种方法,骚操作比较快。
18、防盗链-下载梨视频
页面源代码查不到视频链接地址
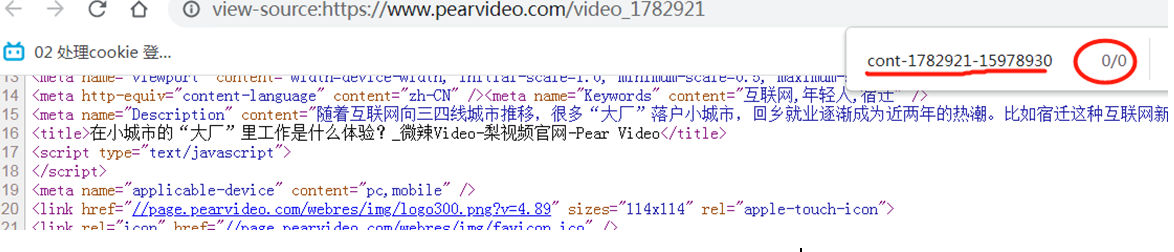
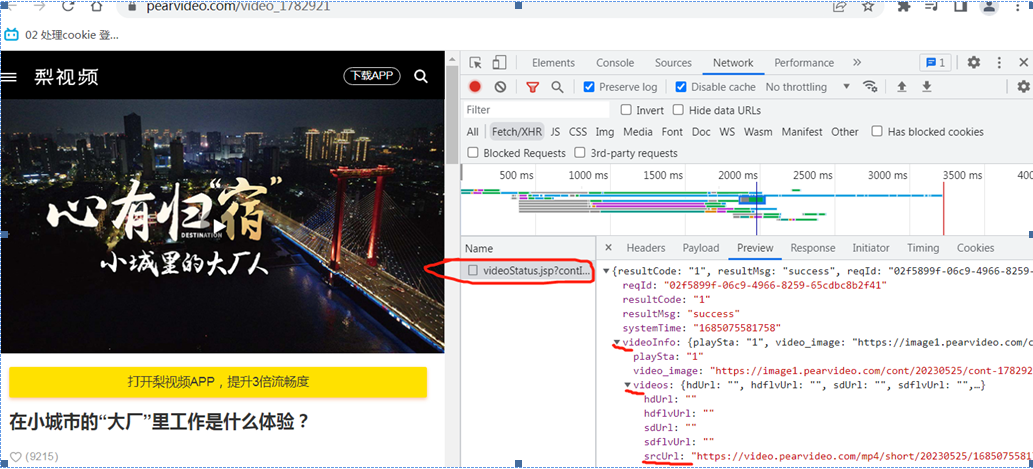
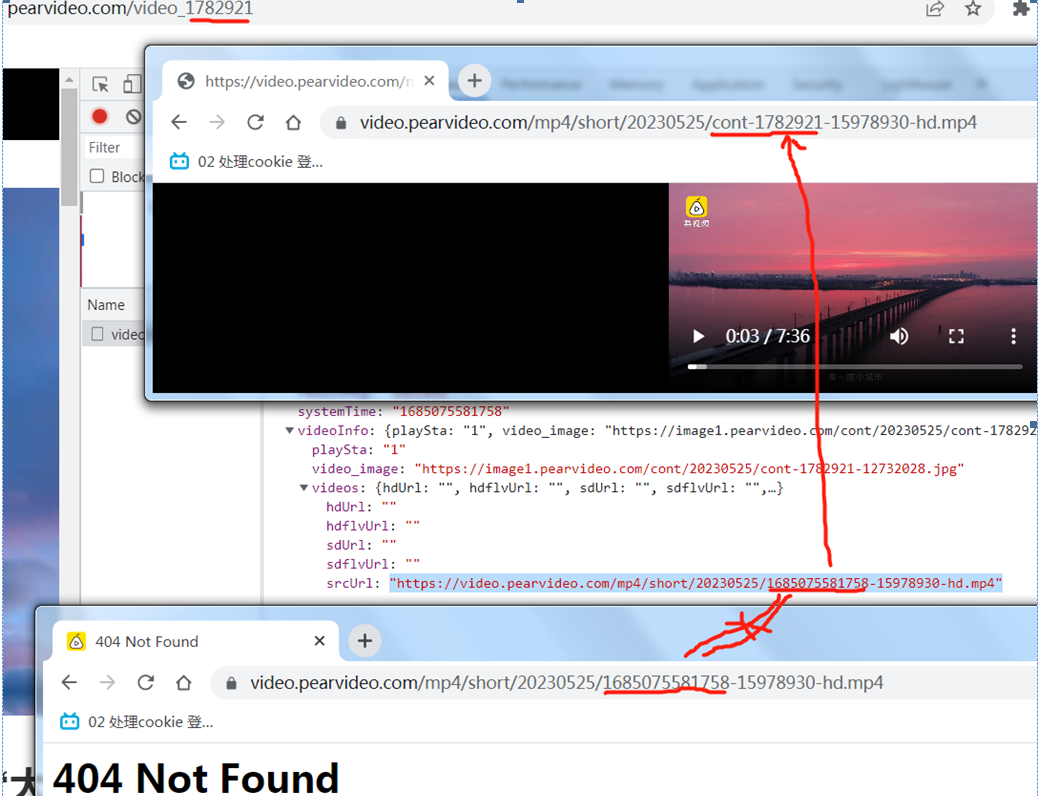
第一次返回,并没有视频链接地址,拿就是通过其他手段或第二次请求获取的。
如上,二次请求的视频地址做了转换。
过程可能有点慢,耐心等待。
代码展示:
# https://www.pearvideo.com/video_1782921 # https://www.pearvideo.com/videoStatus.jsp?contId=1782921&mrd=0.5933374676366527 # https://video.pearvideo.com/mp4/short/20230525/1685075581758-15978930-hd.mp4 # https://video.pearvideo.com/mp4/short/20230525/cont-1782921-15978930-hd.mp4 """ 拿到contId 拿到videostatus返回的json ->srcURL srcURL里面的内容进行修整 下载视频 """ import requests url = "https://www.pearvideo.com/video_1782921" contId = url.split("_")[1] videoStatusUrl = f"https://www.pearvideo.com/videoStatus.jsp?contId={contId}&mrd=0.5933374676366527" # print(videoStatusUrl) headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36", # 防盗链:溯源,当前本次请求的上一级是谁 "Referer": url } resp = requests.get(videoStatusUrl, headers=headers) # print(resp.text) dic = resp.json() srcUrl = dic["videoInfo"]["videos"]["srcUrl"] systemTime = dic["systemTime"] srcUrl = srcUrl.replace(systemTime, f"cont-{contId}") # print(srcUrl) # 下载视频 with open("a1.mp4", mode="wb") as f: f.write(requests.get(srcUrl).content) print("下载完成")
如上,视频下载完成。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· AI Agent开发,如何调用三方的API Function,是通过提示词来发起调用的吗
2019-06-04 1、Devops核心要点及kubernetes架构概述