

Python爬虫入门教程-1
1、Web请求全过程剖析... 1
2、浏览器工具的使用... 3
3、协议简单了解一下... 3
4、Requests模块入门... 4
5、获取豆瓣电影数据... 6
6、正则表达式... 7
7、实战1-爬取豆瓣top250电影... 9
8、实战2-爬取电影天堂热片... 11
9、HTML语法基础... 13
10、BS实战1-获取新发地菜价... 15
11、BS实战2-优化图库图片下载... 16
12、xpath解析... 18
13、xpath示例-猪八戒网址... 20
14、pyquery基础内容... 22
15、pyquery实战1-汽车之家购车信息... 24
16、requests进阶概述... 26
17、cookie-获取小说书架... 26
18、防盗链-下载梨视频... 28
1、Web请求全过程剖析
那么到底我们浏览器在输入网址到我们看到网页的整体内容,这个果子究竟发生了什么。
我们以百度为例。在访问百度的时候,浏览器会把这一次请求发送到百度的服务器,有服务器接收这个请求,然后加载一些数据,返回给浏览器,再由浏览器进行展示。注意,百度的服务器返回给浏览器不是纯粹的页面,而是页面源代码(由html,css,js组成),由浏览器把页面源代码进行执行,然后把执行之后的结果展示给用户。
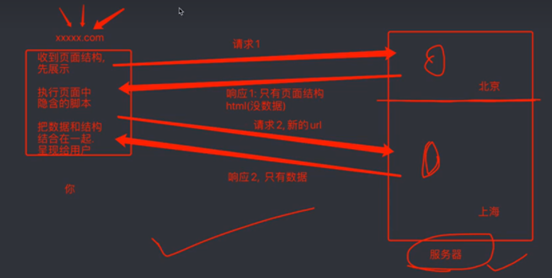
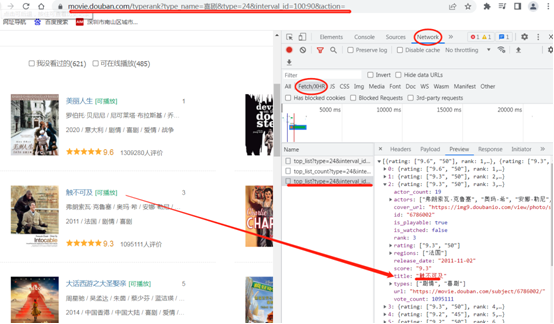
以豆瓣电影排行示例,怎么获取返回的数据。
地址:https://movie.douban.com/typerank?type_name=%E5%96%9C%E5%89%A7&type=24&interval_id=100:90&action=
获取电影信息:
2、浏览器工具的使用
Chrome浏览器为主,浏览器最能直观的看到网页情况以及网页加载内容的地方,我们可以按F12查看一些用户很少能使用到的工具。
如Elements,看到的内容跟数据源代码使用差距的。
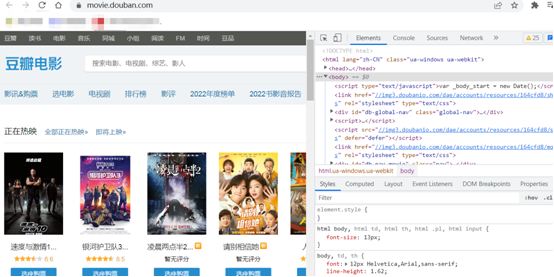
其次最常用的是Network。
3、协议简单了解一下
HTTP协议
协议就是两个计算机之间为了能够流畅的进行沟通而设置的一个君子协议,场景的协议有TCP/IP,SOAP协议,HTTP,SMTP协议等等…
HTTP协议,用户从万维网服务器传输超文本到本地浏览器的传送协议,就是;浏览器和服务器之间的数据交互遵守的规定。
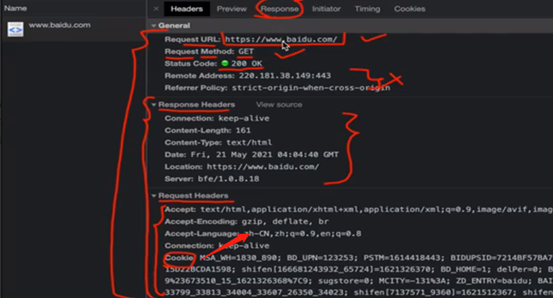
HTTP协议把一条消息分为三大块内容,无论请求还是响应都是三块内容
请求:
请求行: 请求方式(get/post) 请求url 协议
请求头: 放一些服务器要使用的附加信息
请求体: 一般放一些请求参数
响应:
状态行: 协议 状态码
响应头: 放一些客户端要使用的一些附件信息 (cookie,验证信息,解密的key)
响应体: 服务器返回的真正客户端要用的内容(html,json)等
4、Requests模块入门
我们使用urllib来抓取页面源代码,这个是python内置的一个模块,但是。并不是我们常用的爬虫工具,常用的抓取页面的模块通常是一个第三方模块requests,这个模块的优势比urllib还要简单,并且处理各种请求都要方便。
既然是第三方模块,就需要安装
Pip install requests
如果安装速度慢,可以改用国内的源进行下载安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests
安装帮助文档:https://mirrors.tuna.tsinghua.edu.cn/help/pypi/
入门示例,
## 获取数据 import requests # 爬取百度页面源代码 url = "http://www.baidu.com" resp = requests.get(url) resp.encoding = "utf-8" print(resp.text) # 拿到页面源代码
请求方式案例,Get请求示例,

## 获取数据 import requests content = input('请输入你要检索的内容: ') url = f"https://www.sogou.com/web?query={content}" headers = { # 添加一个请求头信息, UA "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36" } resp = requests.get(url, headers=headers) print(resp.text) # 拿到页面源代码 #print(resp.request.headers) # 查看请求头信息
POST示例
页面查看参数,post形式,一般参数实在form表单里面传输。
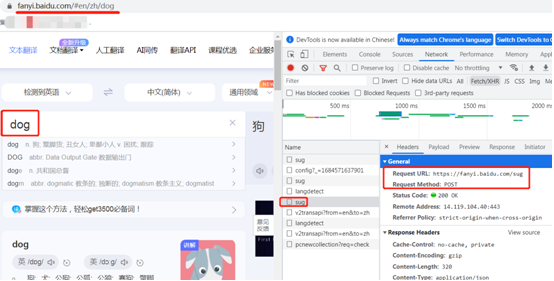
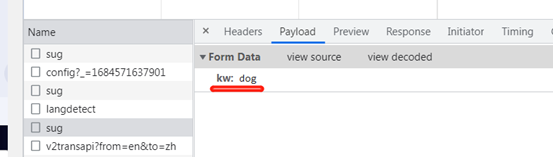
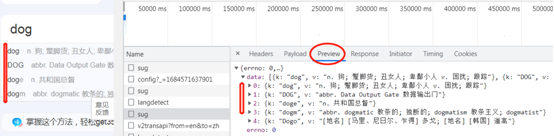
代码示例,
## 获取数据 import requests url = "https://fanyi.baidu.com/sug" dataa = { # 添加一个请求头信息, UA "kw": input("请输入一个单词:") } resp = requests.post(url, data=dataa) #print(resp.text) # 拿到的是文本字符串 print(resp.json()) # 此时拿到的是json数据
5、获取豆瓣电影数据
当一个页面get请求太多的时候,怎么爬取。源代码只能查到页面数据框架。
如豆瓣电影,https://movie.douban.com/typerank?type_name=%E5%96%9C%E5%89%A7&type=24&interval_id=100:90&action=,获取喜剧电影。
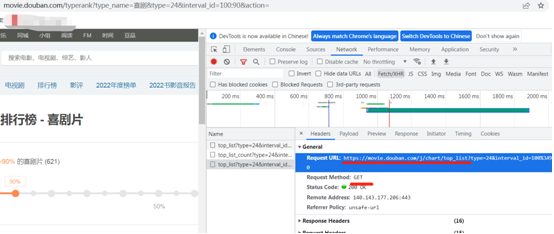
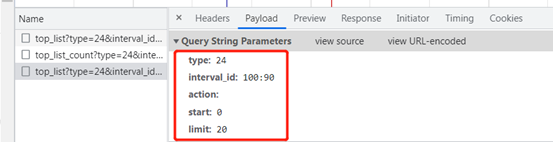
## 获取数据 import requests url = "https://movie.douban.com/j/chart/top_list" dataa = { # 添加一个请求头信息, UA "type": "24", "interval_id": "100:90", "action": "", "start": "0", "limit": "20" } headers = { # 添加一个请求头信息, UA "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36" } resp = requests.get(url, params=dataa, headers=headers) # 请求头,处理反爬 #print(resp.text) # 拿到的是文本字符串 print(resp.json()) #print(resp.request.url)
下面开始对有用数据进行解析,开始之前需要了解正则表达式。
6、正则表达式
在线匹配:https://tool.oschina.net/regex
正则表达式,又称规则表达式,(Regular Expression,在代码中常简写为regex、regexp或RE),是一种文本模式。
我们抓取的网页源代码本质上就是一个超长的字符串,想从里面提前内容,用正则刚好合适。
正则的有点:速度快,效率高,准确性高
正则的缺点:新手上手难点高
正则语法:使用元字符进行排列组合用来匹配字符串,在线正则表达式:https://tool.oschina.net/regex
元字符:具有固定含义的特殊字符
常用元字符:
. 匹配出换行符之外的任意字符,未来在python的re模块中是一个坑。
\w 匹配字母或数字或下划线
\s 匹配任意的空白符
\d 匹配数字
\n 匹配一个换行符
\t 匹配一个制表符
^ 匹配字符串的开始
$ 匹配字符串的结尾
\W 匹配非字母或数字或下划线
\D 匹配非数字
\S 匹配非空白符
() 匹配括号内的表达式,也表示一个组
[...] 匹配字符组中的字符
[^....] 匹配除字符组中字符的所有字符
量词:控制前面的元字符出现的次数
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
贪婪匹配喝惰性匹配
.* 贪婪匹配
.*? 惰性匹配
三个常见匹配参数
# search 只会匹配到第一次匹配的内容
# match匹配过程,是从字符串的开头进行匹配,类似开头加了^字符。
# findall匹配字符串中所有匹配的内容
示例练习
import re #reslu = re.findall("a", "我是一个babcadefg") #print(reslu) #=>['a', 'a'] # reslu = re.findall(r"\d+", "我今年20岁,月薪3800。") # print(reslu) #=>['20', '3800'] # 重点关注,实际使用场景多 # reslu = re.finditer(r"\d+", "我今年20岁,月薪3800。") # for item in reslu: # 从迭代器中拿到内容 # print(item.group()) #从匹配到的结果中拿到数据 # search 只会匹配到第一次匹配的内容 # reslu = re.search(r"\d+", "我今年20岁,月薪3800。") # print(reslu.group()) #=>20 # 匹配过程,是从字符串的开头进行匹配,类似开头加了^字符。 # reslu = re.match(r"\d+", "我今年20岁,月薪3800。") # print(reslu) #=>None
原始匹配示例
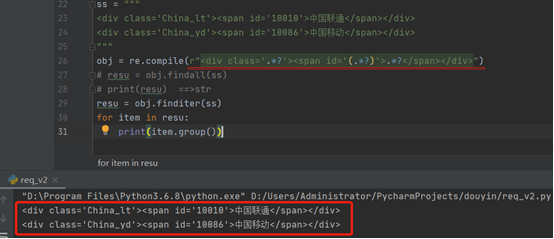
ss = """ <div class='China_lt'><span id='10010'>中国联通</span></div> <div class='China_yd'><span id='10086'>中国移动</span></div> """ obj = re.compile(r"<div class='.*?'><span id='(.*?)'>.*?</span></div>") # resu = obj.findall(ss) # print(resu) ==>str resu = obj.finditer(ss) for item in resu: print(item.group())
如下截图.*?用法
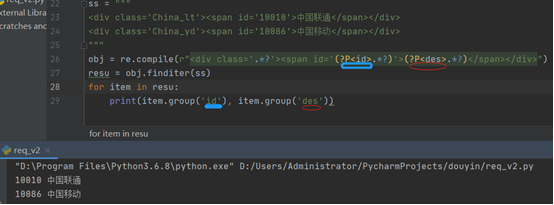
高级示例,插入字段
(.*?) #只拿匹配的内容,
(?P<id>.*?) #拿匹配的内容,指定字段为id
7、实战1-爬取豆瓣top250电影
页面分析:需要获取的数据字段如下
字段:电影片名,导演,年份,评分,评价等字段。
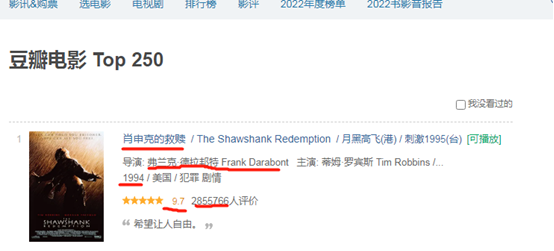
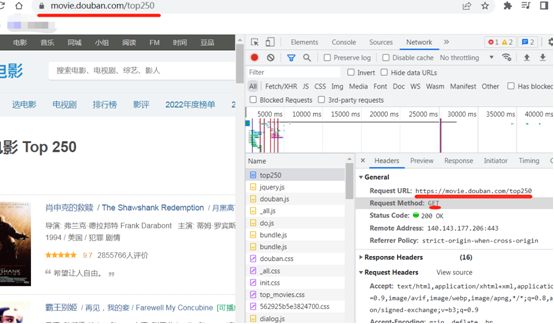
分析网页源代码
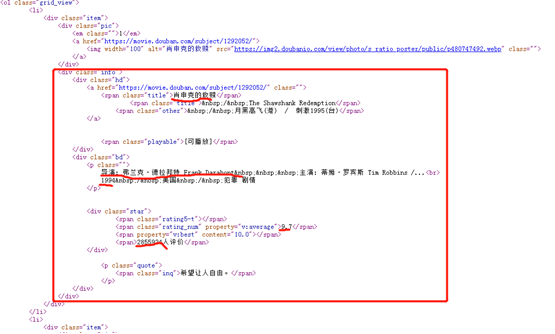
obj = re.compile(r'<li>.*?<span class="title">(?P<name>.*?)</span>.*?<p class="">.*?导演: (?P<director>.*?) .*?<br>(?P<year>.*?) .*?<span class="rating_num" property="v:average">(?P<score>.*?)</span>.*?<span>(?P<num>.*?)人评价</span>', re.S)
编写爬虫代码代码:


""" 思路: 1.拿到页面源代码 2.编写正则,提取页面数据 3.保存数据 """ #coding:utf-8 import requests import re # .csv 数据与数据直接以逗号隔开的1,2,3,4,5 f = open("top250.csv", mode="w", encoding='utf-8-sig') url = "https://movie.douban.com/top250" header = { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36" } resp = requests.get(url, headers=header) # print(resp.text) # obj = re.compile(r'<li>.*?<span class="title">(?P<name>.*?)</span>.*?<p class="">.*?导演: (?P<director>.*?) .*?(?P<year>.*?) .*?<span class="rating_num" property="v:average">(?P<score>.*?)</span>.*?<span>(?P<num>.*?)人评价</span>', re.S) obj = re.compile(r'<li>.*?<span class="title">(?P<name>.*?)</span>.*?<p class="">.*?导演: (?P<director>.*?) .*?<br>(?P<year>.*?) .*?<span class="rating_num" property="v:average">(?P<score>.*?)</span>.*?<span>(?P<num>.*?)人评价</span>', re.S) resu = obj.finditer(resp.text) for item in resu: name = (item.group('name')) director = (item.group('director')) year = (item.group('year')).strip() score = (item.group('score')) num = (item.group('num')) # print(name, director, year, score, num) f.write(f"{name},{director},{year},{score},{num}\n") f.close() resp.close() print("豆瓣250第一页提取完毕.")
遗留问题,分页怎处理?
8、实战2-爬取电影天堂热片
需求:电影天堂2023必看热片,提取电影名和下载地址。
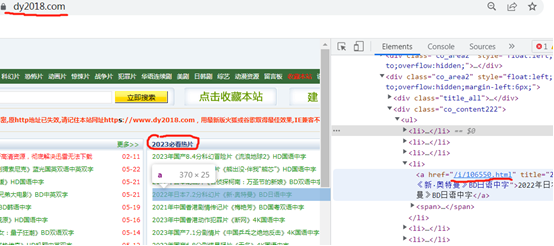
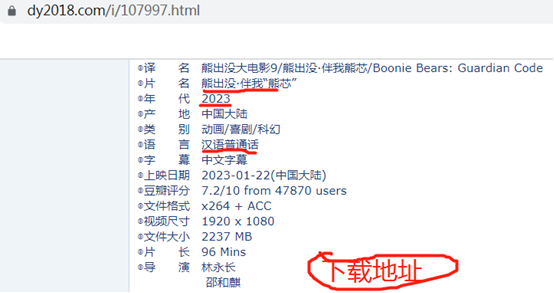
抓取代码:
""" 1.提取到主页面中的每一个电影的背后的url地址 a、拿到"2023必看电影"那一块的html代码 b、从html代码中提取href 2.访问子页面,提取到电影的名称和下载地址 a、拿到子页面的页面源代码 b、数据提取 3.保存数据 """ import requests import re url = "https://www.dy2018.com/" resp = requests.get(url) resp.encoding = "gbk" # print(resp.text) # 提取2023必看热片部分html代码 obj1 = re.compile(r"2023必看热片.*? <ul>(?P<htmla>.*?)</ul>", re.S) result1 = obj1.search(resp.text) htmla = result1.group("htmla") # print(htmla) #提取a标签中的href值 obj2 = re.compile(r"<li><a href='(?P<href>.*?)'", re.S) result2 = obj2.finditer(htmla) obj3 = re.compile(r'<div id="Zoom">.*?<br />◎片 名 (?P<moive>.*?)<br />.*?<td style="WORD-WRAP: break-word" bgcolor="#fdfddf"><a href="(?P<download>.*?)">', re.S) for item in result2: # print(item.group('href')) # 拼接子页面的url child_url = url.strip('/') + item.group('href') child_resp = requests.get(child_url) child_resp.encoding = "gbk" # print(child_resp.text) result3 = obj3.search(child_resp.text) moive = result3.group('moive') download = result3.group('download') print(moive, download) # break
遗留:自己将爬取信息写入文件内。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· AI Agent开发,如何调用三方的API Function,是通过提示词来发起调用的吗
2019-06-04 1、Devops核心要点及kubernetes架构概述