

16、kubernetes之 容器资源需求和资源限制
第十三部分 (Pod)容器资源和容器限制
CPU资源,属于可压缩资源,一个pod或一个容器应该获取指定的资源获取不到时,无非就是等待,
内存:属于非可压缩型资源,可能会因为内存资源耗尽而被kill掉。
资源的起始值和终止值
官网:https://kubernetes.io/docs/concepts/configuration/manage-compute-resources-container/

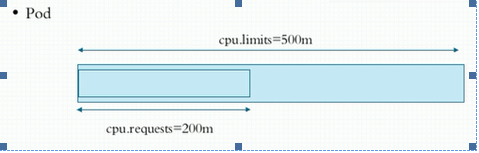
容器的资源需求,资源限制 Request:需求,最低保障; Limits:限制,硬限制 CPU: 1颗逻辑(虚拟)CPU 1=1000,millcores(毫核) 500m=0.5CPU 内存: E、P、T、G、M、K、Ei、Pi
Request保障容器CPU资源可用。示图。
创建资源配置案例。
[root@k8s-master metrics]# cat pod-res-demo.yaml
[root@k8s-master metrics]# cat pod-res-demo.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-res-demo
namespace: default
labels:
app: resapp
tier: frontend
spec:
containers:
- image: ikubernetes/stress-ng
name: resapp
command: ["/usr/bin/stress-ng","-m 1","-c 1","--metrics-brief"]
resources:
requests:
cpu: "200m"
memory: "128Mi"
limits:
cpu: "500m"
memory: "512Mi"
[root@k8s-master metrics]# kubectl create -f pod-res-demo.yaml
[root@k8s-master metrics]# kubectl exec -it pod-res-demo -- /bin/sh
[root@k8s-master metrics]# kubectl exec -it pod-res-demo -- top
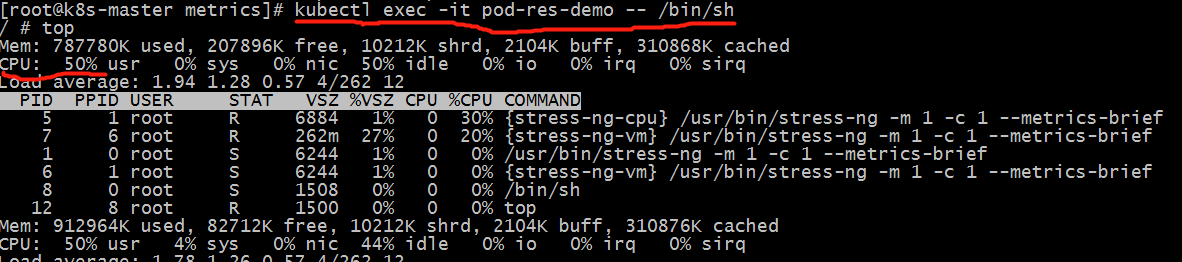
查看CPU压缩使用情况
[root@master ~]# cat /proc/cpuinfo |grep "processor" |wc –l 查看CPU个数,宿主机是2个
1
500m占整个cpu的50%,测试正常。
内存压测限制,导致直接进不去,这里就不演示了。
Qos是被自动配置的
Guranteed:每个容器cpu和内存资源设置了相同值request、limits,当集群资源紧张时,拥有最高优先级调度。 同时设置CPU和内存的request和limits,且相等,自动归类为guranteed。 Cpu.limits=cpu.requests Memory.limites=memory.request Burstable: 至少有一个容器设置CPU或内存资源的requests属性,具有中等优先级。 BestEffort:没有任何一个容器设置了request或limit是属性,最低优先级;
查看上面的Qos,因为设置了cpu,所有术语Burstable中等优先级。
下面我们试试最高优先级的
[root@k8s-master metrics]# cat pod-res-gurantee.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-res-gur
namespace: default
labels:
app: resapp-gur
tier: frontend
spec:
containers:
- image: ikubernetes/myapp:v1
name: resapp-gur
resources:
requests:
cpu: "500m"
memory: "400Mi"
limits:
cpu: "500m"
memory: "400Mi"
[root@k8s-master metrics]# kubectl create -f pod-res-gurantee.yaml
pod/pod-res-gur created
[root@k8s-master metrics]# kubectl get pod/pod-res-gur
NAME READY STATUS RESTARTS AGE
pod-res-gur 1/1 Running 0 9s
[root@k8s-master metrics]# kubectl describe pod/pod-res-gur |grep QoS 如上,自动升级,优先级提升到最高。
QoS Class: Guaranteed
没有设置QoS会自动匹配
[root@k8s-master metrics]# kubectl run nginx-deploy --image=nginx:1.14-alpine --port=80 --replicas=1
kubectl run --generator=deployment/apps.v1 is DEPRECATED and will be removed in a future version. Use kubectl run --generator=run-pod/v1 or kubectl create instead.
deployment.apps/nginx-deploy created
[root@k8s-master metrics]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-deploy-55d8d67cf-zkctp 1/1 Running 0 10s
pod-res-gur 1/1 Running 0 7m9s
[root@k8s-master metrics]# kubectl describe pod nginx-deploy-55d8d67cf-zkctp|grep QoS
QoS Class: BestEffort
综上:当资源不够使用是,BestEffort上面的容器会被优先终止,以腾出资源,确保另外两类pod中容器能够正常运行。优先保证高优先级的容器运行。相同条件下,优先会kill(最低需要保证/最大限制)比率高。
怎么看容器资源使用情况。
生产环境配置参数一般需要根据实际情况来配置这些参数,因此,这些数据的采集需要通过监控服务来采集。
[root@k8s-master ~]# kubectl top #需要部署数据采集和存储
Display Resource (CPU/Memory/Storage) usage.
====新版以下作废,仅供参考
本人采用的是prometheus监控模式,高版本的kubelet已弃用内置cadvisor,所以这里不介绍Influxdb+headster+grafana监控。
关于prometheus监控,可参与前期章节(https://www.cnblogs.com/sunnyyangwang/p/10950382.html)。
Influxdb默认没有存储卷。
Heapster汇聚指标数据
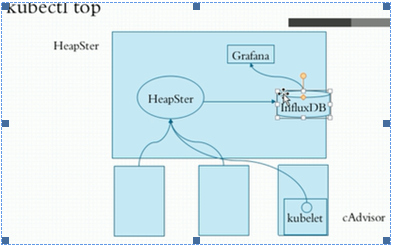
默认采集工具,HeapSter只采集数据,在本节点采集。
新版本的Kubelet内置的cadvisor手机工具,可在单节点查看。默认4194端口。
Cadvisor主动向heapster输入数据,数据缓存在内存中。
需要依赖外部时序数据库系统。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· AI Agent开发,如何调用三方的API Function,是通过提示词来发起调用的吗