

Python3爬取影片入库
Python3爬取影片入库
1、服务器说明
[root@openshift maoyan]# cat /etc/redhat-release
CentOS Linux release 7.4.1708 (Core)
[root@openshift maoyan]# python -V
Python 3.6.3 :: Anaconda, Inc.
2、爬取电影入库
首页页面分地址分析
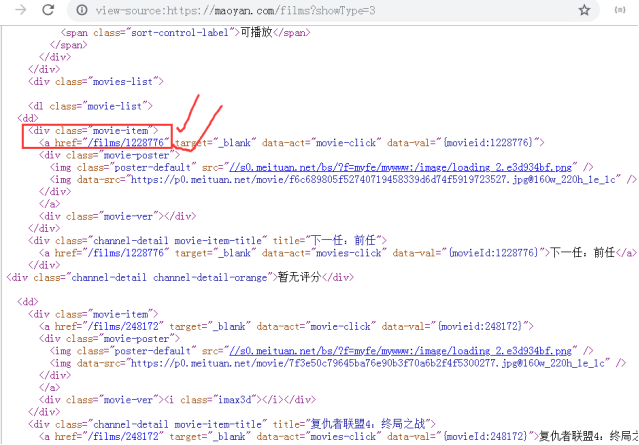
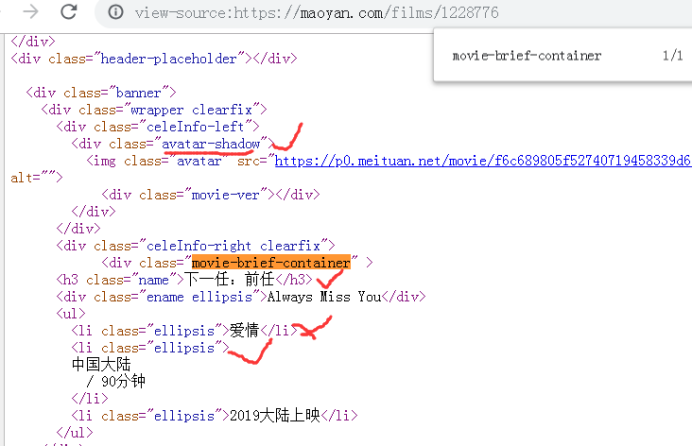
子页面数据获取,四个字段的数据写入,
3、mysql数据库连接
import pymysql
pymysql.install_as_MySQLdb()
class Sql(object):
conn = pymysql.connect(
host="127.0.0.1",
port=3306,
user='root',
passwd='123456',
db="movies",
charset="utf8"
)
4、源代码编写
[root@openshift maoyan]# cat maoyan2.py
# coding:utf-8
import requests,os,sys,django
from bs4 import BeautifulSoup
import re,urllib
import pymysql
pymysql.install_as_MySQLdb()
import datetime
headers = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch',
'Accept-Language':'zh-CN,zh;q=0.8',
'Cache-Control':'max-age=0',
'Connection':'keep-alive',
'Host':'maoyan.com',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
class Sql(object):
conn = pymysql.connect(
host="127.0.0.1",
port=3306,
user='root',
passwd='123456',
db="movies",
charset="utf8"
)
url = 'http://maoyan.com/films?showType=3'
#url = 'https://maoyan.com/films?showType=3&offset=30'
wbdata = requests.get(url,headers=headers)
soup = BeautifulSoup(wbdata.content,'html5lib')
movie_list = soup.select('div.movie-item > a')
for movie in movie_list:
m_url = 'http://maoyan.com' + movie.get('href')
m_data = requests.get(m_url,headers=headers)
m_soup = BeautifulSoup(m_data.content,'html5lib')
name = m_soup.select_one('div.movie-brief-container > h3.name').get_text()
movie_cate = m_soup.select("div.movie-brief-container > ul > li")[0].get_text()
release_date = m_soup.select("div.movie-brief-container > ul > li")[2].get_text()[0:10]
movie_img = m_soup.select_one('div.avatar-shadow > img').get('src')
created = datetime.datetime.now()
viewd = 1
cur = conn.cursor()
cur.execute("insert into userscore_movie(name,movie_cate,viewed,created,release_date,movie_img) VALUES('%s','%s','%d','%s','%s','%s')" %(name,movie_cate,viewd,created,release_date,movie_img))
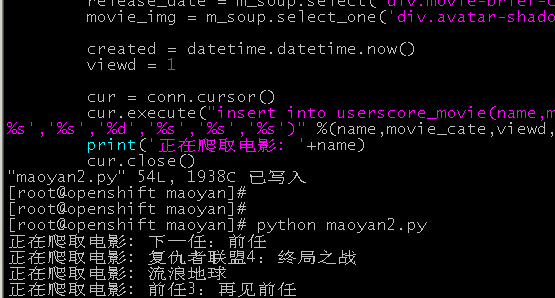
print('正在爬取电影: '+name)
cur.close()
conn.commit()
Sql()
5、执行脚本,爬取数据过程
6、数据库查看
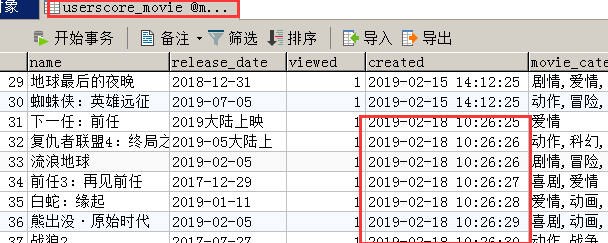
自此,完成了Python3爬取影片入库过程。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· AI Agent开发,如何调用三方的API Function,是通过提示词来发起调用的吗
2017-02-18 Python创建二维码通讯录
2017-02-18 Python web.py模块基本应用