

LangChain RAG 上册
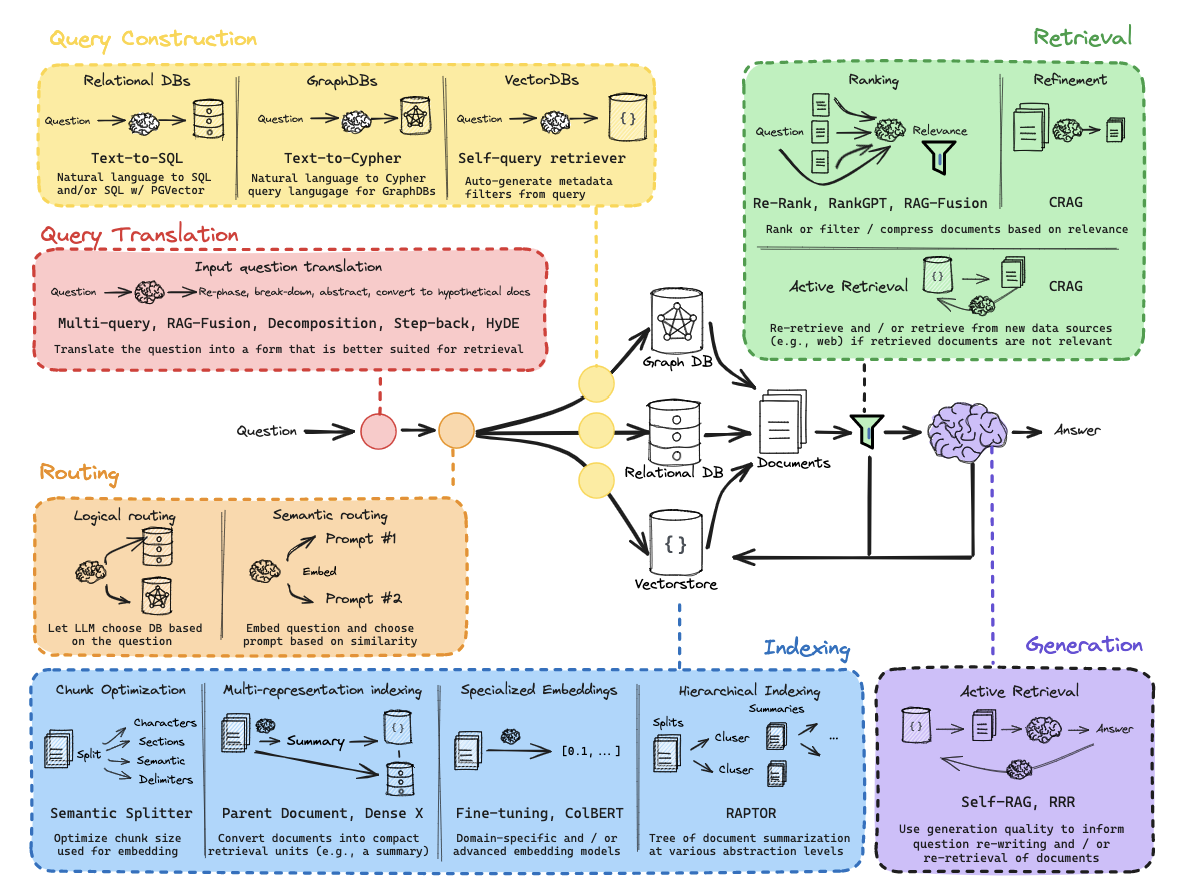
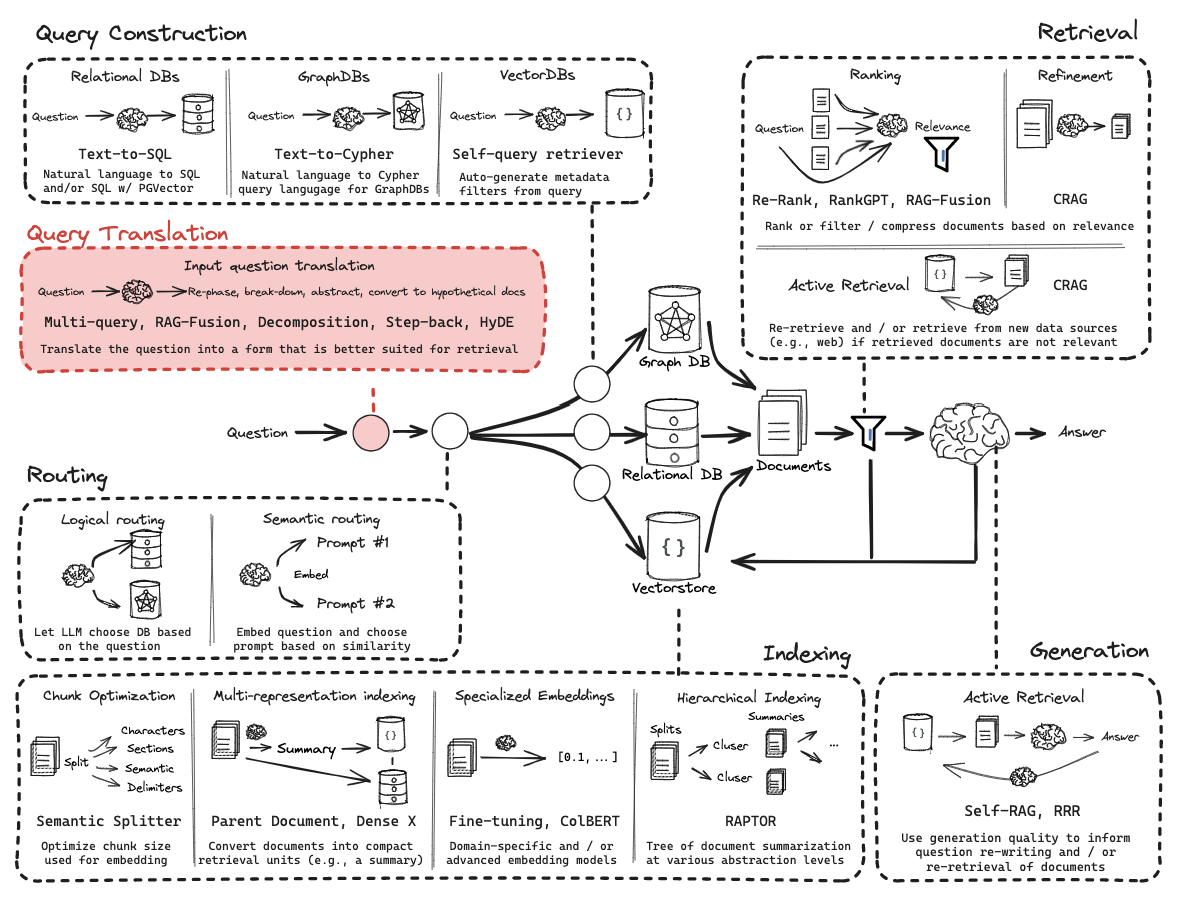
一切都要从这张图开始说起,这是RAG的经典图
涵盖了Question->Translation->Routing->Construction->DB(VectorStore)->Indexing->Documents->Retrieval->Generation->Answer
今天我们就来一起学习、拆解这张图,经过这次的学习,你会对RAG有深刻的理解。
参考资料
https://youtube.com/playlist?list=PLfaIDFEXuae2LXbO1_PKyVJiQ23ZztA0x&feature=shared
https://github.com/langchain-ai/rag-from-scratch/blob/main/rag_from_scratch_1_to_4.ipynb
RAG的整个流程 Overview
1import bs4 2from langchain import hub 3from langchain.text_splitter import RecursiveCharacterTextSplitter 4from langchain_community.document_loaders import WebBaseLoader 5from langchain_community.vectorstores import Chroma 6from langchain_core.output_parsers import StrOutputParser 7from langchain_core.runnables import RunnablePassthrough 8from langchain_openai import ChatOpenAI, OpenAIEmbeddings 9 10#### INDEXING #### 11 12# 加载文档 13loader = WebBaseLoader( 14 web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",), 15 bs_kwargs=dict( 16 parse_only=bs4.SoupStrainer( 17 class_=("post-content", "post-title", "post-header") 18 ) 19 ), 20) 21docs = loader.load() 22 23# 切分 24text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200) 25splits = text_splitter.split_documents(docs) 26 27# 向量化 28vectorstore = Chroma.from_documents(documents=splits, 29 embedding=OpenAIEmbeddings()) 30 31retriever = vectorstore.as_retriever() 32 33#### RETRIEVAL and GENERATION #### 34 35# 提示词 36prompt = hub.pull("rlm/rag-prompt") 37 38# 大模型 39llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0) 40 41# Post-processing 42def format_docs(docs): 43 return "\n\n".join(doc.page_content for doc in docs) 44 45# 链 46rag_chain = ( 47 {"context": retriever | format_docs, "question": RunnablePassthrough()} 48 | prompt 49 | llm 50 | StrOutputParser() 51) 52 53# 问题 -> 答案 54rag_chain.invoke("What is Task Decomposition?")LangChain确实挺好的,简单的几行代码就完成了整个RAG的过程。
索引 Indexing
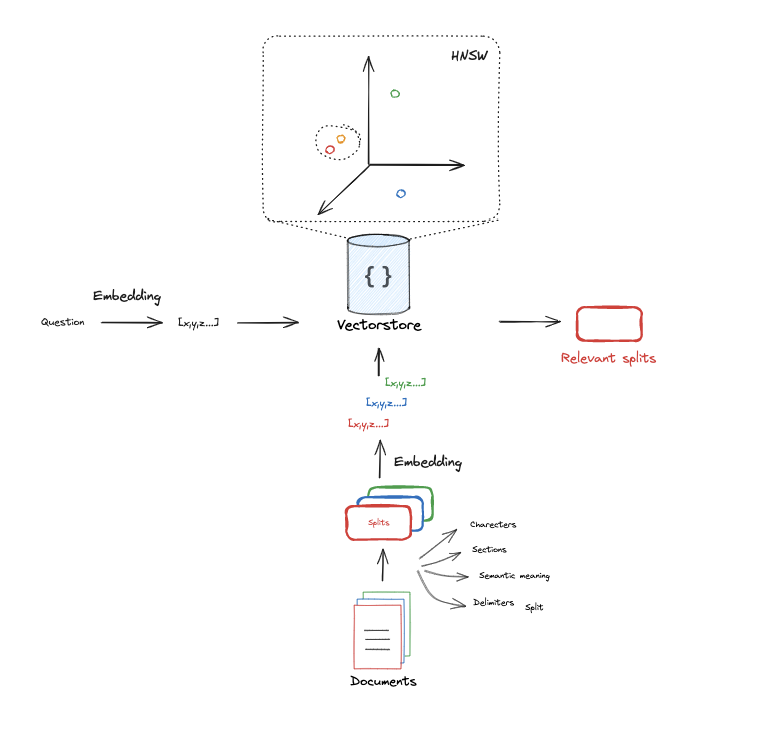
探讨一下文档切分向量化和问题向量化的过程,然后通过HNSW算法找到相似数据
参考资料:
Count tokens considering [~4 char / token
[Text embedding models](https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them)
1# 问题和文档 2question = "What kinds of pets do I like?" 3document = "My favorite pet is a cat." 4 5import tiktoken 6 7def num_tokens_from_string(string: str, encoding_name: str) -> int: 8 """Returns the number of tokens in a text string.""" 9 encoding = tiktoken.get_encoding(encoding_name) 10 num_tokens = len(encoding.encode(string)) 11 return num_tokens 12# 计算token 13num_tokens_from_string(question, "cl100k_base") 14 15# 通过openai进行向量化Embedding 16from langchain_openai import OpenAIEmbeddings 17embd = OpenAIEmbeddings() 18query_result = embd.embed_query(question) 19document_result = embd.embed_query(document) 20len(query_result) 21 22import numpy as np 23 24# 余弦相似性算法 25def cosine_similarity(vec1, vec2): 26 dot_product = np.dot(vec1, vec2) 27 norm_vec1 = np.linalg.norm(vec1) 28 norm_vec2 = np.linalg.norm(vec2) 29 return dot_product / (norm_vec1 * norm_vec2) 30 31similarity = cosine_similarity(query_result, document_result) 32print("Cosine Similarity:", similarity) 33 34#### 索引INDEXING #### 35 36# 加载博客 37import bs4 38from langchain_community.document_loaders import WebBaseLoader 39loader = WebBaseLoader( 40 web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",), 41 bs_kwargs=dict( 42 parse_only=bs4.SoupStrainer( 43 class_=("post-content", "post-title", "post-header") 44 ) 45 ), 46) 47blog_docs = loader.load() 48 49# 切分 50from langchain.text_splitter import RecursiveCharacterTextSplitter 51text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder( 52 chunk_size=300, 53 chunk_overlap=50) 54 55# Make splits 56splits = text_splitter.split_documents(blog_docs) 57 58# 索引Index 59from langchain_openai import OpenAIEmbeddings 60from langchain_community.vectorstores import Chroma 61vectorstore = Chroma.from_documents(documents=splits, 62 embedding=OpenAIEmbeddings()) 63 64retriever = vectorstore.as_retriever()检索 Retrieval
1# Index 2from langchain_openai import OpenAIEmbeddings 3from langchain_community.vectorstores import Chroma 4vectorstore = Chroma.from_documents(documents=splits, 5 embedding=OpenAIEmbeddings()) 6 7 8retriever = vectorstore.as_retriever(search_kwargs={"k": 1}) 9docs = retriever.get_relevant_documents("What is Task Decomposition?") 10len(docs)生成 Generation
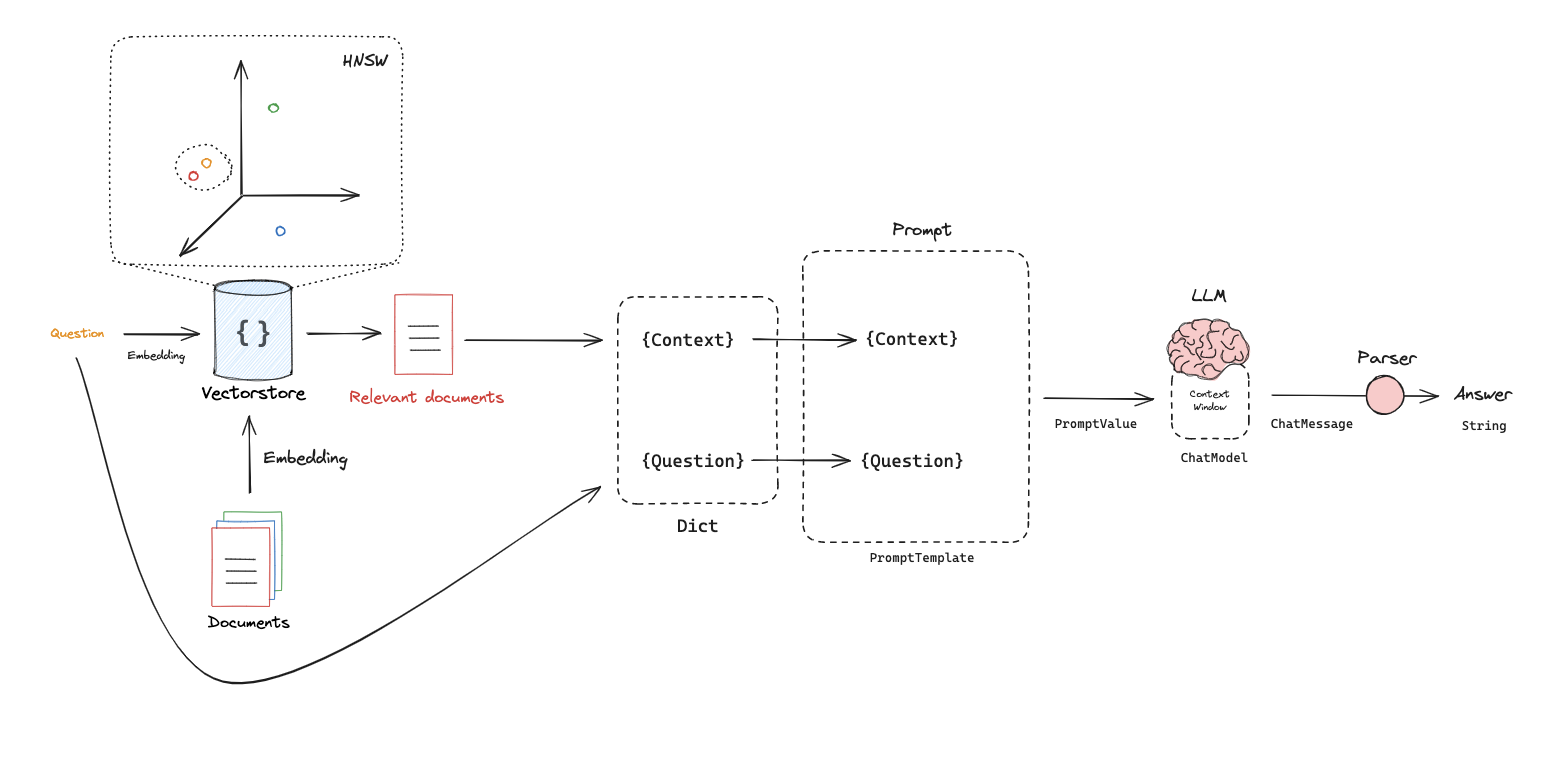
1from langchain_openai import ChatOpenAI 2from langchain.prompts import ChatPromptTemplate 3 4# 提示词 5template = """Answer the question based only on the following context: 6{context} 7 8Question: {question} 9""" 10 11prompt = ChatPromptTemplate.from_template(template) 12prompt 13 14# 大模型 15llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0) 16 17# 链 18chain = prompt | llm 19 20# 运行 21chain.invoke({"context":docs,"question":"What is Task Decomposition?"}) 22 23from langchain import hub 24prompt_hub_rag = hub.pull("rlm/rag-prompt") 25 26prompt_hub_rag 27 28# RAG链 29from langchain_core.output_parsers import StrOutputParser 30from langchain_core.runnables import RunnablePassthrough 31 32rag_chain = ( 33 {"context": retriever, "question": RunnablePassthrough()} 34 | prompt 35 | llm 36 | StrOutputParser() 37) 38 39rag_chain.invoke("What is Task Decomposition?") 40Query Translation
Multi Query
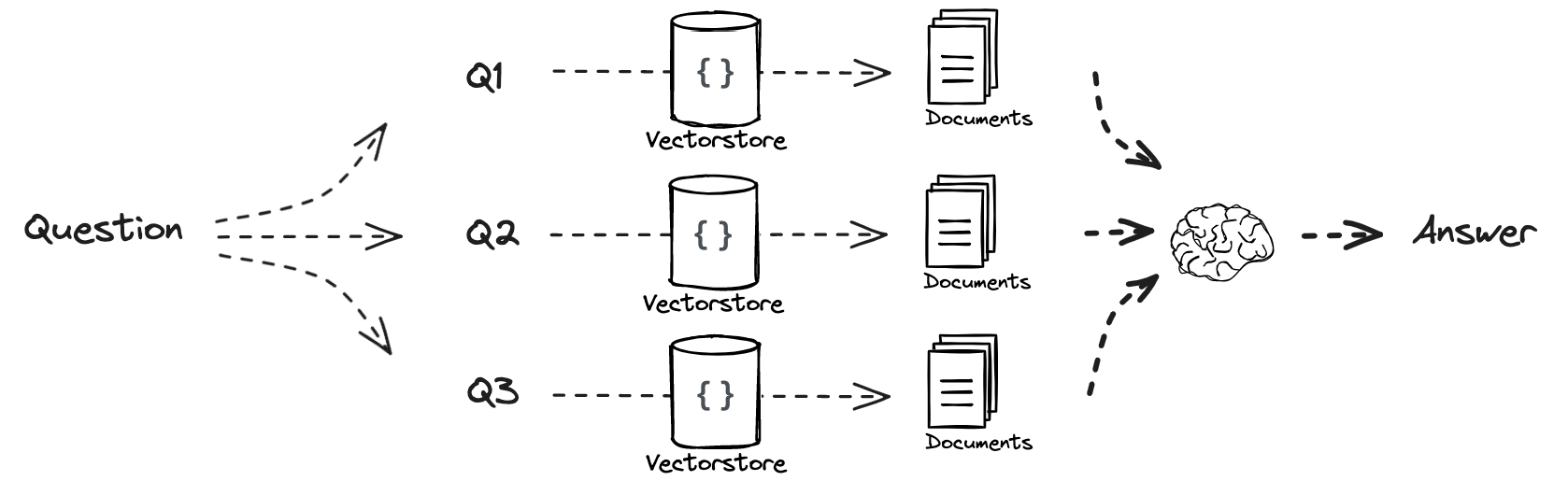
把原本的一个问题 变成 多个问题
参考资料
1#### 索引INDEXING #### 2 3# 抓取博客 4import bs4 5from langchain_community.document_loaders import WebBaseLoader 6loader = WebBaseLoader( 7 web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",), 8 bs_kwargs=dict( 9 parse_only=bs4.SoupStrainer( 10 class_=("post-content", "post-title", "post-header") 11 ) 12 ), 13) 14blog_docs = loader.load() 15 16# 切分 17from langchain.text_splitter import RecursiveCharacterTextSplitter 18text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder( 19 chunk_size=300, 20 chunk_overlap=50) 21 22# Make splits 23splits = text_splitter.split_documents(blog_docs) 24 25# 索引 Index 26from langchain_openai import OpenAIEmbeddings 27from langchain_community.vectorstores import Chroma 28vectorstore = Chroma.from_documents(documents=splits, 29 embedding=OpenAIEmbeddings()) 30 31retriever = vectorstore.as_retriever() 32 33 34#### Prompt###### 35from langchain.prompts import ChatPromptTemplate 36 37# Multi Query: Different Perspectives 38# 基于大语言模型把一个问题生产多个问题 39template = """You are an AI language model assistant. Your task is to generate five 40different versions of the given user question to retrieve relevant documents from a vector 41database. By generating multiple perspectives on the user question, your goal is to help 42the user overcome some of the limitations of the distance-based similarity search. 43Provide these alternative questions separated by newlines. Original question: {question}""" 44prompt_perspectives = ChatPromptTemplate.from_template(template) 45 46from langchain_core.output_parsers import StrOutputParser 47from langchain_openai import ChatOpenAI 48 49generate_queries = ( 50 prompt_perspectives 51 | ChatOpenAI(temperature=0) 52 | StrOutputParser() 53 | (lambda x: x.split("\n")) 54) 55 56from langchain.load import dumps, loads 57 58# 合并 唯一化 59def get_unique_union(documents: list[list]): 60 """ Unique union of retrieved docs """ 61 # Flatten list of lists, and convert each Document to string 62 flattened_docs = [dumps(doc) for sublist in documents for doc in sublist] 63 # Get unique documents 64 unique_docs = list(set(flattened_docs)) 65 # Return 66 return [loads(doc) for doc in unique_docs] 67 68# 检索 Retrieve 69question = "What is task decomposition for LLM agents?" 70retrieval_chain = generate_queries | retriever.map() | get_unique_union 71docs = retrieval_chain.invoke({"question":question