记一次部署系列:prometheus配置通过alertmanager进行邮件告警
1、修改配置
首先在prometheus中配置alertmanager地址,并配置告警规则文件,如下,然后重启prometheus。
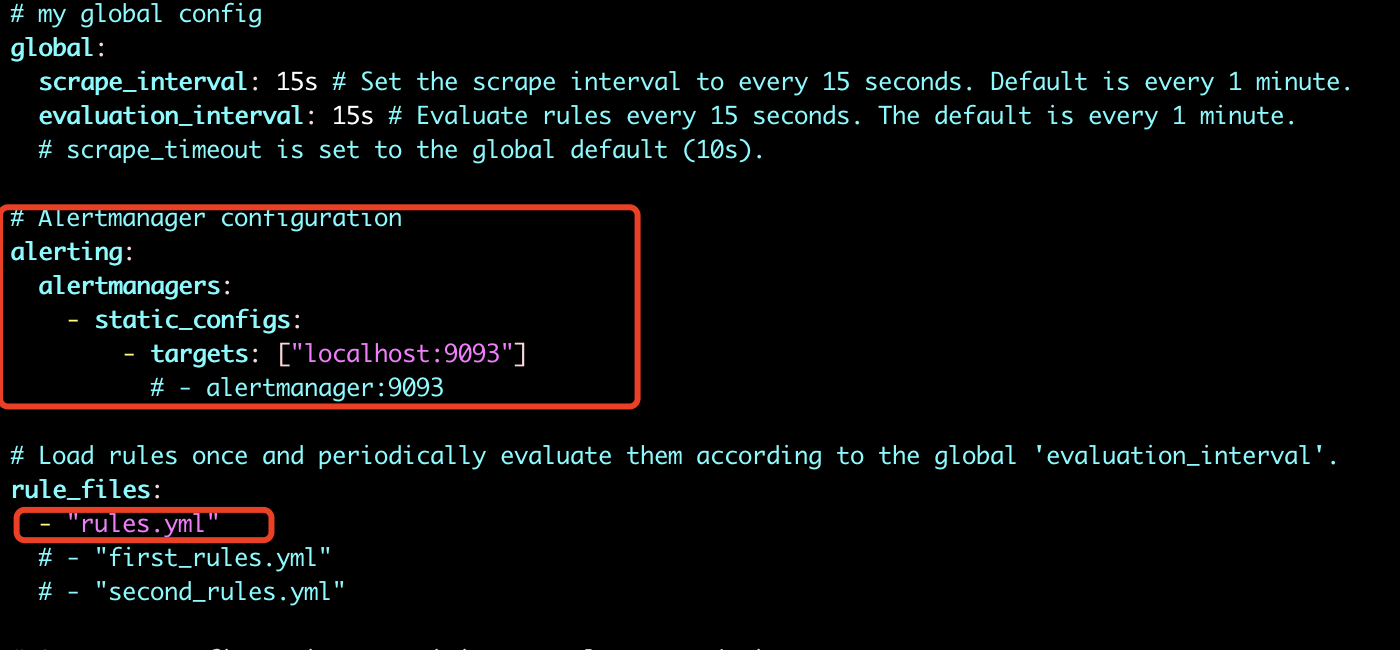
规则文件如下:rules.yml


groups: - name: test-rules rules: - alert: InstanceDown expr: up == 0 for: 2m labels: status: warning annotations: summary: "{{$labels.instance}}: has been down" description: "{{$labels.instance}}: job {{$labels.job}} has been down" - name: base-monitor-rule rules: - alert: NodeCpuUsage expr: (100 - (avg by (instance) (rate(node_cpu{job=~".*",mode="idle"}[2m])) * 100)) > 99 for: 15m labels: service_name: test level: warning annotations: description: "{{$labels.instance}}: CPU usage is above 99% (current value is: {{ $value }}" - alert: NodeMemUsage expr: avg by (instance) ((1- (node_memory_MemFree{} + node_memory_Buffers{} + node_memory_Cached{})/node_memory_MemTotal{}) * 100) > 90 for: 15m labels: service_name: test level: warning annotations: description: "{{$labels.instance}}: MEM usage is above 90% (current value is: {{ $value }}" - alert: NodeDiskUsage expr: (1 - node_filesystem_free{fstype!="rootfs",mountpoint!="",mountpoint!~"/(run|var|sys|dev).*"} / node_filesystem_size) * 100 > 0 #expr: 0 > 1 for: 1m labels: service_name: test level: warning annotations: description: "{{$labels.instance}}: Disk usage is above 0% (current value is: {{ $value }}" - alert: HostOutOfMemory expr: node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100 < 20 for: 2m labels: severity: warning annotations: summary: Host out of memory (instance {{ $labels.instance }}) description: "Node memory is filling up (< 20% left)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}" - alert: NodeFDUsage expr: avg by (instance) (node_filefd_allocated{} / node_filefd_maximum{}) * 100 > 10 for: 2m labels: service_name: test level: warning annotations: description: "{{$labels.instance}}: File Descriptor usage is above 10% (current value is: {{ $value }}" - alert: NodeLoad15 expr: avg by (instance) (node_load15{}) > 100 for: 2m labels: service_name: test level: warning annotations: description: "{{$labels.instance}}: Load15 is above 100 (current value is: {{ $value }}" - alert: NodeAgentStatus expr: avg by (instance) (up{}) == 0 for: 2m labels: service_name: test level: warning annotations: description: "{{$labels.instance}}: Node Agent is down (current value is: {{ $value }}" - alert: NodeProcsBlocked expr: avg by (instance) (node_procs_blocked{}) > 100 for: 2m labels: service_name: test level: warning annotations: description: "{{$labels.instance}}: Node Blocked Procs detected!(current value is: {{ $value }}" - alert: NodeTransmitRate expr: avg by (instance) (floor(irate(node_network_transmit_bytes{device="eth0"}[2m]) / 1024 / 1024)) > 100 for: 2m labels: service_name: test level: warning annotations: description: "{{$labels.instance}}: Node Transmit Rate is above 100MB/s (current value is: {{ $value }}" - alert: NodeReceiveRate expr: avg by (instance) (floor(irate(node_network_receive_bytes{device="eth0"}[2m]) / 1024 / 1024)) > 100 for: 2m labels: service_name: test level: warning annotations: description: "{{$labels.instance}}: Node Receive Rate is above 100MB/s (current value is: {{ $value }}" - alert: NodeDiskReadRate expr: avg by (instance) (floor(irate(node_disk_bytes_read{}[2m]) / 1024 / 1024)) > 50 for: 2m labels: service_name: test level: warning annotations: description: "{{$labels.instance}}: Node Disk Read Rate is above 50MB/s (current value is: {{ $value }}" - alert: NodeDiskWriteRate expr: avg by (instance) (floor(irate(node_disk_bytes_written{}[2m]) / 1024 / 1024)) > 50 for: 2m labels: service_name: test level: warning annotations: description: "{{$labels.instance}}: Node Disk Write Rate is above 50MB/s (current value is: {{ $value }}"
]# systemctl restart prometheus ]# systemctl status prometheus
然后修改alertmanager配置文件,添加邮箱相关信息,如下图,然后重启alertmanager

]# systemctl restart alertmanager ]# systemctl status alertmanager
2、访问prometheus查看规则
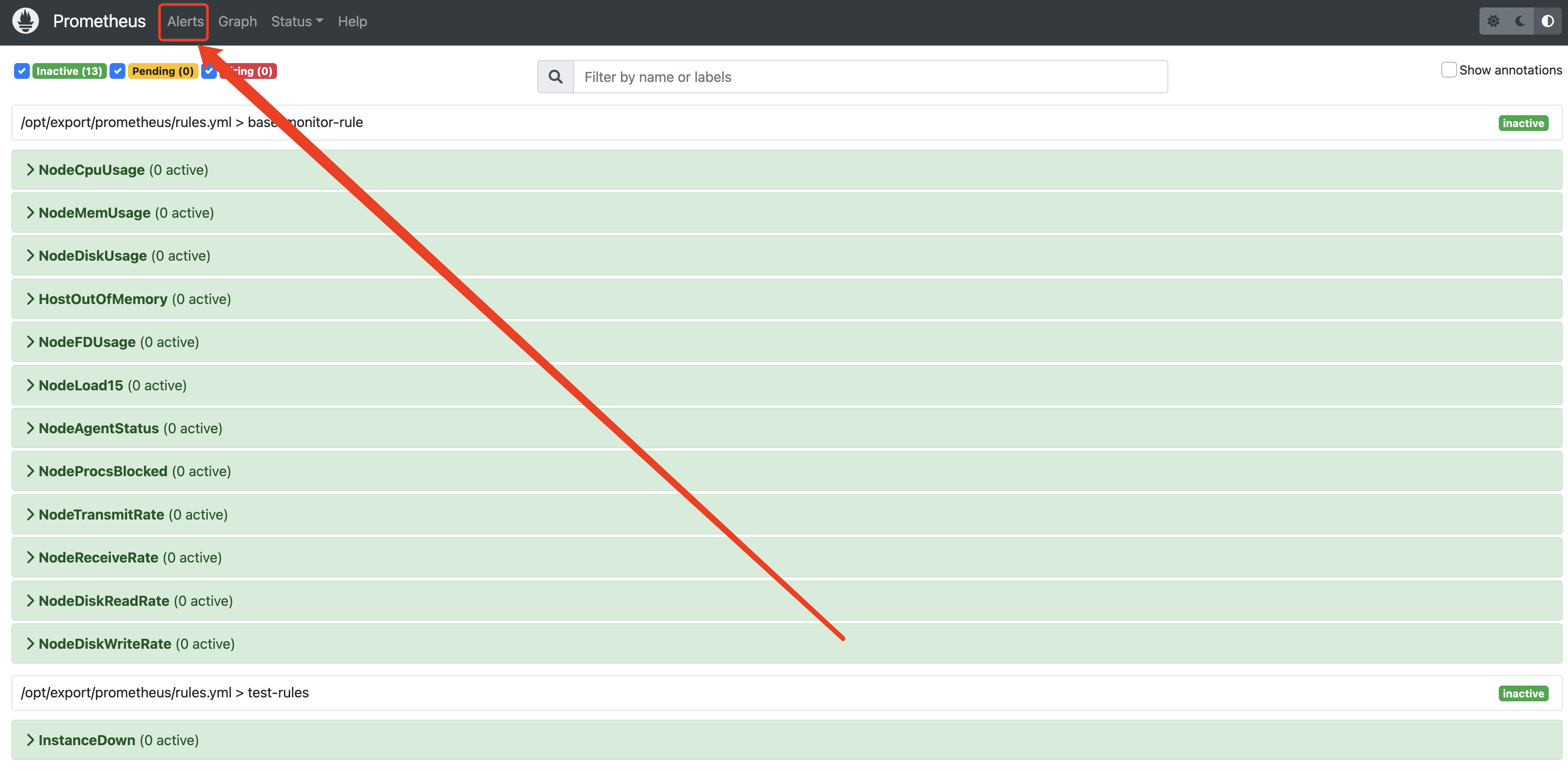
3、测试
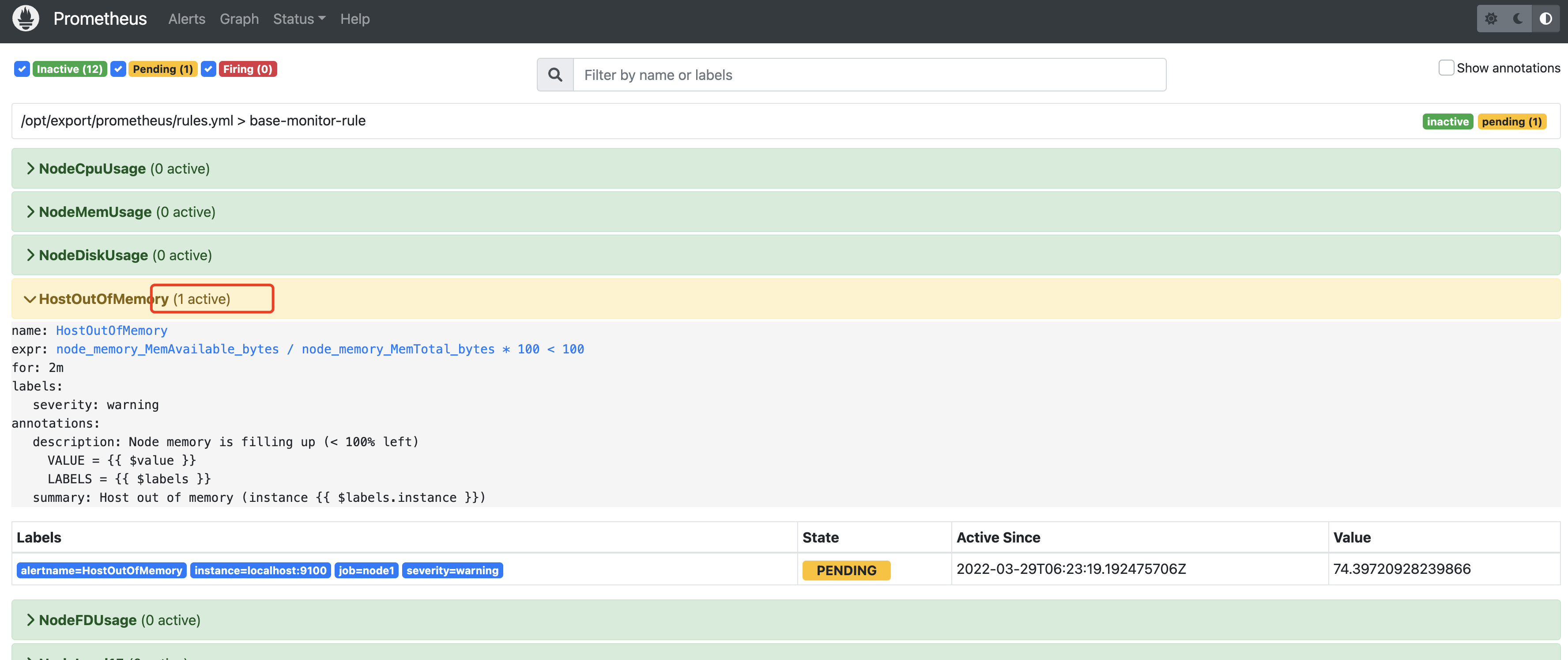
修改规则,以触发邮件告警。修改rules.yml中的内存监控部分,如下。然后重启prometheus

]# systemctl restart prometheus ]# systemctl status prometheus
再次访问prometheus查看规则
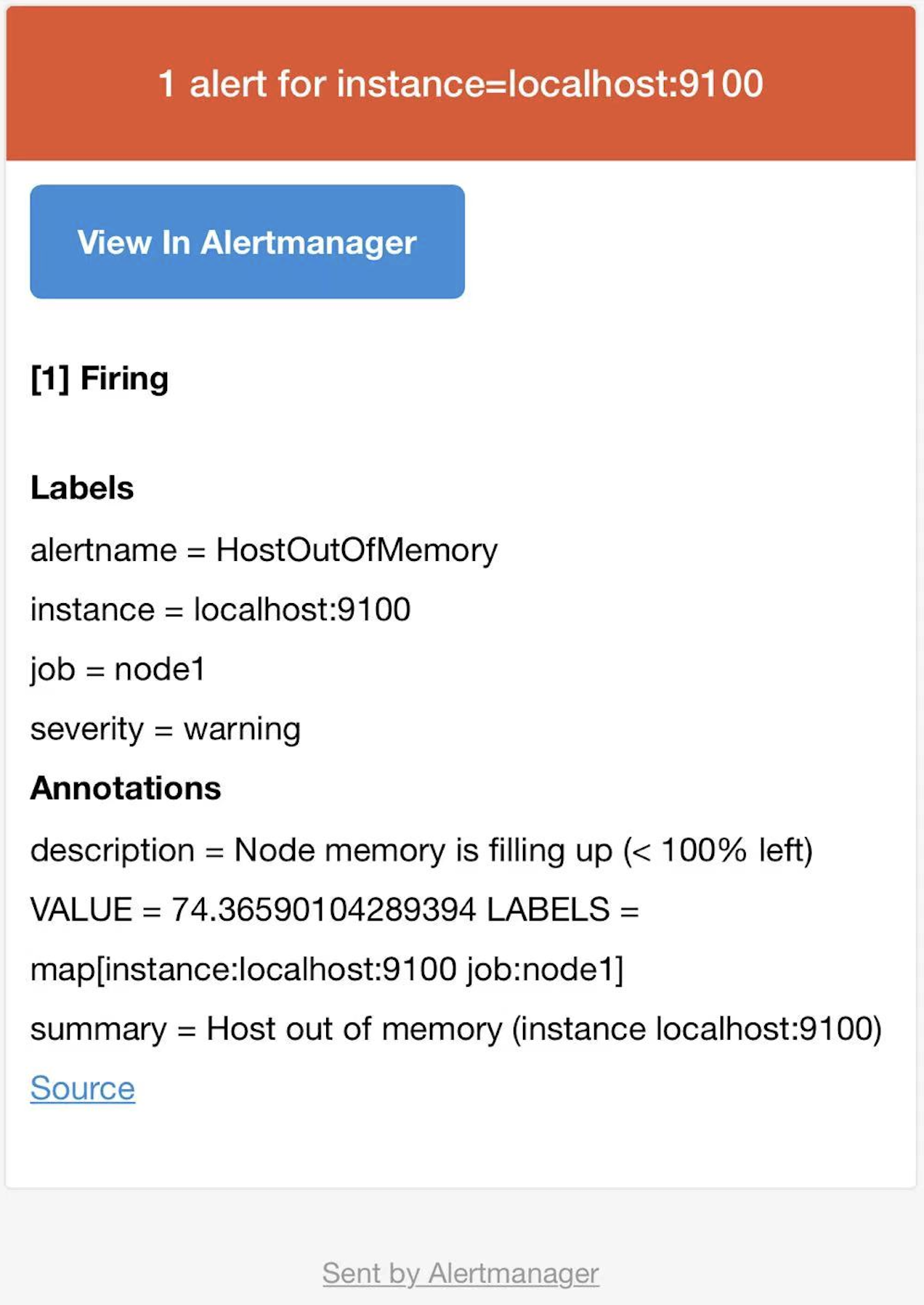
稍等一下,检查邮箱,收到类似下方的邮件,代表邮件告警配置成功。