ES 中文分词器ik及自定义远程词库
ik分词器安装部署
下载地址:https://github.com/medcl/elasticsearch-analysis-ik
注意es和ik分词器的版本匹配.这里下载7.9.3的ik分词器
下载完毕之后去es的工作目录的plugins文件夹下新建ik文件夹,将下载下来的ik压缩包解压缩至ik文件夹下,重启e
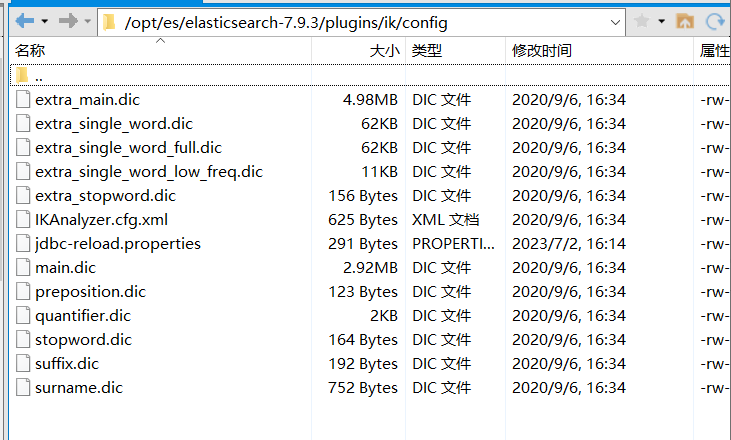
词库介绍
ik分词器主要有以下词库,位于config目录下
(1)、main.dic 主词库,包含日常生活中常用的词
(2)、stopword.dic 英文停用词,当出现该词库中的文本内容时,将不会建立倒排索引
(3)、quantifier.dic 计量单位等
(4)、suffix.dic 后缀名、行政单位等
(5)、surname.dic 百家姓等
(6)、preposition.dic 语气词等
IK中文分词器插件给我们提供了两个分析器
ik_max_word : 会将文本做最细粒度的拆分
ik_smart:会做最粗粒度的拆分
创建索引时指定IK分词器
PUT ik_index { "mappings": { "properties": { "id": { "type": "long" }, "title": { "type": "text", "analyzer": "ik_max_word" } } } }
为索引指定默认IK分词器
PUT ik_index { "settings": { "analysis": { "analyzer": { "default": { "type": "ik_max_word" } } } } }
自定义热词配置介绍
热词配置方式
(1)、自定义文件
(2)、自定义接口
(3)、基于远程数据库
基于自定义文件
IKAnalyzer.cfg.xml ik配置文件位于config目录下,可在此文件配置自定义热词、停词

手动配置
一般情况下,词库是够用的,但是如果碰到一些特殊词汇如网络用词,这个时候就需要手动添加相关的词汇进入到词库中.ik添加自定义词库的步骤如下
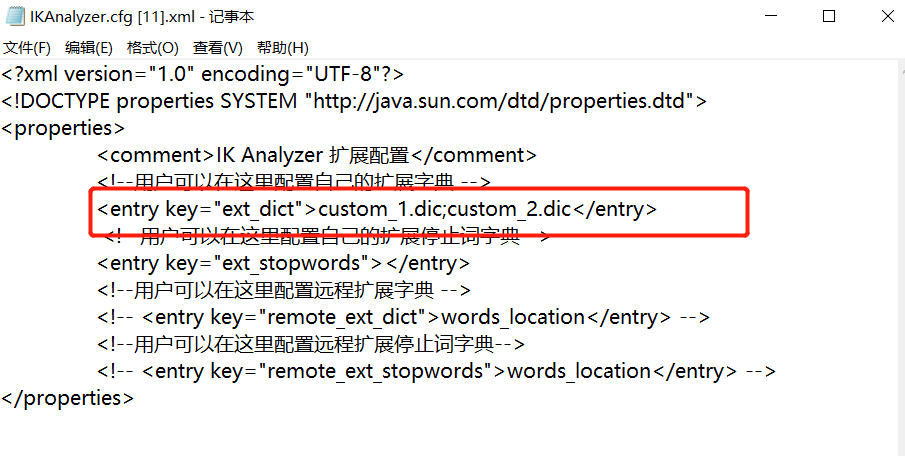
(1)、在config目录下,新增自定义词库文件

(2)、将新增的文件配置的到IKAnalyzer.cfg.xml
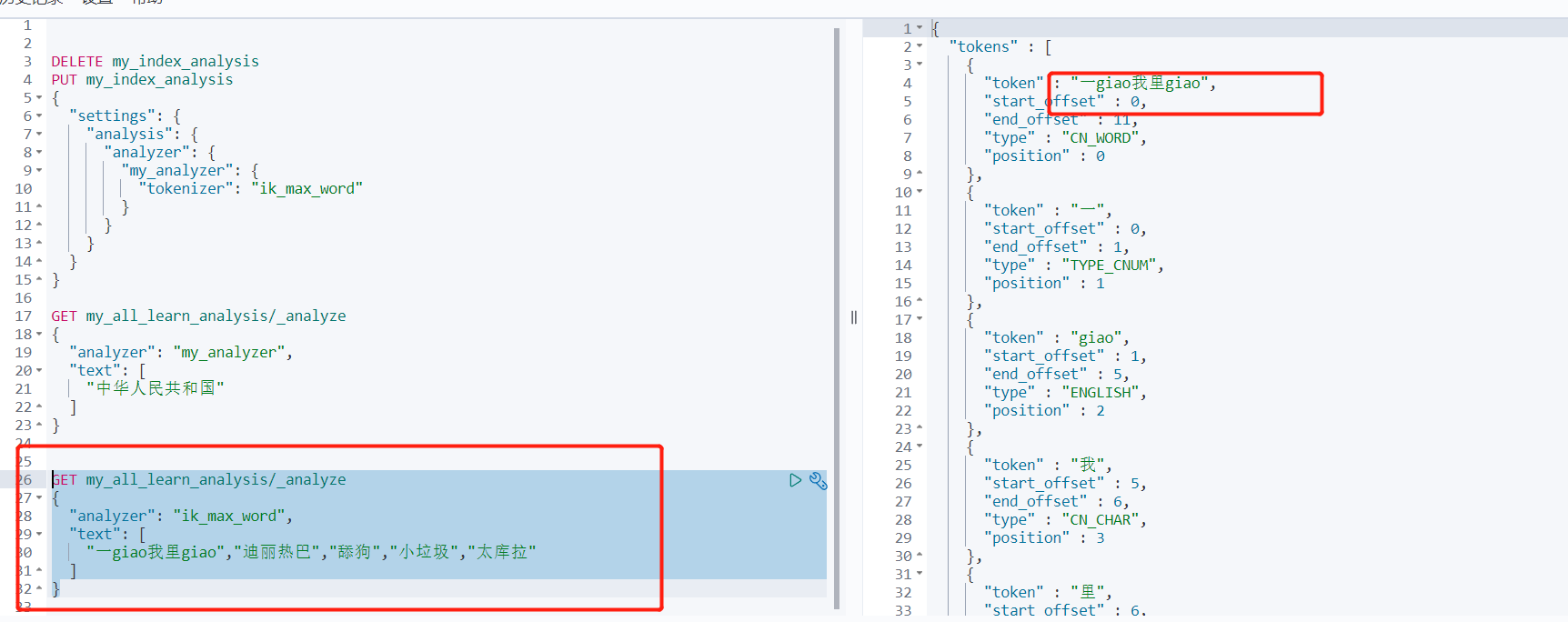
(3)、效果测试
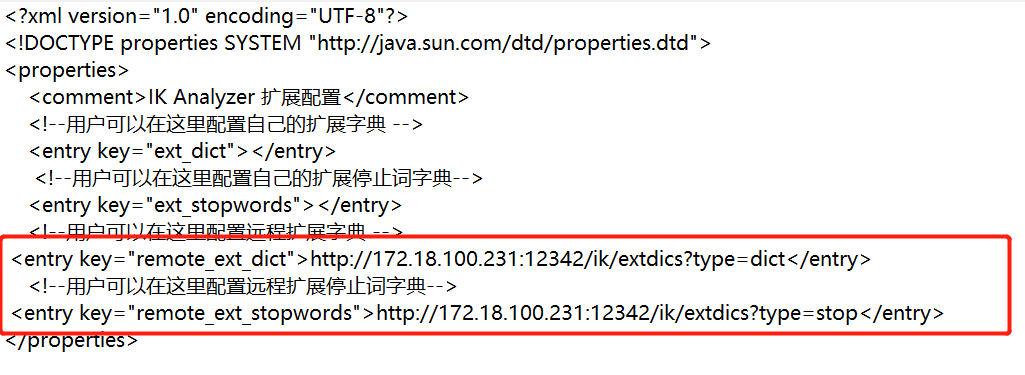
基于自定义接口
自定义接口方式类似于自定义文件方式
基于数据库方式
(1)、gitHub拉去es对应版本的ik分词代码
(2)、打开项目并增加连接代码
(3)、ik分词项目打包
(4)、上jar文件到指定位置
gitHub拉去es对应版本的ik分词代码
ik分词地址:https://github.com/medcl/elasticsearch-analysis-ik/releases?page=7
打开项目并增加连接代码
1.在项目config文件下新增jdbc-reload.properties文件
jdbc.url=jdbc:mysql://192.168.225.1:3306/my_ik?serverTimeZone=UFT&useSSL=false jdbc.user=root jdbc.password=123456 # 更新词库 jdbc.reload.sql=select word from es_ik_extensions_word # 更新停用词词库 jdbc.reload.stopword.sql=select word from es_ik_stop_word jdbc.reload.interval=1000
2.新增一个线程类HotDicReloadThread用于循环调用,在词典管理类Dictionary文件下找到loadMainDict(加载主词典及扩展词典)并新增方法loadMySqlExtDict,然后将HotDicReloadThread天加到init方法
public class HotDicReloadThread implements Runnable{ private static final org.apache.logging.log4j.Logger logger = ESPluginLoggerFactory.getLogger(Dictionary.class.getName()); @Override public void run() { while (true){ logger.info("-------重新加载mysql词典--------"); Dictionary.getSingleton().reLoadMainDict(); } } }
/** * 加载主词典及扩展词典 */ private void loadMainDict() { // 建立一个主词典实例 _MainDict = new DictSegment((char) 0); // 读取主词典文件 Path file = PathUtils.get(getDictRoot(), Dictionary.PATH_DIC_MAIN); loadDictFile(_MainDict, file, false, "Main Dict"); // 加载扩展词典 this.loadExtDict(); // 加载远程自定义词库 this.loadRemoteExtDict(); // 加载远程数据库自定义词库 this.loadMySqlExtDict(); }
/** * 加载远程数据库词典到主词库表 */ private void loadMySqlExtDict() { Connection connection = null; Statement statement = null; ResultSet resultSet = null; try { Path file = PathUtils.get(getDictRoot(), "jdbc-reload.properties"); prop.load(new FileInputStream(file.toFile())); logger.info("-------jdbc-reload.properties-------"); for (Object key : prop.keySet()) { logger.info("key:{}", prop.getProperty(String.valueOf(key))); } logger.info("------- 查询词典, sql:{}-------", prop.getProperty("jdbc.reload.sql")); // 建立mysql连接 connection = DriverManager.getConnection( prop.getProperty("jdbc.url"), prop.getProperty("jdbc.user"), prop.getProperty("jdbc.password") ); // 执行查询 statement = connection.createStatement(); resultSet = statement.executeQuery(prop.getProperty("jdbc.reload.sql")); // 循环输出查询啊结果,添加到Main.dict中去 while (resultSet.next()) { String theWord = resultSet.getString("word"); if (theWord != null && !"".equals(theWord.trim())) { logger.info("------热更新词典:{}------", theWord); // 加到mainDict里面 _MainDict.fillSegment(theWord.trim().toCharArray()); } } Thread.sleep(Integer.valueOf(String.valueOf(prop.get("jdbc.reload.interval")))); } catch (Exception e) { logger.error("error:{}", e); } finally { try { if (resultSet != null) { resultSet.close(); } if (statement != null) { statement.close(); } if (connection != null) { connection.close(); } } catch (SQLException e) { logger.error("error", e); } } }
/** * 词典初始化 由于IK Analyzer的词典采用Dictionary类的静态方法进行词典初始化 * 只有当Dictionary类被实际调用时,才会开始载入词典, 这将延长首次分词操作的时间 该方法提供了一个在应用加载阶段就初始化字典的手段 * * @return Dictionary */ public static synchronized void initial(Configuration cfg) { if (singleton == null) { synchronized (Dictionary.class) { if (singleton == null) { singleton = new Dictionary(cfg); singleton.loadMainDict(); singleton.loadSurnameDict(); singleton.loadQuantifierDict(); singleton.loadSuffixDict(); singleton.loadPrepDict(); singleton.loadStopWordDict(); // 执行更新mysql词库的线程 new Thread(new HotDicReloadThread()).start(); if(cfg.isEnableRemoteDict()){ // 建立监控线程 for (String location : singleton.getRemoteExtDictionarys()) { // 10 秒是初始延迟可以修改的 60是间隔时间 单位秒 pool.scheduleAtFixedRate(new Monitor(location), 10, 60, TimeUnit.SECONDS); } for (String location : singleton.getRemoteExtStopWordDictionarys()) { pool.scheduleAtFixedRate(new Monitor(location), 10, 60, TimeUnit.SECONDS); } } } } } }
3.配置自定义的数据库热词
在/opt/es/elasticsearch-7.9.3/plugins/ik/config新增jdbc-reload.properties并新增内容同项目的jdbc-reload.properties
jdbc.url=jdbc:mysql://192.168.225.1:3306/my_ik?serverTimeZone=UFT8&useSSL=false jdbc.user=root jdbc.password=123456 # 更新词库 jdbc.reload.sql=select word from es_ik_extensions_word # 更新停用词词库 jdbc.reload.stopword.sql=select word from es_ik_stop_word jdbc.reload.interval=1000
将打包后的elasticsearch-analysis-ik-7.9.3.jar放入目录下
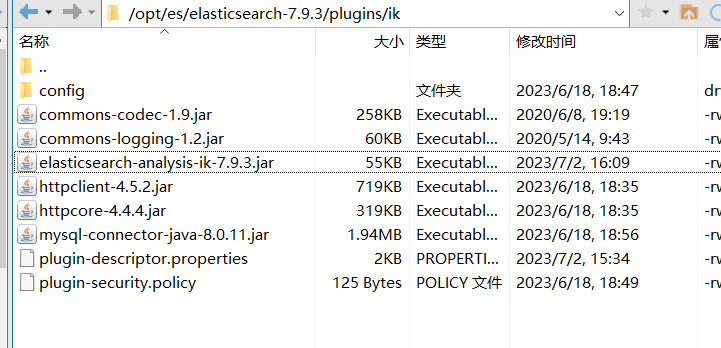
重启es可以看到读取到数据的内容
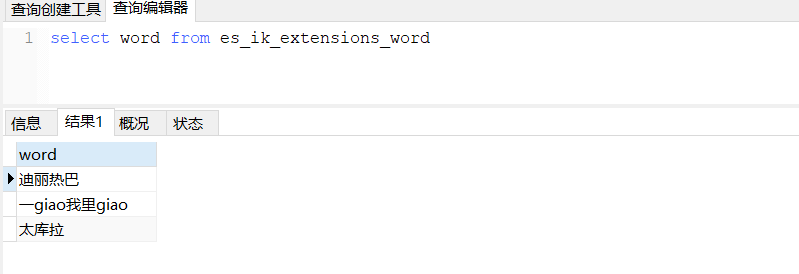

效果测试


 浙公网安备 33010602011771号
浙公网安备 33010602011771号