分布式事务解决方案总结 - 本地消息表
1,什么是分布式事务?
在传统架构中往往是一个单体架构,一个系统就对应一个war包,然后这个系统也只有一个数据库。即一个应用对应一个数据库,此时能满足传统的数据库事务,满足ACID的强一致性。后来,由于业务需求或其他原因,此时一个应用系统操作两个数据库(虽然这个在微服务规范中是不合理的)即一个应用要操作两个资源,此时就不能用传统的事务了。此时就需要用到分布式事务,XA事务。再到后来,为了解耦或其他原因,此时一个应用系统需要拆分成两个子系统,其中一个系统对应一个库,此时也需要用到分布式事务。
讲到了分布式事务,自然离不开分布式系统的一些基本原则和定理,下面接着来介绍分布式系统的CAP原则和BASE理论。
2,CAP原则
CAP理论描述了分布式系统中的基本原则,其中C是指Consistency(一致性),A是指Availability(可用性)和P是指Partition tolerance(区分容错性)。CAP原则指CAP三者不能同时满足,要么能同时满足CP即同时满足区分容错性和一致性,要么同时满足AP即同时满足区分容错性和可用性。从中可以看出,P是分布式系统的基础,没有区分容错性就谈不上分布式系统了。
CAP只能满足AP或CP的原因是,分布式节点之间通常存在一个数据拷贝的过程,在这一个过程中是只能满足AP或者CP的。举个例子好了,比如redis分布式集群中,当一个写请求打到一个主节点上,几乎同时另一个读请求打到redis这个主节点的对应从节点上,此时请问该从节点能返回刚才写在主节点的数据吗?若要保证CP,此时数据正在从主节点复制到从节点的路上,此时该节点的该数据是不可用的;若要保证AP,因为数据正在从主节点复制到从节点的路上,因此节点间的数据状态是不一致的。
3,BASE理论
前面讲到分布式系统的CAP原则要么同时满足AP要么同时满足CP,那么BASE理论则是CAP原则权衡的结果。BASE是指Basically Available(基本可用的),Soft state(软状态),Eventual consistency(最终一致性)。
Basically Available是指在分布式集群节点中,若某个节点宕机,或者在数据在节点间复制的过程中,只有部分数据不可用,但不影响整个系统的整体的可用性。
Soft state是指软状态即这个状态只是一个中间状态,允许数据在节点集群间操作过程中存在存在一个时延,这个中间状态最终会转化为最终状态。
Eventual consistency是指数据在分布式集群节点间操作过程中存在时延,与ACID相反,最终一致性不是强一致性,在经过一定时间后,分布式集群节点间的数据拷贝能达到最终一致的状态。
4,基于本地消息表常用的分布式事务解决方案
上面提到了分布式系统中要实现强一致性比较困难,往往很多业务场景不要求强一致性,允许有个临时的业务中间状态。因此就可以采用最终一致性的分布式事务方案。
常用的分布式解决方案有实现XA事务的Atomikos,本地消息表方案,基于消息中间件的最终一致性方案,TCC方案,阿里的SEATA,SAGA方案和最大努力通知。下面主要对基于本地消息表实现最终一致性的分布式事务方案进行介绍。
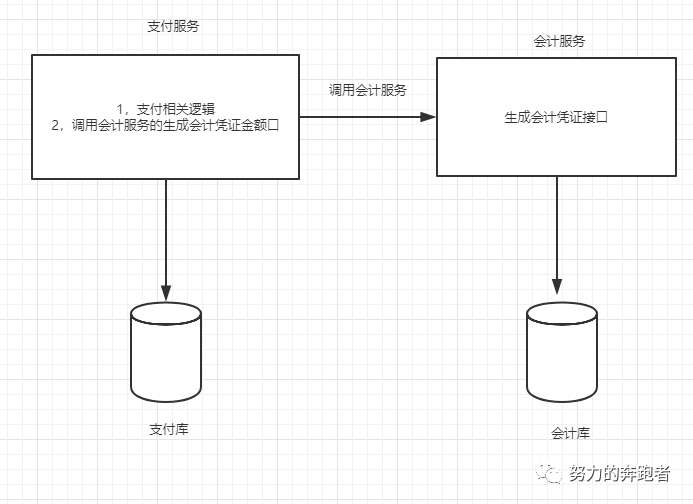
本地消息表方案最初是ebay提出的,其实也是BASE理论的应用,属于可靠消息最终一致性的范畴。这里以支付服务和会计服务为例展开介绍本地消息表方案,大概流程是这样子:用户在支付服务完成了支付订单支付成功后,此时会调用会计服务的接口生成一条原始的会计凭证到数据库中,如图1所示。这里必须明确:支付服务处理完订单支付等逻辑后,此时若直接调用会计服务生成会计凭证数据的接口肯定会遇到分布式事务的问题。
因为用户完成支付后,此时得立马给用户一个支付的反馈,要做的就是提醒用户支付成功。因为会计服务生成的会计凭证保存到数据库的过程中可以对用户透明,用户也无需知道有这么一个流程,为了提高响应速度和解耦,因此可以引入mq来做到异步生成会计凭证,即用户完成支付订单支付后,此时可以将消息投递到mq中,然后会计服务再去监听mq消息去处理消费逻辑。此时如图2:
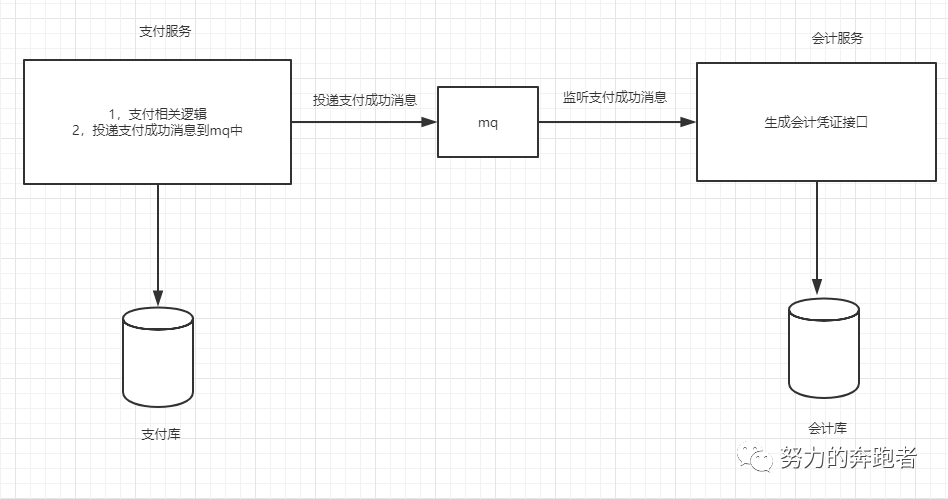
在支付服务和会计服务之间引入mq后,此时又引入了新的问题。大概列举如下:
1,若支付服务完成支付逻辑后,在投递消息到mq中间件的过程中由于网络抖动等原因,没有投递到mq中导致消息丢失了怎么办?
2,mq接收到消息后,由于内部原因导致消息丢失了怎么办?
3,会计服务在监听消息的过程中,由于网络原因没有接收到消息或消费过程中遇到异常,此时也会导致消息丢失,测试怎么办?
经过以上分析,mq可能会丢失消息,传统的mq没有实现分布式事务(注意rocketmq的某些版本有实现分布式事务功能),因此这里可以引入本地消息表结合mq的方式来解决分布式事务的问题,保证消息的可靠投递。
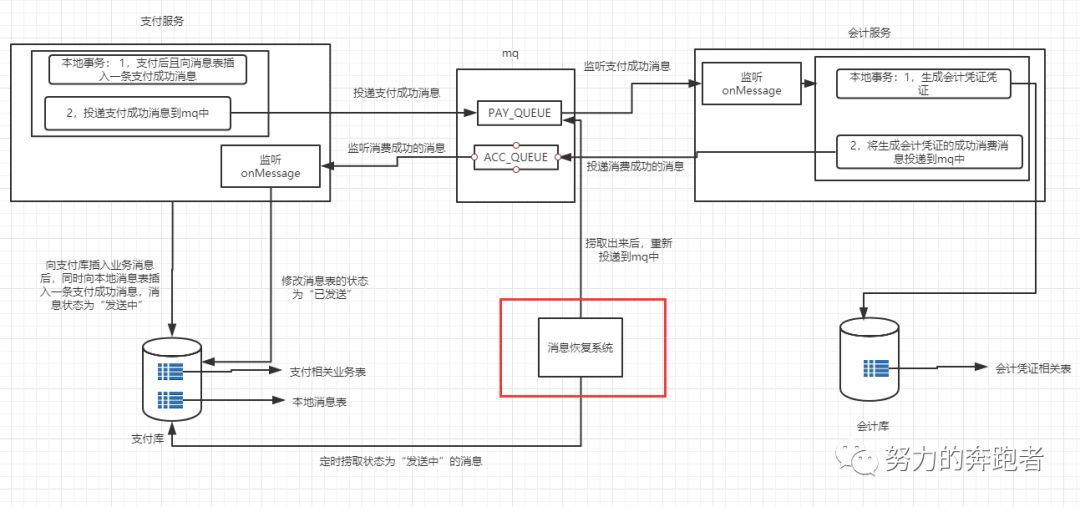
图3是由图2细化后的图,其中红框处引入了一个本地消息表。
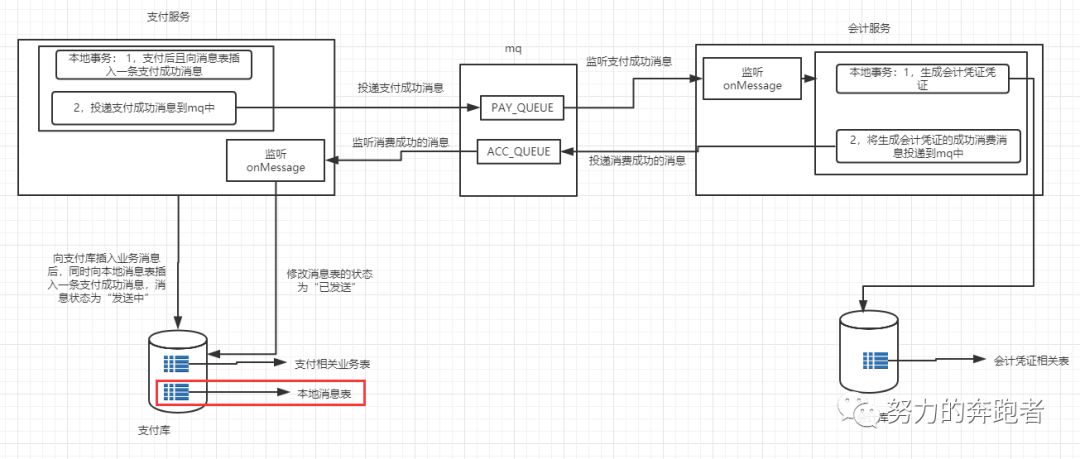
根据图3,正向流程步骤大概如下:
1)在支付库中引入一张消息表来记录支付消息,即用户支付成功后同时往这张消息表插入一条支付成功的消息,状态为“发送中”。注意支付逻辑和插入消息表的代码要包裹在一个事务里面,这里保证了本地事务的强一致性。即支付逻辑和插入消息表的消息组成了一个强一致性的事务,要么同时成功,要么同时失败。
2)完成 1)步的逻辑后,此时再向mq的PAY_QUEUE队列中投递一条支付消息,这条支付消息的内容跟保存在支付库消息表的消息内容一致。
3)mq接收到消息后,此时会计服务也监听到这条消息了,此时会计服务处理消费逻辑即开始生成会计凭证。
4)会计凭证生成后,再反向向mq投递一条消费成功的消息到ACC_QUEUE队列
5)同时支付服务又来监听这个会计服务消费成功的消息,当支付服务监听到这个消费成功的消息后,此时再将本地消息表的消息状态改为“已发送”。
6)经过前面5步后,整个业务就已经完成了。
以上是引入本地消息表后的正常的业务流程,前文分析过生产者,mq和消费者三个环节中都可能弄丢消息,即图4中的红框处可能会造成消息丢失。
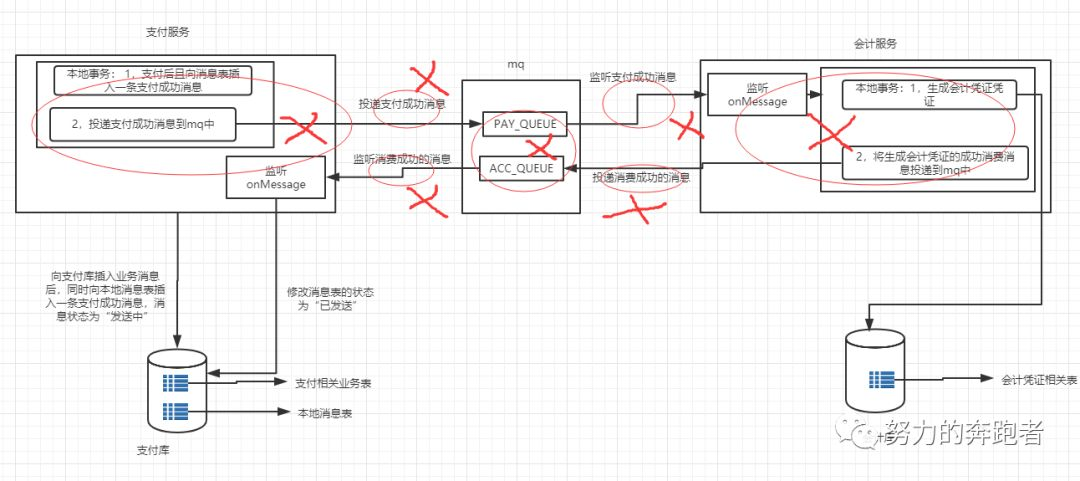
此时可能你会有个疑问:用户支付成功后,若消息在投递过程中丢失了就丢失了,会计服务那边也消费不到了,此时同样也会造成支付服务(生产者)和会计服务(消费者)之间的数据不一致。
之前增加的本地消息表好像也没起作用啊?
那此时怎么办呢?如何来解决消息丢失的问题,做到消息的可靠投递呢?
其实解决方案就是消息重复投递,但消费者的消费接口要实现幂等性。
怎么来让消息重复投递呢?此时本地消息表就派上用场了,刚才我们在支付库中新增加了一张本地消息表,即支付等逻辑处理成功,这张本地消息表也会记录一条记录,此时的消息状态是“发送中”。若第一次生产者投递的消息丢失后,此时我们只要将这张本地消息表状态为“发送中”的消息重新投递即可,直到消费者消费成功为止,消费者消费成功后将这条消息的状态改为“已发送”即可。
因此为了能将丢失后的消息重发,此时我们引入一个定时任务好了,暂且叫它“消息恢复系统”吧,如下图所示。这个消息恢复系统就是每隔一段时间去本地消息表中捞取状态为“发送中”的消息,然后重新投递到mq中间件中,然后消费者就会重新消费了。若消费者已经消费过了,此时就不再处理消费业务逻辑,直接反向投递一条消费成功的消息到mq中,此时原来的生产者此时也会监听这条消费成功的消息,将本地消息表的消息状态改为“已发送”,此时消息恢复系统就不会再去捞取这条状态为“已发送”的消息,然后进行重新投递了。
此时若消息丢失后且消息恢复系统在重新投递过程中,也可能会再次投递失败。此时我们一般会指定最大重试次数,重试间隔时间根据重试次数而线性增长。若达到最大重试次数后,同时记录日志,我们可以根据记录的日志来通过邮件或短信来发送告警通知,接收到告警通知后及时介入人工处理即可。
基于本地消息表的分布式事务方案就介绍到这里了,本地消息表的方案的优点是建设成本比较低,其虽然实现了可靠消息的传递确保了分布式事务的最终一致性,其实它也有一些缺陷:
1)本地消息表与业务耦合在一起,难于做成通用性,不可独立伸缩。
2)本地消息表是基于数据库来做的,而数据库是要读写磁盘IO的,因此在高并发下是有性能瓶颈的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号