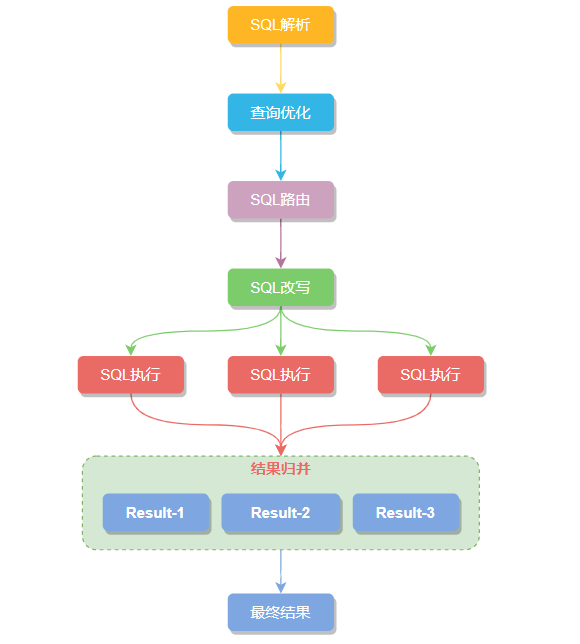
SQL执行和结果归并
一:SQL解析
一张表经过分库分表后被拆分成多个子表,并分散到不同的数据库中,在不修改原业务 SQL 的前提下,Sharding-JDBC 就必须对 SQL进行一些改造才能正常执行。
大致的执行流程:SQL 解析 -> 执⾏器优化 -> SQL 路由 -> SQL 改写 -> SQL 执⾏ -> 结果归并 六步组成,一起瞅瞅每个步骤做了点什么。
二:SQL执行
Sharding-JDBC采用一套自动化的执行引擎,负责将路由和改写完成之后的真实SQL安全且高效发送到底层数据源执行。 它不是简单地将SQL通过JDBC直接发送至数据源执行;也并非直接将执行请求放入线程池去并发执行。它更关注平衡数据源连接创建以及内存占用所产生的消耗,以及最大限度地合理利用并发等问题。 执行引擎的目标是自动化的平衡资源控制与执行效率,他能在以下两种模式自适应切换:
1. 内存限制模式
使用此模式的前提是,Sharding-JDBC对一次操作所耗费的数据库连接数量不做限制。 如果实际执行的SQL需要对某数据库实例中的200张表做操作,则对每张表创建一个新的数据库连接,并通过多线程的方式并发处理,以达成执行效率最大化。
2. 连接限制模式
使用此模式的前提是,Sharding-JDBC严格控制对一次操作所耗费的数据库连接数量。 如果实际执行的SQL需要对某数据库实例中的200张表做操作,那么只会创建唯一的数据库连接,并对其200张表串行处理。 如果一次操作中的分片散落在不同的数据库,仍然采用多线程处理对不同库的操作,但每个库的每次操作仍然只创建一个唯一的数据库连接。
3.⾃动化执⾏引擎
ShardingSphere 最初将使⽤何种模式的决定权交由⽤户配置,让开发者依据⾃⼰业务的实际 场景需求选择使⽤内存限制模式或连接限制模式。
为了降低⽤户的使⽤成本以及连接模式动态化这两个问题,ShardingSphere 提炼出⾃动化执 ⾏引擎的思路,在其内部消化了连接模式概念。 ⽤户⽆需了解所谓的内存限制模式和连接限 制模式是什么,⽽是交由执⾏引擎根据当前场景⾃动选择最优的执⾏⽅案。
⾃动化执⾏引擎将连接模式的选择粒度细化⾄每⼀次 SQL 的操作。 针对每次 SQL 请求,⾃ 动化执⾏引擎都将根据其路由结果,进⾏实时的演算和权衡,并⾃主地采⽤恰当的连接模式 执⾏,以达到资源控制和效率的最优平衡。 针对⾃动化的执⾏引擎,⽤户只需配置 maxConnectionSizePerQuery 即可,该参数表示⼀次查询时每个数据库所允许使⽤的最⼤连接数。
在 maxConnectionSizePerQuery 允许的范围内,当⼀个连接需要执⾏的请求数量⼤于 1 时,意味着当前的数据库连接⽆法持有相应的数据结果集,则必须采⽤内存归并; 反之,当 ⼀个连接需要执⾏的请求数量等于 1 时,意味着当前的数据库连接可以持有相应的数据结果集,则可以采⽤流式归并。 每⼀次的连接模式的选择,是针对每⼀个物理数据库的。也就是说,在同⼀次查询中,如果 路由⾄⼀个以上的数据库,每个数据库的连接模式不⼀定⼀样,它们可能是混合存在的形态。 (当用户设置的maxConnectionSizePerQuery / 所有需在该数据库上执行的SQL数量 等于 0或1 时,则会采用 内存限制模式 如果大于1则会采用 连接限制模式)
内存限制模式适用于OLAP(联机分析处理,分部署数据库,多数据源,主要进行数据分析) 操作,可以通过放宽对数据库连接的限制提升系统吞吐量;
连接限制模式适用于OLTP(在线/联机事务处理,主要是对数据库中的数据进行增删改查)操作,OLTP通常带有分片键,会路由到单一的分片,因此严格控制数据库连接,以保证在线系统数据库资源能够被更多的应用所使用,是明智的选择。
三、结果归并
将从各个数据节点获取的多数据结果集,组合成为一个结果集并正确的返回至请求客户端,称为结果归并。
Sharding-JDBC支持的结果归并从功能上可分为遍历、排序、分组、分页和聚合5种类型,它们是组合而非互斥的关系。
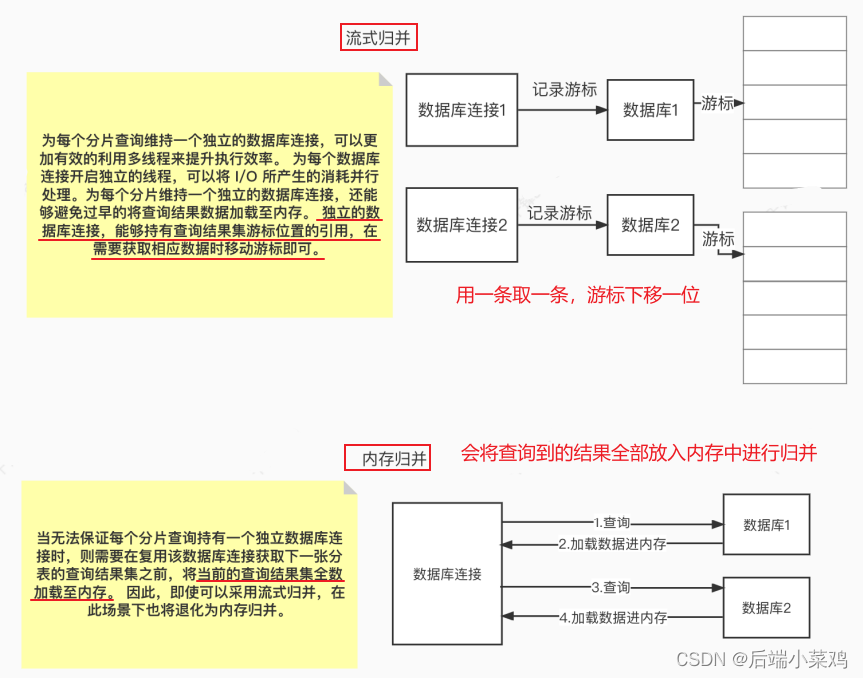
归并引擎的整体结构划分如下图。

结果归并从结构划分可分为流式归并、内存归并和装饰者归并。流式归并和内存归并是互斥的,装饰者归并可以在流式归并和内存归并之上做进一步的处理。
1. 内存归并
内存归并很容易理解,他是将所有分片结果集的数据都遍历并存储在内存中,再通过统一的分组、排序以及聚合等计算之后,再将其封装成为逐条访问的数据结果集返回。
2. 流式归并
流式归并是指每一次从数据库结果集中获取到的数据,都能够通过游标逐条获取的方式返回正确的单条数据,它与 数据库原生的返回结果集的方式最为契合。
下边举例说明排序归并的过程,如下图是一个通过分数进行排序的示例图,它采用流式归并方式。
图中展示了3张表返回的数据结果集,每个数据结果集已经根据分数排序完毕,但是3个数据结果集之间是无序的。 将3个数据结果集的当前游标指向的数据值进行排序,并放入优先级队列,t_score_0的第一个数据值最大,t_score_2的第一个数据值次之,t_score_1的第一个数据值最小,因此优先级队列根据t_score_0,t_score_2和t_score_1的方式排序队列。

下图则展现了进行next调用的时候,排序归并是如何进行的。
通过图中我们可以看到,当进行第一次next调用时,排在队列首位的t_score_0将会被弹出队列,并且将当前游标指向的数据值(也就是100)返回至查询客户端, 并且将游标下移一位之后,重新放入优先级队列。 而优先级队列也会根据t_score_0的当前数据结果集指向游标的数据值(这里是90)进行排序,根据当前数值,t_score_0排列在队列的最后一位。 之前队列中排名第二的 t_score_2的数据结果集则自动排在了队列首位。
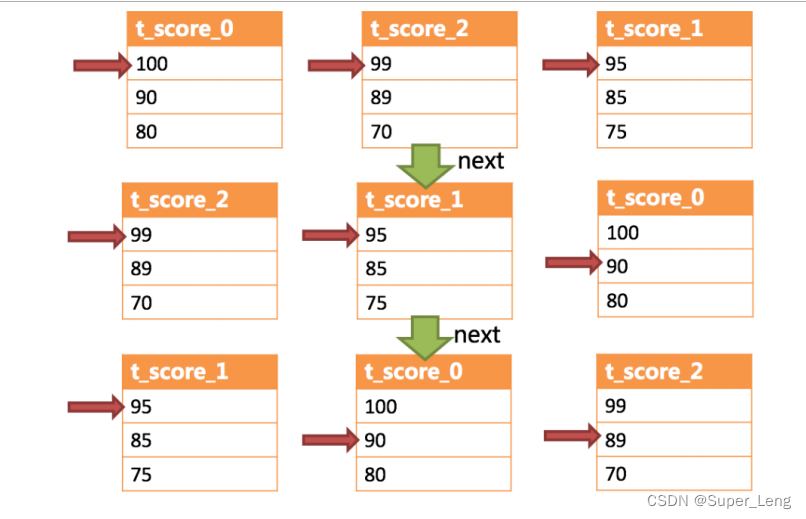
在进行第二次next时,只需要将目前排列在队列首位的t_score_2弹出队列,并且将其数据结果集游标指向的值返回至客户端,并下移游标,继续加入队列排队,以此类推。 当一个结果集中已经没有数据了,则无需再次加入队列。
看到,对于每个数据结果集中的数据有序,而多数据结果集整体无序的情况下,Sharding-JDBC无需将所有的数据都加载至内存即可排序。 它使用的是流式归并的方式,每次next仅获取唯一正确的一条数据,极大的节省了内存的消耗。
3. 装饰者归并
装饰者归并是对所有的结果集归并进行统一的功能增强,比如归并时需要聚合SUM前,在进行聚合计算前,都会通过内存归并或流式归并查询出结果集。因此,聚合归并是在之前介绍的归并类型之上追加的归并能力,即装饰者模式。
参考:
https://www.cnblogs.com/hongdada/p/16975044.html
https://blog.csdn.net/weixin_53922163/article/details/127701570

 浙公网安备 33010602011771号
浙公网安备 33010602011771号