
布隆过滤器(Bloom Filter)
什么是布隆过滤器:
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
布隆过滤器的优点:
时间复杂度低,增加和查询元素的时间复杂为O(N),(N为哈希函数的个数,通常情况比较小)
保密性强,布隆过滤器不存储元素本身
存储空间小,如果允许存在一定的误判,布隆过滤器是非常节省空间的(相比其他数据结构如Set集合)
布隆过滤器的缺点:
有点一定的误判率,但是可以通过调整参数来降低
无法获取元素本身
很难删除元素
布隆过滤器原理:
Bloom Filter 主要参数 数据量大小 误判率 Hash个数 Bloom Filter大小
数据结构
布隆过滤器它实际上是一个很长的二进制向量和一系列随机映射函数。以Redis中的布隆过滤器实现为例,Redis中的布隆过滤器底层是一个大型位数组(二进制数组)+多个无偏hash函数。
一个大型位数组(二进制数组):

多个无偏hash函数:
无偏hash函数就是能把元素的hash值计算的比较均匀的hash函数,能使得计算后的元素下标比较均匀的映射到位数组中。
如下就是一个简单的布隆过滤器示意图,其中k1、k2代表增加的元素,a、b、c即为无偏hash函数,最下层则为二进制数组。

空间计算
在布隆过滤器增加元素之前,首先需要初始化布隆过滤器的空间,也就是上面说的二进制数组,除此之外还需要计算无偏hash函数的个数。布隆过滤器提供了两个参数,分别是预计加入元素的大小n,运行的错误率f。布隆过滤器中有算法根据这两个参数会计算出二进制数组的大小l,以及无偏hash函数的个数k。
它们之间的关系比较简单:
错误率越低,位数组越长,控件占用较大
错误率越低,无偏hash函数越多,计算耗时较长
增加元素
往布隆过滤器增加元素,添加的key需要根据k个无偏hash函数计算得到多个hash值,然后对数组长度进行取模得到数组下标的位置,然后将对应数组下标的位置的值置为1
通过k个无偏hash函数计算得到k个hash值
依次取模数组长度,得到数组索引
将计算得到的数组索引下标位置数据修改为1
例如,key = Liziba,无偏hash函数的个数k=3,分别为hash1、hash2、hash3。三个hash函数计算后得到三个数组下标值,并将其值修改为1.
如图所示: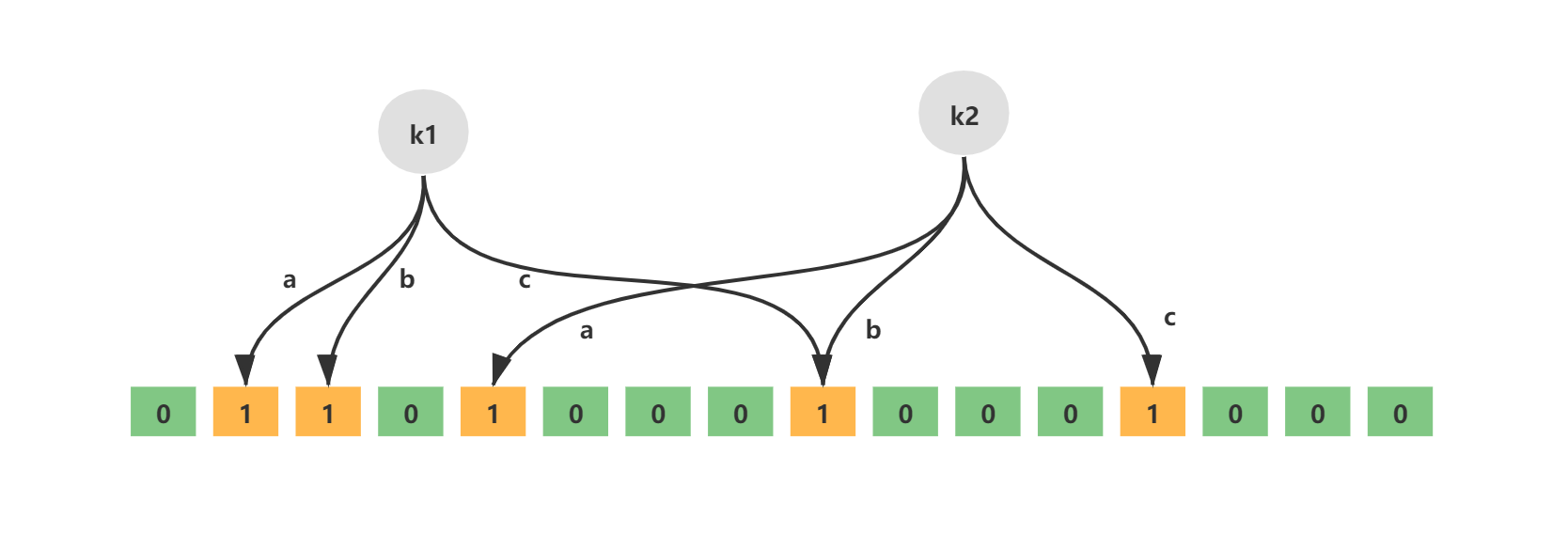
查询元素
布隆过滤器最大的用处就在于判断某样东西一定不存在或者可能存在,而这个就是查询元素的结果。其查询元素的过程如下:
通过k个无偏hash函数计算得到k个hash值
依次取模数组长度,得到数组索引
判断索引处的值是否全部为1,如果全部为1则存在(这种存在可能是误判),如果存在一个0则必定不存在
关于误判,其实非常好理解,hash函数在怎么好,也无法完全避免hash冲突,也就是说可能会存在多个元素计算的hash值是相同的,那么它们取模数组长度后的到的数组索引也是相同的,这就是误判的原因。例如李子捌和李子柒的hash值取模后得到的数组索引都是1,但其实这里只有李子捌,如果此时判断李子柒在不在这里,误判就出现啦!因此布隆过滤器最大的缺点误判只要知道其判断元素是否存在的原理就很容易明白了!
3.5 修改元素
无
3.6 删除元素
布隆过滤器对元素的删除不太支持,目前有一些变形的特定布隆过滤器支持元素的删除!关于为什么对删除不太支持,其实也非常好理解,hash冲突必然存在,删除肯定是很苦难的!
布隆过滤器如何使用
布隆过滤器有很多实现和优化,由 Google 开发著名的 Guava 库就提供了布隆过滤器(Bloom Filter)的实现。在基于 Maven 的 Java 项目中要使用 Guava 提供的布隆过滤器,只需要引入以下坐标
<dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>29.0-jre</version> </dependency>
package com.lizba.bf; import com.google.common.hash.BloomFilter; import com.google.common.hash.Funnels; /** * <p> * 布隆过滤器测试代码 * </p> * * @Author: Liziba * @Date: 2021/8/29 14:51 */ public class BloomFilterTest { /** 预计插入的数据 */ private static Integer expectedInsertions = 10000000; /** 误判率 */ private static Double fpp = 0.01; /** 布隆过滤器 */ private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), expectedInsertions, fpp); public static void main(String[] args) { // 插入 1千万数据 for (int i = 0; i < expectedInsertions; i++) { bloomFilter.put(i); } // 用1千万数据测试误判率 int count = 0; for (int i = expectedInsertions; i < expectedInsertions *2; i++) { if (bloomFilter.mightContain(i)) { count++; } } System.out.println("一共误判了:" + count); } }
Redisson实现布隆过滤器
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.16.0</version>
</dependency>
private void redisConfig(){ Config config = new Config(); // 单机环境 config.useSingleServer().setAddress("redis://172.25.61.39:6933"); //构造Redisson RedissonClient redisson = Redisson.create(config); RBloomFilter<String> bloomFilter = redisson.getBloomFilter("bloom-filter"); //初始化布隆过滤器:预计元素为100000000L,误差率为3%,根据这两个参数会计算出底层的 bit 数组大小 bloomFilter.tryInit(100000L, 0.03); //将 10086 插入到布隆过滤器中 bloomFilter.add("10086"); //判断下面号码是否在布隆过滤器中 System.out.println(bloomFilter.contains("10086"));//true System.out.println(bloomFilter.contains("10010"));//false System.out.println(bloomFilter.contains("10000"));//false }
也可以自定义实现Bloom Filter :
BKDRHASH是一种字符哈希算法,像BKDRHash,APHash,DJBHash,JSHash,RSHash,SDBMHash,PJWHash,ELFHash等等,这些都是比较经典的,通过http://blog.csdn.net/wanglx_/article/details/40300363(字符串哈希函数)这篇文章,我们可知道。
引用:
https://blog.csdn.net/qq_41125219/article/details/119982158
https://www.cnblogs.com/stupidMartian/articles/16388607.html
https://www.cnblogs.com/felixzh/p/16177555.html

