
面试刷题
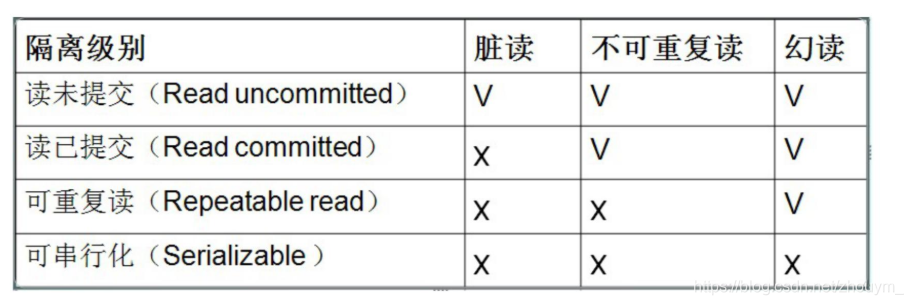
事务的隔离级别
为什么会有隔离级别
事的隔离性就是指,多个并发的事务同时访问一个数据库时,一个事务不应该被另一个事务所干扰,每个并发的事务间要相互进行隔离
1.丢失更新: 丢失更新就是由并发修改数据造成的 可以用排他锁(悲观锁) 和 乐观锁解决
如: 两个事务 同时去查询一条数据 ,并先后 对这条数据进行修改 先修改的数据被后修改的数据 顶掉了,虽然先修改的事务修改成功 但是在未提交事务之前再次查询的时候 得到却不是自己修改后的数据这就是丢失更新 事实上Mysql数据库会在事务里面默认添加写锁,上面的现象是没法重现的。
2.脏读: 一个事务读取到了另一个事务未提交的修改数据 导致前后查询的数据不一样
主要在于读取到别人未提交的数据
3.不可重复读:就是一个事务读到另一个事务修改后并提交的数据
4.幻读:一个事务读取到了另一个事务未提交的删除或插入数据 导致前后查询的数据不一样
1.读未提交 可以解决丢失更新 但是不能解决 脏读 不可重复读 幻读
2.读已提交 可以解决 脏读 但是不能解决 不可重复读 幻读
3.可重复的 可以解决 不可重复读 但是不能解决 幻读
4.序列化 可以解决 所以 但是 效率极低
https://baijiahao.baidu.com/s?id=1611918898724887602&wfr=spider&for=pc
事务传播特性
1.propagation_required 如果当前有事务就加入当前事务 如果当前没有事务就新建一个事务 (required 必须)
2.propagation_support 如果当前有事务就加入当前事务 如果没有就以非事务执行 (support 支持)
3.propagation_mandatory 如果当前有事务就加入当前事务 如果没有就报异常 (mandatory 强制)
4.propagation_required_new 如果当前有事务就把当前事务挂起 新建事务 如果没有也会新建事务
5.propagation_not_supported 如果当前有事务就把当前事务挂起 没有的话就以非实物
6.propagation-never 不支持事务 如果当前有事务就抛异常
7.propagation_nested 如果当前有事务就嵌套到当前事务 没有的话会执行类 propagation-required的操作
sql 优化
where 条件放前面 子查询的优化 in exist like尽量单边
exist优化
查询男性且参加了英语考试
EXISTS式 子查询返回的式布尔值
select id from student st where sex='男'
and EXISTS
(select * from score sc where c_name='英语' and st.id=sc.stu_id);
子查询式
select id from student where sex='男'
and id in
(select stu_id from score sc where c_name='计算机');
where 多表查询 (隐式连接)
select st.id
from student st ,score sc
where st.sex='男' and sc.c_name='计算机' and st.id=sc.stu_id;
inner join on 式 ( xxx join 显式连接)
select st.id , sc.c_name
from student st inner JOIN score sc
on st.sex='男' and sc.c_name='计算机' and st.id=sc.stu_id;
left join 式 左边表为主表 左边的全部信息都可以查出来 对应右表如果有信息则显示 没有则显示null
select st.id , sc.c_name
from student st LEFT JOIN score sc
on st.sex='男' and sc.c_name='计算机' and st.id=sc.stu_id;
where 于 inner join 的区别
where 两表id相同(a.id=b.id)的会创建了两表的笛卡尔积 如果两表中各有 1000条数据
那么查询会先查询出 1000000条数据 然后在根剧 id 进行筛选出1000条数据
inner join 只产生等于ID 的1000条目标结果 增加了效率
有些数据库 会把 where自动转换成 inner join
删除全表数据的两种方法
# 清除全部数据但不清除主键 支持事务回滚
delete from score;
select * from score;
#清除表中所有数据包括主键 不支持事务回滚
truncate score;
把一个表中的数据复制到另一个表中
两表一样的插入
INSERT into student_copy select * from student;
两表不一样 的插入
insert into student_copy select id,name,sex from student;
java中 可以spring Bach 或将数据先放入到一个list中然后再插入到某表
行转列 case when then
当情况什么的时候 然后 结束
# 行转列 id 语文 英语 计算机
select stu_id,
max(case when c_name='中文' then grade end) '中文',
max(case when c_name='英语' then grade end) '英语',
max(case when c_name='计算机' then grade end) '计算机'
from score
group BY stu_id;
聚合函数 和 group by 有聚合函数不一定要有group by 只有当聚合函数和非聚合函数在一起时 需要对聚合函数进行group by
select count from where group by order by having 执行顺序
from->where -> group by ->having->select->count->order by
# 查询参加英语考试且 平均分大于 80的学生 有几人 然后倒叙输出
select stu_id,count(*)
from score
where c_name='英语' GROUP BY stu_id HAVING avg(grade)>88 ORDER BY stu_id DESC;
因为from的表是关联 是从右向左执解析的 where是自上而下执行的
写SQL的时候尽量把小表放在右边 用小表匹配大表
把能筛选出小数据的条件放在where左边 用小表匹配大表
当一个查询语句同时出现了where,group by,having,order by的时候,执行顺序和编写顺序是:
1.执行where xx对全表数据做筛选,返回第1个结果集。
2.针对第1个结果集使用group by分组,返回第2个结果集。
4.针对第2个结集执行having xx进行筛选,返回第3个结果集。
3.针对第3个结果集中的每1组数据执行select xx,有几组就执行几次,返回第4个结果集。
5.针对第4个结果集排序。
Mysql 存储
存储过程
# 没有参数
drop procedure if exists db1;
create procedure db1()
BEGIN
select * from poetry where author='李白';
END
# 有参数
drop procedure if exists db2;
create procedure db2(auth varchar(50))
BEGIN
select * from poetry where author=auth;
END
CALL db2('杜甫');
call db1;
# 有返回值
drop procedure if exists db2;
CREATE PROCEDURE db2(x INT,y INT ,out sum INT)
BEGIN
set sum = x+ y;
END
call db2(1,10,@sum);
SELECT @sum;
# 直接把返回值查询出来
drop procedure if exists db2;
CREATE PROCEDURE db2(x INT,y INT ,out sum INT)
BEGIN
SET sum = x+ y;
select sum;
END
call db2(1,10,@sum);
存储函数
触发器
优点 : 数据库层面 保证数据一致
缺点 : 不便于维护调试 关联的表多 会阻塞
缓存
重写equals 和 hashcode
(五步走)
重写 hashcode
@Override
public int hashCode() {
int result = name.hashCode();
// result = result + 17 * id.hashCode();
result = result + 17 * sex.hashCode();
return result;
}
重写equals 姓名和性别相同就认为是一个人
@Override
public boolean equals(Object obj) {
// 判空
if(obj == null) {
return false;
}
// 判断是否是相同类型 或子类型
if(!(obj instanceof Student)) {
return false;
}
// 自反性
if(obj == this) {
return true;
}
// 类型转换 根据条件重写 equals
Student stu = (Student) obj;
if(this.name==stu.getName()&&this.sex==stu.getSex()) {
return true;
}
return false;
}
// 重写equals 需要重新改hashcode
// 如果不重写hashcode 把一个equals相等的对象放进去HashSet 有可能就得到两个值 与正常情况不符合
// 如 str1.equals(str2) 把他们放进set 应置于一个可以成功 但如果不重写hashcode
会把把str1 srt2 都放进入
// 所以要再重写equals时重写 hashcode
// hashset的底层是根据hashmap实现的 比较set容器内元素是否相等是通过比较对象的hashcode
// set的去重就是先比较hashcode 然后再equals
重写hashcode 不重写 equals 会产生hash碰撞
== 基本数据类型 比较值是否相等 , 比较引用数据类型 比较的是引用指向是否相等
equals
没有重写 比较引用数据类型 比较的是引用指向是否相等
重写后 比较的 内容是否相等
Student stu1 = new Student(1,"张三","男");
Student stu2 = new Student(1,"张三","男");
System.out.println(stu1.hashCode()); // 地址 2018699554
System.out.println(stu2.hashCode()); // 地址 1311053135
证明: 比较的是引用指向是否相等
System.out.println(stu1.equals(stu2)); //没有重写equals 为false
证明: 比较的 内容是否相等
System.out.println(stu1.equals(stu2)); //重写equals 为true
ArrayList和LinkedList
ArrayList : 底层是数组结构 数组初始默认大小 10 1.5倍扩容 查询更新效率高 遵循放入顺序
添加 :ArrayList默认从第一个索引开始储存,当添加元素时是添加到上一个索引位置后面的,
当指定index插入时是将当前位置后所有元素复制,逐一复制给后面位置的索引,
当前index空出来,就可以插入数据了
删除:删除元素时指定 index 是将当前位置后的所有元素复制,逐一复制给前一位位置的索引
查询:删除 可以根据索引位置直接定位
扩容 :当数据大小已经超过原来容量,会新增一个原来1.5倍的数组,将来原来数组的数据赋值到新数组 , 然后将新数组赋值给原来的对象。
LinkedList : 底层是双向链表表 ,数据可以从链表两头插入, 插入删除效率高
链表是由Node节点组成的,每个节点都有自己的头指针,数据和尾指针,头指针指向前一个节点 , 尾指针执行后一个节点,
插入:删除:修改头尾指针的指向就好,
查询和更新,需要先进行链表长度折中,然后判断节点是在左边还是右边,然后遍历数据进行操作
ArrayList和LinkeList占用空间大小
LinkedList的Node存储结构邮三部分组成似乎更占空间 ,ArrayList是1.5倍扩容,当数据量很大的时候,占用空间里也会很大,未填充数据的空间就会造成浪费,当数据量大的时候,ArrayLisy占用空间不一定会比LinkedList小
TreeSet
TreeSet有序但是创建时需要自定义定义排序规则,需要Comparable 接口,不允许保持NULL
判断元素是否重复使用 e1.compareTo(e2) 返回结果为0时,认为e1、e2重复
HashSet
-
HashSet底层实现是hashMap
-
去重先比较hashcode,然后在比较equal,
-
value static final PRESENT
-
扩容机制和hashMap一样 16,0.75 ,2(初始容量16,利用率达到0.75,扩容两倍)
-
add的时候调用的是hashMap的put(key,PRESENT);方法。
-
允许保持NULL
-
HashMap和HashTable
HashMap: K,V对结构 线程不安全 扩容机制16,0.75 ,2(初始容量16,利用率达到0.75,扩容两倍)
HashTable : K,V对结构 线程安全,初始容量可以使用默认(11,0.72,n*2+1)的也可以自定义,每个方法都加了synchronized关键字,效率低于HashMap
ConcurrentHashMap
ConcurrentHashMap虽然也是线程安全的,它的效率比Hashtable要高好多倍,
JDK1.7: ConcurrentHashMap使用了分段锁,是将HashMap进行分割,将哈希数组分成一个个小数组,每个数组由N个HashEntry组成,每个数组小数组都继承了ReenTrantLock(可重入锁),这个小数组叫segment。
JDK1.8:ConcurrentHashMap 取消分段锁,变成CAS + Synchronized 来保证数据安全。
static final class HashEntry<K,V> { // 是一个类,用来分装映射表的键值对
final K key;
final int hash;
volatile V value;
final HashEntry<K,V> next;
}

线程安全的集合:
线程安全的集合:
Vector HashTable
java .util.concurrent包下的
ConcurrentHashMap 支持高并发、高吞吐量的线程安全HashMap实现,其实现原理是JDK1.7锁分离机制 1.8是CAS+ Synchronized
ConcurrentSkipListMap (底层跳数)
ConcurrentSkipListSet 是线程安全的有序的集合,适用于高并发的场景
ConcurrentLinkedQueue
写数组的copy
CopyOnWriteArrayList Write的时候总是要Copy
CopyOnWriteArraySet
Atomic 线程安全 但是底层是乐观锁实现的
所有线程安全的集合都是悲观锁实现 置于Atomic是乐观锁实现的
乐观锁悲观锁
乐观锁 : 乐观锁认为,在自己修改数据的过程不会有别的线程进行数据修改,所以对数据不加锁,但是进行数据修改之前,会进行一次数据判断,判断这个数据有没有修改,如果没有修改就,才会更新这个值。
悲观锁 : 悲观锁任务,在自己修改数据的同时别的线程也会修改数据,所以在进行数据操作之前先进行加锁,在数据操作完才进行释放锁,锁释放之前,别的线程不能操作这个数据
乐观锁 底层也是悲观锁 业务复杂 不是一条sql语句 的 不适合乐观锁
CAS
CAS :是乐观锁的一种实现方式
CAS:Compare and Swap,即比较再交换 是一种乐观锁 使用了
CAS有三个操作数:预期值A,内存值B,旧的内存值C,当且仅当内存值B等于旧内存值C的时候,才会把B修改为A
CPU指令级的操作,只有一步原子操作,所以非常快。而且CAS避免了请求操作系统来裁定锁的问题,不用麻烦操作系统,直接在CPU内部就搞定了
CAS ABA问题
ABA问题描述的是当 :当我想把A变成B的时候,没有线程进行操作,肯定是变出成功的,但是中间多出来一个线程将A变成了B,然后又把B修改为A了,这个时候他进行了操作,但是不影响我的修改。
解决: 如果是基础数据类型 不用管,不影响结果值(int,short,long .....)
引用数据类型,添加版本号,每做一次数据操作,版本号+1,进步比较判断时,连带版本号一起比较
CAS 循环时间长开销大
自旋 CAS 如果长时间不成功,会给 CPU 带来非常大的执行开销。
利用自旋次数或者超时时间解决。
CAS 保证单步原子性
CAS是一种在并发下实现原子操作的机制,但是只能用来保证一个变量的原子性,适用于并发冲突频率较低的场合。
对多个变量使用 CAS 保证不了原子性。
MySql Innodb MVVC也是乐观锁的一种实现方式
volatile 禁止指令重排序
CountDownLatch CycicBarrier Semaphore
MySql 三种引擎
Innodb MylSam memory(数据存放到内存中)
储存引擎:是指表的类型和表在计算机中的储存方式。 储存引擎是Mysql独有的特点。
不通的储存引擎决定了Mysql数据库中的表的不同储存方式
Innodb :创建表的表结构储存在.frm文件中(frame),
表数据 innodb_data_home_dir
表索引存储innodb_data_file_path。
MylSam :表数据储存在三个文件中,文件扩展名 .frm,MYD,MYI
.frm创建的表结构。
.MYD(MyDate)存储表数据
.MYI (MyIndex)表索引
Innodb :Mysql默认引擎 支持事务,支持并发控制 ,读写效率差,占用空间大( 支持主外键,有主键自增策略) 适用于更新和删除的场景多的,因为支持事务回滚
MylSam : 不支持事务,适用于读操作多的场景(有一个单独的索引文件) ,独写效率快,占用空间小
支持插入和读取场景多的,因为 插入数据快,空间和内存使用比较低 ,储存快也和不支持事务有关
MylSam三种数据类型 包括静态型、动态型和压缩型。其中,静态型是MyISAM的默认存储格式,它的字段是固定长度的;动态型包含变长字段,记录的长度不是固定的;压缩型需要用到myisampack工具,占用的磁盘空间较小。
Memory :
将数据存在内存,为了提高数据的访问速度,每一个表实际上和一个磁盘文件关联。文件是frm。
由于数据是存放在内存中,一旦服务器出现故障,数据都会丢失;
Mysql 三种锁
表锁(共享锁 排他锁),行锁(共享锁 排他锁),页面锁
三种锁优劣:加锁速度,锁的粒度 ,性能开销,并发量,锁冲突量几方面开了。
Innodb 引擎下支持 行锁和表锁 : 行锁和表锁是基于索引来说的
不带索引(表锁)要进行全盘扫描,带索引的(行锁)
行锁和表锁是针对 ,inster,update,delete的,,执行 select是不加任何锁的
测试时要关闭自动提交事务。这样才能模拟行锁和表锁 https://www.cnblogs.com/ljy-skill/p/10831708.html
| 行锁 | 表锁 | 页锁 | |
|---|---|---|---|
| MyISAM | √ | ||
| BDB | √ | √ | |
| InnoDB | √ | √ |
表锁 读读不冲突,读写冲突, 写写冲突
| 请求锁模式 是否兼容当前锁模式 | None | 读锁 | 写锁 |
|---|---|---|---|
| 读锁 | 是 | 是 | 否 |
| 写锁 | 是 | 否 | 否 |
MyLSam 在select之前会自动给表加 写锁,在增删改之前会自动给表加写锁。默认情况下显示加锁的过程是关闭的,开始也只是为了模拟事务或者查看读写锁方便。
MVCC的实现,通过保存数据在某个时间点的快照来实现的。
每行数据都存在一个版本,每次数据更新时都更新该版本。
Innodb提供了基于行的锁,如果行的数量非常大,则在高并发下锁的数量也可能会比较大,据Innodb文档说,Innodb对锁进行了空间有效优化,即使并发量高也不会导致内存耗尽
对行的锁有分两种:排他锁、共享锁。共享锁针对对,排他锁针对写,完全等同读写锁的概念。如果某个事务在更新某行(排他锁),则其他事物无论是读还是写本行都必须等待;如果某个事物读某行(共享锁),则其他读的事物无需等待,而写事物则需等待。通过共享锁,保证了多读之间的无等待性,但是锁的应用又依赖Mysql的事务隔离级别。
对Map 的values 进行排序 (三步走)
public static Map<Integer, Object> SortVal(Map<Integer, Object> map) {
// map 转 list
ArrayList<Map.Entry<Integer, Object>> list = new ArrayList<>(map.entrySet());
// 自定义排序规则
Collections.sort(list, new Comparator<Map.Entry<Integer, Object>>() {
TreeSet排序
public static void m2 (){
Comparator cmp = new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2 - o1;
}
};
Set<Integer> set = new TreeSet<Integer>(cmp);
set.add(2);
set.add(5);
set.add(9);
set.add(6);
for (Integer s : set) {
System.out.println(s);
}
}
Mybatis是什么
Mybatis 半自动 ORM框架 帮我们封装了原生JDBC 省去了我们手动创建数据连接 传参获取结果集的步骤
Mybatis有两种用法 一种是xml形式,一种是注解形式
使用Mybatis 只需要导入myabtis架包 利用自动生产工具 生成数据表对应的java接口并继承通用Mapper
生产接口的映射mapper.xml文件 然后在接口中写抽象方法 在映射文件里写sql语句 并且sql语句的 id要和抽象方法名相同
XML形式这种 是接口中的抽象方法没有实现的地方 他是通过动态代理对接口进行调用的
基于注解的方式 是在接口的抽象方法上的注解里写 SQL语句 注解式SQL语句是反射调用的
Mybatis 和 Hibernate 的区别
mybatis是半自动框架 需要自己写SQL Hibernate是全自动框架 跟着命名规范字段生产 sql
Mybatis 的sql是写在 mapper.XML里面的 方便对代码进行优化
jap 是接口继承接口 Repository
Mybatis多表查询
一对一
//需要在实体类中 添加 student属性
<resultMap id="BaseResultMap" type="com.moon.entity.Score">
<id column="id" jdbcType="INTEGER" property="id" />
<result column="c_name" jdbcType="VARCHAR" property="cName" />
<result column="grade" jdbcType="INTEGER" property="grade" />
<!-- 嵌套结果 --> <!-- 嵌套查询 --> 两种方案
<association property="student"
javaType="com.moon.entity.Student">
<id column="id" jdbcType="INTEGER" property="id" />
<result column="name" jdbcType="VARCHAR" property="name" />
<result column="sex" jdbcType="VARCHAR" property="sex" />
<result column="birth" jdbcType="DATE" property="birth" />
<result column="department" jdbcType="VARCHAR"
property="department" />
<result column="address" jdbcType="VARCHAR" property="address" />
</association>
</resultMap>
<select id="findScore" resultMap="BaseResultMap">
select sc.*,sc.id ,st.*
from
score sc INNER JOIN student st where sc.id=#{id};
</select>
一对多
// 实体类里面注入 List<Score>
<resultMap id="BaseResultMap" type="com.moon.entity.Student">
<!-- WARNING - @mbg.generated -->
<id column="id" jdbcType="INTEGER" property="id" />
<result column="name" jdbcType="VARCHAR" property="name" />
<result column="sex" jdbcType="VARCHAR" property="sex" />
<result column="birth" jdbcType="DATE" property="birth" />
<result column="department" jdbcType="VARCHAR"
property="department" />
<result column="address" jdbcType="VARCHAR" property="address" />
<!--嵌套结果-->
<collection property="score" ofType="com.moon.entity.Score">
<id column="id" jdbcType="INTEGER" property="id" />
<result column="stu_id" jdbcType="INTEGER" property="stuId" />
<result column="c_name" jdbcType="VARCHAR" property="cName" />
<result column="grade" jdbcType="INTEGER" property="grade" />
</collection>
</resultMap>
<select id="findstudent" resultMap="BaseResultMap">
select st.* ,sc.* from student st , score sc where st.id=sc.stu_id and st.id=#{id};
</select>
Mybatis 批量处理
批量插入
1.借助foreach
int insertYeb(List<User> userList) ;
<insert id="insertYeb" parameterType="java.util.List">
insert into yeb values
<foreach collection="list" item="userlist" separator=",">
(#{userlist.id},#{userlist.account},#{userlist.money})
</foreach>
</insert>
//传统jdbc 批量处理 耦合性大
public static void main(String[] args) throws Exception {
Connection connection=null;
PreparedStatement preparedStatement=null;
connection = jdbcUtil.getConnection();
jdbcUtil.begin(connection); //autocommit false
String sql = "insert into t_user(username,password) values(?,?)";
preparedStatement=connection.prepareStatement(sql);
long beginTime = System.currentTimeMillis();
for (int i=0;i<10000;i++){
preparedStatement.setString(1,"user"+(i+1));
preparedStatement.setString(2,"pwd"+(i+1));
preparedStatement.executeUpdate();
}
jdbcUtil.commit(connection);
long endTime = System.currentTimeMillis();
System.out.println("total time:"+(endTime-beginTime));//4150
}
批量修改
<update id="updateYeb">
update yeb set state='0' where id in
<foreach collection="list" item="userlist" index="index"
open="(" separator="," close=")">
#{userlist.id}
</foreach>
</update>
union 和 union all
分库分表查询 可以用 union 和 union all
select accountName from mydemo.account where sex='男'
union
select accountName from mydemox.account where sex='男';
union 会对查询出来的结果进行排序和去重 (distinct)
union all 只是对查询出来的结果进行合并 可能会有重复数据
但是 union all 查询效率比 union快
Mysql 和oracle 的区别
1.事务方面
mysql事务默认自动提交 oracle默认手动提交
mysql默认事务隔离级别 repeatable read oracle 默认的是 repeatable commit
2.分页方面
mysql select * from .... limit x,x 直接用limit进行分页
oracle 分页需要一张虚拟表生产 rownum
select * from (select st*,rownun rn from (select * from student ) st where rowun<=10) where rn>=5;
3.主键方面
mysql 主键有自增策略 auto_increment
oracle 没有主键自增策略 需要自己实现: sequence(序列 ) + trigger(触发器)
Spring
框架就是帮我们实现一些复杂的重复的逻辑 让我更有精力进行业务的开发 Spring简单来说是一个轻量级框架 内部集成了很多模块 最核心的IOC和AOP
IOC
我们传统的创建的创建对象是New出来 ,在Spring中创建对象是交给IOC容器完成的, 由IOC管理对象的生命周期和依赖注入。
IOC 是反射+工厂 + xml 实现的
我们把对象放进IOC容器有三种方法 1.xml文件里面配置 Bean标签 2.在类型上标注主键@Component @Repository @Serives @Controller 3.配置@configration @Bean 基于JAVA配置的
Spring IOC步骤:
1.找到配置文件
2.加载配置文件
3.解析配置文件中的bean元素,并识别id和class
4.通过反射(Class.forName().newInstance())创建这个bean的实例
5.将id作为key、实例作为value存放进Spring容器中
6.getBean取出实例
DI 依赖注入 先有IOC后有DI
实现依赖注入的三种方式 构造注入 Set注入 接口注入(不提倡)
AOP
AOP 切面编程 可以通过切点,切面,表达式 通知 很优雅的将一些逻辑植入程序中
Spring AOP就是基于动态代理的 运行时期动态的织入代码
表达式 是我们要对那些方法进行处理的逻辑切 点 是我们需要给那些方法植入逻辑 而这个方法就叫切点通 知 是被切入的点需要执行那些操作 通知又分前置 后置 环绕 异常 最终通知切 面 是切点+通知A O P 可以用来做 日志管理 权限管理 限流操作
限流操作 :
使用谷歌的Guava包 提供的限流工具类 RateLimiter 使用算法 令牌桶 和 漏桶 加上自定义注解 加上AOP
权限管理 :
可以验证用户是否有操作权限 或者用户是否携带密钥(api保护)
认证和授权主要是使用Shiro
什么是反射
Java反射机制的核心是在程序运行时动态加载类并获取类的详细信息,从而操作类或对象的属性和方法。本质是JVM得到class对象之后,再通过class对象进行反编译,从而获取对象的各种信息。
Java属于先编译再运行的语言,程序中对象的类型在编译期就确定下来了,而当程序在运行时可能需要动态加载某些类,这些类因为之前用不到,所以没有被加载到JVM。通过反射,可以在运行时动态地创建对象并调用其属性,不需要提前在编译期知道运行的对象是谁。
动态代理
代理(Proxy)是一种设计模式,指为一个目标对象提供一个代理对象, 并由代理对象控制对目标对象的引用. 使用代理对象, 是为了在不修改目标对象的基础上, 增强目标对象的业务逻辑.
静态代理
动态代理:Jdk自带Proxy ,Cglib代理
区别:
Proxy通过newProxyInstance实现代理 通过 invoke调用代理方法
Cglib通过实现MethodInterceptor 实现代理 继承intercept方法 ,通过 invokeSuper调用方法
JDK的动态代理Proxy有一个限制,就是使用动态代理的对象必须实现一个或多个接口,如果想代理没有实现接口的类,就可以使用Cglib实现.
工厂
工厂方法模式一种创建对象的模式 ,工厂顾名思义,就是用来生产对象的,在java中,万物皆对象,这些对象都需要创建,如果创建的时候直接new该对象,就会对该对象耦合严重,假如我们要更换对象,所有new对象的地方都需要修改一遍,这显然违背了软件设计的开闭原则,如果我们使用工厂来生产对象,我们就只和工厂打交道就可以了,彻底和对象解耦,如果要更换对象,直接在工厂里更换该对象即可,达到了与对象解耦的目的;所以说,工厂模式最大的优点就是:解耦
工厂分为三种 : 单工厂 ,工厂方法,抽象工厂
SpringMVC
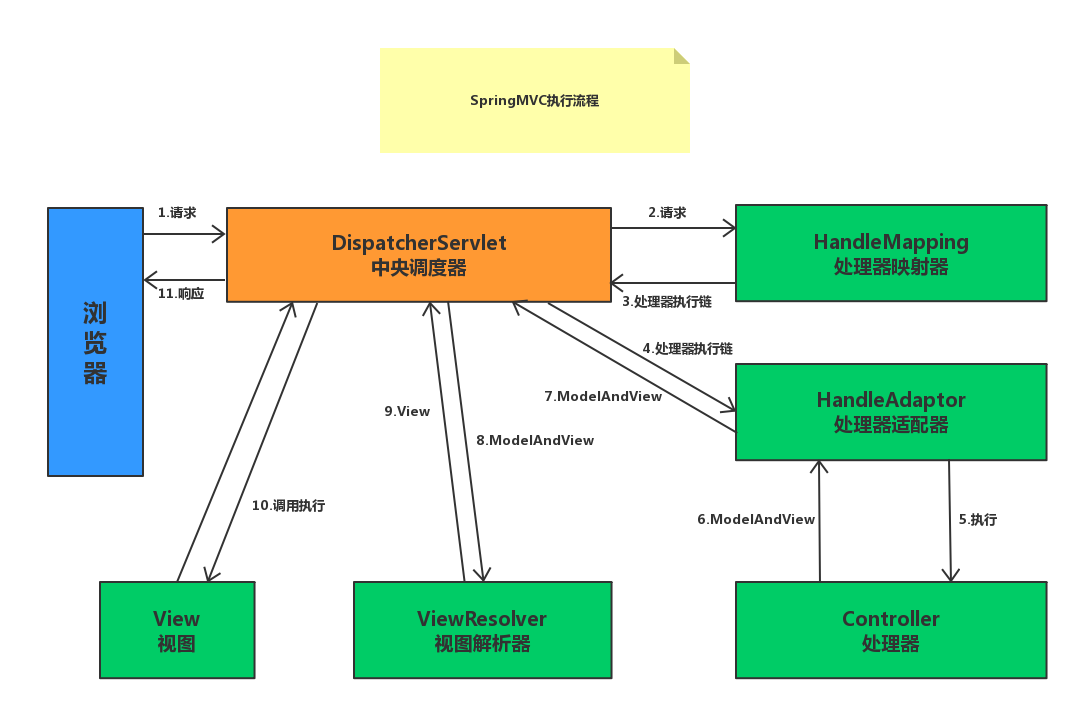
组件说明:
1.DispatcherServlet:前端控制器。用户请求到达前端控制器,它就相当于mvc模式中的c,dispatcherServlet是整个流程控制的中心,由它调用其它组件处理用户的请求,dispatcherServlet的存在降低了组件之间的耦合性,系统扩展性提高。由框架实现 2.HandlerMapping:处理器映射器。HandlerMapping负责根据用户请求的url找到Handler即处理器,生成处理器执行链HandlerExecutionChain(包括处理器对象和处理器拦截器)一并返回给DispatcherServlet ,springmvc提供了不同的映射器实现不同的映射方式,根据一定的规则去查找,例如:xml配置方式,实现接口方式,注解方式等。由框架实现 3.Handler:处理器。Handler 是继DispatcherServlet前端控制器的后端控制器,在DispatcherServlet的控制下Handler对具体的用户请求进行处理。由于Handler涉及到具体的用户业务请求,所以一般情况需要程序员根据业务需求开发Handler。 4.HandlAdapter:处理器适配器。通过HandlerAdapter对处理器进行执行,这是适配器模式的应用,通过扩展适配器可以对更多类型的处理器进行执行。由框架实现。 5.ModelAndView是springmvc的封装对象,将model和view封装在一起。 6.ViewResolver:视图解析器。ViewResolver负责将处理结果生成View视图,ViewResolver首先根据逻辑视图名解析成物理视图名即具体的页面地址,再生成View视图对象,最后对View进行渲染将处理结果通过页面展示给用户。 7View:是springmvc的封装对象,是一个接口, springmvc框架提供了很多的View视图类型,包括:jspview,pdfview,jstlView、freemarkerView、pdfView等。一般情况下需要通过页面标签或页面模版技术将模型数据通过页面展示给用户,需要由程序员根据业务需求开发具体的页面。
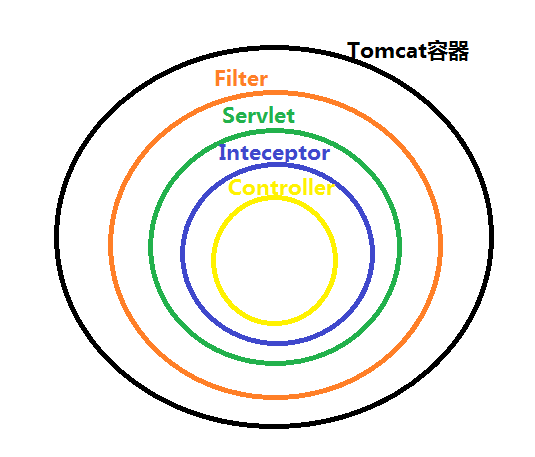
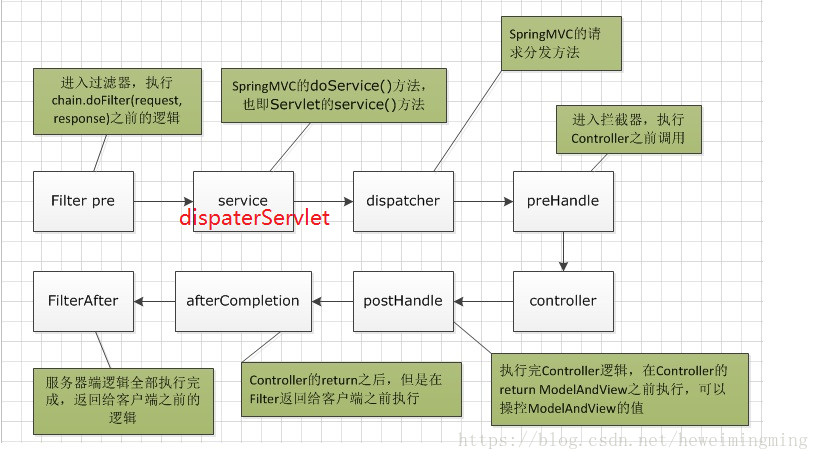
过滤器 拦截器 DispatcherServlet执行顺序

过滤器 拦截器 AOP
这写东西拦截器也可以实现因为拦截器是AOP的思想实现的
拦截器都是别人封装好的 可以直接拿来用 自己用实现AOP的话会很灵活 需要拦截和不需要拦截的 都可以自定义
拦截器和过滤器拦截的是URL AOP拦截的是类或者方法 AOP颗粒度更细
过滤器 回调函数实现的 “取你所想取” 字符集
拦截器使用是反射机制实现的 “拒你所想拒” 敏感词Spring AOP就是基于动态代理的
过滤器 是需要过来的越早对系统性能越好 编写相对公用的代码时优先考虑 过滤器 比如 字符集的过滤
一个请求过来 ,先进行过滤器处理,看程序是否受理该请求 。 过滤器放过后 , 程序中的拦截器进行处理 ,处理完后进入 被 AOP动态代理重新编译过的主要业务类进行处理 。
过滤器 拦截器
1、Filter是依赖于Servlet容器,属于Servlet规范的一部分,而拦截器则是独立存在的,可以在任何情况下使用。
2、Filter的执行由Servlet容器回调完成,而拦截器通常通过动态代理的方式来执行。
3、Filter的生命周期由Servlet容器管理,而拦截器则可以通过IoC容器来管理,因此可以通过注入等方式来获取其他Bean的实例,因此使用会更方便
过滤器
是在javaweb中,你传入的request、response提前过滤掉一些信息,或者提前设置一些参数,然后再传入servlet或者struts的action进行业务逻辑,比如过滤掉非法url(不是login.do的地址请求,如果用户没有登陆都过滤掉),或者在传入servlet或者 struts的action前统一设置字符集,或者去除掉一些非法字符.
过滤器Filter 只能应用在web容器中
触发时机 是在请求进入tomcat容器之后 但未进入servlet之前 结束实际是在 servlet处理完后 返回给前端之前
Filter几乎可以对所有请求过滤
用过滤器的目的,是用来做一些过滤操作,获取我们想要获取的数据,比如:在Javaweb中,对传入的request、response提前过滤掉一些信息,或者提前设置一些参数,然后再传入servlet或者Controller进行业务逻辑操作
设置编码过滤器 跨域调用的CosFilter设置请求头 过来率敏感字符
缺点 一个过滤器实例只能在容器初始化时调用一次
拦截器
拦截器(Interceptor): 用于在某个方法被访问之前进行拦截,然后在方法执行之前或之后加入某些操作,其实就是AOP的一种实现策略。它通过动态拦截Action调用的对象,允许开发者定义在一个action执行的前后执行的代码,也可以在一个action执行前阻止其执行。同时也是提供了一种可以提取action中可重用的部分的方式。
拦截器是spring的一个组件 归spring 管理 拦截器可以使用springIoc里面的Bean 但是过滤器不行
拦截器有三个方法 preHandle postHandle afterCompletepreHandle 是在请求进入方法执行之前执行 在这个方法里面可以做一些 资源的放行拦截 登录认证 和 权限管理postHandle 实在controller执行之后执行的 但在渲染视图之前执行, afterComplete 是做一些善后管理 在页面渲染完成返回给客户端之前执行
拦截器是被过滤器包裹的
缺点 只能对controller请求进行拦截
websocket
项目中websocket 在我们的项目中 websocket 是用来做推送的
做推送有三种实现方式 基于Http的 短轮询 长轮询 和websocket
http有自己的协议 HTTP:// 和HTTPS://
wesocket 也有自己的连接 ws:// wss:// 他们都是 TCP/IP协议的子集
短轮询 客户端定时向服务端发送HTTP请求 不管服务端有没有数据都会响应 短轮询有很大的缺点 轮询时间长了消息不实时 时间小了 造成宽带浪费 增加服务器负担
长轮询 服务器死循环 客户端递归就是客户端请求 建立连接 服务端做死循环 当有数据的时候 返回数据给客户端 跳出死循环响应结束然后 客户端 递归调用 缺点服务端客户端一直保持连接 会造成浪费 容易产生服务瓶颈
websocket 协议是双向通信协议 是真正的推送 客户端和服务端都能主动发送和接受消息websocket 建立连接的时候需要以来一次HTTP协议 连接建立成功之后 这给这个持久连接的通信就与HTTP无关了
websocket 的使用 需要导入依赖 配置一个处理器 一个拦截器 再处理器里面进行消息的接受发送
-web端send会触发服务端onMessage/服务端send会触发web端onMessage---双向推送
如何保存会话列表
线程安全的集合 或者 Redis
使用websocket需要注意
1.可能出现 每隔几分钟没有请求信息,连接就会断开的情况
增加心跳机制维持连接,每隔一段时间就向服务端发送一次自定义请求,或者调用sendPing()来保持住连接。
2.会话的回收 断电/断网/浏览器非正常关闭 : 心跳与重连机制
为什么会进行心跳检测
简单地说是为了证明客户端和服务器还活着。websocket 在使用过程中,如果遭遇网络问题等,这个时候服务端没有触发onclose事件,这样会产生多余的连接,并且服务端会继续发送消息给客户端,造成数据丢失。因此需要一种机制来检测客户端和服务端是否处于正常连接的状态,心跳检测和重连截止就产生了。
//聊天室
var url ="ws://"+location.host+"/chatrecords?commid="+commid;
var ws =new WebSocket(url);
//sendwork 发送消息 websocket 聊天室
function sendwork(){
//得到消息内容 然后输入框清除
var work = $("#work").val();
ws.send(chatrecored)
}
//接受后端返回的消息 并在前端显示
ws.onmessage = function (e) {
//得到消息内容 并显示
alert($.parseJSON(e.data));
}
//发送消息的时候进行处理
如何实现登录页面密码加密
-
页面一加载的时候就发送AJAX请求获取公钥 并保存在前端 获取用户输入的密码 然后根据公钥进行加密
后端获取加密后的密码 然后解密 再与数据库中的密码进行 对比 判断密码是否正确。
-
用户登陆分两次请求 第一次传输用户名 服务端收到用户名后 生成一段随机
然后把用户名和随机数存放到session中 并把随机数返回个客户端 客户端把随机数与密码进行一定规则组合 再经过MD5加密 发送到服务器 服务器到数据库取出密码 密码和随机数也按照一定规则组合 也经过过MD5加密 然后与接收到的密码进行比对 处理

SpringCloud相关组件
eureka 注册中心
eureka 负责服务的注册和发现 包括: 服务的注册中心 服务的提供者 服务的消费者
MyCat
Mycat 企业应用开发的大数据库集群 支持事务、ACID、可以替代MySQL的加强版数据库Mycat作用为:能满足数据库数据大量存储;提高了查询性能分布式情况下 数据库是部署不懂的服务器的 所以IP地址不一样Mycat: 适合分库分表的情况下 或者读写分离Mycat: 随着项目的不断运行 数据库中的数据越来越多 这样的查询效率就会不变慢 所以要进行分库分表
统一发号器 分布式数据库的Id生成 snowflake算法(可以根据自己的实际业务定义自己的分布式ID生成算法)
Mycat的使用 需要配置 rule schema server这三个配置文件
接口和抽象类的区别
1.8之前接口只能有抽象方法 抽象类既可以有抽象方法也可以有普通法
1.8之后接口中可以有默认方法
public interface Demo01 {
public void m1();
// default 是忘了如何实现 可以先返回一个值
default int m2() {
return 0;
} ;
}
//两种区别 考虑 1.8
abstract class a {
public void m1() {
};
public abstract void m2();
}
重载 一个类中 方法名相同参数不同 与返回值无关
重写 子类继承父类 对父类的方法进行重写 方法名相同参数 返回值都要相同
synchornized 和 lock 区别
公平和非公平 syn非公平 lock可以自己设置公平和非公平
trylock
tryLock尝试获取锁 成功返回true 失败返回false
HTTP报文
Http请求报文:
请求行 保存 请求类型(get,post), 请求的路径 (url), HTTP协议版本
请求头 保存Cookie
请求体 保存的是一些参数数据
session() cookie() 区别联系
cookie是保存在Http请求报文的请求头中 cookie中保存有JessionId
请求体中保存的是一些参数数据 get没有请求体 post才有请求体
get请求参数是暴露在地址栏的 post的参数是在请求体中的
get请求可以存放 2KB的数据 post理论无限大
Session 和 token
(session是有状态 token无状态)
session 一半在浏览器一半在服务器的内存或硬盘上 验证用户是否可以访问需要匹配session 但是在分布式项目session无法使用了 因为session有一半是存在服务器的
如果将来搭建了多个服务器,虽然每个服务器都执行的是同样的业务逻辑,但是session数据是保存在内存或硬盘中的(不是共享的),用户第一次访问的是服务器1,当用户再次请求时可能访问的是另外一台服务器2,服务器2获取不到session信息,就判定用户没有登陆过。
token 客户端访问服务端 服务端对用户信息进行加密(token) 传给客户端。客户端将token保存在localStroage中 客户端每次请求携带token 服务端验证token 通过则进行下一步操作 即使在多台服务器上,服务器也只是对token进行解密和查询操作 不需要再服务端保存信息 token这种机制不需要考虑用户在那台服务器登陆了 只需要验证token是否匹配就行了 所有token是分布式session的解决办法
验证session 在父级域名的情况
在父级域名的情况下是相同的 父级域名相同的情况下cookie是共享的JessionId也是共享的
GC
GC垃圾回收机制 回收堆内存中不再使用的对象,释放资源 对象=null 就会被回收GC 发生在堆中
fullGC 老年代 字符串常量池
Young GC 新生代发生
在新生带有三个区域 大部分对象刚创建的时候在Eden区 当Eden区满了会进行一次GC 把无用的对象删除掉
剩余的对象复制到Survivor0 区 此时,Survivor1是空白的,两个Survivor总有一个是空白的)
当Eden再次满的时候 无用的对象会从survivor0删除 其余的复制到survivor1 两个区来回交换15次存活的对象进入 老年代

内存溢出
栈溢出
递归调用 一个对象还没出方法区另一个对象被创建了
堆溢出
很难溢出 jvm参数不合适 了 线程池 队列集合Size太大
线程池
线程池是一种池化思想管理线程的工具 是创建管理线程的地方 , 当我们的每次使用线程的时候都要创建 销毁 会消费消耗系统很大资源, 为了避免这种情况可以使用线程池 来进行线程的重用 同时也可以 提高响应速度 当任务来临时 不用等待线程的创建了
线程池会初始化一些线程放在池子里 当需要线程的时候去线程池里取 取出来之后将线程标记为占用状态 当线
使用完毕 线程不是销毁而是回收到池子中 并标记为空闲状态 当线程池的线程都被占用 别的程序需要线程的时
候 只能阻塞等待 等待别的线程池中有空闲的线程 再来使用;
创建 需要开辟虚拟机栈,本地方法栈、程序计数器等线程私有的内存空间。
线程使应用能够更加充分合理的协调利用cpu 、内存、网络、i/o等系统资源。
线程池执行流程

线程的执行流程

创建线程的几种方式
1. new Thread() 2. new Runnable() 3. Callable() (返回一个参数,需传返回值类型) 4. 使用线程池
线程池创建方式
两种创建方式 Executors. 和 new ThreadPoolExecutor()
Executors 内部四种创建线程池的方式
newCachedThreadPool
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
newScheduledThreadPool
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
为什么不推荐使用Executors 而是推荐使用ThreadPoolExecutor
队列
| 队列 | 有界性 | 锁 | 数据结构 |
|---|---|---|---|
| ArrayBlockingQueue | bounded(有界) | 加锁 | arrayList |
| LinkedBlockingQueue | optionally-bounded | 加锁 | linkedList |
| PriorityBlockingQueue | unbounded | 加锁 | heap |
| DelayQueue | unbounded | 加锁 | heap |
| SynchronousQueue | bounded | 加锁 | 无 |
| LinkedTransferQueue | unbounded | 加锁 | heap |
| LinkedBlockingDeque | unbounded | 无锁 | heap |
ArrayBlockingQueue : 有界阻塞队列,底层是数组实现,遵循FIFO,持有公平锁和非公平所
LinkedBlockingQueue : 有界阻塞队列,底层是链表实现,遵循FIFO, 最大值是Integer.MAX_VALUE
SynchronousQueue : 无缓冲阻塞队列,一个不储存元素的阻塞队列,会直接将任务交给消费者
DelayQueue : 实现了BlockingQueue接口,继承了Delayed,内部使用了Leaded/followers模式
可以用来做定时任务,延迟任务。
数据库连接池
当我们每次于数据库建立连接的时候 都需要注册驱动管理者 建立连接连接 获取数据载体 用完再回收
这样平凡的建立关闭连接 会消耗系统资源 当并发量高的时候会导致数据崩溃 这个时候就需要用到数据库连接池了
forward和 redirect
forward转发 服务器行为 redirect重定向 客户端行为forward 一次请求一次响应 中间服务器做了什么浏览器不知道 所有地址栏不改变 共享request 会携带数据redirect 两次请求两次响应 第一次请求服务器响应状态码给客户端 客户端根据状态码去请求新的url 新的url响应给客户端 地址栏会改变 不 共享request 不会携带数据
Redirect重定向 改变地址栏 两次请求两次响应 不共享request域
forWard 转发 一次请求一次响应 不改变地址栏 共享request中的数据
1、请求次数:重定向是浏览器向服务器发送一个请求并收到响应后再次向一个新地址发出请求,转发是服务器收到请求后为了完成响应跳转到一个新的地址;重定向至少请求两次,转发请求一次;
2、地址栏不同:重定向地址栏会发生变化,转发地址栏不会发生变化;
3、是否共享数据:重定向两次请求不共享数据,转发一次请求共享数据(在request级别使用信息共享,使用重定向必然出错);
4、跳转限制:重定向可以跳转到任意URL,转发只能跳转本站点资源;
5、发生行为不同:重定向是客户端行为,转发是服务器端行为;
Spring 底层是如何解决循环依赖的
循环依赖 A中需要依赖B作为属性 B中需要依赖A作为属性Spring解决循环依赖: Spring底层优化 类实例化的时候 运行 属性字段为null A中依赖的B属性 B中的A属性可以为null 但是B中的其他属性需要是正常的同理 B依赖A也是这样
先IOC后 DI 取出对象全与不全 解决方案 不能互为前提
缓存技术
缓存是为了把数据放到内存中将来再次查询的时候从内存中读取 减轻对数据的的压力 提高性能
mybatis一级缓存和二级缓存
数据库的会话-Sqlsession、链接-Connection和事务-Transaction
链接可以通过数据库链接池被复用。在MyBatis中,不同时刻的SqlSession可以复用同一个Connection,同一个SqlSession中可以提交多个事务。因此,链接—会话—事务的关系如下:
1.得到资源
2.创建工厂建造者对象
3.用工厂建造者创建工厂(把读取信息放进工厂)
4.用工厂得到session
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession sqlSession = sqlSessionFactory.openSession();
public class sessionUtil {
static SqlSessionFactory factory=null;
protected SqlSession session;
static {
try {
Reader r= Resources.getResourceAsReader("mybatisConfig.xml");
SqlSessionFactoryBuilder builder=new SqlSessionFactoryBuilder();
factory=builder.build(r);
} catch (IOException e) {
e.printStackTrace();
}
}
public SqlSession getsession(){
session=factory.openSession();
return session;
}
}
一级缓存
一级缓存是默认开启的 Sqlsession级别的 一级缓存在同一个Sqlsession中有效 当有多个 sqlsession操作的时候会产生脏数据(一个sqlsession查询 另一个在查询之后对数据进行修改 第一sqlsession再次执行形同查询的时候会走内存 查询的是未修改时候的数据 所有就是脏数据)所有建议将一级缓存的级别设置为statement而不使用session
一级缓存中的数据只能在同一个SqlSession中 想要在多个SqlSession共享数据 就要开启二级缓存
二级缓存
二级缓存 : 默认关闭的需要手动开启 配置<cache/>标签 是namespace级别的 多个sqlsession共享相同namespace下的数据
缺点 :二级缓存不适合多表 因为多表所在namespace无法感应其他namespace的修改语句 这样会引起数据脏读 解决办法引用 <Cache ref>
一级缓存 在同一sqlsession对数据进行修改后会清除缓存
二级缓存 是任意一个sqlsession修改数据后并进行提交 缓存清除 设置flushCache=true
如insert、update、delete,flushCache默认为true;如select,flushCache默认为false,因为设置为true,当执行select 也会刷新
<insert id="insertUser" parameterType="cn.itcast.mybatis.po.User" flushCache="true">
Redis缓存
redis 底层是k-v形式 可持久化((一边运行,一边把数据往硬盘中备份一份 防止断电情况) 而且读写效率快 redis 做缓存 把查出的数据放入到redis中 下次查询直接查询redis redis 更新 的两种方法 先更新数据库 然后在让缓存失效 (时效性不高的) 异步更新 使用两个线程 一个去更新数据库 一个区更新缓存 (时效性高的)
延迟双删 : 先删除redis 更新mysql 之后再删除redis
图片上传
// 上传到Ngnix路径上
@Value(value = "${img.pathlocal}")
private String path;
/**
* 图片上传
*/
@RequestMapping(value = "/uploadfile")
@ResponseBody
public String uploadfile(MultipartFile multipartFile , HttpServletRequest request){
try {
String fixpath =path;
//获取文件原始名称
String filename = UUID.randomUUID()+multipartFile.getOriginalFilename();
//根据获取到的文件名称创建目标文件
File file = new File(fixpath,filename);
// 将收到的文件传输到目标文件中
if(!file.getParentFile().exists()){
file.getParentFile().mkdirs();
}
multipartFile.transferTo(new File(fixpath,File.separator+filename));
return filename;
} catch (IOException e) {
e.printStackTrace();
}
return "no";
}
// 框架自带
new Q.Uploader({
url:"/moon/Commodity/uploadfile",
target: $("#uploadimg")[0], //上传按钮,可为数组 eg:[element1,element2]
view: $("#uploadview")[0],//上传任务视图(若自己实现UI接口,则无需指定此参数)
allows: ".jpg,.png,.gif,.bmp",
dataType: "text",
upName:"multipartFile",
on:{
select: function(task){
},
// 点击按钮上传之前 先插入一条空数据 并返回记录主键
complete: function(task){
$.post("/moon/Commodity/insertonecomm",{
name:$("#account").html(),
imgpath:task.response
},function (keyid) {
$("#keyid").html(keyid);
// 静态服务器路径
$("#images").attr('src',"http://localhost/uplocal/"+task.response);
});
}
},
});
Nginx
Nginx 可以做正向代理 反向代理 负载均衡
代理: 比如 我们去耐克的专卖店里买了买了一双鞋
专卖店就是代理 鞋子就是被代理对象 我们就是目标角色

正向代理 Proxy和Client是在Lan(局域网的) 隐藏的是客户端的信息
反向代理 Proxy和Server是在Lan(局域网的) 隐藏的是服务端的信息
事实上 Proxy 在两种代理的情况下 都是代服务器接受请求和发送响应的 不过从结构上看正好左右互换了一下,所以把后出现的那种代理方式称为反向代理了。
正向代理
我们访问国外网站 都是通过FQ实现的 FQ主要是找到一个可以访问国外网站的代理服务器 然后我们发送请求给代理服务器 代理服务器发送请求给国外网站 然后响应数据给我们
正向代理最大的特点是 客户端明确知道要访问的资源路径 而服务端只知道从那个代理服务器过来的而不知道客户端是谁 这样就隐藏的客户端的信息
正向代理,"它代理的是客户端,代客户端发出请求
作用:
-
访问原来无法访问的资源,如 Google
-
可以做缓存,加速访问资源
反向代理
某宝使用的就是Nginx的反向代理 客户端通过访问代理服务器的路径 然后代理服务器将请求分发给内部服务器
服务器返回数据给代理对象 代理对象返回数据个客户端
服务器知道是那个客户端访问的 而客户端却不知道自己访问的是那个服务器
反向代理,"它代理的是服务端,代服务端接收请求", 主要用于服务器集群分布式部署的情况下
作用:
保护内网安全 隐藏内网IP地址
负载均衡
Nginx反向代理接受到的请求数量 就是负载数
Nginx根据一定的规则把请求发送到不同的服务器上这叫均衡规则
服务器接收到的请求按照规则分发的过程,称为负载均衡。
负载均衡策略
weight轮询 权重 根据服务器响应时间进行分权 权重的情况下 一台服务器宕机 Nginx会把这台服务器剔除 请求不好受到影响
upstream backserver {
server 192.168.0.14 weight=8;
server 192.168.0.15 weight=10;
}
ip_hash 根据客户端 IP 的Hash进行结果匹配 决定访问那台服务器 避免了用户分片上传文件后对上传资源的无法整合 每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题。
upstream somestream {
hash $request_uri;
server 192.168.244.1:8080;
server 192.168.244.2:8080;
server 192.168.244.3:8080;
server 192.168.244.4:8080;
}
server {
listen 8081 default;
server_name test.csdn.net;
charset utf-8;
location /get {
proxy_pass http://somestream;
}
上述同样也是一个极简的监听8081端口的nginx服务,当请求url为/get时,会走url_hash;同样配置了upstream模块,hash $request_uri表明了是按照url规则进行hash策略。
静态资源服务器
通过路径拦截 决定他们访问那个文件夹 从哪里获取资源
Nginx 拦截请求路径处理
Nginx 可以拦截所有的请求 " / " 决定他们访问那个路径
可以拦截静态资源访问 决定他们从哪里拿去资源
可以拦截JSP 访问 决定他们从哪里走
3.2设置规则
# 不带数据的请求,包括restful风格的请求
location / {
proxy_pass http://org.tonny.balance;
# root html;
# index index.html index.htm;
}
# 静态文件,从这里获取
location ~* \.(css|gif|png|jpeg|ico|svg)$ {
root D:/App/nginx/apache-tomcat-7.0.92_1/webapps/ROOT;
}
# jsp类型的请求,从这里走
location ~ \.jsp$ {
proxy_pass http://org.tonny.balance;
}
正派索引 倒排索引
正派索引 文档 ----> 单词
倒排索引 单词 ----> 文档
倒排索引 redis + jiebaes分词
//Jieba分词
public void getparticiple(List<Commodity> participle){
Jedis jedis = new Jedis("127.0.0.1", 6379);
JiebaSegmenter jiebaSegmenter = new JiebaSegmenter();
for (Commodity part: participle){
List<SegToken> process = jiebaSegmenter.process(part.getComname(), JiebaSegmenter.SegMode.SEARCH);
for (SegToken segToken: process ){
if(segToken.toString().length()>1){
jedis.sadd(segToken.word,String.valueOf(part.getId()));
}
}
}
}
ES + ik 分词 倒排索引
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>com.sun.jna</groupId>
<artifactId>jna</artifactId>
<version>3.0.9</version>
</dependency>
#ES
spring.data.elasticsearch.cluster-name=elasticsearch
spring.data.elasticsearch.cluster-nodes=127.0.0.1:9300
继承分词接口Repository
public interface PoetryResopstry extends CrudRepository<PoetryEs, Integer>{
public List<PoetryEs> findByContentIn(String words);
}
先把词语存进去 然后根据词语进行查询 IK分词可以自定义热词查询
反射调用
String className = "com.tmc.test.Mapval";
String methods = "m1";
// 反射 根据字符串获取类
Class<?> c = Class.forName(className);
// 获取类的属性
Field[] fields = c.getDeclaredFields();
for (Field field : fields) {
System.out.println(field.getName());
}
//反射 获取类的方法
Method[] methods2 = c.getDeclaredMethods();
for (Method m : methods2) {
System.out.println(m.getName());
}
//反射 根据字符串调用方法
Method declaredMethod = c.getDeclaredMethod(methods, c.getClasses());
declaredMethod.invoke(c, null);
实现工厂
InputStream stream = MainClass.class.getResourceAsStream("setting.properties");
Properties properties = new Properties();
properties.load(stream);
String property = properties.getProperty("fruits");
Class<?> clz = Class.forName(property);
Fruits object = (Fruits)clz.newInstance();
Method[] methods = clz.getDeclaredMethods();
for (Method method : methods) {
method.invoke(object, null);
}
// 创建水果的接口 苹果和橘子都是实现类 然后搞个配置文件写 类的权限的类名
// getClassLoader 是加载ClassPath下的资源 一般就是读取配置文件的
// Src 下的 文件经过编译就去到了 ClassPath下 比如 .java编译后变成.class文件
finall
作用在类上 : 类不能被继承 不能被实先
作用在方法上 : 方法不能被重写
作用在变量上 : 变量的值可以改变但是引用不能改变

