
3.2 符号表之二叉查找树BST
一.插入和查找
1.二叉查找树(Binary Search Tree)是一棵二叉树,并且每个结点都含有一个Comparable的键,保证每个结点的键都大于其左子树中任意结点的键而小于其右子树的任意结点的键。
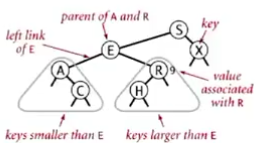
2.一个结点需要维持几个实数域,即键,值,左、右结点,还需要维持一个count值,用来表示该结点含有的子树的结点数(包括自己)
3.查找的实现:如果小于该节点,去该节点的左边找;如果大于该节点,去该节点的右边找,如果相等,则找到了该值。
插入的实现:key在BST中,重置value;key不在BST中,添加新的结点。


package com.cx.serch; import java.util.LinkedList; import java.util.Queue; public class BST<Key extends Comparable<Key>,Value> { private Node root; /** * 定义Node节点,用来存储键值对,以及左右的节点 */ private class Node{ private Key key; private Value value; private Node left,right; //添加一个count属性,这个属性用来记录以该节点为根的节点数(包括自己) private int count; public Node(Key key,Value value,int count) { this.key=key; this.value=value; this.count=count; } } /** * 实现size()方法 */ public int size() { return size(root); } private int size(Node x) { if(x==null) return 0; return x.count; } /** * 实现插入键值对的方法 */ public void put(Key key,Value value) { //如果根节点是null,给它赋上key,value //如果有根节点,根的合适位置添上该节点 root=put(root, key, value); } public Node put(Node x,Key key,Value value) { if(x==null) return new Node(key, value , 1); int cmp=key.compareTo(x.key); if(cmp<0) x.left=put(x.left, key, value); else if(cmp>0) x.right=put(x.right, key, value); else x.value=value; x.count=size(x.left)+size(x.right)+1; return x; } /** * 实现查找某个key的方法 */ //比Node大,去右边找,比Node小去左边找 public Value get(Key key) { Node x=root; while(x!=null) { int cmp = key.compareTo(x.key); if (cmp<0) x=x.left; else if(cmp>0) x=x.right; else return x.value; } return null; } }
4.说明:
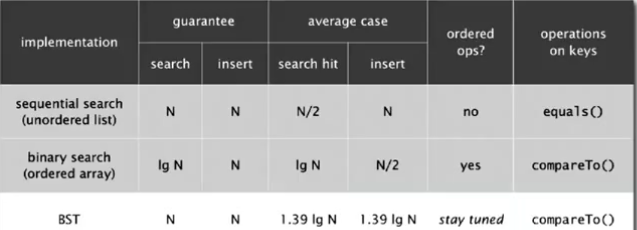
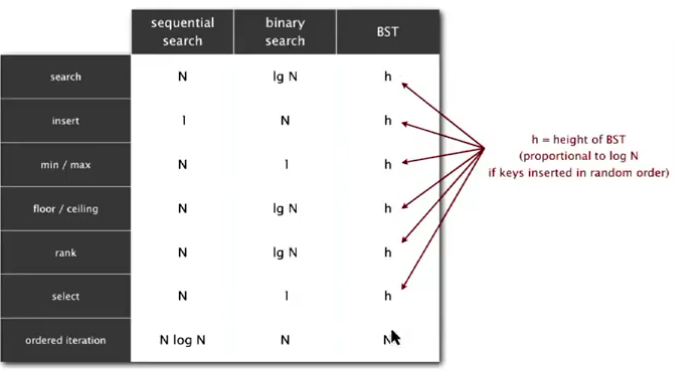
(1)可以看出插入和查找难度一样,均为lgN,即和树的高度有关。
(2)但是二叉查找树的算法的运行时间取决于树的形状,即键被插入的先后顺序。在最坏的情况下,性能可能非常糟糕,也就是当输入的key,已经被排好序的时候,树的高度为N,插入和查找的运行时间也需要N
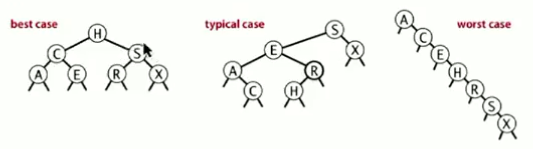
(3)一般来说,如果N个随机键以随机的顺序插入到BST中,那么插入和查找的时间为~2lnN.
(4)我们无法保证输入是随机的,也就是说BST无法避免最坏的情况发生
二.找floor/ceiling值,max/min(对于键来说)
1.floor指的是小于给定k的最大的值,ceiling指大于给定k的最小值。floor和ceiling思路类似,仅举例floor
2.floor的思路:
(1)k等于根root的值,floor(k)为k
(2)k小于根root的值,floor(k)在根的左子树中
(3)k大于根root的值,如果根的右子树全都大于k,则floor(k)为根的值。只要根的右子树有一个小于k,则floor(k)在根的右子树中
这一步是有技巧的,可以直接找去根的右子树中找floor(k),如果找到了,则取该值,否则,取根。
3.min的思路:找以x为根的左子树,直到左边为null为止。
4.代码实现:
/** * 实现查找key的floor的方法,即小于key的最大值 */ public Key floor(Key key) { Node x=floor(root,key); //能找到,返回x,不能找到返回null if (x==null) return null; else return x.key; } //与x.key比较,求key的floor public Node floor(Node x,Key key) { if(x == null) return null; //比较x.key和key int cmp=key.compareTo(x.key); //如果等,floor即为x if(cmp==0) return x; //如果k小于节点,去左边找 else if(cmp<0) return floor(x.left,key); //如果k大于节点,去右边找floor //如果右边全大于k,则为该节点 //换句话说,可以转换为在x的右边子树找floor,存在则为该值,否则为x Node t=floor(x.right, key); if(t == null) return x; else return t; } /** * 实现查找最小key的方法 */ public Key min() { return min(root).key; } //返回以x为根的子树的min public Node min(Node x) { if (x.left==null) return x; //在左边的子树中寻找 return min(x.left); }
三.找rank,即小于k的键的个数。k可以在二叉树里,也可以不在。
1.思路:分三种情况考虑
2.代码实现:
public int rank(Key key) { return rank(key,root); } //一个错误的实现是size(x),但是以x为根的子树有大于它的部分 public int rank(Key key,Node x) { if(x==null) return 0; //key与x.key比较 int cmp=key.compareTo(x.key); //相等 if(cmp==0) return size(x.left); //key小于x.key,去左边找 else if(cmp<0) return rank(key, x.left); //大于,去右边找,且要加上1和左边的size else return 1+size(x.left)+rank(key, x.right); }
四.将键按照中序遍历(inorder traversal)
1.中序遍历:指的是先遍历左子树,再遍历根,最后遍历右子树。
2.这里使用队列存储key
3.代码实现:
public Iterable<Key> keys(){ Queue<Key> queue=new LinkedList<Key>(); inorder(root,queue); return queue; } public void inorder(Node x,Queue<Key> q) { if(x==null) return; inorder(x.left, q); q.add(x.key); inorder(x.right, q); }
五.删除操作
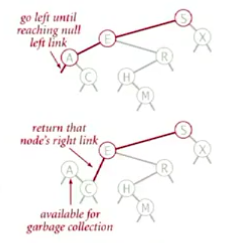
1.删除最小值的思路:
(1)一直找左子树,直到一个结点不存在左子树为止
(2)使用右侧的子树替代它
(3)更新子树的count
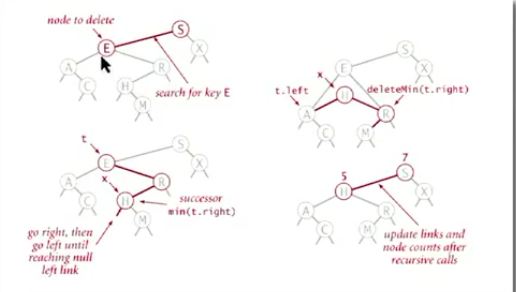
2.删除指定node with key k的思路
(1)如果没有子结点,直接删除它,并将父结点指向空
(2)如果只有一个子结点,将父结点指向它的子结点
(3)如果有两个子结点:
i.找到t的右子树中最小的节点 min(t.right)
ii.删除该节点 deleteMin(t.right)
iii.用x替换t
3.代码实现:
/** * 删除最小值 */ public void deleteMin() { root=deleteMin(root); } //去左边找,直到找到一个有着左侧为空的节点 //用该节点的右侧替换该节点 //更新子树的数目 public Node deleteMin(Node x) { //如果左侧为空,返回该节点 if(x.left==null) return x.right; x.left=deleteMin(x.left); x.count=1+size(x.left)+size(x.right); return x; } /** * 删除指定值 */ public void delete(Key key) { root=delete(root,key); } public Node delete(Node x,Key key) { if(x == null) return null; //寻找key对应的节点 int cmp=key.compareTo(x.key); if(cmp<0) return delete(x.left, key); else if(cmp>0) return delete(x.right, key); //找到了该节点 else { //只有一个child或没有child,用另一部分替代该节点 if(x.right==null) return x.left; if(x.left==null) return x.right; //有两个节点 Node t=x; //1.找到t右子树的最小节点x x=min(t.right); //2.删除最小节点 //3.用x替代t x.right=deleteMin(t.right); x.left=t.left; } //更新count x.count=1+size(x.left)+size(x.right); return x; }
六.总结
1.整个BST的实现代码如下:
package com.cx.serch; import java.util.LinkedList; import java.util.Queue; public class BST<Key extends Comparable<Key>,Value> { private Node root; /** * 定义Node节点,用来存储键值对,以及左右的节点 */ private class Node{ private Key key; private Value value; private Node left,right; //添加一个count属性,这个属性用来记录以该节点为根的节点数(包括自己) private int count; public Node(Key key,Value value,int count) { this.key=key; this.value=value; this.count=count; } } /** * 实现size()方法 */ public int size() { return size(root); } private int size(Node x) { if(x==null) return 0; return x.count; } /** * 实现插入键值对的方法 */ public void put(Key key,Value value) { //如果根节点是null,给它赋上key,value //如果有根节点,根的合适位置添上该节点 root=put(root, key, value); } public Node put(Node x,Key key,Value value) { if(x==null) return new Node(key, value , 1); int cmp=key.compareTo(x.key); if(cmp<0) x.left=put(x.left, key, value); else if(cmp>0) x.right=put(x.right, key, value); else x.value=value; x.count=size(x.left)+size(x.right)+1; return x; } /** * 实现查找某个key的方法 */ //比Node大,去右边找,比Node小去左边找 public Value get(Key key) { Node x=root; while(x!=null) { int cmp = key.compareTo(x.key); if (cmp<0) x=x.left; else if(cmp>0) x=x.right; else return x.value; } return null; } /** * 实现查找key的floor的方法,即小于key的最大值 */ public Key floor(Key key) { Node x=floor(root,key); //能找到,返回x,不能找到返回null if (x==null) return null; else return x.key; } //与x.key比较,求key的floor public Node floor(Node x,Key key) { if(x == null) return null; //比较x.key和key int cmp=key.compareTo(x.key); //如果等,floor即为x if(cmp==0) return x; //如果k小于节点,去左边找 else if(cmp<0) return floor(x.left,key); //如果k大于节点,去右边找floor //如果右边全大于k,则为该节点 //换句话说,可以转换为在x的右边子树找floor,存在则为该值,否则为x Node t=floor(x.right, key); if(t == null) return x; else return t; } /** * 实现查找最小key的方法 */ public Key min() { return min(root).key; } //返回以x为根的子树的min public Node min(Node x) { if (x.left==null) return x; //在左边的子树中寻找 return min(x.left); } /** * 实现rank()方法,也就是<k的数量 * 默认k在该BST中存在 */ public int rank(Key key) { return rank(key,root); } //一个错误的实现是size(x),但是以x为根的子树有大于它的部分 public int rank(Key key,Node x) { if(x==null) return 0; //key与x.key比较 int cmp=key.compareTo(x.key); //相等 if(cmp==0) return size(x.left); //key小于x.key,去左边找 else if(cmp<0) return rank(key, x.left); //大于,去右边找,且要加上1和左边的size else return 1+size(x.left)+rank(key, x.right); } /** * 中序遍历(inorder traversal),会按照自然顺序排序 * traverse left subtree * enqueue key * traverse right subtree */ public Iterable<Key> keys(){ Queue<Key> queue=new LinkedList<Key>(); inorder(root,queue); return queue; } public void inorder(Node x,Queue<Key> q) { if(x==null) return; inorder(x.left, q); q.add(x.key); inorder(x.right, q); } /** * 删除最小值 */ public void deleteMin() { root=deleteMin(root); } //去左边找,直到找到一个有着左侧为空的节点 //用该节点的右侧替换该节点 //更新子树的数目 public Node deleteMin(Node x) { //如果左侧为空,返回该节点 if(x.left==null) return x.right; x.left=deleteMin(x.left); x.count=1+size(x.left)+size(x.right); return x; } /** * 删除指定值 */ public void delete(Key key) { root=delete(root,key); } public Node delete(Node x,Key key) { if(x == null) return null; //寻找key对应的节点 int cmp=key.compareTo(x.key); if(cmp<0) return delete(x.left, key); else if(cmp>0) return delete(x.right, key); //找到了该节点 else { //只有一个child或没有child,用另一部分替代该节点 if(x.right==null) return x.left; if(x.left==null) return x.right; //有两个节点 Node t=x; //1.找到t右子树的最小节点x x=min(t.right); //2.删除最小节点 //3.用x替代t x.right=deleteMin(t.right); x.left=t.left; } //更新count x.count=1+size(x.left)+size(x.right); return x; } }
测试代码如下:
package com.cx.serch; public class Test { public static void main(String[] args) { BST<String,Integer> bst=new BST<String,Integer>(); bst.put("L", 11); bst.put("P", 10); bst.put("M", 9); bst.put("X", 7); bst.put("H", 5); bst.put("C", 4); bst.put("R", 3); bst.put("A", 8); bst.put("E", 12); bst.put("S", 0); show(bst); System.out.println(bst.min()); bst.deleteMin(); show(bst); // System.out.println(bst.floor("O")); System.out.println(bst.min()); } public static void show(BST<String , Integer> bst) { for(String s:bst.keys()) { System.out.print(s+"-"+bst.get(s)+"-"+bst.rank(s)+" "); } System.out.println(); } }
2.说明:
(1)对于bst来说,删除操作需要√N,并且如果允许删除,插入和查找的性能也会变为√N
(2)对于最坏的情况(输入顺序或逆序)来说,三种操作都需要N。
(3)当输入是随机的时候,可以有lgN的性能保障,但是不像排序,我们无法保证输入是随机的,因此需要更好的算法,可以保证最坏情况向也能有lgN的性能。



