



链表基础知识:
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。 相比于线性表顺序结构,操作复杂。由于不必须按顺序存储,链表在插入的时候可以达到O(1)的复杂度,比另一种线性表顺序表快得多,但是查找一个节点或者访问特定编号的节点则需要O(n)的时间,而线性表和顺序表相应的时间复杂度分别是O(logn)和O(1)。
使用链表结构可以克服数组链表需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但是链表失去了数组随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大。链表最明显的好处就是,常规数组排列关联项目的方式可能不同于这些数据项目在记忆体或磁盘上顺序,数据的存取往往要在不同的排列顺序中转换。链表允许插入和移除表上任意位置上的节点,但是不允许随机存取。链表有很多种不同的类型:单向链表,双向链表以及循环链表。链表可以在多种编程语言中实现。像Lisp和Scheme这样的语言的内建数据类型中就包含了链表的存取和操作。程序语言或面向对象语言,如C,C++和Java依靠易变工具来生成链表。
特点:
链表和数组作为算法中的两个基本数据结构,在程序设计过程中经常用到。尽管两种结构都可以用来存储一系列的数据,但又各有各的特点。
数组的优势,在于可以方便的遍历查找需要的数据。在查询数组指定位置(如查询数组中的第4个数据)的操作中,只需要进行1次操作即可,时间复杂度为O(1)。但是,这种时间上的便利性,是因为数组在内存中占用了连续的空间,在进行类似的查找或者遍历时,本质是指针在内存中的定向偏移。然而,当需要对数组成员进行添加和删除的操作时,数组内完成这类操作的时间复杂度则变成了O(n)。
链表的特性,使其在某些操作上比数组更加高效。例如当进行插入和删除操作时,链表操作的时间复杂度仅为O(1)。另外,因为链表在内存中不是连续存储的,所以可以充分利用内存中的碎片空间。除此之外,链表还是很多算法的基础,最常见的哈希表就是基于链表来实现的。基于以上原因,我们可以看到,链表在程序设计过程中是非常重要的。本文总结了我们在学习链表的过程中碰到的问题和体会。
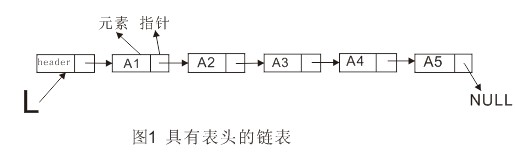
链表由一系列不必在内存中相连的结构构成,这些对象按线性顺序排序。每个结构含有表元素和指向后继元素的指针。最后一个单元的指针指向NULL。为了方便链表的删除与插入操作,可以为链表添加一个表头。
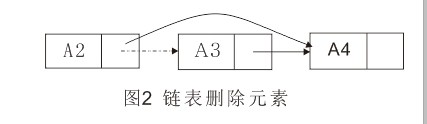
删除操作可以通过修改一个指针来实现。
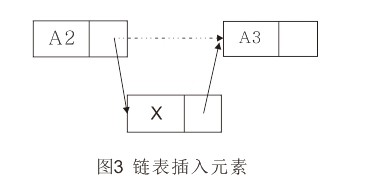
插入操作需要执行两次指针调整。
手动实现一个单向链表:
class Node:
def __init__(self,item):
self.item = item
self.next = None
a=Node(1)
b=Node(2)
c=Node(3)
a.next = b
b.next = c
print(a.next.next.item)
链表的创建和遍历
class Node:
def __init__(self,item):
self.item = item
self.next = None
def create_linklist(li): #头插法
head = Node(li[0]) # 头部第一个
for element in li[1:]:
node =Node(element)
node.next = head #新来的连上上一个
head = node
return head
def create_linklist_tail(li):
head = Node(li[0])
tail = head
for element in li[1:]:
node = Node(element)
tail.next = node #在链表尾部顺序插入li
tail = node
return head
def print_linklist(lk):
while lk:
print(lk.item,end=',')
lk = lk.next
lk = create_linklist([1,2,3])
print_linklist(lk)
print('')
lk = create_linklist_tail([1,2,3])
print_linklist(lk)


