


搜索引擎 Solr 简介
https://blog.csdn.net/qq_36807862/article/details/81116876
1.前言
企业站内搜索技术选型
在一些大型门户网站、电子商务网站等都需要站内搜索功能,使用传统的数据库查询方式实现搜索无法满足一些高级的搜索需求,比如:搜索速度要快、搜索结果按相关度排序、搜索内容格式不固定等,这里就需要使用全文检索技术实现搜索功能。
单独使用Lucene实现
单独使用Lucene实现站内搜索需要开发的工作量较大,主要表现在:索引维护、索引性能优化、搜索性能优化等,因此不建议采用。
使用Google或Baidu接口
通过第三方搜索引擎提供的接口实现站内搜索,这样和第三方引擎系统依赖紧密,不方便扩展,不建议采用。
使用Solr实现
基于Solr实现站内搜索扩展性较好并且可以减少程序员的工作量,因为Solr提供了较为完备的搜索引擎解决方案,因此在门户、论坛等系统中常用此方案。
2.初识Solr
Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化
Solr可以独立运行,运行在Jetty、Tomcat等这些Servlet容器中,Solr 索引的实现方法很简单,用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,Solr根据xml文档添加、删除、更新索引 。Solr 搜索只需要发送 HTTP GET 请求,然后对 Solr 返回Xml、json等格式的查询结果进行解析,组织页面布局。Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
solr是基于lucene开发企业级搜索服务器,实际上就是封装了lucene。
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的文件,生成索引;也可以通过提出查找请求,并得到返回结果
Solr类似webservice,调用接口,实现增加,修改,删除,查询索引库。
3.Lucence的短处
Lucene是一个开放源代码的全文检索引擎工具包,它不是一个完整的全文检索引擎,Lucene提供了完整的查询引擎和索引引擎,目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者以Lucene为基础构建全文检索引擎。
Solr的目标是打造一款企业级的搜索引擎系统,它是一个搜索引擎服务,可以独立运行,通过Solr可以非常快速的构建企业的搜索引擎,通过Solr也可以高效的完成站内搜索功能。
Solr类似webservice,提供接口,调用接口,发送一些特点语句,实现增加,删除,修改,查询。
4.Solrj
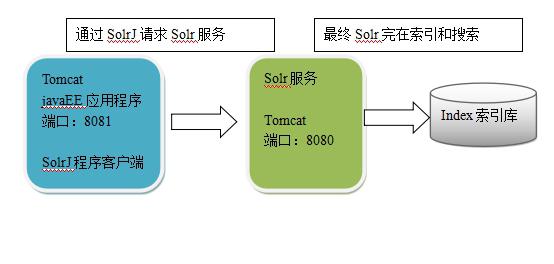
什么是SolrJ
solrj是访问Solr服务的java客户端,提供索引和搜索的请求方法,SolrJ通常在嵌入在业务系统中,通过SolrJ的API接口操作Solr服务
5.Solr优缺点
优点
- Solr有一个更大、更成熟的用户、开发和贡献者社区。
- 支持添加多种格式的索引,如:HTML、PDF、微软 Office 系列软件格式以及 JSON、XML、CSV 等纯文本格式。
- Solr比较成熟、稳定。
- 不考虑建索引的同时进行搜索,速度更快。
缺点
- 建立索引时,搜索效率下降,实时索引搜索效率不高。
6.其他基于Lucene的开源搜索引擎解决方案*
- 直接使用 Lucene
说明:Lucene 是一个 JAVA 搜索类库,它本身并不是一个完整的解决方案,需要额外的开发工作。
优点:成熟的解决方案,有很多的成功案例。apache 顶级项目,正在持续快速的进步。庞大而活跃的开发社区,大量的开发人员。它只是一个类库,有足够的定制和优化空间:经过简单定制,就可以满足绝大部分常见的需求;经过优化,可以支持 10亿+ 量级的搜索。
缺点:需要额外的开发工作。所有的扩展,分布式,可靠性等都需要自己实现;非实时,从建索引到可以搜索中间有一个时间延迟,而当前的“近实时”(Lucene Near Real Time search)搜索方案的可扩展性有待进一步完善
说明:基于 Lucene 的,支持分布式,可扩展,具有容错功能,准实时的搜索方案。
优点:开箱即用,可以与 Hadoop 配合实现分布式。具备扩展和容错机制。
缺点:只是搜索方案,建索引部分还是需要自己实现。在搜索功能上,只实现了最基本的需求。成功案例较少,项目的成熟度稍微差一些。因为需要支持分布式,对于一些复杂的查询需求,定制的难度会比较大。
说明:Map/Reduce 模式的,分布式建索引方案,可以跟 Katta 配合使用。
优点:分布式建索引,具备可扩展性。
缺点:只是建索引方案,不包括搜索实现。工作在批处理模式,对实时搜索的支持不佳。
说明:基于 Lucene 的一系列解决方案,包括 准实时搜索 zoie ,facet 搜索实现 bobo ,机器学习算法 decomposer ,摘要存储库 krati ,数据库模式包装 sensei 等等
优点:经过验证的解决方案,支持分布式,可扩展,丰富的功能实现
缺点:与 linkedin 公司的联系太紧密,可定制性比较差
说明:基于 Lucene,索引存在 cassandra 数据库中
优点:参考 cassandra 的优点
缺点:参考 cassandra 的缺点。
说明:基于 Lucene,索引存在 HBase 数据库中
优点:参考 HBase 的优点
缺点:参考 HBase 的缺点。另外,在实现中,lucene terms 是存成行,但每个 term 对应的 posting lists 是以列的方式存储的。随着单个 term 的 posting lists 的增大,查询时的速度受到的影响会非常大
