Gini 不纯度
一 概念:
Gini 不纯度研究"随机取数出错概率问题"。
假定,一件事正确概率为 0.5 , 出错概率为 1 - 0.5 = 0.5 。
1.1 概念的引入
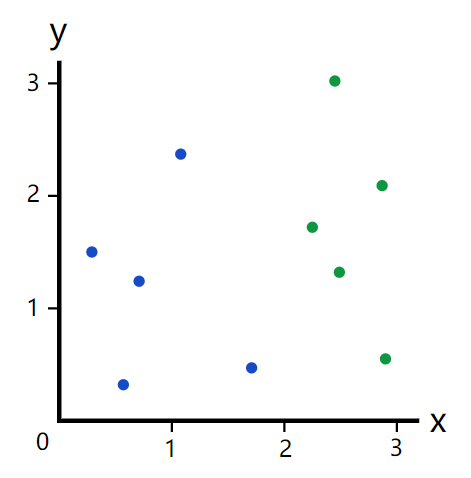
- 图1, 数据样本 ( 蓝点、绿点两种)
- 图2, 分类方式1 ( x=2 , 完美切分蓝点和绿点 )
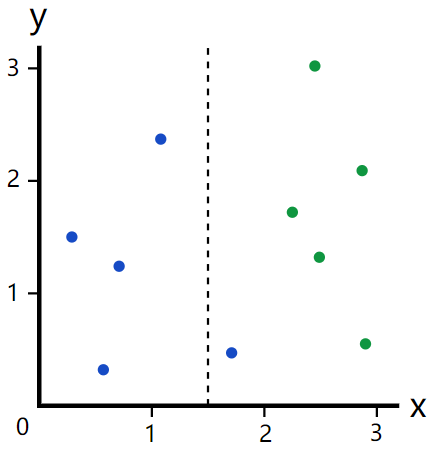
- 图3, 分类方式2 ( x=1.5 , 有杂志 )
问题:
【分类方式2】 没有 【分类方式1】 好, 但怎样用数据的方式表示该问题 ?
人们引入了“基尼不纯度”这个概念,英文名称是Gini Impurity , 用数学的方式描述该问题。

1.2 计算和公式
以上面对数据集举例子:
-
随机从数据集中选出一个点 ,计算分布概率
-
由于数据集中共有5个蓝点和5个绿点,所以随机选取的数据点有
- 50%的可能性是蓝点
- 50%的可能性是绿点 -
计算我们选取的数据点分错类的概率(这个概率就是基尼不纯度Gini Impurity):
**直觉告诉我们这个分错类的概率是0.5,因此使用随机分类的基尼不纯度就是0.5**
公式
这是一个最简单的情况,如果我们的数据集中有C个分类,一个数据点正好是第i个分类的概率是p(i),那么计算基尼不纯度的公式就是
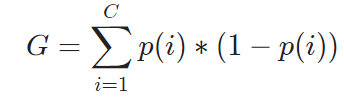
参考:
这样做的结果是左边是4个蓝点,右边是5个绿点和1个蓝点。很显然,这种划分没有上面的好,可是我们如何定量地比较划分结果的好坏呢?
