Python制作ip代理爬取与验证脚本(学会这个你就表格啥的都会爬了)
题记
今天上午看大佬文章又学到新东西了,这是是关于爬虫的,我感觉我已经会爬任何东西了(骄傲脸)。本来打算爬个代理ip试试水,半路突发奇想说书人那个验证ip的脚本,于是就一起来吧,我这比说书人那个简陋一些。我把我的脚本起名为上天入地无敌简单又看似很好的代理ip神经病脚本。感谢那个大佬写的文章让我接触到xpath helper插件,谁用谁知道。
正文
看完文章首先我安装了个xpath helper插件(商店一搜就有),他写的edusrc的爬取内容,我为了变通想起来前几天看到一个高匿代理的网站,于是尝试爬爬这个网站。
1 确定要爬的数据
点插件会弹个框,然后我们按住shift+x选择我们心怡的数据,这里我选择ip,多选几个查看变化,可以看到tr管行变化,td管列变化。


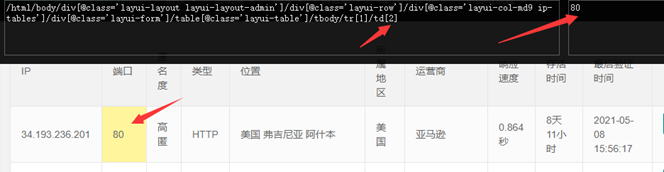
我们取值的时候这么取_element.xpath("//tbody/tr[" + str(k) + "]/td[1]/text()"),看到变化没删掉前面无用的,最后要多加一个/,要不获取不到数据。


2 编写脚本思路
我们的思路是把ip和端口获取到并且用:链接起来存到ip.txt文件,然后验证爬取的ip是否能用,把能用的存在ok.txt文件中。
http://ip.jiangxianli.com/?page=1这个网站page后控制页数。
3 效果截图
1、爬取页数设置
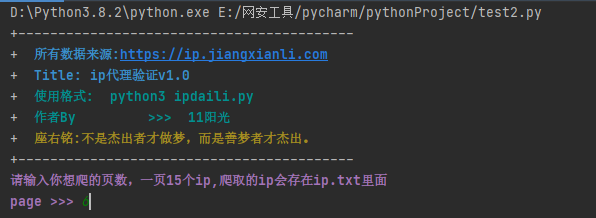
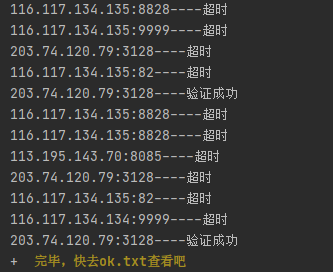
2、爬取完开始验证代理是否可用,我输的6页爬了90个ip。
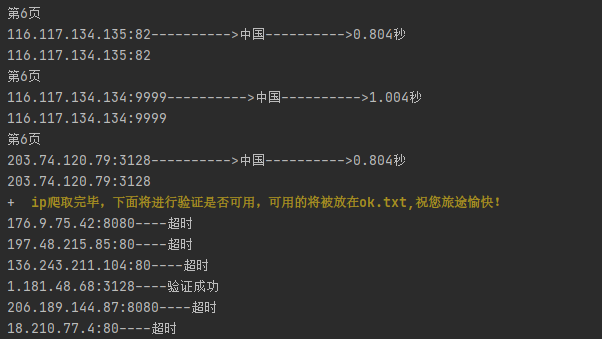
3、验证成功的存到ok.txt,一般来说国内的快,如果想看哪个是国内的,就复制可用ip搜索一下,前面有ip带国籍的。
4 完整代码
from lxml import etree import urllib3 import requests #爬取ip def school(i, k): manager = urllib3.PoolManager() http = manager print("第"+str(i)+"页") r = http.request( 'GET', "https://ip.jiangxianli.com/?page=" + str(i), headers={ 'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0", 'Host': "ip.jiangxianli.com", 'Cookie': "PSTM=1607346916; BIDUPSID=69AFB78A1A2E7FC19402DB7E41C448A8; BAIDUID=0A9A83EB086E30AD2E7AE714FAEF98A8:FG=1; __yjs_duid=1_b16d973dfef393feee90346dbe82f0d51619579133037; BDORZ=FFFB88E999055A3F8A630C64834BD6D0; ab_sr=1.0.0_MTU2NjJhNzIwOWMzM2EyNjM4NmZhOGNhOWQxYzI5YTAwZDQ1MmI3M2Y0NjE0NTY5MmJjMjFhMTQ5ODIzNzU2NzVhM2FlYTg4OWQ1OGNjYzI0YjQ4ODIwM2ExYWQ0OGQz; BDRCVFR[CfxpvPKvC2b]=mk3SLVN4HKm; delPer=0; PSINO=1; BDUSS=cweXRYaUlCSklGWFBoeG5VS3QyZERZdEpMYUR4Y1pjeW50ZWdhZm53MndoYjFnRUFBQUFBJCQAAAAAAAAAAAEAAABlbIWtstDR9LK7wM~QxAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAALD4lWCw-JVgQj; BDUSS_BFESS=cweXRYaUlCSklGWFBoeG5VS3QyZERZdEpMYUR4Y1pjeW50ZWdhZm53MndoYjFnRUFBQUFBJCQAAAAAAAAAAAEAAABlbIWtstDR9LK7wM~QxAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAALD4lWCw-JVgQj; BDRCVFR[pNjdDcNFITf]=mk3SLVN4HKm; H_PS_PSSID=33985_33966_31254_34004_33759_33675_33607_26350_33996; BA_HECTOR=a48g810h8k810124f01g9bvg30r" }, timeout=4.0 ) html = r.data.decode('utf-8', 'ignore') _element = etree.HTML(html) text = _element.xpath("//tbody/tr[" + str(k) + "]/td[1]/text()") port = _element.xpath("//tbody/tr[" + str(k) + "]/td[2]/text()") coun = _element.xpath("//tbody/tr[" + str(k) + "]/td[6]/text()") su = _element.xpath("//tbody/tr[" + str(k) + "]/td[8]/text()") ipdata = '\n'.join(text) port2 = '\n'.join(port) coun2 = '\n'.join(coun) su2 = '\n'.join(su) ipt=ipdata+":"+str(port2) ipo=ipdata+":"+str(port2)+"---------->"+coun2+"---------->"+su2 print(ipo) return ipt #检测代理是否可用 def check_proxy(): for ip in open('ip.txt'): ip_port = ip.replace('\n', '') proxy = { 'https': ip_port } headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_16_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36' } try: r = requests.get('http://www.baidu.com', headers=headers, proxies=proxy, timeout=3) if r.status_code == 200: print(ip_port+'----验证成功') with open(r'ok.txt', 'a+', encoding='utf-8') as a: a.write(ip_port + '\n') a.close() except: print(ip_port+'----超时') #介绍 def title(): print('+------------------------------------------') print('+ \033[1;34m所有数据来源:https://ip.jiangxianli.com \033[0m') print('+ \033[1;34mTitle: ip代理验证v1.0 \033[0m') print('+ \033[1;36m使用格式: python3 ipdaili.py \033[0m') print('+ \033[1;36m作者By >>> 11阳光 \033[0m') print('+ \033[1;33m座右铭:不是杰出者才做梦,而是善梦者才杰出。\033[0m') print('+------------------------------------------') #主函数 if __name__ == '__main__': title() page=str(input("\033[1;35m请输入你想爬的页数,一页15个ip,爬取的ip会存在ip.txt里面\npage >>> \033[0m")) for i in range(1, int(page)+1): for k in range(1, 16): text2=school(i,k) print(text2) with open(r'ip.txt','a+',encoding='utf-8') as f: f.write(text2+'\n') f.close() print('+ \033[1;33mip爬取完毕,下面将进行验证是否可用,可用的将被放在ok.txt,祝您旅途愉快!\033[0m') check_proxy() print('+ \033[1;33m完毕,快去ok.txt查看吧\033[0m')
参考文章
利用xpath爬取edu漏洞列表:http://0dayhack.net/index.php/1979/
说书人的脚本

 浙公网安备 33010602011771号
浙公网安备 33010602011771号