Shodan收集ip脚本加我的thinkphp日志漏洞探测脚本升级版
题记
前些天写了fofa利用cookie获取ip的脚本,fofa好像更新了,我的脚本宕机了,哎,正好前几天4个美刀买了shodan的会员,fofa为啥没买呢,当然是我现在穷啊,呜呜呜。于是这次搞个sadan的脚本,一劳永逸。Shodan不一样的是他更加简便,他可以成为一个模块集成在python里面,只要引入key就可以了。
模块引入
pip3 install shodan //安装shodan模块
shodan init <api key> //初始化
shodan count apache //搜索apache的数量

Pychrm模块引入更简单了,直接在下面那搜完安装即可,我的环境是python3,2的环境变量被我删了,用的时候在写上就行。(另外我的pycharm已经破解到2099了哦)
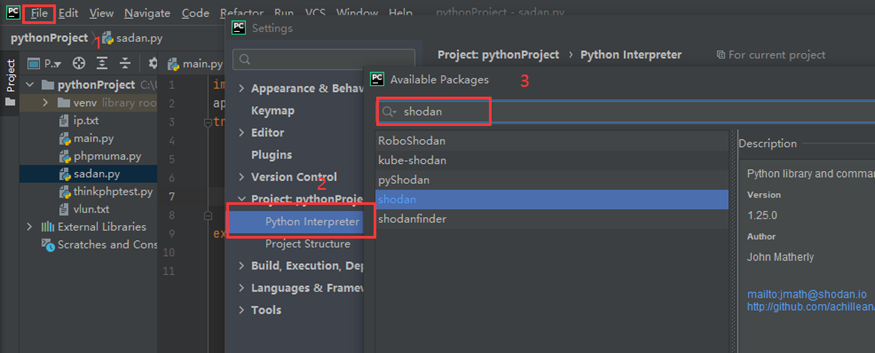
代码编写
1、先写一个简单的脚本,扫描 apache 的主机
import shodan #导入shodan库 api=shodan.Shodan("CJ25") #指定API_KEY,返回句柄 try: results=api.search('apache') #搜索apache,返回 JSON格式的数据 print(results) print("Results found:%s"%results['total']) for result in results['matches']: print(result['ip_str']) #打印出ip地址 except shoadn.APIError as e: #这里注意python3这么写,python2写except shoadn.APIError,e。 print("Error:%s"%e)
我们先看下他返回的json格式在看我们的代码会清晰很多,代码是根据返回内容取值的,真实的json格式很乱的,我们就看下面美化过的,结合上面的扫描脚本,我们可以看出results['total']是直接取的json的total值,for result in results['matches']代表进入matches字段取值,所以在这个循环内我们可以直接打印出ip_str中的ip。
{ 'total': 8669969, 'matches': [ { 'data': 'HTTP/1.0 200 OK\r\nDate: Mon, 08 Nov 2010 05:09:59 GMT\r\nSer...', 'hostnames': ['pl4t1n.de'], 'ip': 3579573318, 'ip_str': '89.110.147.239', 'os': 'FreeBSD 4.4', 'port': 80, 'timestamp': '2014-01-15T05:49:56.283713' }, ... ] }
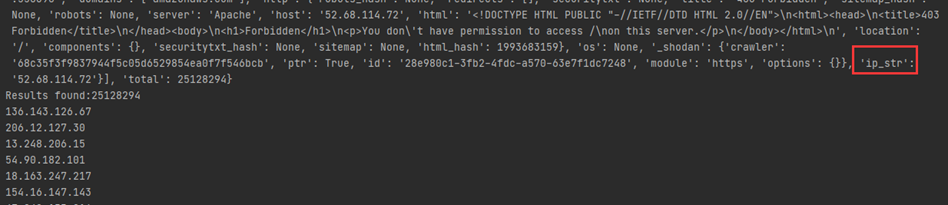
2、把获取的ip存储到target.txt
import shodan api=shodan.Shodan("CJ25") def FindTarget(): try: f = open(r'target.txt', 'a+') results = api.search('thinkphp country:"CN"') print("Results found:%s" % results['total']) for result in results['matches']: url = result['ip_str'] + ":" + str(result['port']) print(url) f.write("http://"+url) f.write("\n") f.close() except shodan.APIError as e: print("Error:%s" % e) FindTarget()
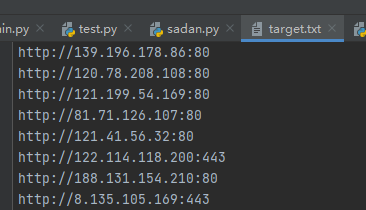
这里加一些我新改的脚本,用来检测thinkphp日志漏洞改进的,不需要的可以不看。
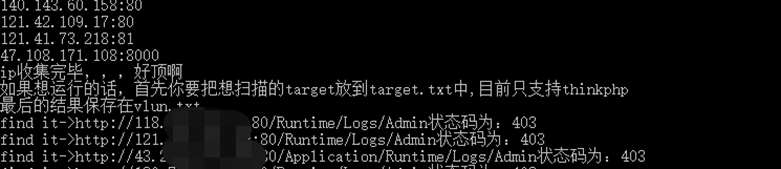
我的想法是这样的,先shadan获取带http://的ip地址存到target.txt,然后检测这些地址是否存在漏洞,存在的话保存到vlun.txt。因为我习惯发现日志漏洞存在单个网址拿出来跑,所以就分开功能了。
一、代码
import shodan import time import requests import sys api=shodan.Shodan("CJ25") #写你自己的api def FindTarget(): print('收集ip开始。。。') try: f = open(r'target.txt', 'a+') results = api.search(sys.argv[3]) print("Results found:%s" % results['total']) for result in results['matches']: url = result['ip_str'] + ":" + str(result['port']) print(url) f.write("http://"+url) f.write("\n") f.close() print('ip收集完毕,,,好顶啊') except shodan.APIError as e: print("Error:%s" % e) def tance(): print("如果想运行的话,首先你要把想扫描的target放到target.txt中,目前只支持thinkphp") payload_o = '/Application/Runtime/Logs/Admin' payload_t = '/Runtime/Logs/Admin' print("最后的结果保存在vlun.txt") for ip in open('target.txt'): # 把换行利用正则换成空格 ip = ip.replace('\n', '') ipo = ip + payload_o ipt = ip + payload_t # 容错处理 try: vlun_o = requests.get(ipo).status_code vlun_t = requests.get(ipt).status_code # if vlun_o==403 or vlun_o==200: # if vlun_o==200: if vlun_o == 403: print('find it->' + ipo + '状态码为:' + str(vlun_o)) # 如果里面想输入汉字的话一定要编码 with open(r'vlun.txt', 'a+', encoding='utf-8') as f: # 尝试读取爆出403的网站保存格式最后为ip------状态码为:403 # f.write(ipo+'---------'+'状态码为:'+str(vlun_o)+'\n') # 尝试读取爆出403的网站保存格式最后为ip f.write(ipo + '\n') f.close() # if vlun_t==403 or vlun_t==200: # if vlun_t==200: if vlun_t == 403: print('find it->' + ipt + '状态码为:' + str(vlun_t)) with open(r'vlun.txt', 'a+', encoding='utf-8') as f: # 尝试读取爆出403的网站保存格式最后为ip------状态码为:403 # f.write(ipt+'---------'+'状态码为:'+str(vlun_t)+'\n') # 尝试读取爆出403的网站保存格式最后为ip f.write(ipt + '\n') f.close() time.sleep(0.5) except Exception as e: pass if len(sys.argv[1])==1: FindTarget() # 收集框架ip,存到target.txt try: if len(sys.argv[2])==2: tance() # thinkphp漏洞探测 except Exception as s: pass
二、使用方法
收集ip不探测:Python |py文件名 |一位数 |一位数|shadon查询语法。

不收集ip只探测thinkphp日志漏洞:Python |py文件名 |两位数 |两位数|shadon查询语法。

收集ip并探测:Python |py文件名 |一位数|两位数|shadon查询语法。

三、踩坑记录
原来我对sys的理解有些错误,原来len(sys.argv[3])是对第3个输入参数长度的判断,成功想办法完成了这个python小程序,醉了,我说为啥我的一直有点问题,因为shadon查询语句有""号,还有空格,他识别起来有难度,看下边测试结果。经过改进把第二个函数的控制权写到了第二个参数的地方。

参考文章
Python中shodan模块的使用:http://xie1997.blog.csdn.net/article/details/84035254
Shodan API使用指南 撒旦网:http://blog.csdn.net/whatday/article/details/84643795
还有我灵活的脑袋瓜子!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号