

协程
进程与线程
有一定基础的小伙伴们肯定都知道进程和线程。
进程是什么呢?
直白地讲,进程就是应用程序的启动实例。比如我们运行一个游戏,打开一个软件,就是开启了一个进程。
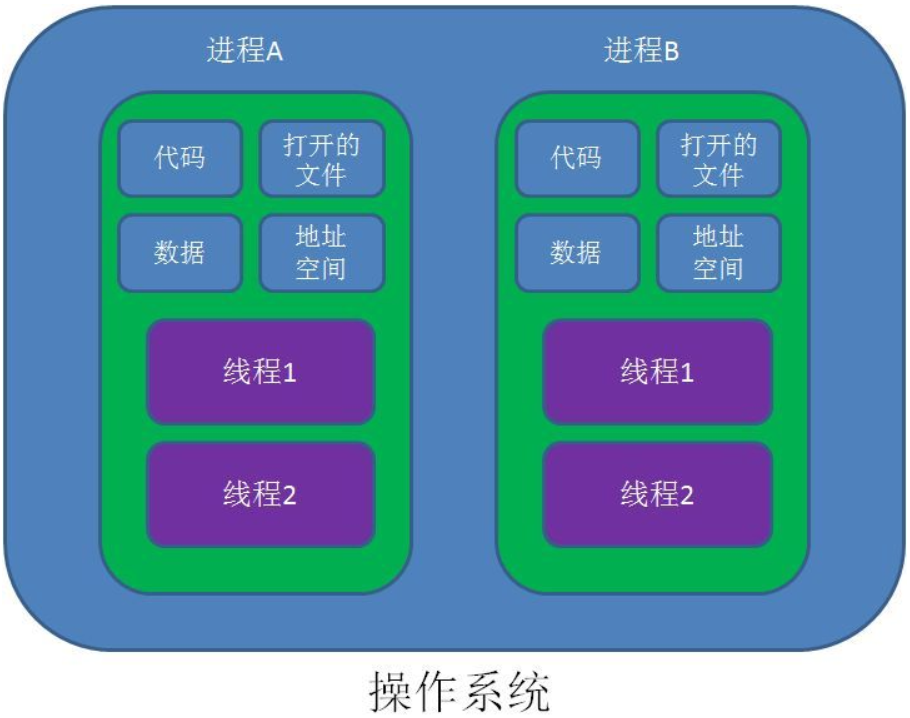
进程拥有代码和打开的文件资源、数据资源、独立的内存空间。
线程又是什么呢?
线程从属于进程,是程序的实际执行者。一个进程至少包含一个主线程,也可以有更多的子线程。
线程拥有自己的栈空间。
有人给出了很好的归纳:
对操作系统来说,线程是最小的执行单元,进程是最小的资源管理单元。
无论进程还是线程,都是由操作系统所管理的。
协程
协程:是一种用户态的轻量级线程,调度完全由用户控制;协程拥有自己的寄存器上下文和栈;
协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。
线程和协程的区别:
一个线程可以多个协程,一个进程也可以单独拥有多个协程;进程线程都是同步机制,而协程则是异步;协程能保留上一次调用时的状态,每次过程重入时,就相当于进入上一次调用的状态。
协程具体介绍
线程之间是如何进行协作的呢?
最经典的例子就是生产者/消费者模式:
若干个生产者线程向队列中写入数据,若干个消费者线程从队列中消费数据。

我们可以举个简单的例子:
public class ProducerConsumerTest { public static void main(String args[]) { final Queue<Integer> sharedQueue = new Queue(); Thread producer = new Producer(sharedQueue); Thread consumer = new Consumer(sharedQueue); producer.start(); consumer.start(); } } class Producer extends Thread { private static final int MAX_QUEUE_SIZE = 5; private final Queue sharedQueue; public Producer(Queue sharedQueue) { super(); this.sharedQueue = sharedQueue; } @Override public void run() { for (int i = 0; i < 100; i++) { synchronized (sharedQueue) { while (sharedQueue.size() >= MAX_QUEUE_SIZE) { System.out.println("队列满了,等待消费"); try { sharedQueue.wait(); } catch (InterruptedException e) { e.printStackTrace(); } } sharedQueue.add(i); System.out.println("进行生产 : " + i); sharedQueue.notify(); } } } } class Consumer extends Thread { private final Queue sharedQueue; public Consumer(Queue sharedQueue) { super(); this.sharedQueue = sharedQueue; } @Override public void run() { while (true) { synchronized (sharedQueue) { while (sharedQueue.size() == 0) { try { System.out.println("队列空了,等待生产"); sharedQueue.wait(); } catch (InterruptedException e) { e.printStackTrace(); } } int number = sharedQueue.poll(); System.out.println("进行消费 : " + number); sharedQueue.notify(); } } } }
1.定义了一个生产者类,一个消费者类。
2.生产者类循环100次,向同步(阻塞)队列当中插入数据。
3.消费者循环监听同步队列,当队列有数据时拉取数据。
4.如果队列满了(达到5个元素),生产者阻塞。
5.如果队列空了,消费者阻塞。
上面的代码正确地实现了生产者/消费者模式,但是却并不是一个高性能的实现。为什么性能不高呢?原因如下:
1.涉及到同步锁。
2.涉及到线程阻塞状态和可运行状态之间的切换。
3.涉及到线程上下文的切换。
以上涉及到的任何一点,都是非常耗费性能的操作。
所以这里就会用到协程的概念
协程,英文Coroutines,是一种比线程更加轻量级的存在。正如一个进程可以拥有多个线程一样,一个线程也可以拥有多个协程。
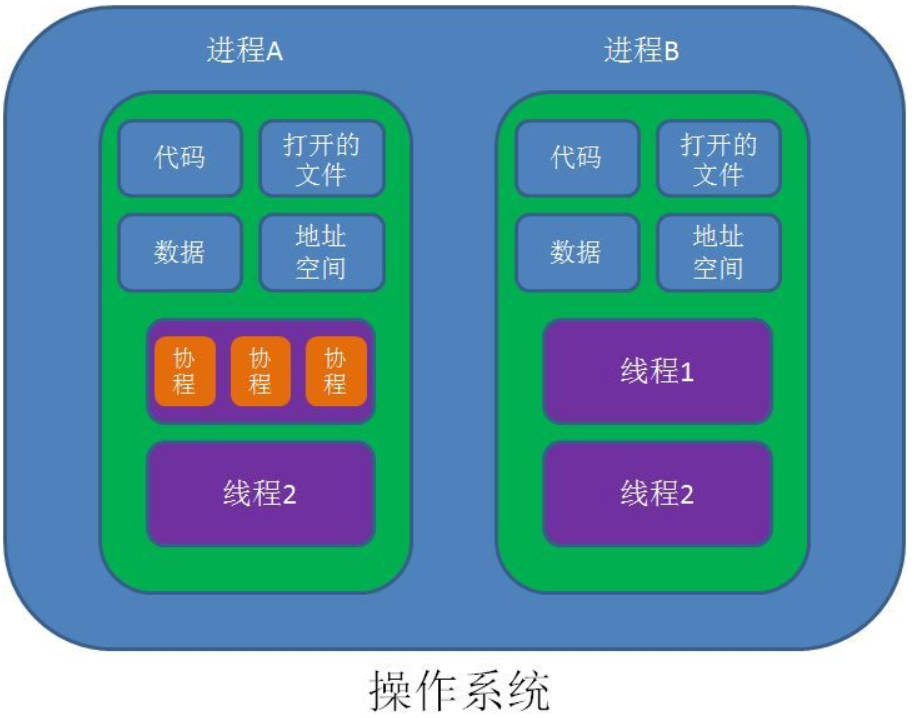
最重要的是,协程不是被操作系统内核所管理,而完全是由程序所控制(也就是在用户态执行)。
这样带来的好处就是性能得到了很大的提升,不会像线程切换那样消耗资源。
既然协程这么好,它到底是怎么来使用的呢?
def consumer(): while True: number = yield print('开始消费',number) consumer = consumer() next(consumer) for num in range(100): print('开始生产',num) consumer.send(num)
这段代码十分简单,即使没用过python的小伙伴应该也能基本看懂。
代码中创建了一个叫做consumer的协程,并且在主线程中生产数据,协程中消费数据。
其中 yield 是python当中的语法。当协程执行到yield关键字时,会暂停在那一行,等到主线程调用send方法发送了数据,协程才会接到数据继续执行。
但是,yield让协程暂停,和线程的阻塞是有本质区别的。协程的暂停完全由程序控制,线程的阻塞状态是由操作系统内核来进行切换。
因此,协程的开销远远小于线程的开销。

