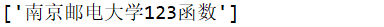Python学习——正则表达式
match方法:
match尝试从字符串的起始位置开始匹配
-
如果起始位置没有匹配成功, 返回None;
-
如果起始位置匹配成功, 返回一个对象, 通过group方法获取匹配的内容;
import re # re:regular express 正则表达式 aObj = re.match(r'we', 'wetoshello') print(aObj) print(aObj.group()) # \d 单个数字 # \D \d的取反 , 除了数字之外 bObj = re.match(r'\d', '1westos') if bObj: print(bObj.group()) bObj = re.match(r'\D', '_westos') if bObj: print(bObj.group())
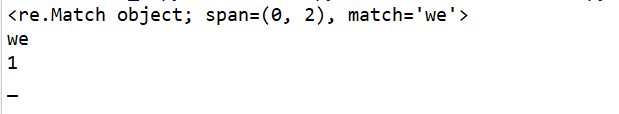
findall方法:
findall会扫描整个字符串, 获取匹配的所有内容;
import re res = re.findall(r'\d\d', '阅读数为2 点赞数为10') print(res)

search方法:
search会扫描整个字符串, 只返回第一个匹配成功的内容的SRE对象;
resObj = re.search(r'\d', '阅读数为8 点赞数为10') if resObj: print(resObj.group())

二、正则表达式的特殊字符类
字符类:
[ ]匹配括号内多个字符中的任意一个字符
[^ ]表示匹配除了括号内的任意一个字符
-
[a-z]:匹配任意一个小写字母
-
[A-Z]:匹配任意一个大写字母
-
[a-zA-Z0-9]:匹配任意一个小写或大写字母或数字
-
[^0-9]:匹配除了数字的任意一个字符
特殊字符类:
-
.: 匹配除了\n之外的任意字符; [.\n]
-
\d: digit–(数字), 匹配一个数字字符, 等价于[0-9]
-
\D: 匹配一个非数字字符, 等价于[^0-9]
-
\s: space(广义的空格: 空格, \t, \n, \r), 匹配单个任何的空白字符;
-
\S: 匹配除了单个任何的空白字符;
-
\w: 字母数字或者下划线, [a-zA-Z0-9_]
-
\W: 除了字母数字或者下划线, [^a-zA-Z0-9_]
^: 在[]前面表示以什么开头,在[]里面表示除括号内字符之外的任意一个字符^: 以什么开头
$: 以什么结尾
# 匹配数字 # pattern = r'\d' pattern = r'[0-9]' string = "hello_1$%" print(re.findall(pattern, string)) # 匹配字母数字或者下划线; # pattern = r'\w' pattern = r'[a-zA-Z0-9_]' string = "hello_1$%" print(re.findall(pattern, string)) # 匹配除了字母数字或者下划线; # pattern = r'\W' pattern = r'[^a-zA-Z0-9_]' string = "hello_1$%" print(re.findall(pattern, string)) # .: 匹配除了\n之外的任意字符; [.\n] print(re.findall(r'.', 'hello westos\n\t%$'))

指定字符出现的次数
匹配字符出现次数:
*: 代表前一个字符出现0次或者无限次; \d*, .*
+: 代表前一个字符出现一次或者无限次; \d+
?: 代表前一个字符出现1次或者0次; 假设某些字符可省略, 也可以不省略的时候使用,即去贪婪
第二种方式
{m}: 前一个字符出现m次;
{m,}: 前一个字符至少出现m次; * == {0,}; + ==={1,}
{m,n}: 前一个字符出现m次到n次; ? === {0,1}
# *: 代表前一个字符出现0次或者无限次; \d *,.* print(re.findall(r'\d*', '234')) print(re.findall(r'.*', 'hello223%')) print(re.findall(r'd*', 'ddhello223%')) # +: 代表前一个字符出现一次或者无限次; d+ print(re.findall(r'd+', '')) print(re.findall(r'd+', 'dddderrttt')) print(re.findall(r'\d+', '阅读数: 8976 点赞数:900')) # ?: 代表前一个字符出现1次或者0次; 假设某些字符可省略, 也可以不省略的时候使用 # 2019-10 print(re.findall(r'\d+-?\d+', '2019-10')) print(re.findall(r'\d+-?\d+', '201910')) print(re.findall(r'\d{4}-?\d{1,}', '2019-1')) print(re.findall(r'\d{4}-?\d{1,2}', '2019-10')) print(re.findall(r'\d+-?\d+', '201910'))

三、北美号码的合法性
问题描述: 北美电话的常用格式:(eg: 2703877865)
前3位: 第一位是区号以2~9开头 , 第2位是0~8, 第三位数字可任意; 中间三位数字:第一位是交换机号, 以2~9开头, 后面两位任意 最后四位数字: 数字不做限制;
# 传统正则 pattern = r'[2-9][0-8]\d[2-9]\d\d\d\d\d\d'
# 可以利用重复符号的方式 pattern = r'[2-9][0-8]\d[2-9]\d{6}'
def is_valid(pattern,tel): telObj=re.search(pattern,tel) if telObj: print('%s合法' %(tel)) else: print('%s不合法' %(tel)) if __name__ == '__main__': pattern = r'[2-9][0-8]\d[2-9]\d{6}' is_valid(pattern,'2777777777') is_valid(pattern,'1777777777')

四、分组匹配
表示分组
-
| : 匹配| 左右任意一个表达式即可;
-
(ab): 将括号中的字符作为一个分组
-
\num: 引用分组第num个匹配到的字符串
-
(?P): 分组起别名
-
(?P=name) : 引用分组的别名
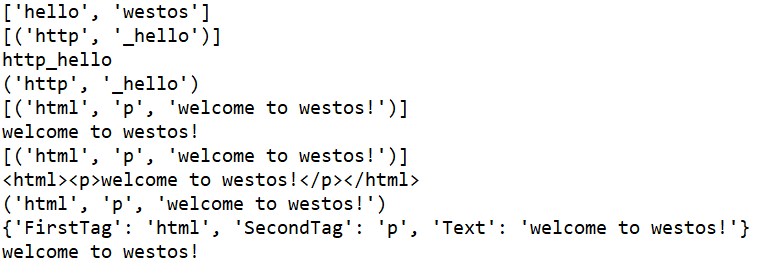
print(re.findall(r'westos|hello', "hellowestos")) # 进行分组的时候, findall方法只返回分组里面的内容; print(re.findall(r'(http|https)(.+)', 'http_hello')) # search sreObj = re.search(r'(http|https)(.+)', 'http_hello') if sreObj: # group方法会返回匹配的所有内容; print(sreObj.group()) # groups方法返回分组里面的内容; print(sreObj.groups()) # 需求: 获取标签里面的文字, 并判断标签是否成对出现? htmlStr = "<html><p>welcome to westos!</p></html>" pattern = r'<(\w+)><(\w+)>(.+)</\2></\1>' print(re.findall(pattern, htmlStr)) print(re.findall(pattern, htmlStr)[0][2]) # 需求: 分组起别名? htmlStr = "<html><p>welcome to westos!</p></html>" pattern = r'<(?P<FirstTag>\w+)><(?P<SecondTag>\w+)>(?P<Text>.+)' \ r'</(?P=SecondTag)></(?P=FirstTag)>' print(re.findall(pattern, htmlStr)) sreObj = re.search(pattern, htmlStr) if sreObj: print(sreObj.group()) print(sreObj.groups()) print(sreObj.groupdict()) print(sreObj.groupdict()['Text'])
五、练习之URL合法性验证
问题描述: 检查某段给定的文本是否是一个符合需要的URL;
思路:
1). 检查URL是否以web浏览器普遍采用的通信协议方案开头: http, https, ftp file
2). 协议后面紧跟 :// 3). 协议后面字符任意;
def isUrl(url): pattern = re.compile(r'^(http|https|ftp|file)://.+$') resObj = re.search(pattern, url) if resObj: return True return False if __name__ == '__main__': print(isUrl('file:///tmp')) print(isUrl('http://www.baidu.com')) print(isUrl('https://www.baidu.com')) print(isUrl('ftp://www.baidu.com'))

六、匹配汉字
字符串是否包含中文 []表示匹配方括号的中任意字符,\u4e00是Unicode中汉字的开始,\u9fa5则是Unicode中汉字的结束
user = '南京邮电大学123函数' pattern = r'[\w\-\u4e00-\u9fa5]+' print(re.findall(pattern, user))