
Python3.5学习——文件操作&字符编码与转码
本节内容:
1、字符串操作
2、字典操作
3、集合
4、文件操作
5、字符编码与转码
6、函数与函数式编程
一、字符串操作
name='kobe' name.capitalize() 首字母大写 name.casefold() 大写全部变小写 name.center(50,"-") 输出 '---------------------kobe----------------------' name.count('be') 统计be出现次数 name.encode() 将字符串编码成bytes格式 name.endswith("Li") 判断字符串是否以 Li结尾 name.find('A') 查找A,找到返回其索引, 找不到返回-1 format : >>> msg = "his name is {}, and age is {}" >>> msg.format("kobe",22) 'my name is kobe, and age is 22' >>> msg = "my name is {1}, and age is {0}" >>> msg.format("kobe",22) 'my name is 22, and age is kobe' >>> msg = "my name is {name}, and age is {age}" >>> msg.format(age=22,name="kobe") 'my name is kobe, and age is 22' format_map >>> msg.format_map({'name':'kobe','age':22}) 'my name is kobe, and age is 22' msg.index('a') 返回a所在字符串的索引 '9aA'.isalnum() 判断是否阿拉伯数字或字母,是则返回true '9'.isdigit() 是否整数 name.isnumeric 是否数字 name.isprintable 是否可打印 name.isspace 是否是空格 name.istitle 是否首字母大写 name.isupper 是否大写 "+".join(['alex','jack','rain']) 'alex+jack+rain' maketrans >>> intab = "aeiou" #This is the string having actual characters. >>> outtab = "12345" #This is the string having corresponding mapping character >>> trantab = str.maketrans(intab, outtab) >>> >>> str = "this is string example....wow!!!" >>> str.translate(trantab) 'th3s 3s str3ng 2x1mpl2....w4w!!!' msg.swapcase 大小写互换 msg.zfill(40) 打印40个字符,不够则前面补0 n4.ljust(40,"-") 保证打印够40个字符,不够后面用-补齐 ‘Hello 2orld-----------------------------' n4.rjust(40,"-") 保证打印够40个字符,不够前面用-补齐
'-----------------------------Hello 2orld'
>>> b="ddefdsdff_哈哈"
b.isidentifier() #检测一段字符串可否被当作标志符,即是否符合变量命名规则 True
二、字典操作
字典是一种key-value(即键-值)的数据类型,使用时就像字典,通过笔画、字母来查询对应页的内容。
1、一级字典
下面举一个一级字典的简单例子:
__author__ = 'Sunny Han' info={ 'stu1101':'han', 'stu1102':'duan', 'stu1103':'wang', } print(info)
代码执行结果如下:

可以看出字典打印出来是无序的,也就不能用下标索引。
字典也有许多其他操作,举例如下:
info={ 'stu1101':'han', 'stu1102':'duan', 'stu1103':'wang', } b={'stu1101':'mao', 'stu1104':'li', 'stu1105':'zhao',} info.update(b) #将字典info更新为b,即原有的key值相同的换成字典b的value值,之 前字典info不存在而字典b存在的key值内容则直接添加进去 print(info) print(info['stu1101']) #打印key值为1101所对应的value值 print(info.get('stu1108')) #查询是否存在key值为1108的相应内容,若存在则直接打 印出来对应的value值,不存在则返回None print('stu1101' in info) #判断是否存在key值为1101的内容,存在则返回True,不存 在返回False print(info.keys()) #打印字典中所有的key值 print(info.values()) ##打印字典中所有的value值 print(info.items()) #把字典打印为一个列表 for i in info: #循环打印字典内容 print(i,info[i]) for k,v in info.items(): #循环打印字典内容 print(k,v)
代码执行结果如下:

2、多级字典嵌套及操作
player_catalog={ 'west':{'kobe':'GOAT', 'CP3':'GREAT DRRIBLER', 'MELO':'OLD GUY' }, 'EAST':{'LBJ':'ATHLETIC', 'ANSWER':['FASTEST','SHOOTER']} } player_catalog['EAST']['ANSWER'][0]='NO PASS' print(player_catalog['EAST'].get('LBJ')) print(player_catalog.keys()) print(player_catalog.values()) player_catalog.setdefault('china',{'YI':['strong','smart']}) #创建一个新的字典内容 print('-->',player_catalog.values()) print('-->',player_catalog.keys())
代码执行结果如下:

3、三级菜单
通过上面的学习我们可以尝试着写一个三级菜单,并能实现
- 打印三级菜单
- 可返回上一级
- 可随时退出程序
以上三个功能,代码示例如下:
data={ '北京':{ '昌平':{ '沙河':{'oldboy','test'}, '天通苑':{'链家地产','我爱我家'} }, '朝阳':{'望京':['奔驰','陌陌'], '国贸':{'CICC','HP'}, '东直门':{'advent','飞信'} }, '海淀':{}, }, '山东':{'德州':{}, '青岛':{}, '济南':{}, }, '广东':{ '东莞':{}, '常熟':{}, '佛山':{} }, } exit_flag=False while not exit_flag: for i in data: print(i) choice=input('选择进入>>:') if choice in data: while not exit_flag: for i2 in data[choice]: print('\t',i2) choice2=input('请选择进入2>>:') if choice2 in data[choice]: while not exit_flag: for i3 in data[choice][choice2]: print('\t\t',i3) choice3=input('请选择进入3>>:') if choice3 in data[choice][choice2]: while not exit_flag: for i4 in data[choice][choice2][choice3]: print('\t\t',i4) choice4=input('最后一层,按b返回') if choice4=='b': pass elif choice4=='q': exit_flag=True if choice3=='b': break elif choice3=='q': exit_flag=True if choice2=='b': break elif choice2=='q': exit_flag=True
代码也能够实现相应的功能,有兴趣的可以自行练习一下。
三、集合
集合是一个无序的,不重复的数据组合,它的主要作用如下:
- 去重,把一个列表变成集合,就自动去重了
- 关系测试,测试两组数据之前的交集、差集、并集等关系
下面举一个简单的例子:
list_1=[1,4,5,6,8,6,5,9] #首先创建一个列表list_1 list_1=set(list_1) #将列表转化为集合,这时打印出来的重复项内容及(5,6)就只出现一次了 list_1.add(999) #添加一项 list_1.update([88,55]) #添加多项 list_1.remove(88) #删除指定的元素 list_2=set([2,6,5,9,7,32]) #创建集合list_2 list_3=set([1,4,5]) #创建集合list_3 print('一',list_1.discard(66)) #删除元素,若所删除的元素不存在,返回None print('二',list_1,type(list_1),len(list_1)) #打印list_1的内容、类型及长度 print('三',77 in list_1) #判断集合list_1是否包含77,不包含则返回False print('四',list_1.pop()) #随意删除一个集合元素 print('五',list_1,list_2) #打印list_1,list_2两个集合 print('六',list_2.intersection(list_1)) #打印list_1,list_2两个集合的交集 print('七',list_1&list_2) #打印list_1,list_2两个集合的交集 print('八',list_1.union(list_2)) #打印list_1,list_2两个集合的并集 print('九',list_1|list_2) #打印list_1,list_2两个集合的并集 print('十',list_1.difference(list_2)) #打印list_1,list_2两个集合的差集(list_1中有而list_2中没有) print('十一',list_1-list_2) #打印list_1,list_2两个集合的差集(list_1中有而list_2中没有) print('十二',list_2.difference(list_1)) #打印list_2,list_1两个集合的差集(list_2中有而list_1中没有) print('十三',list_3.issubset(list_1)) #判断集合list_3是否list_1的子集 print('十四',list_2.issubset(list_1)) #判断集合list_2是否list_1的子集 print('十五',list_1.symmetric_difference(list_2)) #打印list_1,list_2两个集合的对称差集(list_1中和list_2中没有互相没有的) print('十六',list_1^list_2) #打印list_1,list_2两个集合的对称差集(list_1中和list_2中没有互相没有的)
代码执行结果如下:

四、文件操作
1、文件操作流程:
- 打开文件,得到文件句柄并赋值给一个变量
- 通过句柄对文件进行操作
- 关闭文件
下面进行详细介绍:
首先建立一个文本文件‘yesterday’如下:
 yesterday
yesterday接下来我们对此文件进行一些基本的操作如下:
f = open('yesterday',encoding='utf-8') #打开文件 data = f.readline() print('first line:',data) #读一行 print('我是分隔线'.center(50,'-')) data2 = f.read()# 读取剩下的所有内容,文件大时不要用;这里要注意的是,当上面读完第一行之后,光标就会自动放在第一行末尾,故打印的是除第一行外的剩余部分 print(data2) #打印文件 f.close() #关闭文件
打开文件的模式有:
- r,只读模式(默认)。
- w,只写模式。【不可读;不存在则创建;存在则删除内容;】
- a,追加模式。【可读; 不存在则创建;存在则只追加内容;】
上述例子默认是只读模式‘r’,接下来介绍只写模式和追加模式:

f = open('yesterday3','w',encoding='utf-8') #创建一个新文件'yesterday3' f.write('我爱北京天安门\n') f.write('天安门上太阳升')
f = open('yesterday','a',encoding='utf-8') #对原文件'yesterday'进行追加 f.write('\n我爱你中国\n亲爱的母亲') #写追加内容
2、其它语法
若我们想对文件内容进行修改,我们可以做如下操作:
f=open('yesterday','r',encoding='utf-8') f_new=open('yesterday_bak','w',encoding='utf-8') for line in f: if '就如夜晚的微风' in line: line=line.replace('就如夜晚的微风','就好像夜晚的微风') f_new.write(line)
在这里我们就将原文件‘yesterday’中‘就如夜晚的微风’全都依次改为‘就好像夜晚的微风’。
为了避免打开文件后忘记关闭,可以通过使用with语句来帮助自动关闭文件,即:
with open('yesterday','r',encoding='utf-8')as f: for line in f: print(line)
五、字符编码与转码
首先借网络上比较经典的解释字符编码与解码的图来直观概括如下:
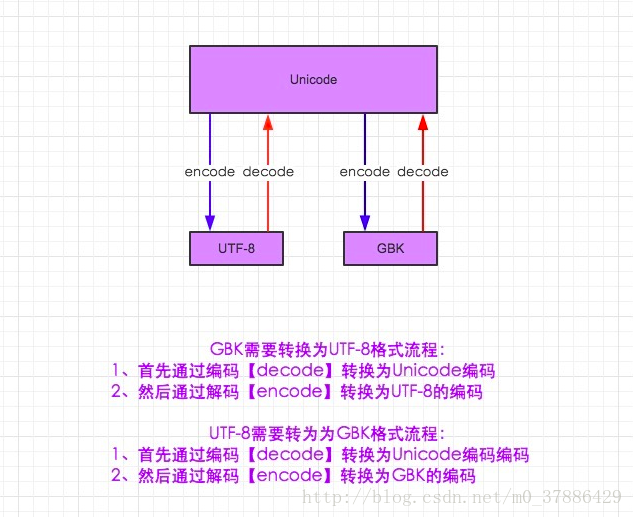
也就是说,所有不同的编码相互转换前首先要先转成Unicode,utf-8是Unicode的扩展集,GBK是中文软件。
举例如下:
import sys print(sys.getdefaultencoding()) #打印默认编码格式,为utf-8 s='你好' s_gbk=s.encode('gbk') #将‘你好’编码成‘gbk'格式 s_utf8=s.encode('utf-8') #将‘你好’编码成‘utf-8'格式 gbk_to_utf8=s_gbk.decode('gbk').encode('utf-8') #解码‘gbk’模式,再编码成‘utf-8'格式 ss=s_gbk.decode('gbk').encode('utf-8').decode('utf-8') print(s_gbk) print(s_utf8) print(gbk_to_utf8) print(ss)
代码执行结果如下:

六、函数与函数式编程
1、定义
函数定义:在一个变化过程中,对于自变量x,都有一个唯一对应的因变量y,它们间的关系可以表述为:y=f(x),其中f为映射关系。
编程中的函数定义:函数是逻辑结构化和过程化的一种编程方法。
python中函数的定义方法为:
def func1(x): '''the function definitions''' x += 1 return x
其中,def为定义函数的关键字。
func1为自定义的函数名,函数名后的括号内可以写形参,也可什么都不写。
三引号内为函数的文档描述,即介绍此函数的功能和用途。
x+=1,泛指代码块或程序处理逻辑,这里举例为 x+=1。
return定义返回值。
接下来我们举一个简单的调用函数的例子,如下:
def func1(): '''testing1''' print('in the func1') return 0 #定义了一个函数func1 def func2(): '''testing2''' print('in the func2') #无返回值,我们称它为定义了一个过程而非函数 x=func1() #调用函数func1 y=func2() #调用过程func2 print('from func1 return is %s'%x) #这里打印的是函数的返回值0 print('from func1 return is %s'%y) #这里因func2无返回值故打印NULL
代码执行结果如下:

我们可以从以上例子直观的看出函数与过程的区别。
使用函数有三大优点:1、代码重用。
2、保持一致性。
3、可扩展性
2、函数返回值
要想获取函数的执行结果,就可以用return语句把结果返回。
def test1(): print('in the test1') def test2(): print('in the test2') return 0 #返回值为0 def test3(): print('in the test2') return 1,'kobe',['west','east'],{'name':'howard'} #返回值类型,个数可不固定 x=test1() #调用test1 y=test2() #调用test2 z=test3() #调用test3 print(x) print(y) print(z)
代码运行结果如下:

我们可以看出返回值的类型,个数可以是不固定的。
在这里我们要注意的是:
- 函数在执行过程中只要遇到return语句,就会停止执行并返回结果,所以也可以理解为 return 语句代表着函数的结束。
- 如果未在函数中指定return,那这个函数的返回值为None。
在这里我们可以总结一下:返回值个数=0,返回None。
返回值个数=1,返回object。
返回值个数>1,返回tuple(元组)。
3、参数
接下来我们简单介绍一下函数中参数的使用方法,举例如下:
def test(x,y): #括号里的x,y称为形式参数,简称形参,本身不存在,不会占用空间 print(x) print(y) test(2,1) #这里将2,1称为实参,是真实存在的,其中2和1按照位置的先后顺序被分别赋值给x,y
代码执行结果如下:

在这里我们需要了解的是,实参赋值给形参有两种方法:位置参数调用和关键字调用,二者可以联合起来同时使用。其中如上例所示按照形参与实参的一一对应的位置来赋值的方法称为位置参数调用。
接下来我们介绍一下关键字调用,举例如下:
def test(x,y): #括号里的x,y称为形式参数,简称形参,本身不存在,不会占用空间 print(x) print(y) test(y=1,x=2) #关键字调用
代码执行结果和上例相同。也就是说,关键字调用关键在于要把实参的值一一赋给形参,顺序可以颠倒。
我们要注意的是,在同时使用关键字调用和位置参数调用时,关键字调用是不能写在位置参数调用前的。
4、默认参数与参数组
在实际中,我们常常需要给一些形参赋一个默认值以方便我们使用,这就是默认参数,举例如下:
def test(x,y=6): #形参y的值默认为6 print(x) print(y) test(5) #调用函数时可只给x赋值
代码执行结果如下:

当然,这里的默认值也是可以通过实参赋值来修改的,举例如下:
def test(x,y=6): print(x) print(y) test(5,3)
代码执行结果如下:

可以看到默认参数也是可以修改的。
5、参数组
在我们的实际工作中可能会遇到实参个数不确定的情况,那这样的话,如何在使用函数时定义形参成为了我们首先需要解决的问题,这里就需要用到参数组。
在这里我们举一个简单的例子如下:
def test(*args): print(args) test(1,2,3,4) test(*[1,5,6,4])
代码执行结果如下:

也就是说,在实参个数不确定时,我们在定义形参时的格式为*+‘变量名’。
若将位置参数调用与参数组结合起来使用,我们可以看到如下效果:
def test1(x,*args): print(x) print(args) test1(1,2,3,4)
代码执行结果如下:

以上的形参接收的为元组的形式,同样,形参也可以接收字典,格式为**+‘变量名’,举例如下:
def test2(**kwargs): print(kwargs) print(kwargs['name']) print(kwargs['age']) test2(name='kobe',age=39)
代码执行结果如下:

若将默认参数与字典结合起来:
def test4(name,age=18,**kwargs): print(name) print(age) print(kwargs) test4('kobe',sex='m',hobby='singing',age=39)
代码执行结果如下:

6、局部变量
在这一节我们介绍一下局部变量与全局变量的使用。
1、在子程序中定义的变量称为局部变量,在程序一开始定义的变量称为全局变量。
2、全局变量的作用域是整个程序,局部变量的作用域是定义该变量的子程序。
3、当全局变量与局部变量同名时,在定义局部变量的子程序内,局部变量起作用,在其他地方全局变量起作用。
接下来我们举个简单的例子来说明:
def change_name(name): print('before change',name) name='KOBE' #这里定义的即为局部变量,只在函数内生效 print('after change',name) name='kobe' #这里定义的则为全局变量,在整段程序内生效 change_name(name) print(name)
代码执行结果如下:

从这里我们就可以看出全局变量与局部变量间的明显差别。
但假若我们想在函数内也定义个全局变量应该怎么办呢?我们可以使用关键字‘global’,示例如下:
school='oldboy' def change_name(name): global school school='mage' print('before change',name,school) name='KOBE' print('after change',name) name='kobe' change_name(name) print(name) print(school)
代码执行结果如下:

我们可以看出,使用global在函数内部定义了全局变量之后,全局变量school的值由原来的‘oldboy’变为之后的‘mage’。
7、递归
在函数内部可以调用其他函数,若此函数调用自身,则为递归函数。
递归函数特性:
1、必须要有一个明确的结束条件。
2、每次进入更深一层递归时,问题规模相比上次递归应有所减少。
3、递归效率不高,递归层数过多时会导致栈溢出(在计算机中函数调用是通过栈(stack)来实现的,每当进入一个函数调用,栈就会增加一层栈帧,每当函数返回时,栈就会减一层栈帧,由于栈的大小有限,所以,若递归调用的次数过多,将会导致栈溢出)。
接下来举一个例子来说明栈溢出,如下:
def calc(n): print(n) return calc(n+1) calc(0)
代码执行结果如下(部分截图):
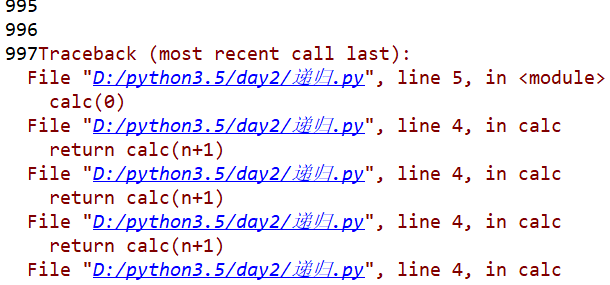
我们可以看到,该程序想要通过递归来实现循环加1的功能,但未设置结束条件,故代码只能执行到997(计算机极限),之后会报错。
接下来我们举一个成功利用递归的例子,如下:
def calc(n): print(n) if int(n/2)>0: return calc(int(n/2)) print('->',n) calc(10)
代码执行结果如下:

8、高阶函数
变量可以指向函数,函数的参数可以接收变量,那么一个函数就可以接收另一个函数作为参数,这种函数就叫做高阶函数。
举例如下:
def add(a,b,f): return f(a)+f(b) res=add(3,-6,abs) print(res)
代码执行结果为9,即abs(3)+abs(-6)=9。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号