
sparseinst简单理解
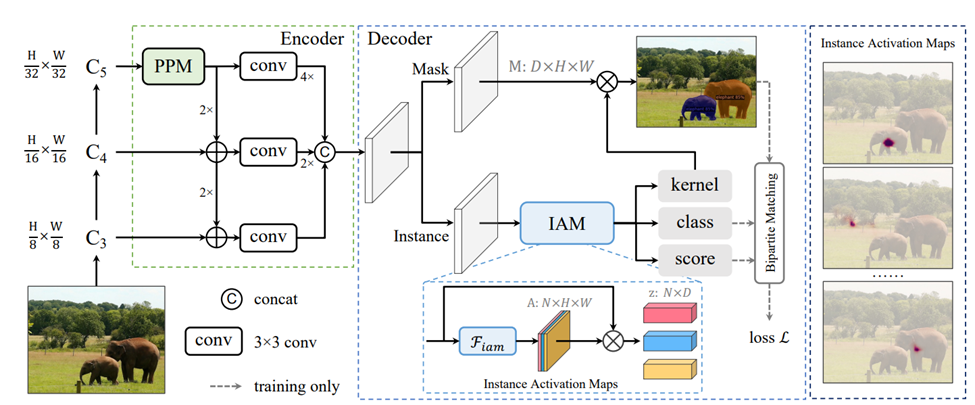
这个网络其实跟yolact有点像,差别在哪里呢?
几个点
- Self attention
- Nms free
- Coordconv
首先是encode, backbone提取特征,没有什么特别的。
encode的提取的特征先和坐标做一个concact。 然后decode的模块分为两部分,mask branch和instance branch,就像下面这样。 这个concact就是coordconv的设计思想。他可以达到根据坐标选取图像某一部分特征的目的。
|
coord_features = self.compute_coordinates(features) features = torch.cat([coord_features, features], dim=1) pred_logits, pred_kernel, pred_scores, iam = self.inst_branch(features) mask_features = self.mask_branch(features) |
根据作者给出的这个图,他的iam可以选取出不同部位的特征。
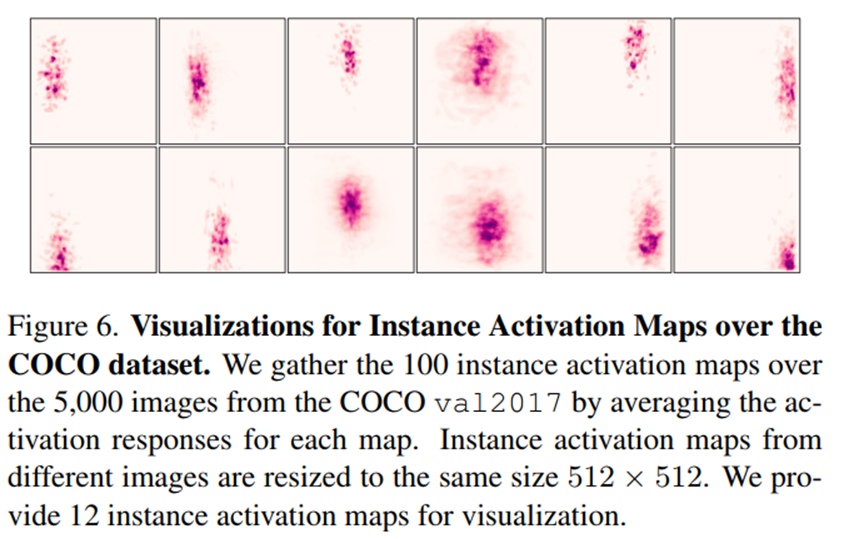
然后这个就是query, 这个去和原始的feature做bmm,就是矩阵相乘之后,得到的是每个像素的特征跟选出来的某个点的特征的相似度。然后这个attention map再去和mask的feature去做bmm,得到的是mask的output。是100个mask,每个mask就是对应一个objectness和类别。
这个角度来看,跟yolact其实是差不多的。
yolact生成coeffience的那个网络没有这么复杂,没有加attention和coordconv这些东西。
关于nms free, 如果用的是yolact可以也这么做吗?
不可以,yolact有anchor, 得到的框很多都是非常接近的。这边nms free就是说anchor是网路自己学到的。目前有两种方法去学,一个是transformer的方法,一个是位置编码coordconv。
一些detail
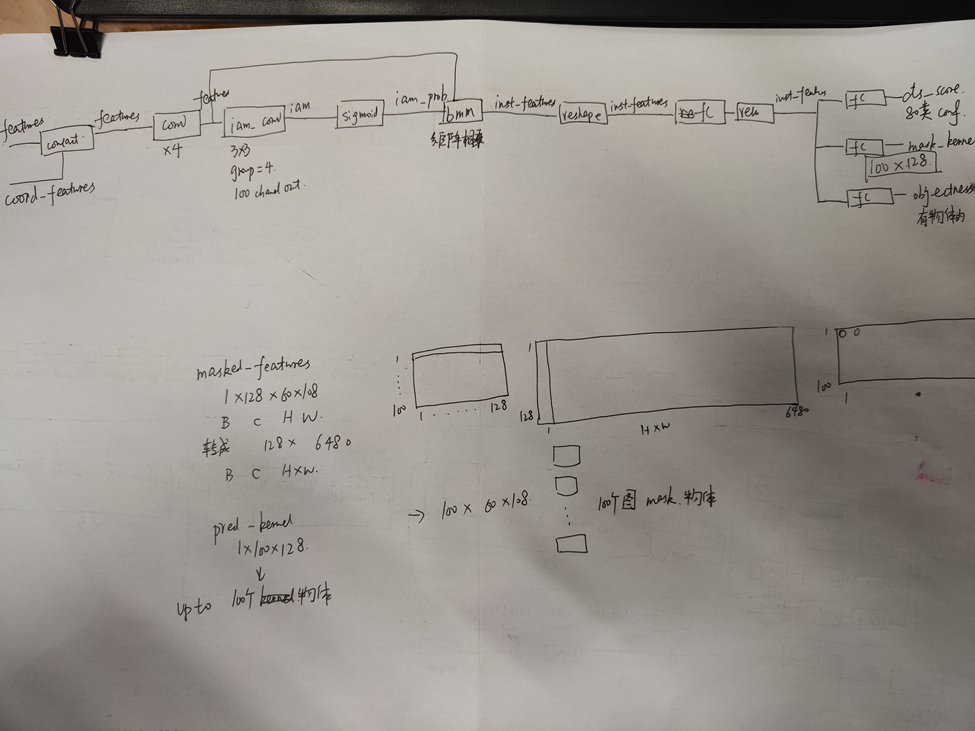
Fiam就是一些3x3的卷积
图中的x就是指的bmm,矩阵相乘
Inst branch的三个输出,第一个kernel的大小是100x128,就是每个物体一个128的kernel,这个1x128的kernel会和mask branch的feature 128x6480(H60xW108)去做矩阵相乘,这一部分和yolact的coeffiency很像的。yolact是32,这边是128。
Instance branch如下图所示。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号