biggan 参数解读
{'dataset': 'I128_hdf5', 'augment': False, 'num_workers': 8, 'pin_memory': True, 'shuffle': False, 'load_in_mem': False, 'use_multiepoch_sampler': False, 'model': 'BigGAN', 'G_param': 'SN', 'D_param': 'SN', 'G_ch': 64, 'D_ch': 64, 'G_depth': 1, 'D_depth': 1, 'D_wide': True, 'G_shared': False, 'shared_dim': 0, 'dim_z': 128, 'z_var': 1.0, 'hier': False, 'cross_replica ': False, 'mybn': False, 'G_nl': 'relu', 'D_nl': 'relu', 'G_attn': '64', 'D_attn': '64', 'norm_style': 'bn', 'seed': 0, 'G_init': 'ortho', 'D_init': 'ortho', 'skip_init': False, 'G_lr' : 5e-05, 'D_lr': 0.0002, 'G_B1': 0.0, 'D_B1': 0.0, 'G_B2': 0.999, 'D_B2': 0.999, 'batch_size': 64, 'G_batch_size': 0, 'num_G_accumulations': 1, 'num_D_steps': 2, 'num_D_accumulations': 1, 'split_D': False, 'num_epochs': 100, 'parallel': True, 'G_fp16': False, 'D_fp16': False, 'D_mixed_precision': False, 'G_mixed_precision': False, 'accumulate_stats': False, 'num_sta nding_accumulations': 16, 'G_eval_mode': False, 'save_every': 2000, 'num_save_copies': 2, 'num_best_copies': 2, 'which_best': 'IS', 'no_fid': False, 'test_every': 5000, 'num_inception_ images': 50000, 'hashname': False, 'base_root': '', 'data_root': 'data', 'weights_root': 'weights', 'logs_root': 'logs', 'samples_root': 'samples', 'pbar': 'mine', 'name_suffix': '', ' experiment_name': '', 'config_from_name': False, 'ema': False, 'ema_decay': 0.9999, 'use_ema': False, 'ema_start': 0, 'adam_eps': 1e-08, 'BN_eps': 1e-05, 'SN_eps': 1e-08, 'num_G_SVs': 1, 'num_D_SVs': 1, 'num_G_SV_itrs': 1, 'num_D_SV_itrs': 1, 'G_ortho': 0.0, 'D_ortho': 0.0, 'toggle_grads': True, 'which_train_fn': 'GAN', 'load_weights': '', 'resume': False, 'logstyle ': '%3.3e', 'log_G_spectra': False, 'log_D_spectra': False, 'sv_log_interval': 10}
bigGan的参数真心多,我们来拆解看看每个参数都是干嘛的, 注意repo在此 https://github.com/ajbrock/BigGAN-PyTorch 最好的办法是就先用script文件夹下面的那些shell脚本,保证不会出奇怪的错误
|
parser.add_argument( '--dataset',type=str,default='I128_hdf5', help='WhichDatasettotrainon,outofI128,I256,C10,C100;' 'Append"_hdf5"tousethehdf5versionforISLVRC' '(default:%(default)s)') |
数据集 |
可选不同大小的输入数据集 |
|
|
parser.add_argument( '--augment',action='store_true',default=False, help='Augmentwithrandomcropsandflips(default:%(default)s)') |
数据集是否需要做augmentation |
会对非hdf5的数据做 ifdatasetin['C10','C100']: train_transform=[transforms.RandomCrop(32,padding=4), transforms.RandomHorizontalFlip()] else: train_transform=[RandomCropLongEdge(), transforms.Resize(image_size), transforms.RandomHorizontalFlip()]
|
对于人脸数据集常用的aug手法是什么?crop应该没有吧 |
|
parser.add_argument( '--num_workers',type=int,default=8, help='Numberofdataloaderworkers;considerusinglessforHDF5' '(default:%(default)s)') |
|
常规操作 |
|
|
parser.add_argument( '--no_pin_memory',action='store_false',dest='pin_memory',default=True, help='Pindataintomemorythroughdataloader?(default:%(default)s)') |
|
常规操作 |
|
|
parser.add_argument( '--shuffle',action='store_true',default=False, help='Shufflethedata(stronglyrecommended)?(default:%(default)s)') |
|
train_loader=DataLoader(train_set,batch_size=batch_size, shuffle=shuffle,**loader_kwargs) |
|
|
parser.add_argument( '--load_in_mem',action='store_true',default=False, help='Loadalldataintomemory?(default:%(default)s)') |
|
常规操作 |
|
|
parser.add_argument( '--use_multiepoch_sampler',action='store_true',default=False, help='Usethemulti-epochsamplerfordataloader?(default:%(default)s)') |
是否使用MultiEpochSampler来代替dataloader,据说可以解决memory leak的问题?? |
multi-epoch Dataset sampler to avoid memory leakage and enable resumption of training from the same sample regardless of if we stop mid-epoch |
|
|
parser.add_argument( '--model',type=str,default='BigGAN', help='Nameofthemodelmodule(default:%(default)s)') |
模型 biggan biggan_deep可选 |
|
|
|
parser.add_argument( '--G_param',type=str,default='SN', help='ParameterizationstyletouseforG,spectralnorm(SN)orSVD(SVD)' 'orNone(default:%(default)s)') |
使用SN或者就是普通的conv和linear层?? |
ifself.G_param=='SN': self.which_conv=functools.partial(layers.SNConv2d, kernel_size=3,padding=1, num_svs=num_G_SVs,num_itrs=num_G_SV_itrs, eps=self.SN_eps) self.which_linear=functools.partial(layers.SNLinear, num_svs=num_G_SVs,num_itrs=num_G_SV_itrs, eps=self.SN_eps) else: self.which_conv=functools.partial(nn.Conv2d,kernel_size=3,padding=1) self.which_linear=nn.Linear |
|
|
parser.add_argument( '--D_param',type=str,default='SN', help='ParameterizationstyletouseforD,spectralnorm(SN)orSVD(SVD)' 'orNone(default:%(default)s)') |
使用SN或者就是普通的conv和linear层。目前只能打开,否则不赋值 |
|
|
|
parser.add_argument( '--G_ch',type=int,default=64, help='ChannelmultiplierforG(default:%(default)s)') |
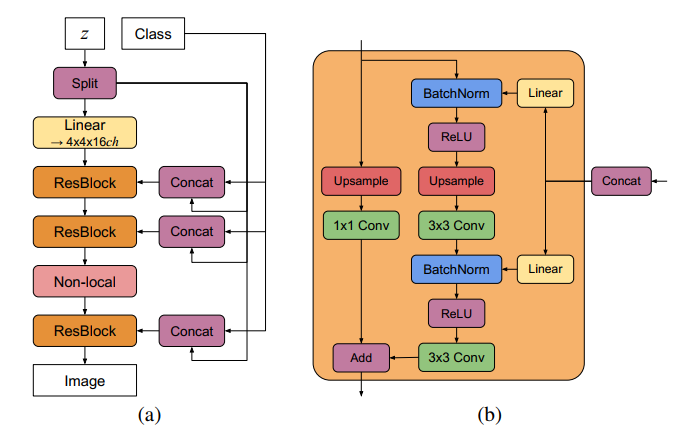
G的Channel number的base, 这个64就可以替换右边的ch,即,对于128x128的输出,第一层出来是4x4x(16x64=1024)
4x4x1024 8x8x1024 16x16x512 32x32x256 64x64x128 Non-local attention block 128x128x64 128x128x3 【和GNGAN的是一模一样,除了non-local那一层】
|

|
|
|
parser.add_argument( '--D_ch',type=int,default=64, help='ChannelmultiplierforD(default:%(default)s)') |
D的Channel的base |
|
|
|
parser.add_argument( '--G_depth',type=int,default=1, help='NumberofresblocksperstageinG?(default:%(default)s)') |
每个resBlock里面的residule blockde 数量,默认是1 |
|
|
|
parser.add_argument( '--D_depth',type=int,default=1, help='NumberofresblocksperstageinD?(default:%(default)s)') |
每个resBlock里面的residule blockde 数量,默认是1 |
|
|
|
parser.add_argument( '--D_thin',action='store_false',dest='D_wide',default=True, help='UsetheSN-GANchannelpatternforD?(default:%(default)s)') |
貌似没用到 |
|
|
|
parser.add_argument( '--G_shared',action='store_true',default=False, help='UsesharedembeddingsinG?(default:%(default)s)') |
对于类别使用shared embedding再加linear层 |
平常的conditioanl gan都是直接每一层加embedding,把类别转换成一维向量去做的,这边是直接用一次embending, 然后每一个stage用不同的linear层 |
|
|
parser.add_argument( '--shared_dim',type=int,default=0, help='G''ssharedembeddingdimensionality;if0,willbeequaltodim_z.' '(default:%(default)s)') |
embeding的维数 |
|
|
|
parser.add_argument( '--dim_z',type=int,default=128, help='Noisedimensionality:%(default)s)') |
Latent code的维数,默认为128x1 |
|
|
|
parser.add_argument( '--z_var',type=float,default=1.0, help='Noisevariance:%(default)s)') |
正态分布的标准差 Tensor.normal_ |
|
|
|
parser.add_argument( '--hier',action='store_true',default=False, help='UsehierarchicalzinG?(default:%(default)s)') |
|
如果打开的话,会把latent code按照有几个stage()slipt开,比如下图就会拆成4份,4个等长的 128/4,每个是32, 如果不打开,就只在一开始的时候有z,后面每一个resblock只有class作为输入,没有latent code
|
|
|
parser.add_argument( '--cross_replica',action='store_true',default=False, help='Cross_replicabatchnorminG?(default:%(default)s)') |
Synced BatchNorm
默认不打开,打开效果很奇怪,训练不出好的结果。biggan的code在这个地方的实现有bug。特别是多卡,出来的效果很差,单卡能出效果,但是多样性降低。 |
|
|
|
parser.add_argument( '--mybn',action='store_true',default=False, help='Usemybatchnorm(whichsupportsstandingstats?)%(default)s)') |
|
|
|
|
parser.add_argument( '--G_nl',type=str,default='relu', help='ActivationfunctionforG(default:%(default)s)') |
激活函数 |
|
|
|
parser.add_argument( '--D_nl',type=str,default='relu', help='ActivationfunctionforD(default:%(default)s)') |
激活函数 |
|
|
|
parser.add_argument( '--G_attn',type=str,default='64', help='WhatresolutionstouseattentiononforG(underscoreseparated)' '(default:%(default)s)') |
attention的位置,默认在64x64的位置 |
|
|
|
parser.add_argument( '--D_attn',type=str,default='64', help='WhatresolutionstouseattentiononforD(underscoreseparated)' '(default:%(default)s)') |
|
|
|
|
parser.add_argument( '--norm_style',type=str,default='bn', help='NormalizerstyleforG,oneofbn[batchnorm],in[instancenorm],' 'ln[layernorm],gn[groupnorm](default:%(default)s)') |
|
|
|
|
###Modelinitstuff### parser.add_argument( '--seed',type=int,default=0, help='Randomseedtouse;affectsbothinitializationand' 'dataloading.(default:%(default)s)') |
torch.manual_seed设定随机数的种子,这样每次跑 torch.rand(2)出来的结果都是一样的,用于sample的时候观看结果,能保持一致性 |
|
|
|
parser.add_argument( '--G_init',type=str,default='ortho', help='InitstyletouseforG(default:%(default)s)') |
|
|
|
|
parser.add_argument( '--D_init',type=str,default='ortho', help='InitstyletouseforD(default:%(default)s)') |
|
|
|
|
parser.add_argument( '--skip_init',action='store_true',default=False, help='Skipinitialization,idealfortestingwhenorthoinitwasused' '(default:%(default)s)') |
|
|
|
|
###Optimizerstuff### parser.add_argument( '--G_lr',type=float,default=5e-5, help='LearningratetouseforGenerator(default:%(default)s)') |
Learning rate |
|
|
|
parser.add_argument( '--D_lr',type=float,default=2e-4, help='LearningratetouseforDiscriminator(default:%(default)s)') |
Learning rate |
|
|
|
parser.add_argument( '--G_B1',type=float,default=0.0, help='Beta1touseforGenerator(default:%(default)s)') |
beta |
|
|
|
parser.add_argument( '--D_B1',type=float,default=0.0, help='Beta1touseforDiscriminator(default:%(default)s)') |
beta |
|
|
|
parser.add_argument( '--G_B2',type=float,default=0.999, help='Beta2touseforGenerator(default:%(default)s)') |
Beta 2 |
|
|
|
parser.add_argument( '--D_B2',type=float,default=0.999, help='Beta2touseforDiscriminator(default:%(default)s)') |
Beta 2 |
|
|
|
###Batchsize,parallel,andprecisionstuff### parser.add_argument( '--batch_size',type=int,default=64, help='Defaultoverallbatchsize(default:%(default)s)') |
Batch size |
|
|
|
parser.add_argument( '--G_batch_size',type=int,default=0, help='BatchsizetouseforG;if0,sameasD(default:%(default)s)') |
Batch size |
|
|
|
parser.add_argument( '--num_G_accumulations',type=int,default=1, help='NumberofpassestoaccumulateG''sgradientsover' '(default:%(default)s)') |
变相的增加batch size |
|
|
|
parser.add_argument( '--num_D_steps',type=int,default=2, help='NumberofDstepsperGstep(default:%(default)s)') |
G每跑1次, D跑几次 |
|
|
|
parser.add_argument( '--num_D_accumulations',type=int,default=1, help='NumberofpassestoaccumulateD''sgradientsover' '(default:%(default)s)') |
|
|
|
|
parser.add_argument( '--split_D',action='store_true',default=False, help='RunDtwiceratherthanconcatenatinginputs?(default:%(default)s)') |
Split_D means to run D once with real data and once with fake, rather than concatenating along the batch dimension. |
|
|
|
parser.add_argument( '--num_epochs',type=int,default=100, help='Numberofepochstotrainfor(default:%(default)s)') |
|
|
|
|
parser.add_argument( '--parallel',action='store_true',default=False, help='TrainwithmultipleGPUs(default:%(default)s)') |
多GPU训练 |
|
|
|
parser.add_argument( '--G_fp16',action='store_true',default=False, help='Trainwithhalf-precisioninG?(default:%(default)s)') |
|
|
|
|
parser.add_argument( '--D_fp16',action='store_true',default=False, help='Trainwithhalf-precisioninD?(default:%(default)s)') |
|
|
|
|
parser.add_argument( '--D_mixed_precision',action='store_true',default=False, help='Trainwithhalf-precisionactivationsbutfp32paramsinD?' '(default:%(default)s)') |
|
|
|
|
parser.add_argument( '--G_mixed_precision',action='store_true',default=False, help='Trainwithhalf-precisionactivationsbutfp32paramsinG?' '(default:%(default)s)') |
|
|
|
|
parser.add_argument( '--accumulate_stats',action='store_true',default=False, help='Accumulate"standing"batchnormstats?(default:%(default)s)') |
? |
|
|
|
parser.add_argument( '--num_standing_accumulations',type=int,default=16, help='Numberofforwardpassestouseinaccumulatingstandingstats?' '(default:%(default)s)') |
? |
|
|
|
###Bookkepingstuff### parser.add_argument( '--G_eval_mode',action='store_true',default=False, help='RunGinevalmode(running/standingstats?)atsample/testtime?' '(default:%(default)s)') |
|
|
|
|
parser.add_argument( '--save_every',type=int,default=2000, help='SaveeveryXiterations(default:%(default)s)') |
|
|
|
|
parser.add_argument( '--num_save_copies',type=int,default=2, help='Howmanycopiestosave(default:%(default)s)') |
|
|
|
|
parser.add_argument( '--num_best_copies',type=int,default=2, help='Howmanypreviousbestcheckpointstosave(default:%(default)s)') |
|
|
|
|
parser.add_argument( '--which_best',type=str,default='IS', help='Whichmetrictousetodeterminewhentosavenew"best"' 'checkpoints,oneofISorFID(default:%(default)s)') |
|
|
|
|
parser.add_argument( '--no_fid',action='store_true',default=False, help='CalculateISonly,notFID?(default:%(default)s)') |
是否计算fid |
|
|
|
parser.add_argument( '--test_every',type=int,default=5000, help='TesteveryXiterations(default:%(default)s)') |
|
|
|
|
parser.add_argument( '--num_inception_images',type=int,default=50000, help='Numberofsamplestocomputeinceptionmetricswith' '(default:%(default)s)') |
采用多少张图片计算inception feature |
|
|
|
parser.add_argument( '--hashname',action='store_true',default=False, help='Useahashoftheexperimentnameinsteadofthefullconfig' '(default:%(default)s)') |
|
|
|
|
parser.add_argument( '--base_root',type=str,default='', help='Defaultlocationtostoreallweights,samples,data,andlogs' '(default:%(default)s)') |
|
|
|
|
parser.add_argument( '--data_root',type=str,default='data', help='Defaultlocationwheredataisstored(default:%(default)s)') parser.add_argument( '--weights_root',type=str,default='weights', help='Defaultlocationtostoreweights(default:%(default)s)') parser.add_argument( '--logs_root',type=str,default='logs', help='Defaultlocationtostorelogs(default:%(default)s)') parser.add_argument( '--samples_root',type=str,default='samples', help='Defaultlocationtostoresamples(default:%(default)s)') parser.add_argument( '--pbar',type=str,default='mine', help='Typeofprogressbartouse;oneof"mine"or"tqdm"' '(default:%(default)s)') parser.add_argument( '--name_suffix',type=str,default='', help='Suffixforexperimentnameforloadingweightsforsampling' '(consider"best0")(default:%(default)s)') parser.add_argument( '--experiment_name',type=str,default='', help='Optionallyoverridetheautomaticexperimentnamingwiththisarg.' '(default:%(default)s)') parser.add_argument( '--config_from_name',action='store_true',default=False, help='Useahashoftheexperimentnameinsteadofthefullconfig' '(default:%(default)s)') |
|
|
|
|
###EMAStuff### parser.add_argument( '--ema',action='store_true',default=False, help='KeepanemaofG''sweights?(default:%(default)s)') |
Ema - exponential moving average weights的更新和历史数据也有关系
|
|
|
|
parser.add_argument( '--ema_decay',type=float,default=0.9999, help='EMAdecayrate(default:%(default)s)') |
|
|
|
|
parser.add_argument( '--use_ema',action='store_true',default=False, help='UsetheEMAparametersofGforevaluation?(default:%(default)s)') |
|
|
|
|
parser.add_argument( '--ema_start',type=int,default=0, help='WhentostartupdatingtheEMAweights(default:%(default)s)') |
|
|
|
|
###NumericalprecisionandSVstuff### parser.add_argument( '--adam_eps',type=float,default=1e-8, help='epsilonvaluetouseforAdam(default:%(default)s)') |
|
|
|
|
parser.add_argument( '--BN_eps',type=float,default=1e-5, help='epsilonvaluetouseforBatchNorm(default:%(default)s)') parser.add_argument( '--SN_eps',type=float,default=1e-8, help='epsilonvaluetouseforSpectralNorm(default:%(default)s)') parser.add_argument( '--num_G_SVs',type=int,default=1, help='NumberofSVstotrackinG(default:%(default)s)') parser.add_argument( '--num_D_SVs',type=int,default=1, help='NumberofSVstotrackinD(default:%(default)s)') parser.add_argument( '--num_G_SV_itrs',type=int,default=1, help='NumberofSVitrsinG(default:%(default)s)') parser.add_argument( '--num_D_SV_itrs',type=int,default=1, help='NumberofSVitrsinD(default:%(default)s)') |
|
|
|
|
###Orthoregstuff### parser.add_argument( '--G_ortho',type=float,default=0.0,#1e-4isdefaultforBigGAN help='ModifiedorthoregcoefficientinG(default:%(default)s)') parser.add_argument( '--D_ortho',type=float,default=0.0, help='ModifiedorthoregcoefficientinD(default:%(default)s)') parser.add_argument( '--toggle_grads',action='store_true',default=True, help='ToggleDandG''s"requires_grad"settingswhennottrainingthem?' '(default:%(default)s)') |
|
|
|
|
###Whichtrainfunction### parser.add_argument( '--which_train_fn',type=str,default='GAN', help='How2trainyourbois(default:%(default)s)') |
|
|
|
|
###Resumetrainingstuff parser.add_argument( '--load_weights',type=str,default='', help='Suffixforwhichweightstoload(e.g.best0,copy0)' '(default:%(default)s)') parser.add_argument( '--resume',action='store_true',default=False, help='Resumetraining?(default:%(default)s)') |
|
|
|
|
###Logstuff### parser.add_argument( '--logstyle',type=str,default='%3.3e', help='Whatstyletousewhenloggingtrainingmetrics?' 'Oneof:%#.#f/%#.#e(float/exp,text),' 'pickle(pythonpickle),' 'npz(numpyzip),' 'mat(MATLAB.matfile)(default:%(default)s)') parser.add_argument( '--log_G_spectra',action='store_true',default=False, help='Logthetop3singularvaluesineachSNlayerinG?' '(default:%(default)s)') parser.add_argument( '--log_D_spectra',action='store_true',default=False, help='Logthetop3singularvaluesineachSNlayerinD?' '(default:%(default)s)') parser.add_argument( '--sv_log_interval',type=int,default=10, help='Iterationintervalforloggingsingularvalues' '(default:%(default)s)') |
|
|
|
|
#Argumentsforsample.py;notpresentlyusedintrain.py defadd_sample_parser(parser): parser.add_argument( '--sample_npz',action='store_true',default=False, help='Sample"sample_num_npz"imagesandsavetonpz?' '(default:%(default)s)') parser.add_argument( '--sample_num_npz',type=int,default=50000, help='NumberofimagestosamplewhensamplingNPZs' '(default:%(default)s)') parser.add_argument( '--sample_sheets',action='store_true',default=False, help='Produceclass-conditionalsamplesheetsandstickthemin' 'thesamplesroot?(default:%(default)s)') parser.add_argument( '--sample_interps',action='store_true',default=False, help='Produceinterpolationsheetsandstickthemin' 'thesamplesroot?(default:%(default)s)') parser.add_argument( '--sample_sheet_folder_num',type=int,default=-1, help='Numbertouseforthefolderforthesesamplesheets' '(default:%(default)s)') |
|
|
|
|
parser.add_argument( '--sample_random',action='store_true',default=False, help='Produceasinglerandomsheet?(default:%(default)s)') |
|
|
|
|
parser.add_argument( '--sample_trunc_curves',type=str,default='', help='Getinceptionmetricswitharangeofvariances?' 'Tousethis,specifyastartpoint,step,andendpoint,e.g.' '--sample_trunc_curves0.2_0.1_1.0forastartpointof0.2,' 'endpointof1.0,andstepsizeof1.0.Notethatthisis' 'notexactlyidenticaltousingtf.truncated_normal,butshould' 'haveapproximatelythesameeffect.(default:%(default)s)') |
|
|
|
|
parser.add_argument( '--sample_inception_metrics',action='store_true',default=False, help='CalculateInceptionmetricswithsample.py?(default:%(default)s)')
|
|
|
|