
[video super resolution] ESPCN论文笔记
ESPCN是twitter2017年提出来的实时视频超分辨率的方法。下面记录下对论文的一些理解。
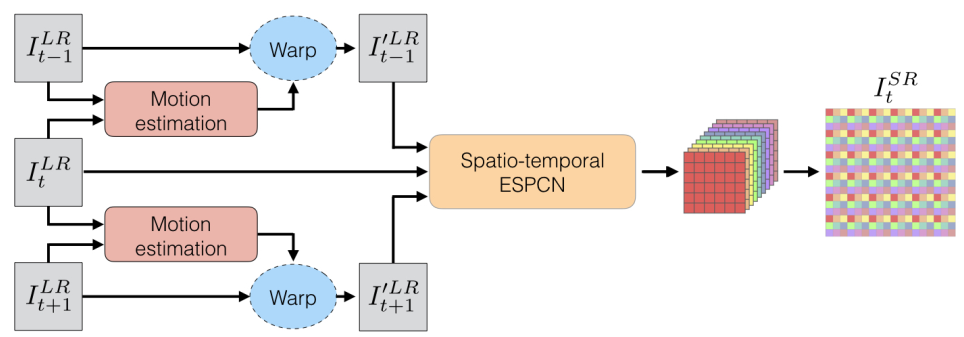
上面这张图就是整个网络的架构。输入t帧的相邻图像,t-1和t+1,在具体的网络中,有输入连续3张,5张,7张和9张的,在论文中有分析这个对具体效果的影响,这边是以3张为例。逐像素计算t-1和t帧的lr的图像的位移(通过一个motion estimation的网络),然后将这个位移apply在t-1的lr图像上面,得到warp过的t-1图像。将warp过的t-1/t+1和t图像一起输入一个时空网络,得到最终的单张t帧的SR图像。
所以主要网络是两个,一个motion estimation一个spatio-temporal。
先介绍motion estimation。
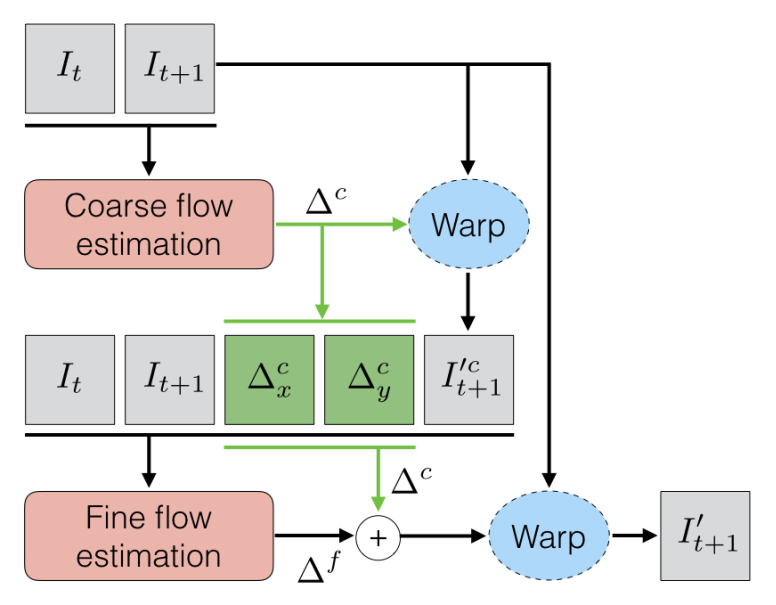
这个分两步去做,一个先做coarse 的flow预测,再做fine flow的预测,这样可以使用小的计算量计算更大的位移。这也是在video SR中常用的做法。
再介绍一下另一个重要的时空网络。
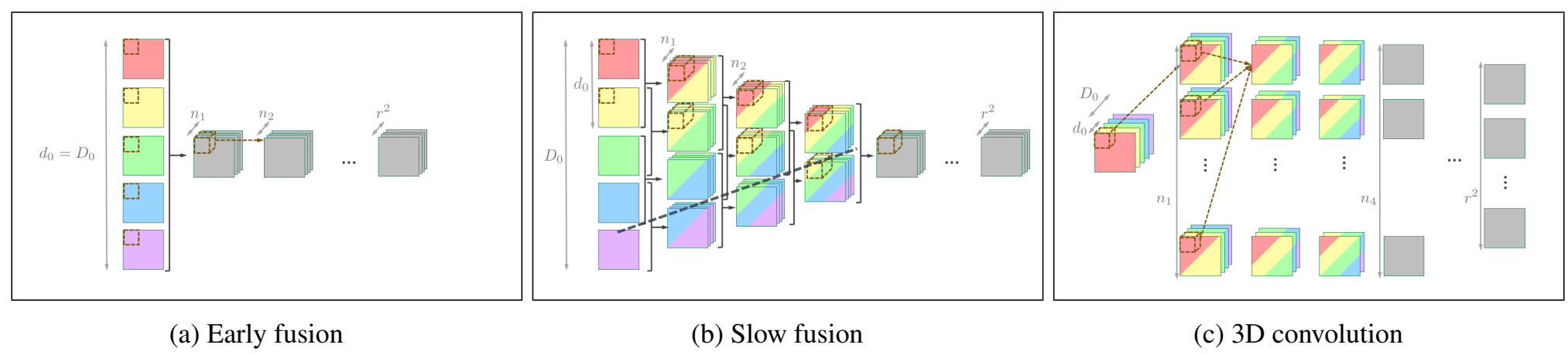
时空网络要做的事情是这样的,把几张不同帧的LR图像合成一张SR,所以既有时间上的融合也有空间上的插值。
上图介绍了几种常用的时空网络
a) early fusion
将输入的n张图片concat起来然后用一个n channel的filter去做卷积,这样就把所有的图片在第一layer就融合起来了
b) slow fusion
在第一层的时候不融合所有的图片,比如图中所示,每层只融合相邻的2帧,这就是slow fusion
c) 3D convolution
我们将第一个卷积层的第一个输出feature map放大来看,会发现其实每一个channel都是两个相邻帧得到的
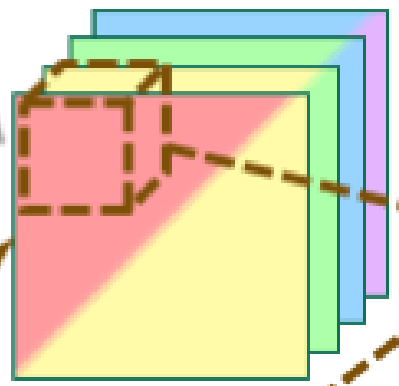
等价于下面我们常见的3D卷积。

这里,3D conv可以看做是slow fusion的权值共享的版本,只不过是在temporal和空域上swap了一下,稍微解释一下。
3D convolution的第一层的第一个feature map,可以看做是slow fusion的第一层的所有feature map的channel 1concat起来的。所不同的是,需要slow fusion中的同一层的weight要一样(即权值共享)。这种权值共享的slow fusion一大好处就是计算力比较省,因为可以复用之前的结果。比如t+2 t+1 t t-1 t-2和t+1 t t-1 t-2 t-3其实中间有一些结果是可以复用的。
具体的结果和分析可以去看论文。
Real-Time Video Super-Resolution with Spatio-Temporal Networks and Motion Compensation (CVPR 2017)
See https://arxiv.org/abs/1611.05250

