
数据流
索引周期管理如下:
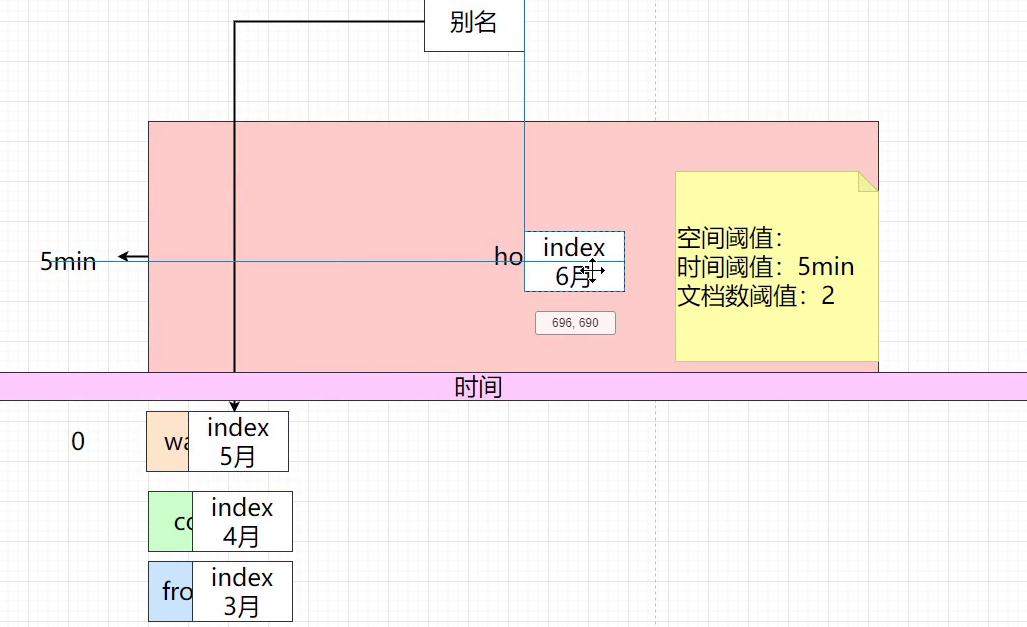
索引周期缺点:数量过多,性能无法保证,性能安全
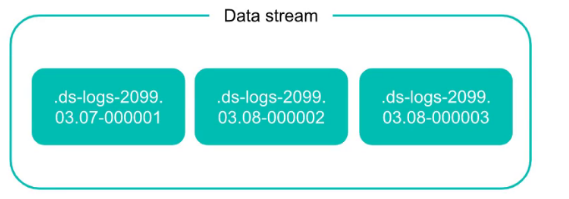
数据流
数据流允许您跨多个索引存储仅附加的时间序列数据,同时为您提供单个命名资源用于请求。数据流非常适合日志、事件、指标和其他连续生成的数据。
您可以将索引和搜索请求直接提交到数据流。流自动将请求路由到存储流数据的支持索引。您可以使用索引生命周期管理(ILM)来自动管理这些支持索引。例如,您可以使用ILM自动将较旧的支持索引移动到成本较低的硬件并删除不需要的索引。随着数据的增长,ILM可以帮助您降低成本和开销。
支持指数
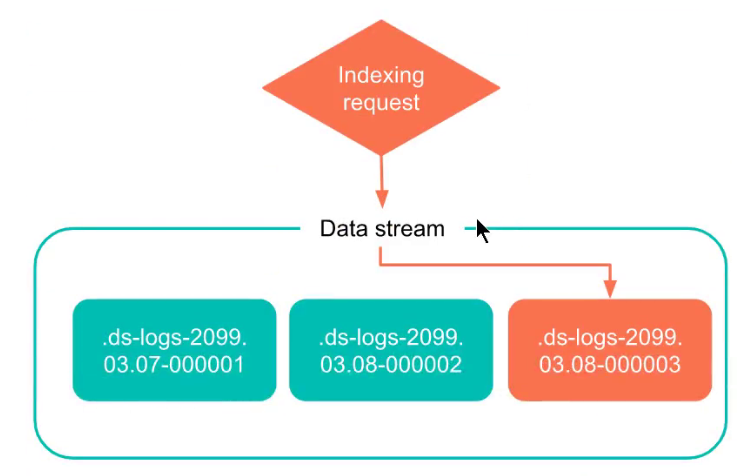
数据流由一个或多个隐藏的、自动生成的后备索引组成。
一个数据流需要一个匹配的索引模板。该模板包含用于配置流的支持索引的映射和设置。
每个索引到数据流的文档都必须包含一个@timestamp字段,映射为一个date或date_nanos字段类型。如果索引模板没有为@timestamp字段指定映射,Elasticsearch将映射@timestamp为date具有默认选项的字段。
同一个索引模板可以用于多个数据流。您不能删除数据流正在使用的索引模板。
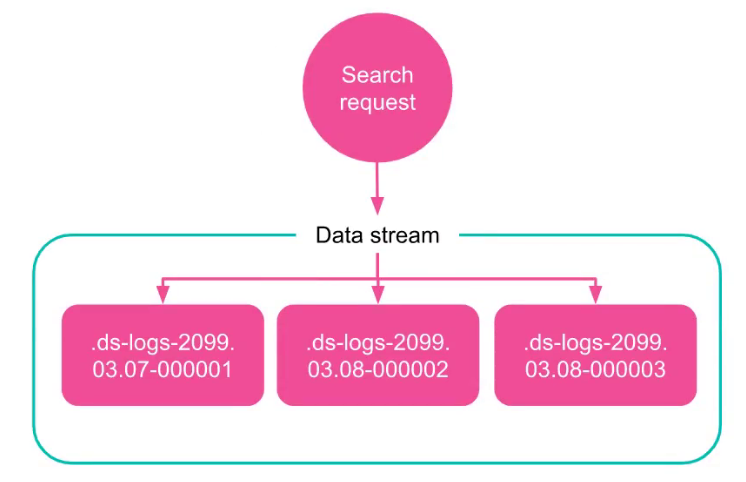
读取请求
当您向数据流提交读取请求时,该流会将请求路由到其所有支持索引。
写索引
最近创建的后备索引是数据流的写入索引。该流仅将新文档添加到此索引。
即使直接向索引发送请求,您也无法将新文档添加到其他支持索引。您也不能对可能妨碍索引的写入索引执行操作,例如:
- ·克隆
- ·删除
- 。冻结
- 。收缩。分裂
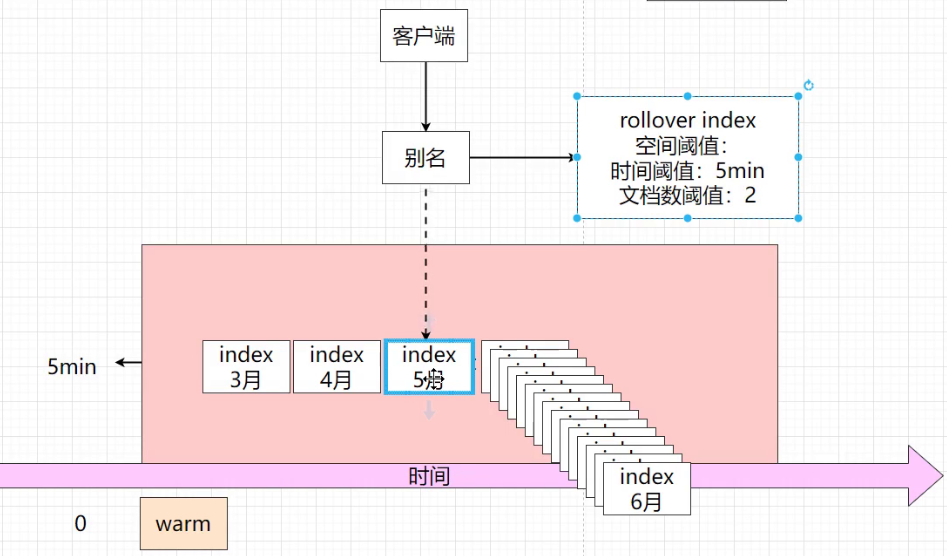
滚下
翻转创建一个新的后备索引,该索引成为流的新写入索引。
我们建议在写入索引达到指定的年龄或大小时使用ILM自动翻转数据流。如果需要,您还可以手动翻转数据流。
一代
每个数据流都跟踪它的生成:一个六位数的零填充整数,用作流翻转的索积计数,从eo8081.创建后备索引时,索引使用以下约定命名:
.ds -<数据流>-< yyyy 。嗯。dd >-<代>
更多官方文档


Simulate multi-component templates Since templates can be composed not only of multiple component templates, but also the index template itself, there are two simulation APIs to determine what the resulting index settings will be. To simulate the settings that would be applied to a particular index name: POST /_index_template/_simulate_index/my-index-000001 Copy as curl View in Console To simulate the settings that would be applied from an existing template: POST /_index_template/_simulate/template_1 Copy as curl View in Console You can also specify a template definition in the simulate request. This enables you to verify that settings will be applied as expected before you add a new template. PUT /_component_template/ct1 { "template": { "settings": { "index.number_of_shards": 2 } } } PUT /_component_template/ct2 { "template": { "settings": { "index.number_of_replicas": 0 }, "mappings": { "properties": { "@timestamp": { "type": "date" } } } } } POST /_index_template/_simulate { "index_patterns": ["my*"], "template": { "settings" : { "index.number_of_shards" : 3 } }, "composed_of": ["ct1", "ct2"] } Copy as curl View in Console The response shows the settings, mappings, and aliases that would be applied to matching indices, and any overlapping templates whose configuration would be superseded by the simulated template body or higher-priority templates. { "template" : { "settings" : { "index" : { "number_of_shards" : "3", "number_of_replicas" : "0" } }, "mappings" : { "properties" : { "@timestamp" : { "type" : "date" } } }, "aliases" : { } }, "overlapping" : [ { "name" : "template_1", "index_patterns" : [ "my*" ] } ] } The number of shards from the simulated template body The @timestamp field inherited from the ct2 component template Any overlapping templates that would have matched, but have lower priority
https://www.elastic.co/guide/en/elasticsearch/reference/7.13/data-streams.html
模板创建文档
https://www.elastic.co/guide/en/elasticsearch/reference/7.13/simulate-multi-component-templates.html
创建组件模板
# Creates a component template for mappings PUT _component_template/my-mappings { "template": { "mappings": { "properties": { "@timestamp": { "type": "date", "format": "date_optional_time||epoch_millis" }, "message": { "type": "wildcard" } } } }, "_meta": { "description": "Mappings for @timestamp and message fields", "my-custom-meta-field": "More arbitrary metadata" } } # Creates a component template for index settings PUT _component_template/my-settings { "template": { "settings": { "index.lifecycle.name": "my-lifecycle-policy" } }, "_meta": { "description": "Settings for ILM", "my-custom-meta-field": "More arbitrary metadata" } }




创建索引模板的目的是关联那些索引会使用到数据流



8.2坑与避坑
8.2.1 Rollove中的时间配置和ILM的流转时间关系
Hot phase的默认最小声明周期(min_age,可配置)为10秒([min_age]=[10s]),当在Hot phase中未设置Rollover时,Warm中的最小时间流转不能低于Hot phase的默认最小声明周期,也就是10秒。此时 Hotphase向 warm phase的时间流转取决于warm phase的min_age值,和Hot phase的min_age值无关
·当在Hot phase中配置了Rollover的时候,Hot phase向Marm phase的时间流转会受到 Rollover的影响。其最终流转时间需同时满足warm phase的 min_age和Rollover的最先执行的条件。Rollover如果所有条件都一直不满足,warm phase的 min_age会等待Rollover的条件至少满足一个为止,换句话说,只要设置了Rollover,Rollover如果不满足创建新索引的条件,那么 warm phase会一直等待下去,直到创建新索引那一刻,warmphase的min_age开始计时。
举个例子:如果Rollover的三个条件为:
"rollover": {
"max_primary_shard_size": "5 egb",
"max_age": "100m" ,
"max_docs": 5
},
而Marm phase的min_age设置的时间为10秒,此时,如果索引的文档数一直是小于5,并且索引的体积一直小于50GB,那么索引从Hot phase流转到warm phase的时间即: 100m + 10 s,因为100分钟后Rollover产生了新索引。此时Manm phase开始计时,10秒后流转。如果在100分钟内,max_primary_shard_size 或者max_docs满足了其中任何一个条件,那么从满足条件这一刻起开始计时,10s中后数据从Hot phase流转到 warm phase。因此在做数据流或者ILM题目的时候,如果不是题目要求,不建议配置Rollover,以避免在对Rollover和LM Phase关系不熟的情况下,把时间配置错误。
8.22关于node.roles的注意事项
node.roles配置项如果没有显式的配置,那么当前节点拥有所有角色(master、data、ingest、ml
remote_cluster_client、transform)。如果你放开了注释,或者手动显式添加了node.roles配置项,那么当前节点仅拥有此配置项的中括号中显式配置的角色,没有配置的角色将被阉割。因此如果在不熟悉角色配置的情况下,不要轻易修改角色配置值,切勿画蛇添足。
1.7.13版本不要使用传统的老方式去配置角色设置,即如下方式不要再用
node.master: true
node.data: true
1.单节点集群一定要保证节点同时拥有master和data两个角色,切记是data (或data_content)不是data_hot/data_warm/data_cold。
8.2.3 data和data content角色的理解误区
配置data_hot/data_warm/data_cold的时候,必须保证**data_content**角色同时存在,因为**data_content**和这三个配置项不冲突,不可互相替代,也没有包含关系。不要想当然的以为配置了data_hot/data_warm/data_cold其中一个,就不用配置data_content了。此题可以用角色来自定义属性两种方案来控制冷热节点,但是如果对角色的理解不透彻,建议用自定义属性,更简单而且对角色没有影响。切勿舍近求远。
本文来自博客园,作者:孙龙-程序员,转载请注明原文链接:https://www.cnblogs.com/sunlong88/p/17691480.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号