
1、multi_match是啥
概念:
多字段检索,是组合查询的另一种形态,考试的时候如果考察多字段检索,并不一定必须使用multi_match,使用bool query,只要结果正确亦可,除非题目中明确要求(目前没有强制要求过)
语法:
GET <index>/_search { "query": { "multi_match": { "query": "<query keyword>", "type": "<multi_match_type>", "fields": [ "<field_a>", "<field_b>" ] } } }
2、multi_match和_source区别
multi_match:从哪些字段中检索,指的是查询条件
_source:查询的结果包含哪些字段,指的是元数据
3、multi_match type:
3.1 best_fields:
3.1.1 概念:
侧重于字段维度,单个字段的得分权重大,对于同一个query,单个field匹配更多的term,则优先排序。
3.1.2 用法:
注意,best_fields是multi_match中type的默认值
GET product/_search { "query": { "multi_match" : { "query": "super charge", "type": "best_fields", // 默认 "fields": [ "name^2", "desc" ], "tie_breaker": 0.3 } } }
3.1.3 案例
针对于以下查询,包含两个查询条件:分别是条件1和条件2
GET product/_search { "query": { "dis_max": { "queries": [ { "match": { "name": "chiji shouji" }}, #条件1 { "match": { "desc": "chiji shouji" }} #条件2 ] } } }
假设上述查询的执行得到以下结果,best_fields策略强调hits中单个字段的评分权重。打个比方:每一条hit代表一个奥运会的参加国,每个字段代表该国家的参赛运动员,但是限定每个国家只能派出一名运动员,其成绩就代表该国家的成绩,最后以该运动员的成绩代表国家进行排名。所谓best_fields就是说最好的字段嘛,用最好的字段的评分代表当前文档的最终评分,即侧重字段权重。在这个例子中,多个查询条件并未起到关键性作用。
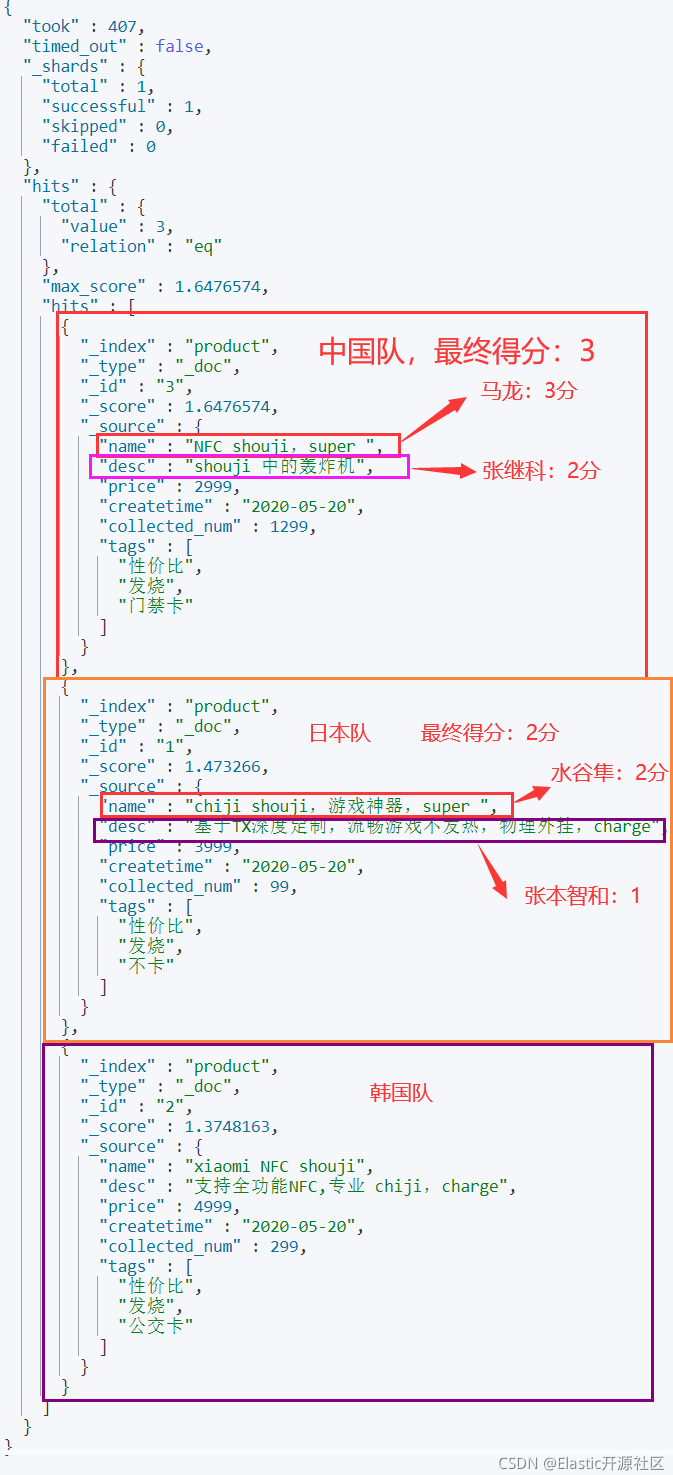
3.1.4 tie_breaker参数
在best_fields策略中给其他剩余字段设置的权重值,取值范围 [0,1],其中 0 代表使用 dis_max 最佳匹配语句的普通逻辑,1表示所有匹配语句同等重要。最佳的精确值需要根据数据与查询调试得出,但是合理值应该与零接近(处于 0.1 - 0.4 之间),这样就不会颠覆 dis_max (Disjunction Max Query)最佳匹配性质的根本。
在上面例子中,如果一个国家仅仅由一个运动员的成绩来决定,显然不是很有代表性,因为一个国家可能整体实力很弱,但是有一个运动员(假设叫做阿尔法)就是特别的出类拔萃,世界第一!但是其他人都很弱,这时他就不能代表整个国家的实力了。反而可能另一个国家,虽然国内成绩最好的运动员没有阿尔法的成绩好,但是这个国家包揽了世界的第二名到第十名,并且实力比较接近,那这样这个国家的整体实力仍然是可以排第一的。所以我们不应该让第一名完全代表一个国家的成绩,一个更好的做法是:每个国家的最终成绩由所有运动员的成绩经过计算得来,每个运动员的成绩都可能影响总成绩,但是这个国家排名第一的运动员的成绩占的权重最大。这种做法更容易凸显一个国家的整体实力,这个整体实力就等价于我们搜索结果排名中的相关度。
用法:
GET product/_search { "query": { "dis_max": { "queries": [ { "match": { "name": "super charge" }}, { "match": { "desc": "super charge" }} ], "tie_breaker": 0.3 # 代表次要评分字段的权重是 0.3 } } }
3.1.5 类比
以下两个查询等价
查询1
GET product/_search { "query": { "dis_max": { "queries": [ { "match": { "name": { "query": "chiji shouji", "boost": 2 # name字段评分两倍权重 } } }, { "match": { "desc": "chiji shouji" } } ], "tie_breaker": 0.3 } } }
查询2
GET product/_search { "query": { "multi_match" : { "query": "super charge", "type": "best_fields", // 默认 "fields": [ "name^2", "desc" ], # name字段评分两倍权重 "tie_breaker": 0.3 } } }
3.2 most_fields:
3.2.1 概念
侧重于查询维度,单个查询条件的得分权重大,如果一次请求中,对于同一个doc,匹配到某个term的field越多,则越优先排序。
3.2.2 类比
以下两个查询脚本等价
查询1:
# 下面查询中包含两个查询条件 GET product/_search { "query": { "bool": { "should": [ { "match": { "name": "chiji shouji" } }, { "match": { "desc": "chiji shouji" } } ] } } }
查询2
GET product/_search { "query": { "multi_match": { "query": "chiji shouji", "type": "most_fields", "fields": [ "name", "desc" ] } } }
3.3 cross_fields:
注意:理解cross_fields的概念之前,需要对ES的评分规则有基本的了解,戳:评分,学习ES评分的基本原理
3.3.1 概念
将任何与任一查询匹配的文档作为结果返回,但只将最佳匹配的评分作为查询的评分结果返回
3.3.2 用法
# 以下查询语义: # 吴 必须包含在 name.姓 或者 name.名 里 # 或者 # 磊 必须包含在 name.姓 或者 name.名 里 GET teacher/_search { "query": { "multi_match" : { "query": "吴磊", "type": "cross_fields", "fields": [ "name.姓", "name.名" ], "operator": "or" } } }
3.3.3 案例
假设我们有如下teacher索引,索引中包含了name字段,包含姓和名两个field(案例中使用中文为方便观察和理解,切勿在生产环境中使用中文命名,一定要遵循命名规范)。
POST /teacher/_bulk { "index": { "_id": "1"} } { "name" : {"姓" : "吴", "名" : "磊"} } { "index": { "_id": "2"} } { "name" : {"姓" : "连", "名" : "鹏鹏"} } { "index": { "_id": "3"} } { "name" : { "姓" : "张","名" : "明明"} } { "index": { "_id": "4"} } { "name" : { "姓" : "周","名" : "志志"} } { "index": { "_id": "5"} } { "name" : {"姓" : "吴", "名" : "亦凡"} } { "index": { "_id": "6"} } { "name" : {"姓" : "吴", "名" : "京"} } { "index": { "_id": "7"} } { "name" : {"姓" : "吴", "名" : "彦祖"} } { "index": { "_id": "8"} } { "name" : {"姓" : "帅", "名" : "吴"} } { "index": { "_id": "9"} } { "name" : {"姓" : "连", "名" : "磊"} } { "index": { "_id": "10"} } { "name" : {"姓" : "周", "名" : "磊"} } { "index": { "_id": "11"} } { "name" : {"姓" : "张", "名" : "磊"} } { "index": { "_id": "12"} } { "name" : {"姓" : "马", "名" : "磊"} } #{ "index": { "_id": "13"} } #{ "name" : {"姓" : "诸葛", "名" : "吴磊"} }
我们执行以上代码创建teacher索引,并且执行以下查询语句
# 语义: 默认分词器的对`吴磊`的分词结果为`吴`和`磊` # name.姓 中包含 `吴` 或者 `磊` # OR # name.名 中包含 `吴` 或者 `磊` # 如果设置了"operator": "and",则中间 OR 的关系变为 AND GET teacher/_search { "query": { "multi_match": { "query": "吴 磊", "type": "most_fields", "fields": [ "name.姓", "name.名" ] // ,"operator": "and" } } }
根据上面查询的语义,我们期望的结果是:姓为吴并且名为磊的doc评分最高,然而结果却如下:
{ "took" : 3, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 9, "relation" : "eq" }, "max_score" : 2.4548545, "hits" : [ { "_index" : "teacher", "_type" : "_doc", "_id" : "8", "_score" : 2.4548545, "_source" : { "name" : { "姓" : "帅", "名" : "吴" } } }, { "_index" : "teacher", "_type" : "_doc", "_id" : "1", "_score" : 2.03873, "_source" : { "name" : { "姓" : "吴", "名" : "磊" } } }, { "_index" : "teacher", "_type" : "_doc", "_id" : "5", "_score" : 1.060872, "_source" : { "name" : { "姓" : "吴", "名" : "亦凡" } } }, { "_index" : "teacher", "_type" : "_doc", "_id" : "6", "_score" : 1.060872, "_source" : { "name" : { "姓" : "吴", "名" : "京" } } }, { "_index" : "teacher", "_type" : "_doc", "_id" : "7", "_score" : 1.060872, "_source" : { "name" : { "姓" : "吴", "名" : "彦祖" } } }, { "_index" : "teacher", "_type" : "_doc", "_id" : "9", "_score" : 0.977858, "_source" : { "name" : { "姓" : "连", "名" : "磊" } } }, { "_index" : "teacher", "_type" : "_doc", "_id" : "10", "_score" : 0.977858, "_source" : { "name" : { "姓" : "周", "名" : "磊" } } }, { "_index" : "teacher", "_type" : "_doc", "_id" : "11", "_score" : 0.977858, "_source" : { "name" : { "姓" : "张", "名" : "磊" } } }, { "_index" : "teacher", "_type" : "_doc", "_id" : "12", "_score" : 0.977858, "_source" : { "name" : { "姓" : "马", "名" : "磊" } } } ] } }
上面结果显示,名叫帅磊的doc排在了最前面,即便我们使用best_fields策略结果也是帅磊评分最高,因为导致这个结果的原因和使用哪种搜索策略并无关系。这些然不是我们希望的结果。那么导致上述问题的原因是什么呢?看以下三条基本的评分规则:
评分基本规则:
词频(TF term frequency ):关键词在每个doc中出现的次数,词频越高,评分越高
反词频( IDF inverse doc
frequency):关键词在整个索引中出现的次数,反词频越高,评分越低
每个doc的长度,越长相关度评分越低
分析结果:
在上述案例中,吴磊作为预期结果,其中吴字作为姓氏是非常常见的,磊作为名也是非常常见的。反应在索引中,他们的IDF都是非常高的,而反词频越高则评分越低,因此吴磊在索引中的IDF评分则会很低。
而帅磊中帅作为姓氏却是非常少见的,因此IDF的得分就很高。在词频相同的情况下就会导致以上不符合常理的搜索预期。
解决办法:
为了避免某一个字段的词频或者反词频对结果产生巨大影响,我们需要把姓和名作为一个整体来查询,体现在代码上即:
# 吴 必须包含在 name.姓 或者 name.名 里 # 并且 # 磊 必须包含在 name.姓 或者 name.名 里 GET teacher/_search { "query": { "multi_match" : { "query": "吴磊", "type": "cross_fields", "fields": [ "name.姓", "name.名" ], "operator": "and" } } }
参考:https://www.elastic.co/guide/en/elasticsearch/reference/7.13/query-dsl-multi-match-query.html
本文来自博客园,作者:孙龙-程序员,转载请注明原文链接:https://www.cnblogs.com/sunlong88/p/17660548.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号