
1,常用API
1.1 cat api
cat/nodes: 查询节点分配情况
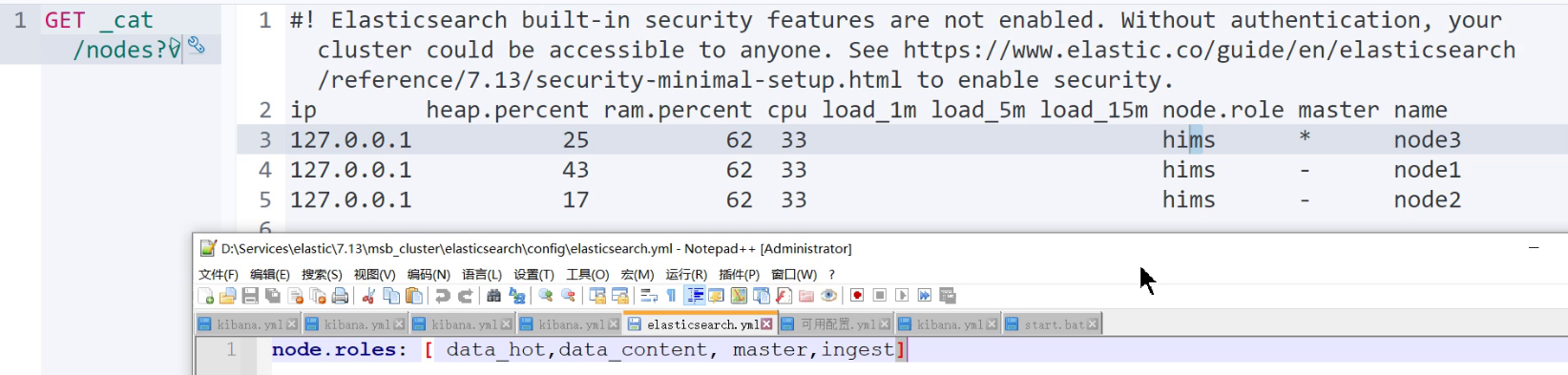
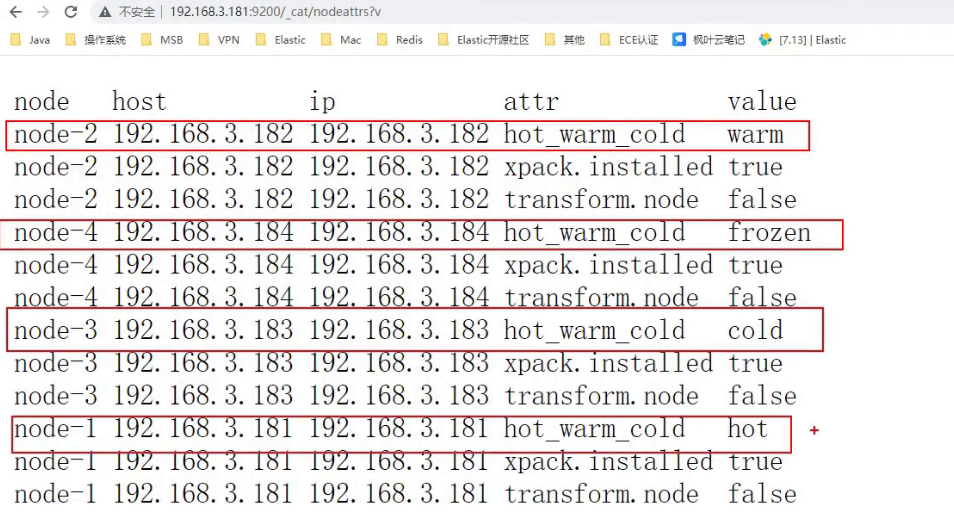
cat/nodeattrs: 查询节点属性
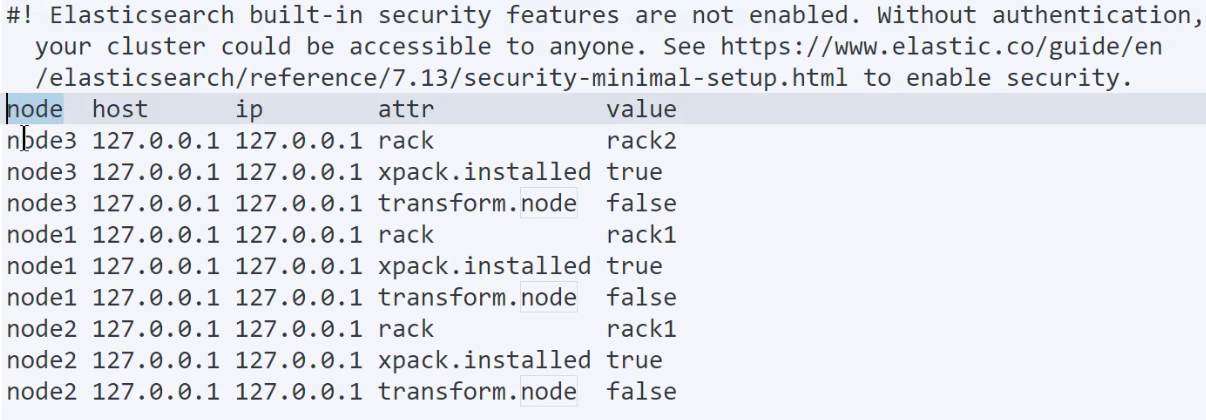
cat/shards: 查询分片分配情况
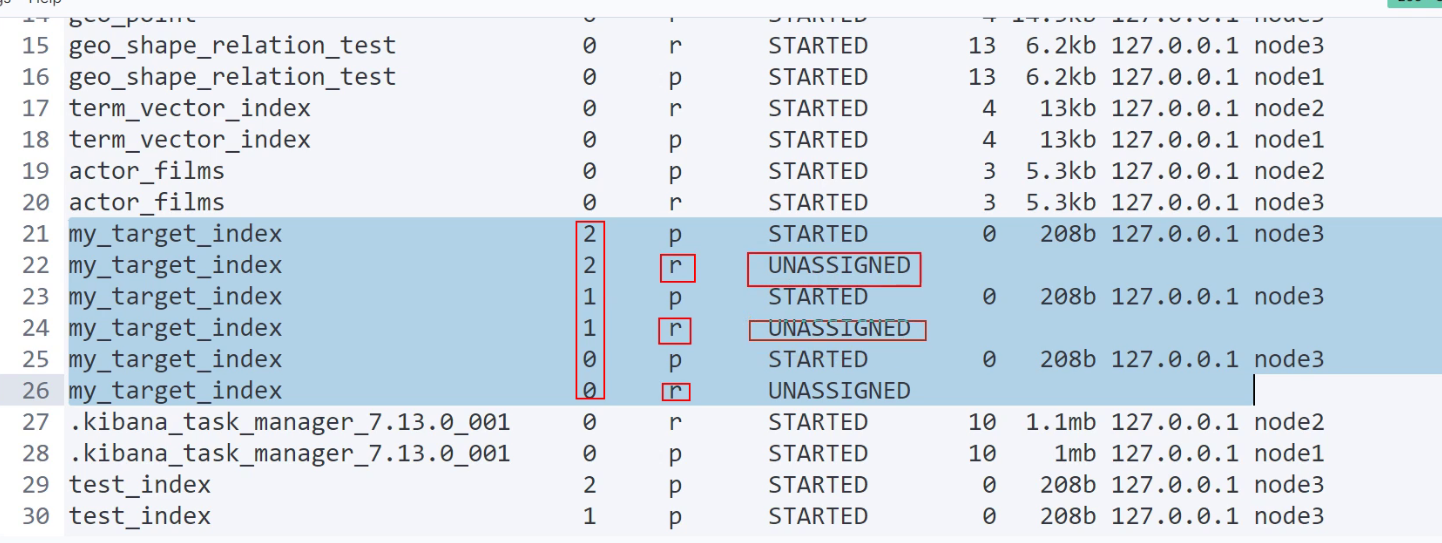
cat/allocation: 查看节点的硬盘占用和剩余
cat/count/<index>: 查看索引的文档数量,可以用 count 替代
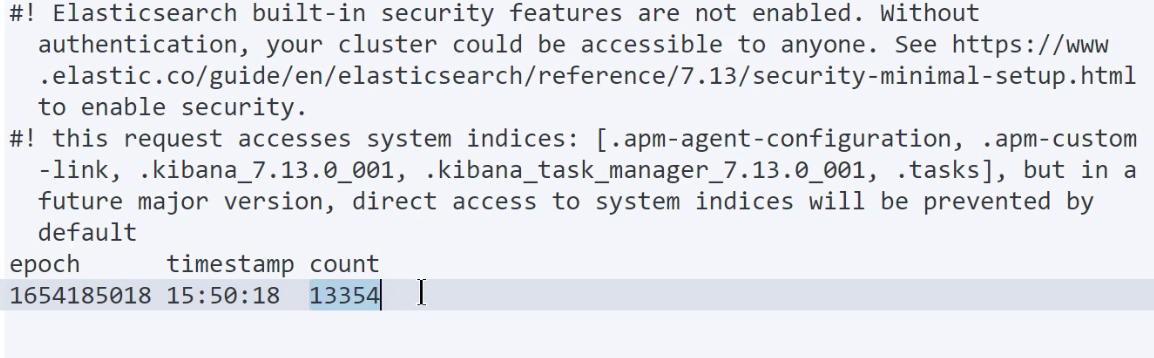
cat/health:查看集群健康状态
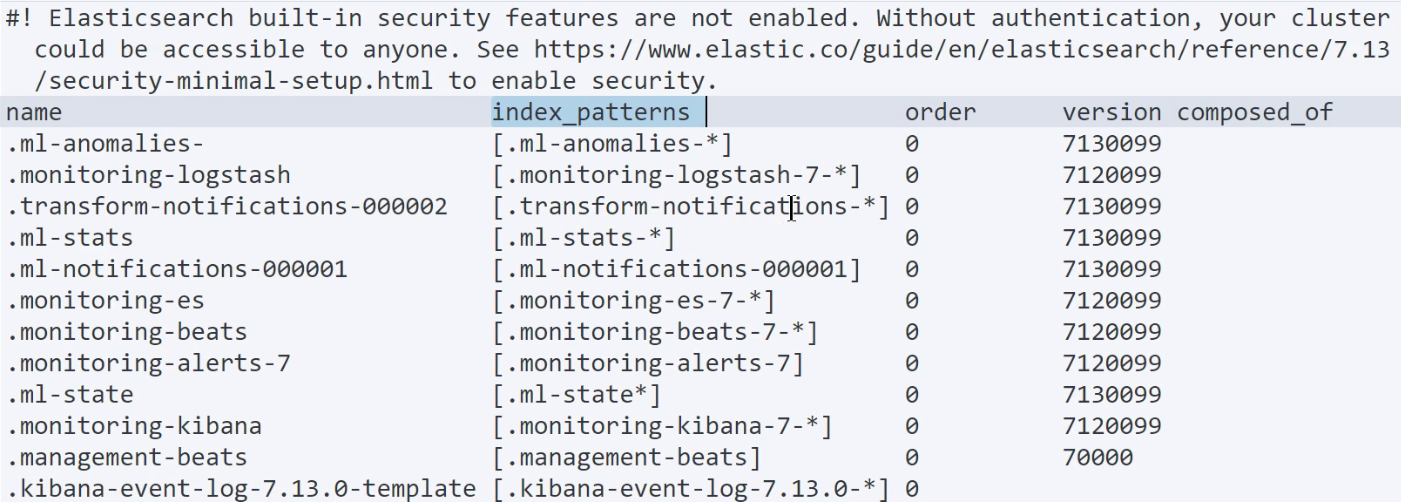
cat/indices: 查看集群中索引的分片数、文档数等信息,常用于查看集群中包含哪些索引。
cat/plugins: 查看集群中安装了哪些插件
cat/templates: 查看集群中包含了哪些索引模板
1.2 cluster api
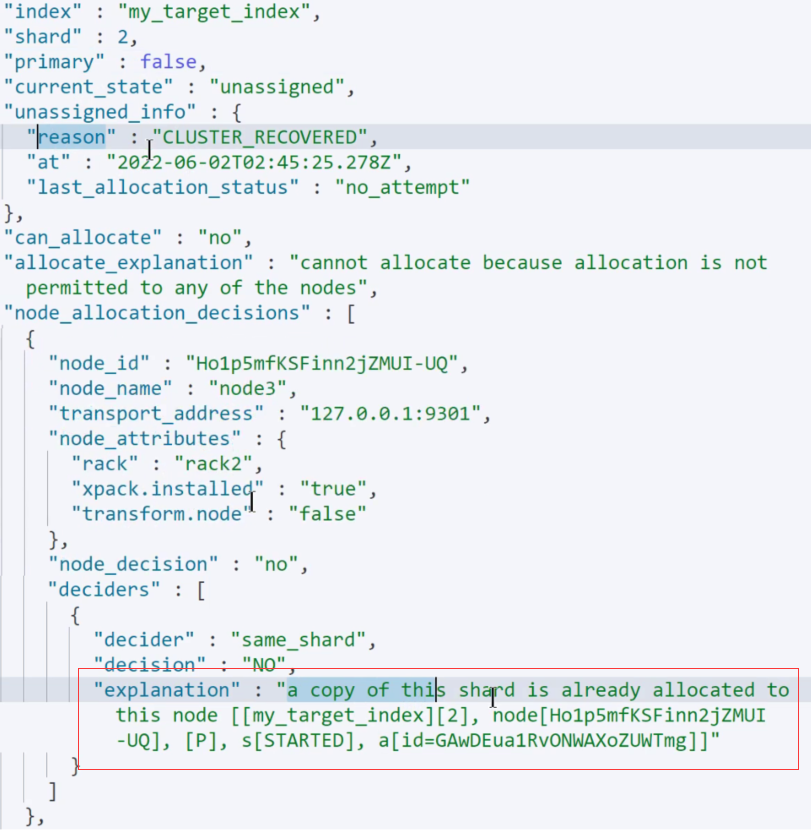
cluster/allocation/explain: 查看索引的分配执行计划,常用语查看索引为什么没有分配或者为什么分配到当前节点
cluster/health: 查看集群的健康状态
cluster/state: 查看集群状态的元数据
cluster/stats: 查看集群统计信息,相当于对 cat api 信息的一些汇总
_cat/nodes?v
_cat/nodeattrs?v
_cat/shards?v
_cat/allocation?v

_cat/count/product?v

_cat/health?v

_cat/indices?v

cat/plugins

cat/templates
cluster/allocation/explain

cluster/health

cluster/state
集群状态元数据
cluster/stats
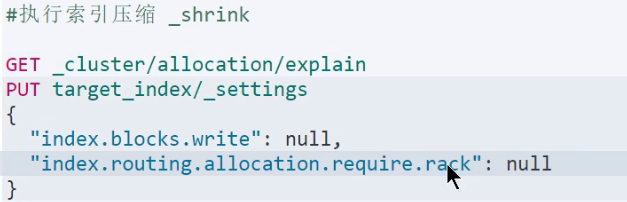
2,索引压缩
实际上是压缩的分片,并非在原有索引上压缩,而是生成了一个新的索引,由于使用了 hash 路由算法以及索引
不可变的特性

---操作步骤---
**********reindex不会把mapping和seting复制过去********************

删除副本
删除副本 "index.number of_replicas": 0 设置只读 "index.blocks.write": true


案例:

allocation.requre.rack:rack1
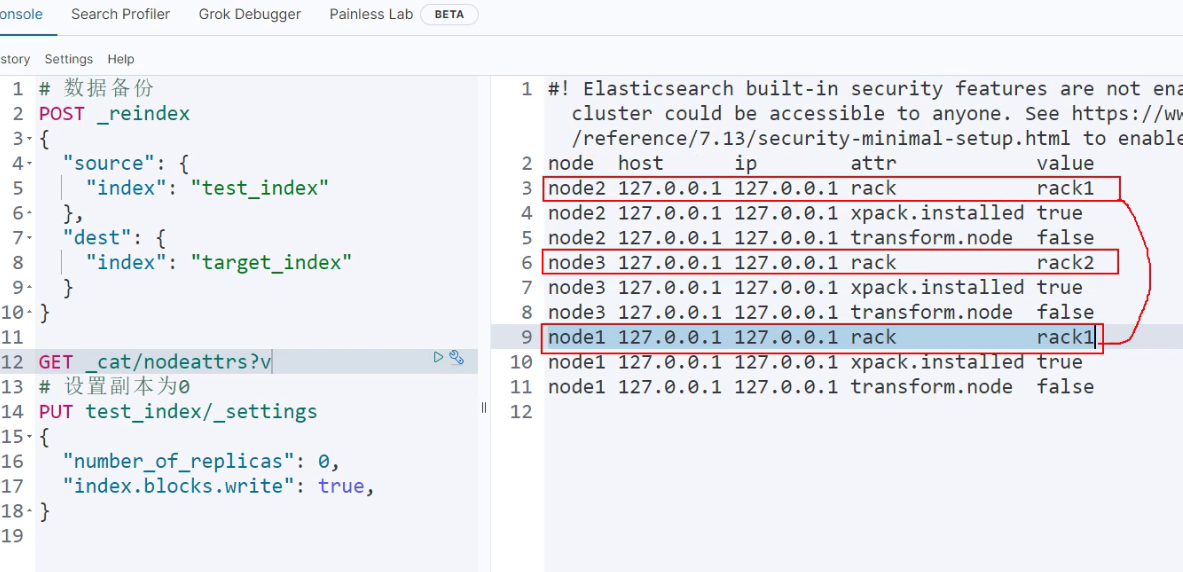

-----------执行压缩时候所有分片必须都在同一个节点上---------------
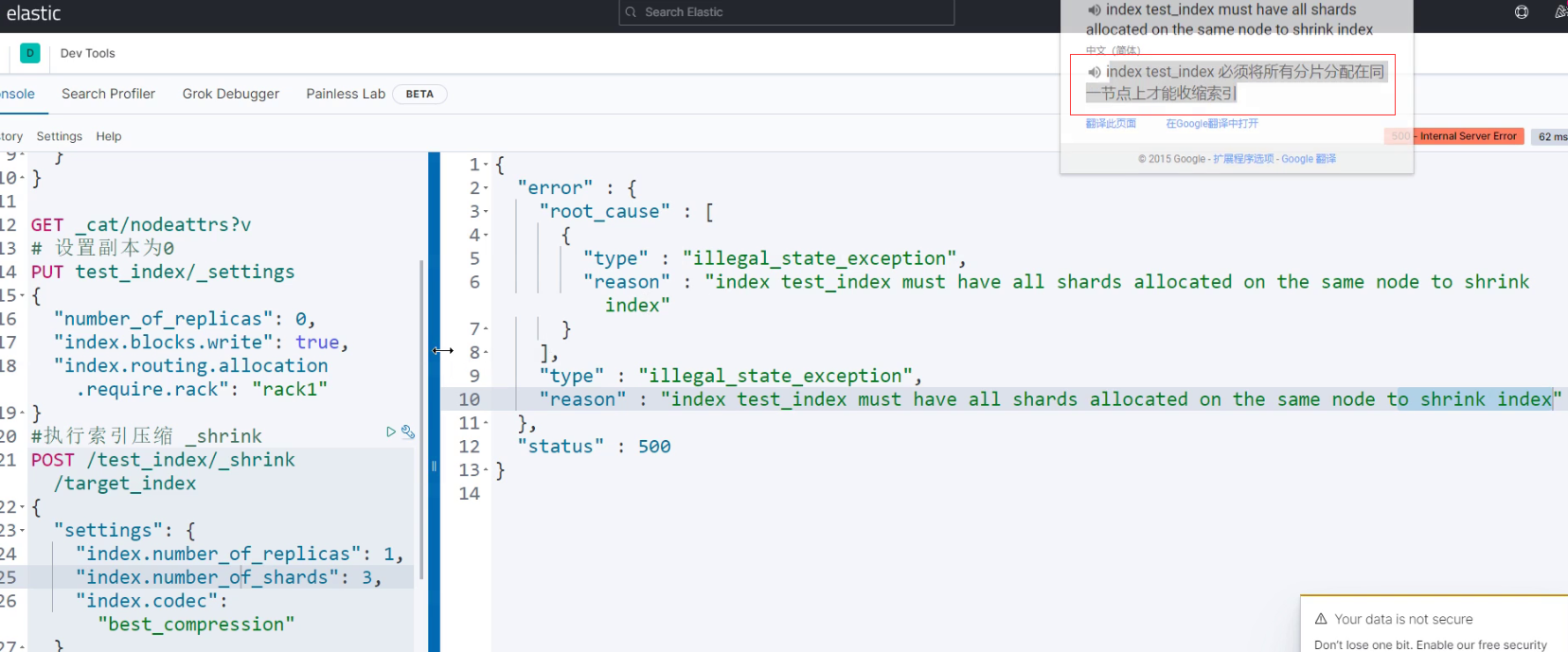
解决:
index.routing.allocation.require._name:null
index.routing.allocation.require._name:node1
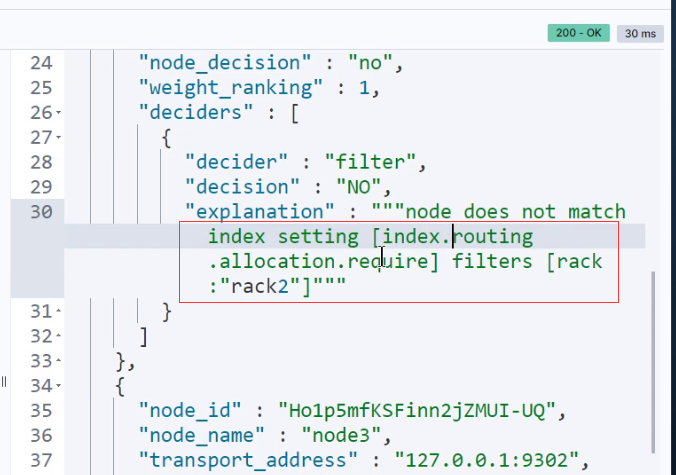
如果发现副本还是恢复失败可以通过命令查看错误原因
GET _cluster/allocation/explain

工作原理和过程
1.创建一个新的目标索引,其定义与源索引相同,但分片数量较少。
2.将段从源索引硬链接到目标索引。如果文件系统不支持硬链接,则将所有segmenttfile都复制到新索引中复制过程很耗时。
3.shard recovery 操作,恢复目标索引。
3,索引别名
GET .kibana task manager_7.13.0_001/ alias
语法:
POST /_aliases


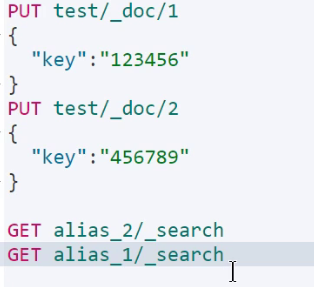
定义了两个别名,分别进行查询
4,滚动索引
根据上面别名实现的滚动索引,别名会跟着最新索引移动
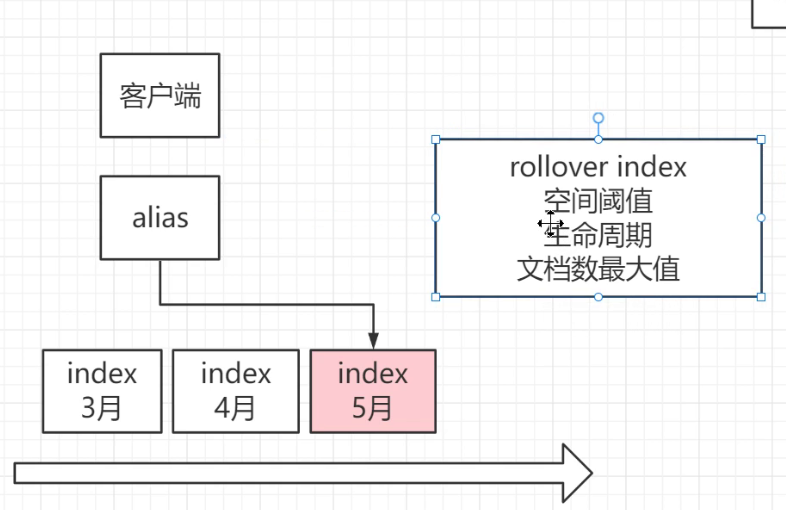
2 触发条件
- max age: 时间闻值
- max docs: 文档数闻值
- max size: 空间闻值

4,创建索引
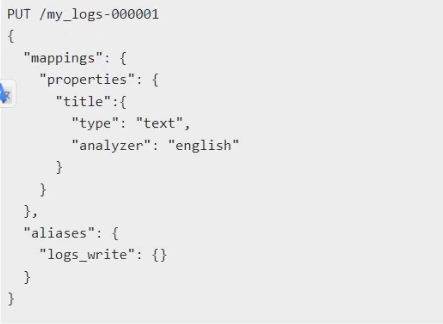
使索引满足触发条件

注意:
- ES 的写入默认有延迟,可执行手动刷新
- POST logs_write/_refresh
执行滚动索引

滚动索引内部其实就是利用reinx实现的,所以新创建的索引会丢失mapping和setting,利用下面的索引模板可以解决
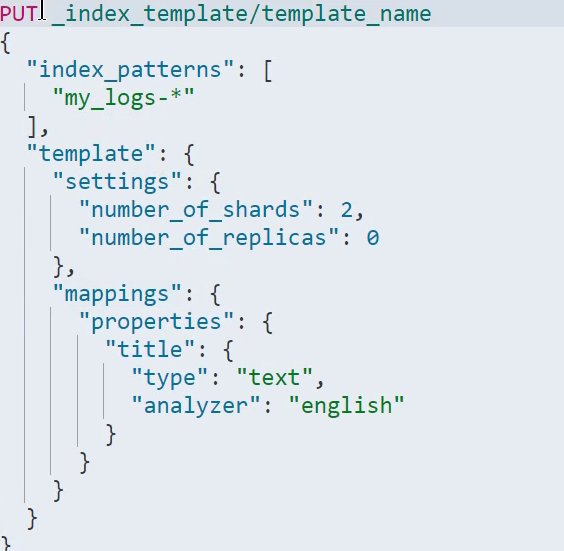
6、索引模板
6.1 概念
官方解释: 索引模板是一种告诉Elasticsearch在创建索引时如何配置索引的方法。对于数据流,索引模板在创建时配置流的 backingDice。模板已配置创建索引之前,创建索引时(无论是手动创建还是通过索引文档),模板设置都将用作创建索引的基础。
官方对于索引模板的解释已经比较清晰了,索模板在企业生产实践中常配合滚动索引(Rollover index)、索引的生命周期管理(ILM: Index lifecycle management) 、数据流一起使用。
案例:

上面的index_a和index_b的mapping的设置值不一样因为: reindex不会复制源mapping的设置值
index_patterns 索引规则,以my_logs-开头的索引
7,索引生命周期管理
7.1 官方释义
配置索引生命周期管理(LM)策略,以根据性能、可伸缩性和保留要求自动管理索引。例如,使用ILM 来
。当索引达到特定大小或文档数量时启动新索引
。每天、每周或每月创建一个新索引并归档以前的索引
。删除过时的索引以强制执行数据保留标准
通过 Kibana Management或ILM API创建和管理索引生命周期策略,当为 Beats 或 Logstash Elasticsearch输出插件启用索引生命周期管理时,会自动配置默认策略。
7.2生命周期的阶段

Hot(热): The index is actively being updated and queried.(可读可写可修改)
Warm(温): The index is no longer being updated but is still being queried.
Cold(冷): The index is no longer being updated and is queried infrequently The information still needsto be searchable, but it’ s okay if those queries are slower.(查询慢没关系)
Frozen(冻结): The index is no longer being updated and is queried rarely. The information still needs tobe searchable, but it' s okay if those queries are extremely slow.(比如银行20年前的数据)
Delete(删除): The index is no longer needed and can safely be removed.(50年前的数据)
7.3 不同阶段允许的操作
7.3.1 Hot phase
- Set Priority
- Unfollow
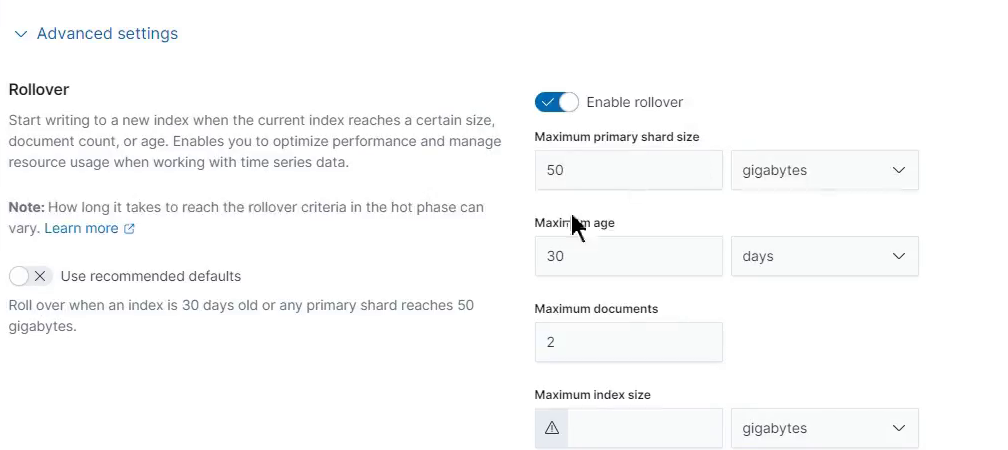
- Rollover(滚动索引) 常用
- Read-Only
- Shrink(索引压缩)
- Force Merge
- Searchable Snapshot
7.3.2 Warm phase
- set piorify
- nfollow
- Read-Only
- Allocate
- Migrate
- Shrink
- Force Merge
7.3.3 Cold phase
- Set Priority
- Unfollow
- Read-Only
- Searchable Snapshot(快照)
- Allocate
- Migrate
- Freeze
7.3.4 Frozen phase
- Searchable Snapshot -》 https://www.elastic.co/! SearchableSearchable Snapshot
7.3.5 Delete phase
- Wait For Snapshot
- Delete

索引生命周期策略

Hot phase设置
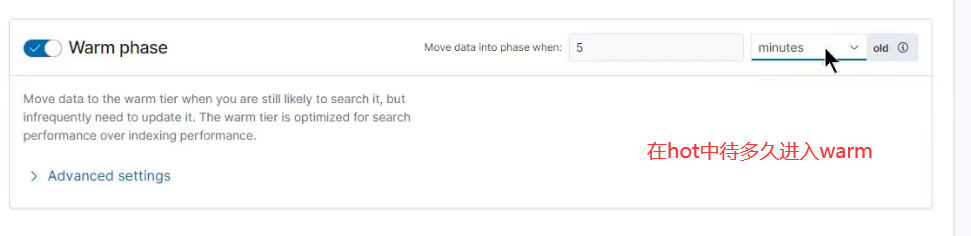
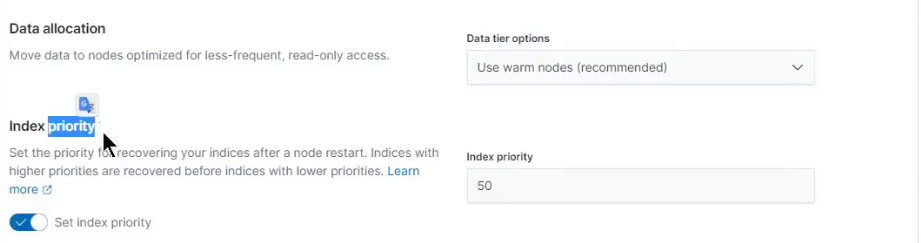
warm phase
cold phase设置

点击 show request可以复制配置




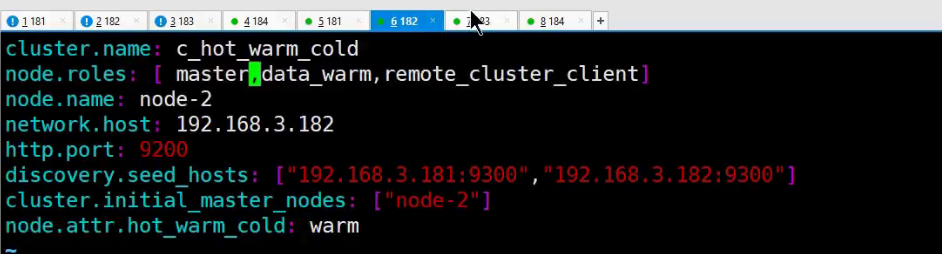
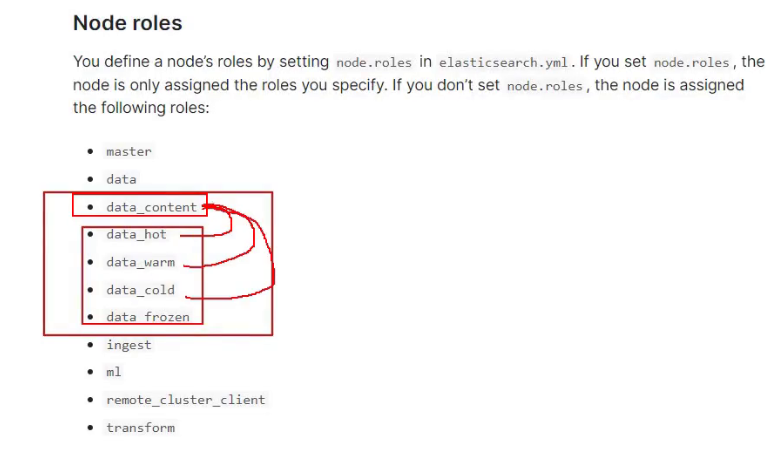
单纯使用ILM策略的时候,数据会优先分配给具有data_content节点,所以在hot节点需要配置data_content



8,数据流
数据流详见 《elastic索引管理-数据流 》
本文来自博客园,作者:孙龙-程序员,转载请注明原文链接:https://www.cnblogs.com/sunlong88/p/17626611.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号