

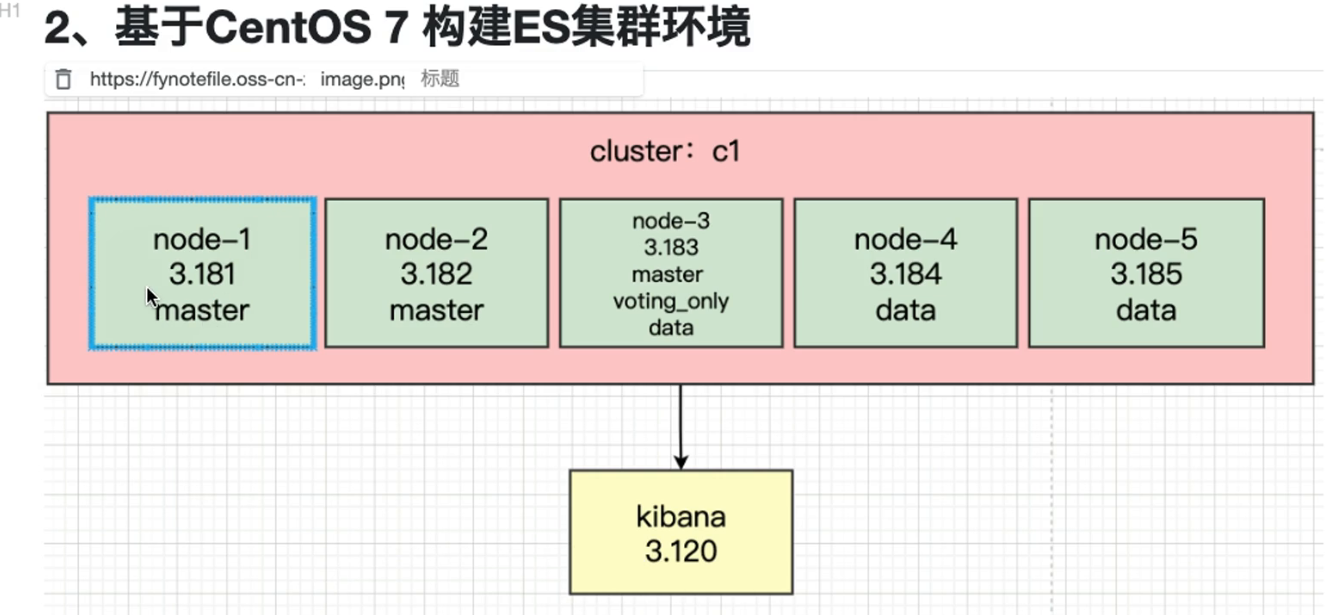
集群:
node1-node3专用主节点
node3仅投票节点
启动服务: ./bin/elasticsearch 后台启动守护进程 ./bin/elasticsearch 推荐方式 ./bin/elasticsearch -d -p pid 关闭进程 ps -ef|grep elastic 杀进程 kill -9 'cat pid' pkill -F pid
常见问题:
本地无法访问:
关闭防火墙,生产环境建议仅开放指定端口
systemctl stop firewalld
#禁用防火墙systemctl disabled firewalld
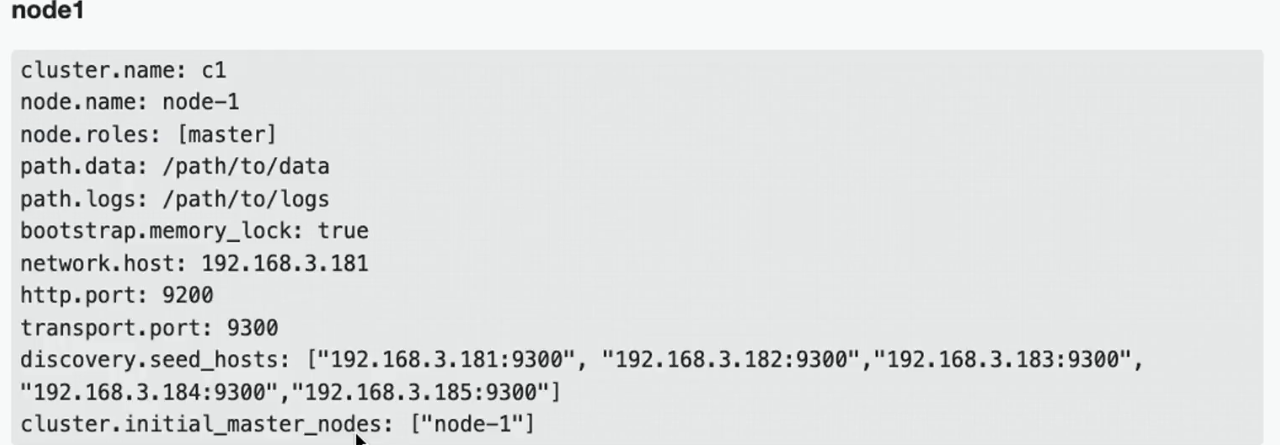
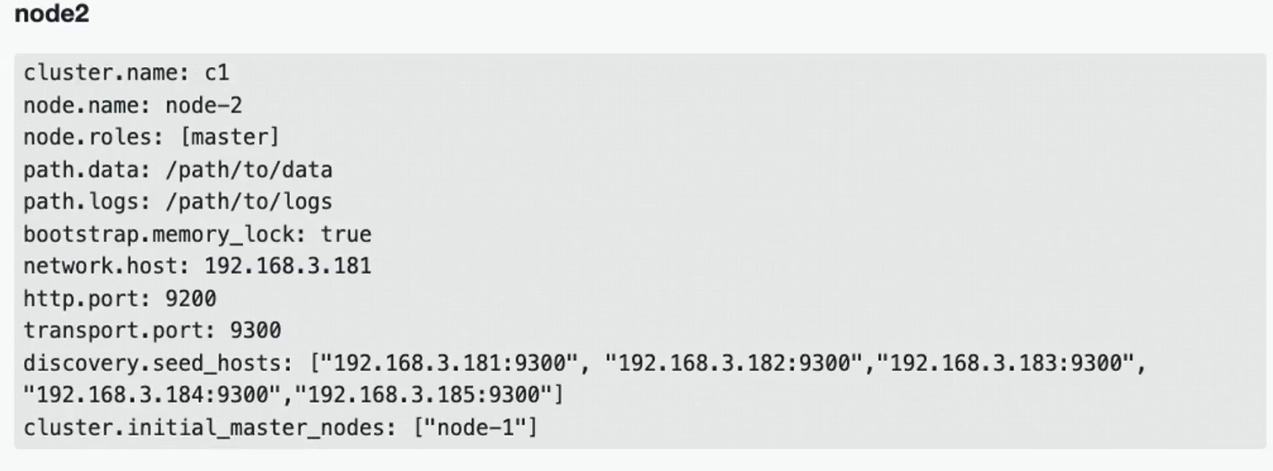
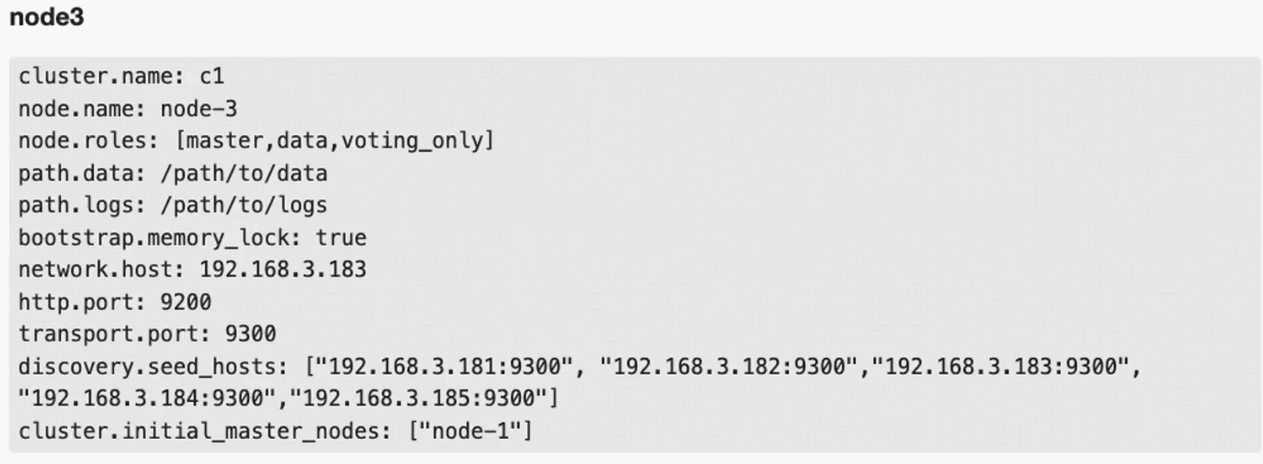
配置节点:
- clustername:集群名称,节点根据集群名称确定是否是同一个集群。
- 。node.name:节点名称,集群内唯一。
- noderoles:[data,master, voting_only],node.roles配置项如果没有显式的配置,那么当前节点拥有所有角色 (master、data、ingest、ml、remote cluster_client、transform) 。如果你放开了注释,或者手动显式添加了 node.role配置项,那么当前节点仅拥有此配置项的中括号中显式配置的角色,没有配置的角色将被阉割。因此如果在不熟悉角色配置的情况下,不要轻易修改角色配置值,切勿画蛇添足。network.host: 节点对外提供服务的地址以及集群内通信的ip地址bootstrap.memory_lock: Swapping对性能和节点稳定性非常不利,应该不惜一切代价避免。它可能导致GC持续几分钟而不是几毫秒,并且可能导致节点响应缓慢甚至与集群断开连接。在弹性分布式系统中,使用Swap还不如让操作系统杀死节点效果更好。可以通过设置 bootstrap.memory_lock: true 以防止任何Elasticsearch 堆内存被换出。
- http.port:对外提供服务的端口号
- discovery.seed hosts: 集群初始化的种子节点,可配置部分或全部候选节点,大型集群可通过嗅探器发现剩余节点,考试环境配置全部节点即可
- clusterinitial_master_nodes: 节点初始active master节点,必须是有master角色的节点,即必须是候选节点,但并不是必须配置所有候选节点。生产模式下启动新集群时,必须明确列出应在第一次选举中计算其选票的候选节点。第一次成功形成集群后,cluster.initial_master_nodes从每个节点的配置中删除设置。重新启动集群或向现有集群添加新节点时,请勿使用此设置。
高可用集群
冷热集群
1、冷热数据分离思想
2、数据层:Data tiers
2.1 内容层:Content Tier
2.2 热数据层:Hot Tier
2.3 温数据层:Warm Tier
2.4 冷数据层:Cold Tier
2.5 冻结层:Frozen Tier
3、节点角色
3.1 内容节点
3.2 热数据节点
3.3 温数据节点
3.4 冷数据节点
3.5 冻结数据节点
引言
首先抛出问题:对于热点搜索而言,最高效的存储手段是什么?
一味地堆硬件配置,不仅不能有效的解决问题,反而会让服务变得臃肿,集群变得累赘增加管理成本和硬件成本。
本文主要探讨关于热点数据的高效存储问题,讨论范围在数据持久化前提下,多级缓存暂不讨论。
1、冷热数据分离思想
冷热集群架构方案即我们常说的冷热数据分离。本质是针对不同访问频率的数据做分离存储,让访问量高的数据存放在性能更好的磁盘中,以实现更合理的资源分配和调度。
就实际而言,其实超过80%的请求,集中在20%的数据上,所以如果普遍采取廉价的机械磁盘存储,势必达不到良好的性能。而如果全面采用SSD做保证数据持久化存储,又会带来高昂的硬件成本,这其实完全没有必要。
这里有人提过质疑,说热数据做缓存就行了呀,费这个劲干啥?其实从原理上来说,冷热数据分离和多级缓存是非常类似的,一句话概括就是把更高频访问的数据,放在性能搞好的硬件上。但区别就是多级缓存是不考虑数据持久化的。
这种资源分层调度的思想应用其实非常广泛:
性能越快的硬件往往空间越少,以至于其只能把最高频使用的数据放进去,如CPU的L1、L2、L3三级缓存。性能递减,容量递增。上升到整个计算机层面,CPU到内存再到磁盘,也是速度递减,容量递增。本质上讲,就是把最常用的东西放在最近的位置。
举个通俗易懂的例子:
我们睡觉的时候,都是把第二天要穿的衣服放在床边,床边是最方便的,但是床边就只能放这么一套衣服,放不了太多。
如果向要换衣服,就要去衣柜里找,衣柜的空间更大,但是衣柜离我们更远,拿取衣服就需要翻箱倒柜(寻址)
衣柜里也没你想要的衣服了,那你就要去商场里购买,商场里有足够多的衣服让你选,但是商场很远,你需要更多的时间来选衣服、把衣服运送过来。
这个例子可以看成是一个多级缓存的例子,在这里例子里,床边让你放衣服的椅子拿衣服是最快的,你可以看成是你的顶级缓存或一级缓存;衣柜可以看成是你的二级缓存,容量大一些,速度慢一些;而商场就是三级缓存,容量更大,速度更慢。如果把这个过程看成是计算机的CPU、内存到磁盘的过程。那么在商场中选购衣服可以看成是在磁盘中查找数据。选衣服的过程就是磁盘寻址,而把衣服拿回家,就是磁盘IO。
同样这个例子也可以是冷热数据分离的一个比喻,此时我们可以把数据划分为热数据、温数据、冷数据三个阶段。那么可以做如下类比:
床边放衣服的椅子 => 热数据
衣柜 => 温数据
商场 => 冷数据
2、数据层:Data tiers
在 Elasticsearch 中,不同热度的数据,通过 Data tiers 来界定。数据层是具有相同数据角色的节点的集合,通常共享相同的硬件配置文件。根据不同的热度,ES 把数据层定义为四个阶段:
hot tier:处理时间序列数据(例如日志或指标)的索引负载,并保存您最近、最常访问的数据。
warm tier:保存访问频率较低且很少需要更新的时间序列数据。
cold tier:保存不经常访问且通常不更新的时间序列数据。
frozen tier:保存很少访问且从不更新的时间序列数据,保存在可搜索的快照中。
另外还有一个特殊的内容层:
content tier:处理产品目录等内容的索引和查询负载。
当文档直接索引到特定 index 时,会永久保留在 content tier 节点上。
当文档索引到数据流时,数据最初驻留在 hot tier 节点上。
2.1 内容层:Content Tier
存储在内容层中的数据通常是项目的集合,例如产品目录或文章存档。与时间序列数据不同,内容的价值随着时间的推移保持相对恒定,因此随着时间的推移将其移动到具有不同性能特征的层是没有意义的。内容数据通常具有较长的数据保留要求,并且您希望能够快速检索项目,无论它们有多旧。
内容层节点通常针对查询性能进行优化——它们优先考虑处理能力而不是 IO 吞吐量,因此它们可以处理复杂的搜索和聚合并快速返回结果。虽然它们还负责索引,但内容数据的摄取率通常不如日志和指标等时间序列数据那么高。从弹性的角度来看,该层中的索引应配置为使用一个或多个副本。
内容层是必需的。不属于数据流的系统索引和其他索引会自动分配给内容层。
2.2 热数据层:Hot Tier
热层是时间序列数据的 Elasticsearch 入口点,保存最近、最常搜索的时间序列数据。热层中的节点需要快速读取和写入,这需要更多的硬件资源和更快的存储 (SSD)。为了弹性,热层中的索引应配置为使用一个或多个副本。
热层是必须的。作为数据流一部分的新索引会自动分配给热层。
2.3 温数据层:Warm Tier
一旦查询的频率低于热层中最近索引的数据,时间序列数据就可以移动到热层。暖层通常保存最近几周的数据。仍然允许更新,但可能不频繁。热层中的节点通常不需要像热层中的节点那样快。为了弹性,应将暖层中的索引配置为使用一个或多个副本。
2.4 冷数据层:Cold Tier
一旦数据不再被更新,它就可以从暖层移动到冷层,并在不经常被查询的情况下停留在那里。冷层仍然是响应式查询层,但冷层中的数据不会正常更新。随着数据转换到冷层,它可以被压缩和缩小。对于弹性,冷层可以使用完全安装的 可搜索快照索引,从而消除对副本的需求。
2.5 冻结层:Frozen Tier
一旦数据不再被查询或很少被查询,它可能会从冷层移动到冻结层,并在其余生中停留。
冻结层使用部分安装的索引来存储和加载来自快照存储库的数据。这降低了本地存储和运营成本,同时仍然让您搜索冻结的数据。因为 Elasticsearch 有时必须从快照存储库中获取冻结数据,所以在冻结层上的搜索通常比在冷层上慢。
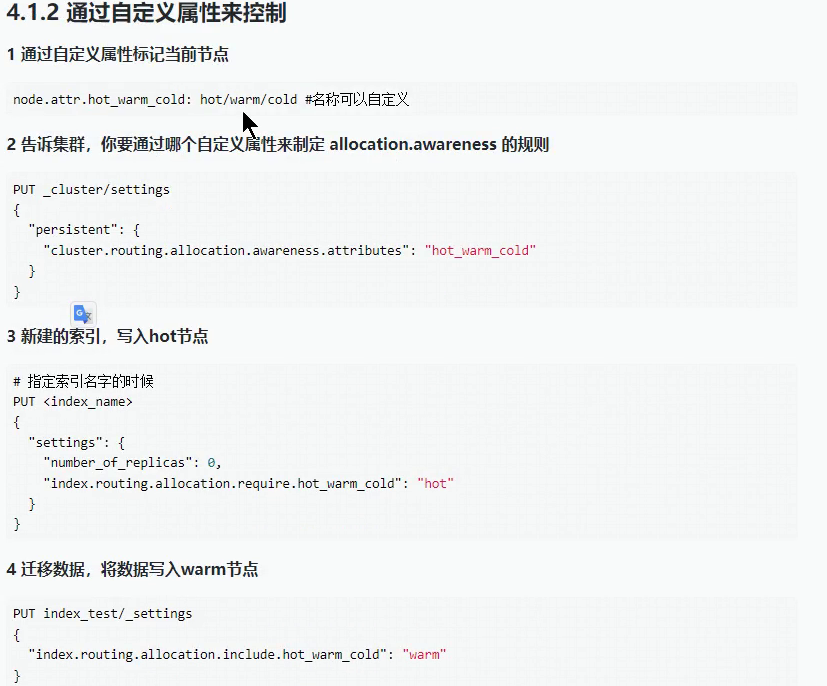
1,通过节点角色来控制
角色
-
- data_content
- data_hot
- data_warm
- data_cold
- data_frozen
关于 node.roles的注意事项
node.roles配置项如果没有显式的配置,那么当前节点拥有所有角色 (master、data、ingest、mlremote cluster client、transform) 。如果你放开了注释,或者手动显式添加了 node.roles配置项,那么当前节点仅拥有此配置项的中括号中显式配置的角色,没有配置的角色将被阉割。因此如果在不熟悉角色配置的情况下,不要轻易修改角色配置值,切勿画蛇添足。
7.13 之后版本不要使用传统的老方式去配置角色设置,即: 如下方式不要再用
- node.master: true
- node.data: true
单节点集群一定要保证节点同时拥有 master和 data 两个角色,切记是 data(或 data content)不是 data hot/data warm/data cold.
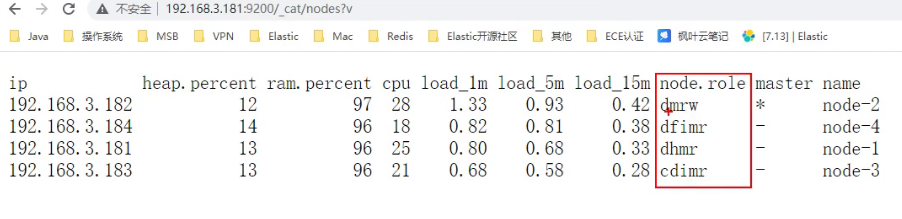
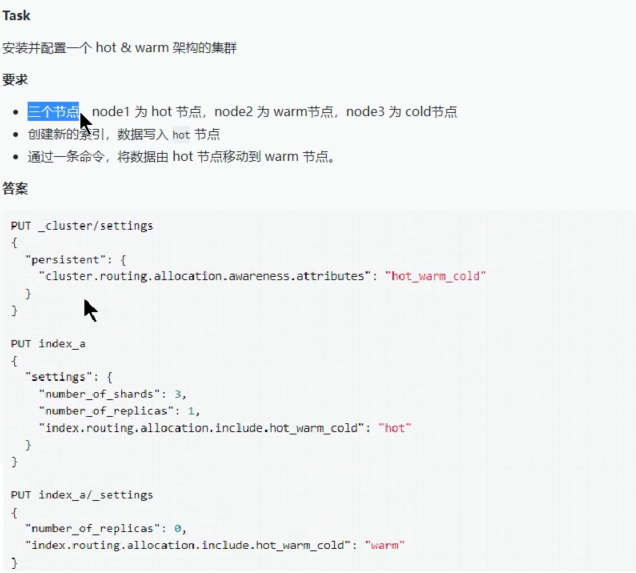
案例:
3.1 内容节点
内容数据节点容纳用户创建的内容。它们支持 CRUD、搜索和聚合等操作。
要创建专用内容节点,在配置文件中设置:
node.roles: [ data_content ]
1
3.2 热数据节点
热数据节点在进入 Elasticsearch 时存储时间序列数据。热层对于读取和写入都必须快速,并且需要更多的硬件资源(例如 SSD 驱动器)。
要创建专用热节点,配置
node.roles: [ data_hot ]
1
3.3 温数据节点
暖数据节点存储不再定期更新但仍在查询的索引。查询量的频率通常低于索引处于热层时的频率。此层中的节点通常可以使用性能较低的硬件。
要创建一个专用的暖节点,
node.roles: [ data_warm ]
1
3.4 冷数据节点
冷数据节点存储访问频率较低的只读索引。该层使用性能较低的硬件,并且可以利用可搜索的快照索引来最小化所需的资源。
要创建专用冷节点,设置
node.roles: [ data_cold ]
1
3.5 冻结数据节点
冻结层 专门存储部分安装的索引。我们建议您在冻结层中使用专用节点。
要创建专用的冻结节点,设置
node.roles: [ data_frozen ]
1
本文来自博客园,作者:孙龙-程序员,转载请注明原文链接:https://www.cnblogs.com/sunlong88/p/17626463.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号