
bm25算法与tf-idf算法比较
一、tf-idf算法介绍
词频(TF)=某篇文章中某个关键词出现的次数/文章总字数,逆文档频率(IDF) = log(语料库文章总数/包含该关键词的文章总数+1),tfidf=tf*idf,下面给大家举个实例,你大概就明白了,例如语料库中有以下三篇文章:
第一篇:张一山与杨紫疑似相恋;
第二篇:C罗又一次完成了帽子戏法,这就是足球的魅力;
第三篇:恭喜TES创历史记录,在s10的世界总决赛上完成了让二追三;
首先是对每篇文章进行分词且过滤停用词得doc_lis=[[张一山,…,相恋],[C罗,…,魅力],[恭喜,…,让二追三]],然后依次计算每个关键词的tfidf。TF(张一山)=1/4(“与”作为停用词过滤掉了所以是4) IDF(张一山)=log(3/1+1),所以tfidf=TF*IDF=1/4*log3/2=0.25*0.405=0.1,按照这个方式依次计算就能得到所有词的tfidf,最终的结果如下表:
| 文章\词 | 张一山 | 杨紫 | … | 完成 | 让二追三 |
| 第一篇 | 0.1 | 0.1 | 0 | 0 | |
| 第二篇 | 0 | 0 | 0 | 0 | |
| 第三篇 | 0 | 0 | tfidf值 | tfidf值 |
这张表的shape应该(总词数,总文章数),因此tfidf的应用可以有:
1、文章关键词提取(可以提取tfidf值前几个作为关键词);
2、文章分类,这个矩阵直接输入到项lsvm,lr等模型(当然要打好label);
3、用LDA或SVD进行降维(为什么要降维,因为语料库的总词数是非常多的,所以每篇文章的向量是非常稀疏的),再当做文章的embeding;
4、把tfidf或idf值当做每个词的权重。
tfidf算法的优点:
简单,快速,如果语料库是不变的话,可以提前离线计算好语料库中所有词的tfidf值(这在实际应用中非常重要的,后面有这个应用的举例)
tfidf算法的缺点:
1、仅以“词频”度量词的重要性,后续构成文档的特征值序列,词之间各自独立,无法反映序列信息;
2、tfidf得到是一个稀疏而庞大的矩阵,需要采用降维方式,才方便做后续的文本任务,而降维可能会损失一些信息,同时降维的也会提高模型的复杂度,而失去了原本快速的优点;
3、tfidf得到的embedings再输入后续的模型,做文本分类、文本匹配等任务,在效果上通常会差于采用词向量模型训练得到的embedding。
二、BM25算法介绍
bm25是一种用来评价搜索词和文档之间相关性的算法,它是一种基于概率检索模型提出的算法,再用简单的话来描述下bm25算法:我们有一个query和一批文档Ds,现在要计算query和每篇文档D之间的相关性分数,我们的做法是,先对query进行切分,得到单词$q_i$,然后单词的分数由3部分组成:
1、单词$q_i$和D之间的相关性
2、单词$q_i$和D之间的相关性
3、每个单词的权重
最后对于每个单词的分数我们做一个求和,就得到了query和文档之间的分数。
bm25算法解释
讲bm25之前,我们要先介绍一些概念。
二值独立模型 BIM
BIM(binary independence model)是为了对文档和query相关性评价而提出的算法,BIM为了计算$P(R|d,q)$,引入了两个基本假设:
假设1
一篇文章在由特征表示的时候,只考虑词出现或者不出现,具体来说就是文档d在表示为向量$\vec x=(x_1,x_2,…,x_n)$,其中当词$t$出现在文档d时,$x_t=1$,否在$x_t=0$。
假设2
文档中词的出现与否是彼此独立的,数学上描述就是$P(D)=\sum_{i=0}^n P(x_i)$
有了这两个假设,我们来对文档和query相关性建模:
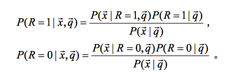
其中

分别表示当返回一篇相关或不相关文档时文档表示为x的概率。
接着因为我们最终得到的是一个排序,所以,我们通过计算文档和query相关和不相关的比率,也可得文档的排序,有下面的公式:
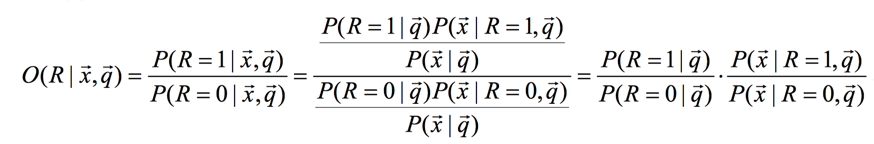
其中
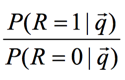
是常数,我们可以不考虑,再根据之前的假设2:一个词的出现 与否与任意一个其他词的出现与否是互相独立的,我们可以化简上面的式子:
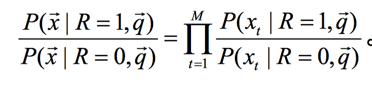
我们接着引入一些记号:
![]()
词出现在相关文档的概率
![]()
词出现在不相关文档的概率
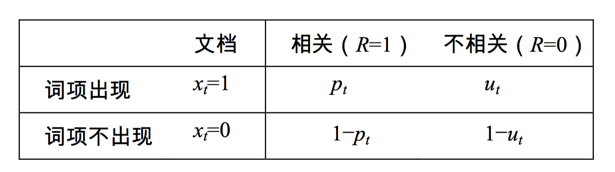
于是我们就可得到:
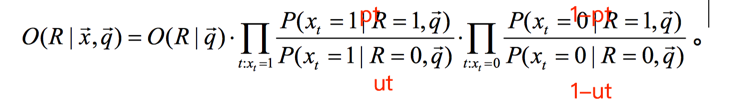
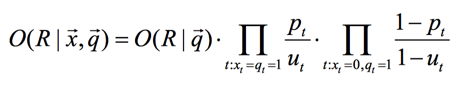
我们接着做下面的等价变换:
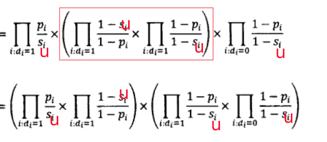
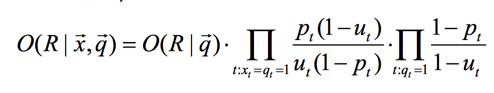
此时,公式中
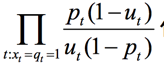 根据出现在文档中的词计算,
根据出现在文档中的词计算,
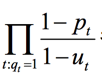
则是所有词做计算,不需要考虑,此时我们定义RSV (retrieval status value),检索状态值:
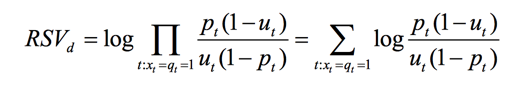
定义单个词的ct
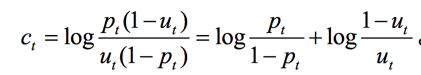
下一步我们要解决的就是怎么去估计pt和ut,看下表:
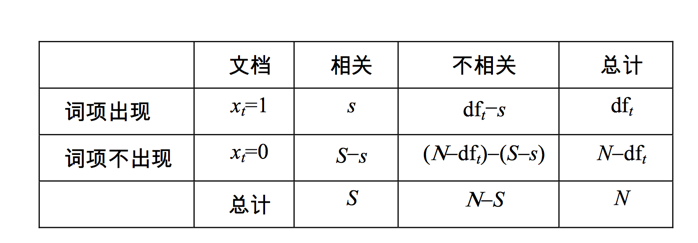
其中dft是包含词t的文档总数,于是
![]()
此时词t的ct值是:
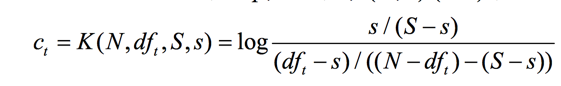
为了做平滑处理,我们都加上1/2,得到:
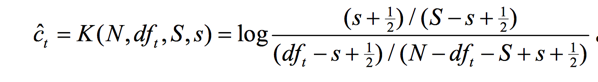
在实际中,我们很难知道t的相关文档有多少,所以假设S=s=0,所以:
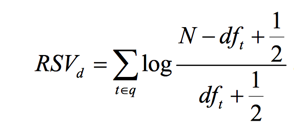
其中N是总的文档数,dft是包含t的文档数。
以上就是BIM的主要思想,后来人们发现应该讲BIM中没有考虑到的词频和文档长度等因素都考虑进来,就有了后面的BM25算法,下面按照
1、单词t和D之间的相关性
2、单词t和D之间的相关性
3、每个单词的权重
3个部分来介绍bm25算法。
单词权重
单词的权重最简单的就是用idf值,即
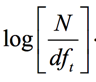
,也就是有多少文档包含某个单词信息进行变换。如果在这里使用 IDF 的话,那么整个 BM25 就可以看作是一个某种意义下的 TF-IDF,只不过 TF 的部分是一个复杂的基于文档和查询关键字、有两个部分的词频函数,还有一个就是用上面得到的ct值。
单词和文档的相关性
tf-idf中,这个信息直接就用“词频”,如果出现的次数比较多,一般就认为更相关。但是BM25洞察到:词频和相关性之间的关系是非线性的,具体来说,每一个词对于文档相关性的分数不会超过一个特定的阈值,当词出现的次数达到一个阈值后,其影响不再线性增长,而这个阈值会跟文档本身有关。
在具体操作上,我们对于词频做了”标准化处理“,具体公式如下:
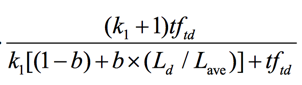
其中,tftd 是词项 t 在文档 d 中的权重,Ld 和 Lave 分别是文档 d 的长度及整个文档集中文档的平均长度。k1是一个取正值的调优参数,用于对文档中的词项频率进行缩放控制。如果 k 1 取 0,则相当于不考虑词频,如果 k 1取较大的值,那么对应于使用原始词项频率。b 是另外一个调节参数 (0≤ b≤ 1),决定文档长度的缩放程度:b = 1 表示基于文档长度对词项权重进行完全的缩放,b = 0 表示归一化时不考虑文档长度因素。
单词和查询的相关性
如果查询很长,那么对于查询词项也可以采用类似的权重计算方法。
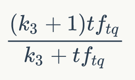
其中,tftq是词项t在查询q中的权重。这里k3 是另一个取正值的调优参数,用于对查询中的词项tq 频率进行缩放控制。
于是最后的公式是:

bm25算法gensim中的实现
gensim在实现bm25的时候idf值是通过BIM公式计算得到的:

然后也没有考虑单词和query的相关性。

其中几个关键参数取值:
PARAM_K1 = 1.5
PARAM_B = 0.75
EPSILON = 0.25
此处EPSILON是用来表示出现负值的时候怎么获取idf值的。
bm25的算法的优点:
优点:可以方便线下做离线先计算好文档中出现的每一个词的idf并保存为一个字典,当用户搜了一个query,直接分词然后查字典就能得到这个词的idf,如果字典中没有idf值无意义,因为R=0。同于tfidf。
缺点:同于tfidf
总结下本文的内容:BM25是检索领域里最基本的一个技术,BM25 由三个核心的概念组成,包括词在文档中相关度、词在查询关键字中的相关度以及词的权重。BM25里的一些参数是经验总结得到的,后面我会继续介绍BM25的变种以及和其他文档信息(非文字)结合起来的应用。
bm25算法适用于什么情况
BM25算法,通常用来作搜索相关性平分。一句话概况其主要思想:对Query进行语素解析,生成语素qi;然后,对于每个搜索结果D,计算每个语素qi与D的相关性得分,最后,将qi相对于D的相关性得分进行加权求和,从而得到Query与D的相关性得分。
BM25算法的一般性公式如下:
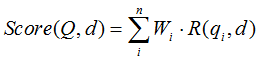
其中,Q表示Query,qi表示Q解析之后的一个语素(对中文而言,我们可以把对Query的分词作为语素分析,每个词看成语素qi。);d表示一个搜索结果文档;Wi表示语素qi的权重;R(qi,d)表示语素qi与文档d的相关性得分。
下面我们来看如何定义Wi。判断一个词与一个文档的相关性的权重,方法有多种,较常用的是IDF。这里以IDF为例,公式如下:
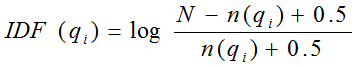
其中,N为索引中的全部文档数,n(qi)为包含了qi的文档数。
根据IDF的定义可以看出,对于给定的文档集合,包含了qi的文档数越多,qi的权重则越低。也就是说,当很多文档都包含了qi时,qi的区分度就不高,因此使用qi来判断相关性时的重要度就较低。
我们再来看语素qi与文档d的相关性得分R(qi,d)。首先来看BM25中相关性得分的一般形式:
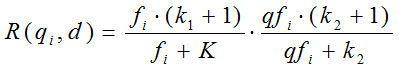
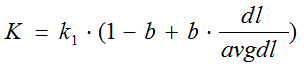
其中,k1,k2,b为调节因子,通常根据经验设置,一般k1=2,b=0.75;fi为qi在d中的出现频率,qfi为qi在Query中的出现频率。dl为文档d的长度,avgdl为所有文档的平均长度。由于绝大部分情况下,qi在Query中只会出现一次,即qfi=1,因此公式可以简化为:
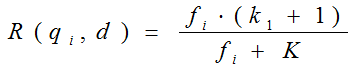
从K的定义中可以看到,参数b的作用是调整文档长度对相关性影响的大小。b越大,文档长度的对相关性得分的影响越大,反之越小。而文档的相对长度越长,K值将越大,则相关性得分会越小。这可以理解为,当文档较长时,包含qi的机会越大,因此,同等fi的情况下,长文档与qi的相关性应该比短文档与qi的相关性弱。
综上,BM25算法的相关性得分公式可总结为:
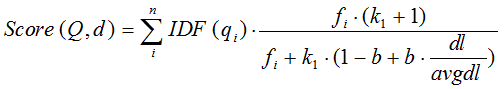
从BM25的公式可以看到,通过使用不同的语素分析方法、语素权重判定方法,以及语素与文档的相关性判定方法,我们可以衍生出不同的搜索相关性得分计算方法,这就为我们设计算法提供了较大的灵活性。
本文来自博客园,作者:孙龙-程序员,转载请注明原文链接:https://www.cnblogs.com/sunlong88/p/17598930.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号