
1,系统设计原则及技术指标
系统-技术设计原则
好系统是迭代出来的。
先解决核心的问题,预测未来可能出现的问题。第一版 1000人,所以单机。
不要过度复杂化系统。
先行的规划和设计。
对现有的问题有方案,对未来系统有预案。
无状态原则:
无状态:对单词请求的处理,不依赖于其他的请求。
处理一次请求所需的全部信息,都在这个请求中,要么可以从外部获取(配置文件,外部存储(redis)),
服务器本身不存储任何信息。
总结:服务器是不保存请求状态的服务,就是无状态。
所有需要鉴权的都是有状态?token。
服务器是不是可以 无限扩展,水平扩展。
token:
1。 不存token。坏处:不好控制。token可以自过期(jwt)。
2。存token。坏处:存储负担。
拆分原则:
巨石系统。
用户量大,业务复杂了,公司可以投入的资源多了。
拆:高内聚,低耦合。
系统维度:商品系统,购物车系统,支付系统,优惠券系统等等。
需要和产品经理配合。
电商系统:用户系统,订单系统。
将这个系统尽量做成黑盒。
功能维度:优惠券系统:后台创建券的系统,用户领券系统,用券系统。
**读写维度:**读写比例特征进行拆分。读服务(多级缓存)和写服务(分区、分库分表)。
切面:cdn。对系统功能进行详细的梳理。aop。
模块:基础架构组,二方库。数据库连接模块,分库分表模块,综合消息队列(统一配置,主流消息队列 ),。
服务化原则:单节点?节点集群?
服务化原则:1万个服务,url。服务治理:自动注册与发现。流量不可控,限流、熔断、降级、隔离、恢复。
项目介绍。带上自己的思考。
代码:埋点。
系统-业务设计原则
防重原则,幂等原则
识别什么是重复?读?和写(有些不用,逻辑删除update 0->0,update set = 0 where = 1),每次都+1。?。
针对重复做拒绝。
模块服用原则:当你有拷贝欲望的时候,就要考虑代码的重构了。沉淀通用功能。
可追溯原则:任何问题,要有据可查,要好定位。
反馈原则:给调用方一个明确的反馈。
A:用户名不存在,账号密码错误,用户无权限。
B:登录错误,请重试。
备份原则:
代码备份:git,分支
数据备份:运维备份。操作记录备份。
人员备份:也就是 不因某个人离职,而导致项目的停滞。
规范。定期review,提交之前有责任人。罚款。gerrit。
分享:挑刺。
软件质量衡量标准
从你不同的维度对我负责的项目进行评判。 面试、晋升,工作中。
晋升:总结过去(衡量的标准),展望未来
ios/iec 250xxxxx。
功能性:满足功能要求。
效能:投入多少,产出多少。
兼容性:
易用性:
可靠性:容错,可恢复。
安全:
可维护性:
可移植性:
我自己舒服,第二别人觉得我厉害。
答疑:
二方库:自己公司内部的公共模块。
在别人的烂代码上做功能扩展怎么破?感觉烂又不敢动,太难了。
解决方案:保证黑盒。由小到大(一行代码,一个方法,一个类,一个模块)。
互联网项目:oa(卖出去的)。bat。
表现自己的思考。
系统衡量指标
吞吐量
单位时间内,能接受和发出的数据量。业务、配置。
TPS: Transaction Per Second,事务:请求,处理,响应。
QPS:Queries Per Second,
tps和qps:之间的换算关系,必须由指定的业务场景来定。
并发数
300 并发用户数?并发连接数?并发请求数?并发线程数?
响应时间&平均响应时间
RT:
阿姆达尔定理:
加速比:Rm=T老/T新。
增强比例:p=m/总
T新=T老 * [(1-p)+p/Rm]
P大的。Rm
io。Rm
可靠性指标
串联:99% 99% 99% 99% 99% 越乘以 越小= 95%
冗余:
并联:1-(1-r1)*(1-r2)(1-r3)** 越乘以 越大?
消除单点。
化串联为并联:
你出去买东西,一手交钱一手交货。你从网上买东西时,你先付钱,一段时间后才会给你发货,这就爸交钱和交货分开了,它能不能发货不影响你付账
项目面试要点
需求。必须熟悉。
解决方案。校验,token,黑名单,权限。
难点。重点:过程。找原因(原理,源码),并解决。
1。突出解决问题的能力。2。技术深度。
不好编,作为一个大牛,怎么可以有难点
黄晟
可以说项目中遇到的问题、瓶颈,怎么解决的
2,客户端优化
客户端优化
资源的获取,资源的处理,资源的展示。
资源:样式文件,脚本文件,图片,视频,文本等等。
浏览器:DOM树。
过程:
1。资源下载。
快:压缩。
不必要的cookie。
1k 1一亿个呢? 8亿。
JavaScript:删除无效字符,注释:1。减少体积。2。代码安全。语义合并。
CSS:类似。语义合并。9行。原来10个按钮 10个样式,class 1个样式。
http请求压缩:
head中加参数:Accept-Encoding:gzip,deflate
表示 客户端 可以接受的压缩内容的格式。
服务端响应:head: Content-Encoding:gzip
在服务端:手动做一些压缩的操作。
减少请求:
资源数目多、体积小,频繁创建http链接?
雪碧图:样式文件 background-postition:
js合并。
矢量图:<svg >
base64图片。
40% 以下。gzip 对文本文件的压缩 能压缩到原来的 40%以下。
转移给第三方。
连接:
http1.0 http 1.1()
http没有长短连接一说,长短连接 是 针对tcp的。
http是针对 请求和响应模式的,只要服务端给了响应,本次http连接 结束。
http1.1 发请求的时候,在请求头中:connection:keep-alive。
好处:减少了 创建和销毁连接的 消耗。
例子:网页,(css,js,html),baidu.com。
header里设置超时。
长轮询 和 短轮询
长轮询:发现服务端没有变化的话,那么将当前请求挂起一段时间,如果没变化,一直等到超时,如果有变化,则返回。
假如是查询数据库的,那不是一直要不停的查询吗?
1。 用redis。
2。发布 订阅。
形成自己的解决问题的 思路的框架。
双工通信
netty,websocket(ws)。
http在tcp的基础上 有 长 短 轮询。
tcp链接 有 长短。
现在 基本上都是http1。1 默认支持长连接。
长轮询 :是服务端控制的。
双工通信:前后端 可以彼此 交互。
connection: keep-alive
keep-alive: timeout=60s
资源的缓存
页面缓存,客户端本地缓存()
页面的缓存:可以控制 客户端、各级代理(中间的各个节点)、 对页面资源的缓存。
如何控制:headers : Cache-Control:public
可缓存性:
pubic(服务器 响应中): 各级都能缓存。
private(服务器 响应中): 只能 客户端 缓存,中间各级不缓存。
no-cache: (请求,响应):可以缓存,但是不能直接使用缓存,要去服务端验证一下。
no-store: (请求,响应):哪都不要存。
缓存有效期:
max-age=秒,缓存可以存活的时间。
s-maxage=秒,在各级节点存活的时间,如果是 客户端存储忽略。
max-stale=秒,可以忍受资源过期的时间。
min-fresh=秒,
重新验证和加载的设置
must-revalidate: 服务器重新验证之前,不可以使用该资源。
proxy-revalidate: 各级节点有效。
no-transform: 不能压缩图像。
only-if-cached: 只要缓存的,不要服务器的资源。
header:
Cache-Control: pulic, max-age=10,no-transform
缓存更新不及时:
1。更新文件名:版本号,url时间戳的变化。my-js.js。my-js-1.js。客户端和服务器要达成一致。
发布上线一个文件,这个文件名是变的,那么 缓存的文件 就失效了。
2。验证 缓存的有效性。
基于 文件的最后修改时间。
服务端:last-modified : 最后修改时间。
客户端:if-modified-since :自己需要资源的时间。
你要我1个手机,我给你手机,手机贴标:时间戳。。304,不返回具体资源。200:返回具体资源。
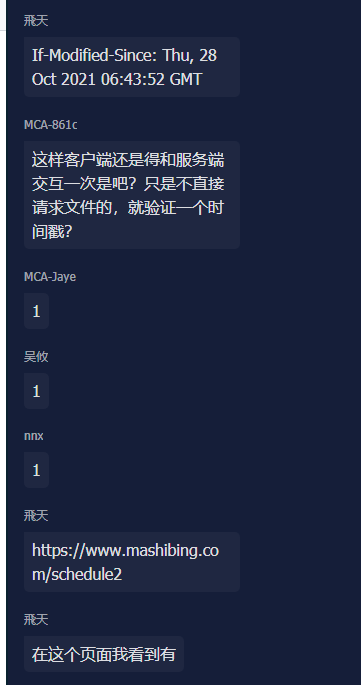
基于:版本号的。
etag: 版本号。
客户端在请求中:if-none-match:
2。 解析。元素,样式,脚本。
目的? 优化解析。
1。优化正常解析流程。
元素
css样式文件 render tree 布局好, 绘制。
js脚本
回流:
重绘:
目的:缩小 回流和重绘的 范围。
方法:分几个块。
2。创新解析流程。:
虚拟dom(Virtual DOM)。算法,比较前后两个dom的区别。
如果改变不了 它 本来的面目,那么就给 它 化化妆,改变展现的面目。
oracle 物化视图?
缓存 redis?
懒加载
h5 app 界面。
懒加载:仅仅加载 最基础的元素,以后,再根据用户的操作,进行局部加载。将原来一次性要加载的内容拆分成了多次加载。分流。
回流、重绘。
app上的,
树形组件,折叠面板,标签页。
尽量灵活一些,支持多种情况。
到了不得不看具体数据的时候,才调用后端。
但是也不一定,一些 经常不变的数据,就没必要了。
预加载
先后顺序。
1 2 3 4 5 ---10
1。同一个域名下。
拉去资源
<link rel="preload" href="xxxx.js" />
<link rel="prefetch" href="xxxx.js" />
2。不同域名下。
A,B,C
减少域名解析此时:dns缓存。
DNS预获取。
dns解析速度,被很多人忽视。蚊子腿也是肉。
预解析:
dns解析,多级递归查询。对时间是消耗,我们想办法节省时间。
我们在当前页面,完成对下一个页面域名的解析,而在下一个页面直接使用预解析之后的结果。
dns prefetching。
告知浏览器 打开域名的预解析
<meta http-equiv="x-dns-prefetch-control" content="on">
解析谁
<link rel="dns-prefetch" href="//www.baidu.com">
<meta http-equiv="x-dns-prefetch-control" content="off">
拉去资源
<link rel="preload" href="xxxx.png" />
<link rel="prefetch" href="xxxx.js" />
preload: 针对当前页面,更早的去下载资源,当前页面的资源。
音频,视频,embed,图片,js,css,
prefetch: 针对下一页,如果下个页面 存在比较大的资源,当前页面处理完,浏览器闲置的时候,
会去加载 该资源。
扩展:
图片->base64->放到 css文件里。
客户端数据库
一个用户1k,1000w个用户 10G。
cookie算一个:过期时间,坏处:
sqllite。
动静分离
媒体类网站:一篇新闻,
数据不仅包括 传统意义上的页面,也包括 没有和访问者相关的个性化数据。
缓存:
把静态数据 放到 离用户最近的地方。:浏览器,cdn,服务端的cache。
链接和数据做映射。url1 获得一个数据。key value。如果缓存到了 客户端,都不用发http请求了。
nginx,apache。
怎么做?
url唯一,做映射。
特殊展示的元素做分离:尽可能的多做静态化。
将页面中的cookie,与用户个性化相关的 东西 去掉。
架构方案:
静态服务器:nginx,apache
统一缓存管理服务:缓存做分发。
上CDN得了。
数据库查的 数据 + 样式文件 = html文件。
客户端优化 到此为止
用户在客户端中的优化。
网络分发
请求 从 客户端出来之后的优化。
DNS
目的:将域名解析成IP地址。
理解成:web服务,挂着一个 分布式数据库,并且提供了 crud功能。
记录类型:
A(Address):域名和IP的对应关系。
CName(Canonical Name):域名和域名的对应关系。
NS(name server):域名和 能解析此域名的域名服务器 的对应关系。
服务器类型
根域名服务器:13个。
A:主根,其他:辅根。2020年8月统计:1097个根域名服务器。
根服务器的镜像服务器:
域名解析流程
教科书:
LDNS。www.baidu.com
缓存
xxx.a.baidu.com hosts
浏览器
操作系统:hosts
LDNS:
a.baidu.com ns服务器
回答问题:
域名和域名的对应关系怎么理解?
xiaodoufu.com zhangdou.com
优化:
1。提前做好dns缓存。
2。A 记录,域名 对应 多个 Ip?结论:通过dns做负载均衡。
缺点:时效性问题。负载均衡算法 无法灵活使用。
CDN
结论:大型系统,部署多个节点。
请求多个节点如何做优化:
1。将请求分配到多个节点上,减少每个节点的并发数。
2。将请求落到离用户最近(地理位置最近,网络拓扑最近)的节点上。
cdn:放静态资源。
cdn两个关键节点:
源站:核心业务系统,所有信息的源头。
缓存(边缘)节点:静态资源。
流程:画图。
节点数目:
设计CDN
用户来源(如何识别,根据ip地址查询用户 地理信息)
就近分发()
1。www.mashibing.com: cname www.mashibing.com---xiaodoufu.com
if(地理信息 是否 是 北京的){
指向 北京
}else{
指向 杭州。
}
内容的缓存:
/xxx.html /xxx.png 静态 缓存到 cdn中。
做好映射:/xxx.html value:响应的值。
扩展:
数据来源:
1。启动时,初始化。内置好。
2。增量更新。有效期。
CDN总结
流程图OK
扩展一下(类似于:注册中心):
地址的获取:
内容的请求:
多地址直连
功能:将用户动态的请求 做分发。
用户、调用方。
cdn服务商,管理服务的通讯录。维护用户的cdn节点(源站 :提供动态内容)的列表。
cdn节点(真正提供服务的节点)。
方案:
注册中心:优化:客户端缓存。
规则中心
更简化的方法:将选择权 交个用户。
代理
请求到了确定的IP。IP不一定是真正提供服务的机器,只是他们对外提供的统一的IP。
正向代理
反向代理
识别用户的请求:
应用层 http ftp
表示层
会话层
传输层 tcp
网络层
数据链路层
物理层
4层反向代理:根据用户的ip和端口。
7层反向代理:根据用户协议,方法,头,正文参数,cookie。掌握更多的内容,更智能,效率低。
upstream:
access_by_lua_file.
负载均衡算法
轮询:RR。Round Robin。挨个发。适用于所有服务器硬件都相同的场景。一个一个来,
代码实现:
加权:WRR。Weight round robin。
代码实现:比如两个服务,一个权重是6 ,另一个权重是4。
1-10之间去 随机数。如果取到 1-6,那么 找6权重的服务。
如果取到 7-10,找 4权重的服务。
随机
random。
hash(原地址散列) Source Hashing
请求来的Ip 是 a, 我将a进行hash ,做成 对应到 1好 服务节点。
好处:便于session维护。
hash
最少链接 Least connecitons
将请求路由到 最少链接的服务器上。
代码实现:
redis存储结构:hash。 hset key field value
服务集群方案
并发和并行
并行:在某个时间点,多个任务进行。
并发:在某个时间点,只有一个任务进行。但是 在一个时间段,有多个任务同时进行。
集群。
集群缺点:
注意幂等。(幂等:每次操作都是一样的结果)
注意数据存储的共享。
杨通
弄一个数据共享的模块?
瞿菲
分布式事务吧
无状态节点集群
做集群的时候,不要修改服务内存的数据。
无状态:请求到达服务器,携带了服务端所需要的所有参数,服务端(服务的内存)不存储
所有跟请求相关的任何数据。map
有状态:在服务端存储之前的请求信息,用于后面请求的处理。
集群一般用无状态。确保无状态,必须保证所有接口都是恒等类,系统内存中存储的数据不能发生变化。可以
考虑通过 公共存储,实现无状态。
协作的问题:
定时任务,发短信。
锁:在程序执行的时候判断是否可以发?
外部唤醒:
内部和外部。
单一服务节点集群
选服?实时对战。长连接。
关键:实现用户和服务器对应关系的映射。
手动选择服务器
用户id分配服务器
解决了有状态的问题。
容错性差。
信息共享节点集群
多个服务共同连接:共享的存储。
协作:
缺点:受到共享存储的限制。存储容量,读写性能。故障的单点,瓶颈所在。
信息一致节点集群
读写分离。
分流。
存储之间:数据一致性问题。
强一致:
弱一致:最终一致
分布式系统
统一接口的定义。彼此当成黑盒。
微服务
总结:
一个服务---服务的分身(复制多份)----垂直切分。
如何实现的高并发:
高并发系统中的代码,就是我们普通的代码。
if else for
大量的机器,架构设计。
项目上线----加机器------优化架构------沉淀技术(中间件)----
课程后面加代码实践。
CAP
一致性。
越往上发展,设计和理论越显得重要。
是理解分布式系统的起点。
C 一致性,A 可用性,P 分区容错性,不可能同时满足,三者中选二挑一。
数据的一致性,从什么角度去看?
读、写。
P:分区容错性。
分区:
容错:
形成分区的原因只有网络故障这一种吗
网络的8大谬误:
1 网络总是可靠的:
2 没有延迟。
3 带宽无限
4 网络总是安全的。
5 网络拓扑不会改变。
6 只有一个管理员
7 传输代价为0:
8 网络是同构的。
P 必须保证。即使网络出现问题,我们的系统也要能正常使用。
三选二挑一。
P CA。
那P可以通过哪些方式保证呢?
数据被复制到其他节点上。提前把数据给你。mysql,redis:slaveOf ,zk。
为什么只能选 AP,CP?
一致性:写什么,就能读出什么。写:原子操作。
强一致性:写操作完成,后续的所有的读都能看到新数据。
弱一致性:写操作后,对该数据的读,可能是新值,也可能是旧值。
最终一致性:写后,读在一段时间内,可能读的是旧值,但是 最终,能读到新值。
可用性:向未崩溃的节点发请求,总能收到响应。有数据就行,管它对不对。
如何取舍?
看业务要求,或者说容忍度。
(中间件去聊)
AP:web缓存,dns,cdn。(大部分情况下)
不错的策略:
保证可用性和分区容错性,保证AP,兼顾C一致性(舍弃强一致性,保证最终一致性)。
电商:买东西 送积分。先买东西,积分次日到账。
红包,
如果保证强一致性,会对吞吐量造成负面影响。
A、B两系统,合起来完成一个业务。
A用10s,B用10s。一共 20s。10s。解耦。
信息一致性方案:
前面所有内容:服务和服务之间的并发。
服务内的并发
多进程
每个进程之间,资源独立,具有很强的隔离性。
java -jar xxxx.jar: 启动一个java进程。
两台物理机:a、b、c三个服务。
多线程
一个方法:先计算,然后 等待io,
出租车 计费:
时长计费(1min 多少钱),里程计费(1公里 多少钱)。
future。
目的:
1 提高效率。
2 实现异步。提前释放主线程。(降低了响应时间,节省了保持客户端和服务连接的资源)
线程数的计算
公式一:线程数=cpu核数 * cpu利用率 * (1+w/c)。
cpu利用率:0-1之间。
双核:0.4s, 0.6, = 50%。
算的时候,用100%。
线程数=cpu核数 * (1+w/c)。
w:等待时间,c:计算时间。wait/computer
2c cpu 2ms, 1ms == 2*(1+2)=6 个线程。
直观的结论:等待越久,线程数越高。
wc:
公式二:
线程数=cpu核数/(1-阻塞系数)。
阻塞系数:计算密集型:0,IO密集型:1。
统一公式:
cpu核数 * (1+w/c)=cpu核数/(1-阻塞系数)
阻塞系数= w/w+c。
实际以压测为准。
线程数,qps,机器配置。
cpu核数 * (1+w/c)
IO密集型和计算密集型的计算方式不一样吧老师
2 cpu核数。
计算密集型: cpu核数
压测为准。
缓存设计
分流:到达服务之前,减少服务处理的请求数。
并发:到达服务之后,提升服务处理的请求数。
缓存设计
导流:将原本复杂的操作请求(sql 大堆),引导到简单的请求上。前人栽树后人乘凉。
缓存:空间换时间的一个做法。
redis, memcached,localcache guava,客户端缓存,
user_info_xxxx : 姓名,年龄,xxx。getKey 内存操作
select * from user where id = xxx。 硬盘IO
缓存的收益
成本,收益。
读、写。
位置:介于 请求方和提供方之间。
收益:节省了响应时间。
成本:
kv
计算key的时间,查询key的时间,转换值的时间。命中率P。
所有数据的查询时间=计算key的时间+查询key的时间+转换值的时间+(1-p) * 原始查询时间
计算key的时间+查询key的时间+转换值的时间+(1-p) * 原始查询时间 <<<< 所有数据 的原始查询时间
适合:耗时特别长的查询(复杂sql),读多写少。
缓存键的设计
kv
单向函数:给定输入,很容易,很快能计算出结果,但是给你结果,很难计算出输入。
正向快速,逆向困难,输入敏感,冲突避免。
sha-256
冲突的概率 极低。
查询key的速度 取决于:物理位置 (内存,硬盘)。
值:
序列化
对象
总结:
无碰撞。高效生成。高效查询,高效转换。
上面所有:都被中间件提供的api 封装了。
实际中:前缀_业务关键信息_后缀。 公司统一制定规范。
user_order_xxxx:
user+order+xxxx:
user-order-xxxx:
$
缓存的更新机制
被动更新
调用方 暂存方(缓存) 数据提供方
被动:有效期到后,再次写入。
1。客户端 查数据,缓存中没有,从提供方获取,写入缓存(有一个过期时间t)。
2。在t内,所有的查询,都由缓存提供。所有的写,直接写数据库。
3。当 缓存数据 t 到点了,缓存 数据 变没有。后面的查询,回到了第1步。
适合:对数据准确性和实时性要求不高的场景。比如:商品 关注的人数。
主动更新
主动:被其他操作直接填充。
数据库:更新数据库
缓存:更新缓存,删除缓存
保持一个定量,考虑围绕它的变量,这样才不会有异常的遗漏。
更新缓存,更新数据库
数据不一致的风险比较高,所以一般不采用。
更新数据库,更新缓存
一般也不采用。
请求被阻塞,
业务要求:修改数据库,然后经过大量的计算,才能得出缓存的值。浪费了性能。如果缓存还没用,更浪费。
删除缓存,为了节省计算时间。
删除缓存,更新数据库
一般不采用,因为大概率 读比写快。
延时双删,休眠多久,系统吞吐量下降。
昨天被高德一个面试问:说,你这个延时双删有这么几步操作。如果其中某一步失败了这么办?
删除缓存
更新数据库:事务,回滚就OK。
第二次删除缓存
重试删除:当你前面的操作,无法回滚时,为了保证后续数据的一致性,
(最便宜的做法)硬着头皮往前走,重试。
借用中间件:消息队列,重发消息。
系统外订阅:canal。binlog。
二次删除key,和我们的业务代码解耦。
更新数据库,删除缓存
经常采用的方式。
cache-aside模式。
异常流程:
前提:缓存无数据。数据库有数据。
A:查询,B:更新
A查缓存,无数据,去读数据库,旧值。-----查
B更新数据库 新值
B删除缓存
A 将旧值写入缓存。
脏数据。
就是说这个方案也有问题?这次是读的速度慢了?
读比写慢 概率很低,极低。
缓存无数据。
如果非要解决,延时双删。再删除一次。
Read/Write Through
程序启动时,将数据库 的数据, 放到缓存中,不能等启动完成,再放缓存中。
Write Behind
降低了写操作的时间,提高了系统吞吐量。
双写一致性。
缓存清理机制
如何提升缓存命中率:尽可能多的缓存。所有数据都放缓存,命中率 100%。
我们需要用有限的缓存空间,发挥最大的作用。
如何判断 一个数据 在未来被访问的次数呢?
读的时间频繁:当清理一个数据的时候,发现,它一直被访问,那我就认为他 马上的未来,也会被访问。
写入时间的时间节点。
我是问代码怎么实现:当清理数据时,发现他一直被访问。
读一次,记录一次 ,时间。阈值。
读:
getKey, k =0 ttl 1min , incr
if(!getK > 1){
delete k
}
时效性清理
给缓存设置一个过期时间,到期 缓存 自动 清理。
缓存中的数据 有 一个 生存时间:ttl。过期时间。set k v ex 10 s
set cookie 过期时间。
k v 10s
定时任务轮询。delete
自动清理机制: cookie redis expire .。(本质:轮询)
数目阈值式清理机制
判断缓存中的缓存的数量 达到一定值 ,对缓存进行清理。
阈值:根据自己的业务来定。1g,1m,1024个, 800 80%。
采取什么策略去清理:
fifo: 先进先出
package com.example.cachetest;
import java.util.LinkedList;
import java.util.Queue;
/**
* 数据阈值式清理
*/
public class CacheThresholdTest {
public static void main(String[] args) {
Queue<String> queue = new LinkedList<>();
for (int i = 0; i < 4; i++) {
setCache(queue,""+i);
}
}
public static void setCache(Queue<String> queue,String cache){
int size = queue.size();
if (size >= 3){
queue.poll();
}
queue.add(cache);
System.out.println("缓存中的值如下:");
for (String q: queue) {
System.out.println(q);
}
}
}
random:随机
lru:规律:
LinkedHashMap 套。fifo,lru。
map:存 键值对。
顺序:插入顺序 fifo,访问顺序 lru。
removeEldestEntry。
package com.example.cachetest;
import org.junit.jupiter.api.Test;
import java.util.LinkedHashMap;
import java.util.Map;
public class TestCache {
@Test
public void testLinkedHashMap() {
// 在介绍accessOrder属性的时候说accessOrder设置为false时,按照插入顺序,设置为true时,按照访问顺序
LinkedHashMap<String, String> map = new LinkedHashMap<String, String>(5, 0.75F, true) {
@Override
protected boolean removeEldestEntry(Map.Entry<String, String> eldest) {
//当LinkHashMap的容量大于等于5的时候,再插入就移除旧的元素
return this.size() >= 5;
}
};
map.put("1", "bb");
map.put("2", "dd");
map.put("3", "ff");
map.put("4", "hh");
System.out.println("原始顺序:");
print(map);
map.get("2");
System.out.println("2 最近访问:");
print(map);
map.get("3");
System.out.println("3 最近访问:");
print(map);
map.put("5","oo");
System.out.println("加元素");
print(map);
}
void print(LinkedHashMap<String, String> source) {
source.keySet().iterator().forEachRemaining(System.out::println);
}
}
实现:k v。 map 一台服务器上能用。redis。
软引用清理
用空间换时间的模块。尽量用空间,用以提高缓存 命中率p。
适时的释放空间,gc。
识别出要清理的缓存,然后清除。
gc root引用。
强:哪怕自己oom,不清理。(不用)
软:当空间不足的时候,会被回收。√。
弱
虚
空间不足时,进行缓存清理。软引用。
把值 放到 SoftReference 包装中。
package com.example.cachetest;
import java.lang.ref.ReferenceQueue;
import java.lang.ref.SoftReference;
import java.util.*;
/**
* 软引用 缓存 实验
*/
public class CacheSoftReferenceTest {
public static void main(String[] args) throws InterruptedException {
soft();
}
static void soft(){
// 缓存
Map<Integer, SoftRefedStudent> map = new HashMap<Integer, SoftRefedStudent>();
ReferenceQueue<Student> queue = new ReferenceQueue<Student>();
int i = 0;
while (i < 10000000) {
Student p = new Student();
map.put(i, new SoftRefedStudent(i, p, queue));
//p = null;
SoftRefedStudent pollref = (SoftRefedStudent) queue.poll();
if (pollref != null) {//找出被软引用回收的对象
//以key为标志,从map中移除
System.out.println("回收"+pollref.key);
map.remove(pollref.key);
System.out.println(i+"新一轮================================================");
Iterator<Map.Entry<Integer, SoftRefedStudent>> iterator = map.entrySet().iterator();
while (iterator.hasNext()){
Map.Entry entry = iterator.next();
if ((int)entry.getKey() == pollref.key){
System.out.println("见鬼了");
}
}
System.out.println(i+"新一轮================================================");
}
i++;
}
System.out.println("done");
}
}
class Student{
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
class SoftRefedStudent extends SoftReference<Student> {
public int key;
// 第3个参数叫做ReferenceQueue,是用来存储封装的待回收Reference对象的
/**
* 当Student对象被回收后,SoftRefedStudent对象会被加入到queue中。
*/
public SoftRefedStudent(int key, Student referent, ReferenceQueue<Student> q) {
super(referent, q);
this.key = key;
}
}
缓存清理机制总结
时效式清理+数目阈值:防止:短期内,密集查询,导致缓存空间的急剧增大。
--自己的完整思路。
lru+软引用:保证热数据,最大限度的提高 缓存命中率,p。
不建议:仅仅使用 软引用。因为我们失去了对它的控制。
目的:提高缓存命中率,节省空间,=》提升性能。
缓存风险概述
在系统中,每增加一个环节,就多一份风险。用是不得已。
缓存穿透
缓存中没有,数据库也没有。
方案:在第一次调用的时候,数据提供方返回一个空值,将空值放到缓存中。
缓存雪崩
大量缓存突然失效,导致大量的请求,倾泻到数据库上,引起数据库压力骤增。
时效式清理:批量缓存,统一时间到期。缓存ttl=(固定时间,结合业务)+随机时间。
软引用清理:某个时间点,空间突然紧张,常用的缓存用强引用,不常用的用软引用。
缓存击穿
高频率的缓存,突然失效,大量请求倾泻到数据库上。
lru:
read write through or write behind.更新机制:无所谓。数据永远留在缓存当中。
缓存预热
read write through or write behind
预热:高频访问的,提前准备。
计价规则,提前加载到缓存中。
系统启动前:加载缓存,不让缓存统一时间过期。
电商系统:热门商品,提前加入缓存。网约车中,计价规则提前加入缓存。
热门数据,加到缓存。
缓存风险的总结
遇到风险,分析原因,解决之。
原因:更新机制,清理机制。
缓存的位置
缓存来源:L1 L2 L3。
缓存的读取过程:
思考:如何避免cpu浪费时间。
减少我的等待时间----缓存。
我尽量多做事情-----多线程。
目的:降本增效。
级联系统缓存位置
要想系统性能好,缓存一定要趁早。
客户端缓存位置
1
2 秒杀系统,商品详情页就是静态文件(扣一块动态的)。
降级。
代码:storage。
浏览器:cookie。失效时间。如果非必要,不要用cookie做缓存。
静态缓存
1。静态页面。apache。录个视频,apache静态页。
2。通过数据库查出来的。
如果每个用户查出来的都一样。 物流信息:省市区。
凡是与用户个体无关的具有较强通用性的数据,都可以作为静态数据缓存。
已经有缓存页面,后台更改数据之后,如何让数据快速生效。cache aside。
不适合缓存通用性很差的数据。
服务缓存
个性化的动态的不值得缓存。但是 这些数据的生成 都有一个过程。
数据库本身的缓存
aside。
数据库耗时比较久。
怎么做?
冗余字段。订单表里 id,有用户姓名,商品名称。
中间表:学生表,课程表,排课表。
查询缓存:建议不用。mysql8以上,抛弃了。query cache.
select * from user_info
SELECT * from user_info.
指定规范,大小写该统一就统一。my.ini my.cnf。
清理碎片,flush query cache., reset query cache.
历史表:将数据放到 历史表中,以后的操作比如说 统计,可以延迟操作。而中间的数据存储 ,相当于一次缓存。
coder学员:新老数据,还在一起,统计数据剥离。
写缓存
目的:削峰。
数据处理方的 处理速率是固定的 ,为了 防止请求 洪峰 压垮系统。采用写缓存。
写缓存收益
只要能给数据进行更改的操作,都叫写。
数据处理方时间。10s
引入缓存后:写缓存时间 2s,从缓存读取数据的时间,传递时间,数据处理方时间。
收益在于:用户。-8s。减少了用户响应时间,提升了系统吞吐量。
读缓存和写缓存:
读缓存:用缓存的命中率,替换数据提供方的操作。能减少用户的请求时间,能减少系统的总处理时间。
写缓存:花费额外的时间。来延迟数据处理方的操作,减少用户的等待。只能减少请求响应的时间,反而会增加系统的总处理时间。
是。
1s 0.1s(1s) 10倍。
i like u(you)
4(for) u
2(to) B
log4j log for java
C#。
day day up:
cache aside。更新完数据库,删除缓存。 迁移到: 修改完页面,删除静态页。io.write("d:/apache/www/x.html")
写缓存实践
利用redis 发布订阅。
MQ
数据库。(先写数据,剩下的和主业务无关的操作,后置)
目的:只要能减少用户的响应时间。就OK。
适合场景:请求峰谷值变化明显、对实时性要求不高的场景。
缓存总结
数据库设计
数据库优化的理由
收益:阿姆达尔定理
数据库单点压力:
积累压力:
数据库设计
1。先设计数据表的关系,再推导使用对象。
2。反之。
设计别扭的时候。1-2,3-2。
数据冗余:
数据不一致:
插入异常:删除异常。
数据库范式。等级越高、越严格。
反范式,建议 在范式的基础上进行修正,减少范式带来的负面影响。
第一范式:每个字段都是原子的,不能再拆分。
反例:json。先看设计是否合理,再选合适的存储组件。
第二范式:必须有主键(可以是一个,或 多个字段),非主属性,必须依赖于主键。
反例:好友关系列表。主键:关注人id,被关注人Id,关注人头像。
第三范式:没有传递依赖,非主属性直接依赖于主键,而不能间接依赖于主键。
反例:员工表:员工id。部门id,部门名称。部门简介。
反范式:字段冗余。
如果你的系统是重业务的系统,对性能和并发的要求不高,最好用第三方范式。
如果系统对某些查询较频繁,可以考虑冗余,反范式。
巨量数据的优化
数据量增加---》响应时间的增加。
常用的方法:建索引。mysql性能调优。
表分区->分库分表->读写分离
表分区
表。每个表对应磁盘上的一个文件。ibd。data目录下
分流:对一个ibd文件的请求,分发到对多个ibd文件的请求。
将数据 多个物理表进行存储,逻辑上,还是一张表。
好处:
1。 当查询条件 可以判定 某个数据位于哪个分区,那么直接在分区中查询,不用扫描整个表。
2。业务代码不用改。
3。分区进行单独管。备份,恢复。
range。0-10,11-20。
partition by range
list: partition by list xxxxxxxxxxx values in (1,2)
hash:partion by hash
key
做分区的注意事项:
1。 做分区时,要结合查询规则。尽量保证常用查询落到一个分区中。
举例:大数据量: 学生姓名,老师姓名。如果以学生姓名作为条件查询较多。以学生姓名分区。
2。分区条件放到where语句中。比如上面的学生姓名。
坏处:如果出现跨区查询,适得其反。
分库分表
目的:
1。业务拆分。
2。通过分库分表应对高并发。需要看场景:读多写少(从库,缓存)?读少写多?
3。数据隔离。将核心业务和非核心业务进行拆分。
分库分表的设计
一个库里有两张表a,b。
如何拆?
1。不破坏表。a放一个库,b放一个库。
2。破坏表。垂直分 和 水平分
垂直分:
字段1,字段2,字段3,字段4。
数据条数不变,字段数变少。
场景:
水平分:
字段1,字段2,字段3,字段4。用户表:性别,年龄,姓名,介绍。
1
2
3
4
婚恋。
额外的操作:
路由操作:
拼接操作:
开发中:遇到问题,先用简单办法解决,解决不了,再复杂。
分库分表的方法
范围路由:选取 有序的列,按照一定的范围去划分。
分段小:导致子表数量多,增加维护难度,分段大:有可能,单表依然存在性能问题。
分的依据:分表后,表的各方面性能,能否满足系统要求。
优点:可以平滑的扩充新表,只需增加子表的数据量,原有的数据不用动。
缺点:数据分布不均匀。
hash路由:选取 列 ,进行hash运算。 %10 = 。
优点:相反,
缺点:相反。
10, 11 --1 。
11,11--0
分库分表的问题
分布式id的问题:
需要 全局id生成服务。
注意点:全局唯一(时间戳,机器号,序列号);高性能;高可用;易使用,好接入;
uuid,数据库自增,号段,redis自增,雪花算法,TinyID,UIDGenerator。leaf。
有独立的课。
拆分维度的问题:电商系统-订单表:,用户id,订单id,商品id。
依据:自己业务的情况。看那个字段用的多?
索引表、映射表:(过渡方案)
dts,datax:增量同步。
join问题:
商品、订单、用户。单库join没问题,多库join失败。
1。在代码层面做join。
2。es。canal --》es。
目前:数据库越简单越好。 禁止3张表 做关联,禁用存储过程,禁用触发器。
事务事务:
XA,jar包。不好用。shardingsphere.
成本问题:
非必要 不分库。不要过度设计。
1亿 1张表,10ms。100w1张表 1min。
读写分离
1个库。
2年后:10个库。
4年后:又慢了。
10个库里的每一个 做 读写分离。(前提)
分流:
数据库锁(分)对数据库并发有影响。
X锁-写锁,只能我一人,读、写 干不了。
S锁-读锁,
场景:读多写少。不适用:读少写多(反而用途不大)。
防止阻塞。
一主(写)多从(读)
路由问题:select S 锁 从库 ; create update delete add. X 锁 写库。 mybatis插件。
主从复制的问题:
1 写主库,如何 高效 同步到从库。
从库用sql命令写,会失去读写分离的意义。因为 回到了从前。
主库:binlog , 传给从库,写入从库:的relayLog,解析relaylog。重现数据。
base:
2 会有时间差。
(一)
编造业务场景:注册(主库),登录(查 从库)。
将注册后的第一次 查询 ,指到 主库上。
比如说:注册完,写个redis,key 用户id 1。删掉key。
和业务耦合大。
lich:我是先从库查,返回空后,再查一次主库,如果没有的话,那就真的没有了。-- 个别业务用。
(二)
主业务用主库,非主业务用从库。
用户系统,注册登录,都走主库, 用户介绍、xxx 走从库。
实现
分库分表,读写分离。
读写分离:将读和写,分开。
分库分表:将 数据 分库。
分-
分配机制-
将不同的sql 分发到不同的机器上。
select ----某台机器上
update --某台机器上。
where id = 1 某台机器上
where id = 2 某台机器上。
拦截,判断,分发。
代码封装:dao抽象一层。夹层。tddl(Taobao Distributed Data Layer) 头都大了。
Shardingjdbc。需要改代码。
中间件封装:mycat。
应用保护
系统压力太大,负载过高。
数据库慢查询,
核心思想:优先保证核心业务,优先保证大部分用户。
降级
论坛:
思想:丢车保帅。保证核心业务可用。
1。系统提供后门接口。
2。独立降级系统。对1封装。redis。
if(ifxxList){
getXXList();
}else{
getXXlis备用();
}
前提:代码提前规划好。
自动开关降级
提起写好降级逻辑。
触发降级的条件:
1。超时。阈值。
2。异常。 阈值。 1001 运行时异常。
3。限流。排队页面,卖光了。
降级手段:
减少不必要的操作,保留核心业务功能。
停止读数据库,准确结果转为近似结果。静态结果(猜你喜欢),同步转异步(写多读少)。功能裁剪(推荐干掉)。禁止写(高峰期减少不必要的写)。分用户降级。工作量证明 POW(验证码,数学题,拼图题等,滑块)。
熔断
A服务:X功能(熔断 )--B T。
阈值怎么定?5次/1s--3次,先预估,上线观察,最后调优。
保险丝。
熔断策略:
根据请求的失败率:熔断开关 打开。过一个时间窗口(10s),熔断开关关闭。开关再打开。--半开。Fail Fast。
hystrix:yml。每20个请求,当失败率50%,打开开关,等过5s,开关关闭。
根据响应时间:sentinel。时间阈值,超过 熔断开关打开。
限流
外部(请求太多了)、内部(资源)。
基于请求的限流
请求的总量。
直播间超过100人,出去。
限制时间量。
一个时间窗口内:接100个请求。
上线观察、调优。
1s 1万人。结果 5k人就扛不住了。
提前压测。
排队:缓冲。MQ,长连接给用户响应。
基于资源的限流
连接数,线程数,请求队列。cpu参数。
难点:确定关键资源,阈值。
池化技术:连接数,线程池。
队列大小:请求队列。10个。
cpu参数:perl。
tomcat:
acceptCount: 如果tomca线程池满了,
maxConnections:最大链接数。
maxThread:
固定时间窗口
滑动时间窗口
突刺。
漏桶算法:
漏桶的队列长度。
漏桶里有请求等着处理,但是我的出口,确实处理不了。
一个是浪费。
O(1)。
令牌桶算法
漏桶和令牌桶
漏桶:限制平滑的流入:
令牌桶:可以容忍部分突刺。
节流
去抖。 减少网络的请求呢?
定义一个时间窗口。1s 开源。
前置:a记录的转发,cdn。缓存扛不住) 限流。
请求来-中间环节--处理完。
(应用保护)
序列化(字节流),对象。
隔离
数据隔离:数据重要性排序。分库。
机器隔离:给重要的用户单独配置服务器。用户的标识去路由。
线程池隔离:线程池分配。hystrix。
信号量隔离:计数器。hystrix。
集群隔离:服务分组(注册中心),秒杀。(单独分出一组服务给 核心业务)
机房隔离:3个服务。局域网ip、路由。
读写隔离:主从。create update delete \ select (数据延迟,前面的课里讲过)
动静隔离:识别动静态数据,进行隔离。nginx,apache。
爬虫隔离:openrestry user-agent。 对ip的访问频率。
冷热隔离:秒杀,抢购。读:缓存。写:缓存+队列。
恢复
撤出限流,消除降级,关闭熔断。
半开关。
让吞吐量爬升。缓存预热。
1。类实例创建,反射调用创建实例。
2。缓存数据预热。
灰度发布。限流逐步提升:阈值。用户打标签(18以下用户10个,18以上 1万人。)
异地多活
异地
多活(不是备份)
1。请求某一个节点,都能正常响应。
2。某些系统故障,用户访问其他系统也能正常。
分类:
同城异区,跨城异地,跨国异地(隔离)
跨城异地:质变:RTT。Round Trip Time 50ms。京广。 京沪:30ms。 数据不一致。
跨国异地:延迟,已经无法让系统提供正常服务。
负载均衡。---dns cdn。分流。
数据不一致问题:
1。保证核心业务多活。
用户系统:注册,登录,修改用户信息。 广州 北京。
注册:
登录:
修改用户信息:根据时间合并。分布式ID。
1000万用户。每天注册 几万个。修改用户信息的呢 几千个。 1000w登录。
基于已有的数据。上天总是公平的。
2。保证核心数据最终一致性。
自建网络。国字头。
session数据。token。(量大,同步不值得。)
同步手段:
中间件的主从复制。mysql ,redis。
消息队列:订阅发布。
二次读取:
回源读取:
重新生成:
保证大部分用户:小部分用户忍。
异地多活设计步骤:
1。业务分级。
微信聊天和朋友圈。
广告收入。新闻网站。
公司、用户影响。
2。数据分类。
唯一性:手机号。额外存储。crud。
实时性:
可丢失性:session
可恢复性:session可恢复的?
3。 数据同步。
4。异常处理。
多通道同步:mysql主从复制+消息队列。两种方式走不同的网络。
同步和访问结合:
广州,北京。
A用户登录广州,生成 session,sessionID(带有广州气息的sessionID xxxxx1)。
session不同步给北京。
A访问北京的服务器:参数 sessionID(带有广州气息的sessionID xxxxx1)。
if(endWith(1)){
String session = http.调用(拿对应用户的session);
sesson.set(K,V);
}
javaer。
j2cache,nginx+lua
OVER!!!
方案性东西。找我讨论。
从0到1 的代码课,商城。
重试,持久化,重发。
迭代。
代码量不够:
system.out.println("hello world")。
本文来自博客园,作者:孙龙-程序员,转载请注明原文链接:https://www.cnblogs.com/sunlong88/p/17473002.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号