
elasticsearch--相关度评分算法
- 相关度评分
- TF-IDF算法
- BM25算法
- SHARD LOCAL IDF
- Relevance Score
- 精准控制频分和干预排序
1、相关度评分:score
1.1 相关度
31.1.1 相关性概念
相关性指的是召回结果和用户搜索关键词的匹配程度,也就是和用户搜索的预期值的匹配程度,
1.1.2 搜索和检索
搜索和检索的区别在于查询条件边界的界定上面
搜索:有明确的搜索边界条件,结果数量是确定的。如eq、lte、gte 均属于搜索行为
检索:讲究相关度、没有明确的查询条件边界。比如搜索召回的结果有可能是因为拼音、谐音、热梗、别名、同义词等等而被匹配,但不同原因匹配到的结果权重不同。
1.2相关度评分
相关度评分用于对搜索结果排序,评分越高则认为其结果和搜索的预期值相关度越高,即越符合搜索预期值。在7x之前相关度评分默认使用TF/IDF算法计算而来,7.x之后默认为BM25.
默认情况下,Elasticsearch 按相关性分数对匹配的搜索结果进行排序,相关性分数衡量每个文档与查询的匹配程度。
相关性分数是一个正浮点数,在响应上下文对象中_score元数据字段中返回。分数越高,文档越相关。虽然每种查询类型可以不同地计算相关性分数,但分数计算还取决于查询子句是在查询还是过滤上下文中运行
1.3 基本排序规则
如果没有指定排序字段,则默认按照评分高低排序,相关度评分为搜索结果的排序依据,默认情况下评分越高则结果越靠前。
1.4基本评分规则
以下是Lucene 中定义的 TermFreq (词频)和Inverse Doc Frequency (文档频率)的源代码

1.4.1 词频(TF term frequency )
也叫检索词频率,关键词在每个doc中当前字段出现的次数,词频越高,评分越高。比如字段中出现过 5 次要比只出现过
1次的相关性高


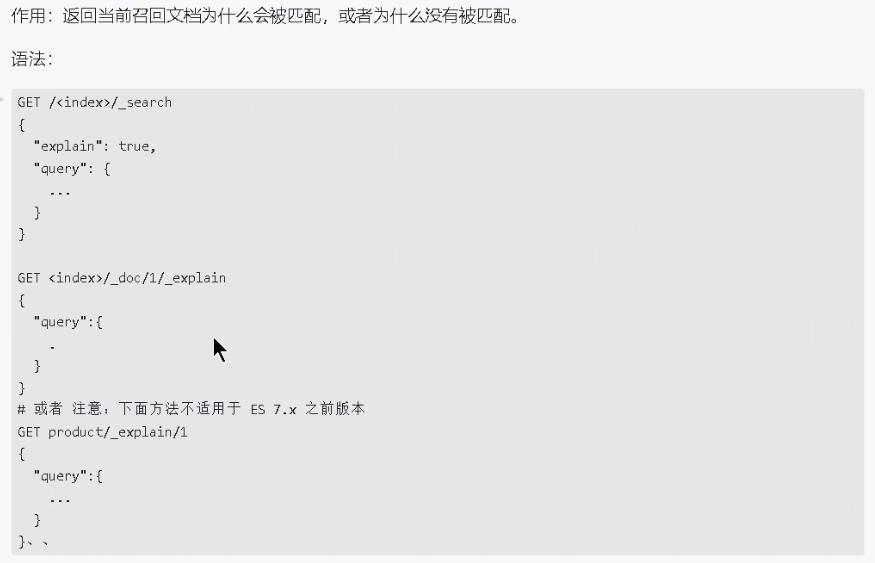
1.4.2 反词频或文档频率(IDF inverse doc frequency)
关键词在整个索引中出现的次数,反词频越高,权重越低,评分越低
计算公式:idf(t) = 1 +log( numDocs / (docFreq + 1)) // 的逆文频率( idf )是:索引中文档数量除以所有包含该词的文档数,然后求其对数。示例:

1.4.3 文档长度规约 (field-length norm)
字段长度越短,字段搜索权重越高,相关度评分越高。比如:检索河出现在一个短的 title 要比同样的词出现在个长的 content字段权重更大
计算公式:
norm(d) = 1 / VnumTerms
//字段长度归一值 ( norm )是字段中词数平方根的倒数。
示例:

IF-IDF算法
Similarity
Classic :也就是 TF/IDF,在7.x 中已弃用,在7.x 之前是Elasticsearch 和Lucene 中的默认算法
BM25: Okapi BM25算法,在7.x 之后为 Elasticsearch 和Lucene中默认使用的算法
Boolean:一个简单的布尔相似度,当不需要全文排序并目分数应该只基于查询词是否匹配时使用。布尔相似性给术语的分数等于它们的查询提升
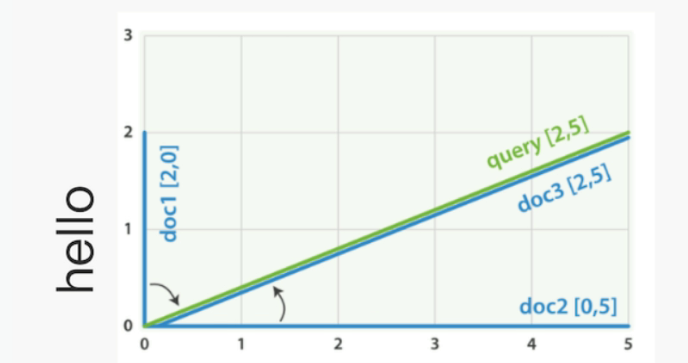
2.2 空间向量模型(vector space model)
向量空间模型(vector space model) 提供一种比较多查询的方式,单个评分代表文档与查询的匹配程度,为了做到这点,这个模型将文栏和查询都以向量 (vectors) 的形式表示
向量实际上就是包含多个数的一维数组,例如:[1,2,52238
向量空间模型里的每个数字都代表一个词的权重

评分算法函数



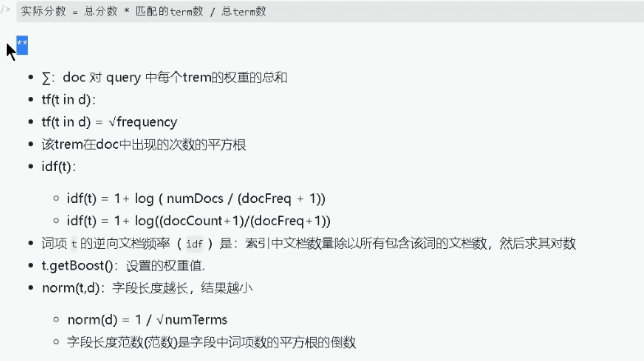
2.4 Explain api
BM25算法
为什么要使用bm25?
- 更任性的相关性曲线
- 词频相关性可控性更好
尽管 TF/IDF 是向量空间模型计算词权重的默认方式,但不是唯一方式。Elasticsearch 还有其他模型如 Okapi.BM25 。TF/IDF 是默认的因为它是个经检验过的简单又高效的算法,可以提供高质量的搜索结果
3.1 引言
BM25 (全称:Okapi BM25)BM 指的 Best Matching 的缩写 是搜索引擎常用的一种相关度评分函数。且和 TF/IDF一样,BM25 也是基于淘频和文档频率和文档长度相关性来计算相关度,但是规则有所不同,文章中将会给出详细讲解。
BM25 也被认为 ctrl目前最先进的 评分算法
文档: https://en.wikipedia.org/wiki/Okapi BM25
3.2 相关度概率模型
BM25 是一个 bag-of-words 检索功能,它根据每个文档中出现的查询词对一组文档进行排名,而不管它们在文档中的接近程度如何。它是一系列评分函数,其组件和参数略有不同。
概率相关模型是通过预估文档d;与查询 相关的概率的理论模型。该模型假设这种相关概率取决于查询和文档表示。此外,它假设所有文档中有一部分是用户首选的作为查询g的答案集。这样一个理想的答案集称为R并且应该最大化与该用户相关的整体概率。预测是这个集合R中的文档与查询相关,而集合中不存在的文档是不相关的。
文档: https://en.wikipedia.org/wiki/Probabilistic relevance mode




相关性曲线
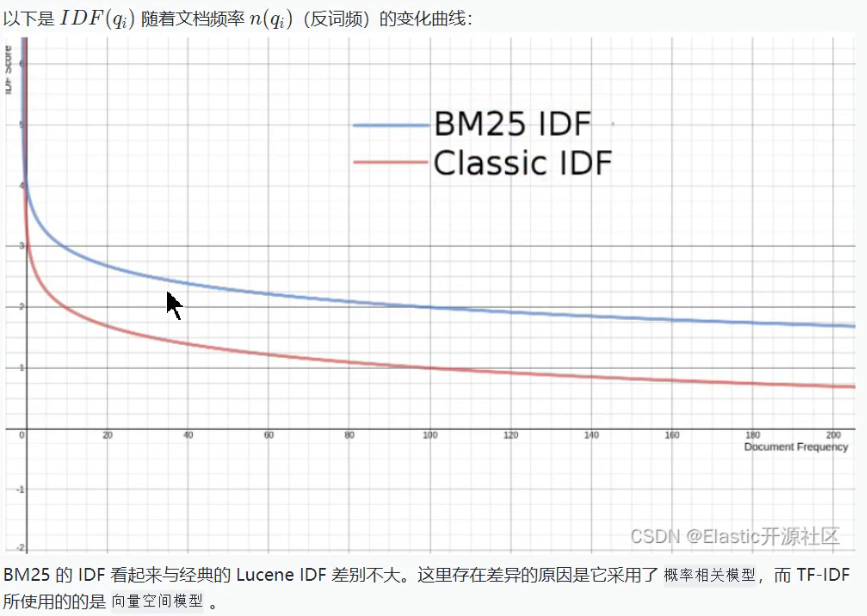
在TF-IDF 算法中,coord(g,d)可以对匹配到的词项提供加成,文档中出现的次数越多,加成越多,这个关系是个线性函数。
但是,如果同一人 doc 中,出现了 1000 次某个相同的词项,比如 id = 1的文档的 title 字段为: “苹果-苹果·..-苹果” (共 1000 次苹果),而 id = 2 的文档的 title 字段为: “苹果-苹果-·..-苹果” (共 100 次果)。那么对于词项“苹果”,文档1的相关性应该是文档2的十倍吗?
显然不是,对于文档一和文档二,这两个文档对苹果这个词项的相关性应该是非常接近的,换句话说,当文档中出现了一个词项的时候,后面再次出现相同词项,对当前文档的相关性虽然应该有提升,但是提升幅度应该逐渐下降。当词频足够多或者说达到某个闻值的时候,再增加词频对于相关度的提升应该无限趋近于0。
降低TF 的增益权重的常用手段是对其取平方根,但是这仍然是一个无穷大函数,所以就需要设置一个闻值来限制 TF 的最大值。而i 就是控制因子。

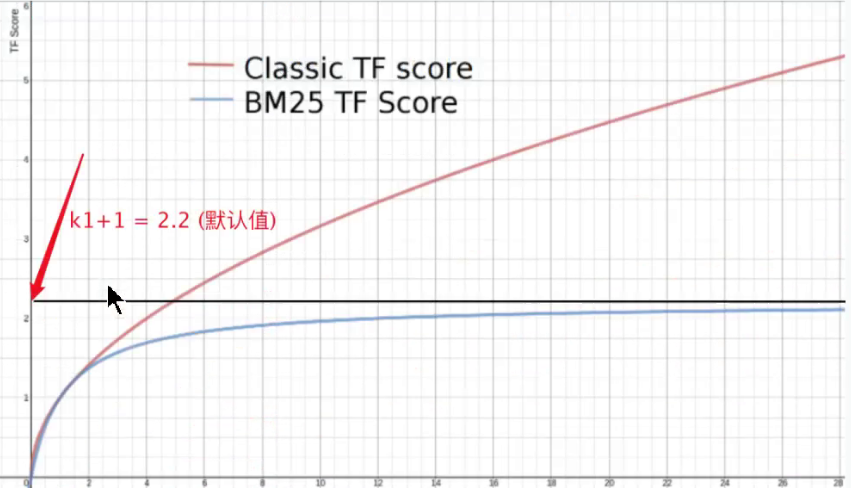
BM25降低了TF的对评分增益率
非常直观的可以看到,这条曲线随着词频的不断增大,无限地趋近于(k + 1)(默认 = 1.2)
K1值的作用
我们可以人为的通过设置 k 的值来控制最大 TF 得分。更重要的一点是增加 k 的值可以延迟 TF 达到最大值的速度,通过拉伸这个临界值,可以来调节较高和较低词频之间的差异相关性。

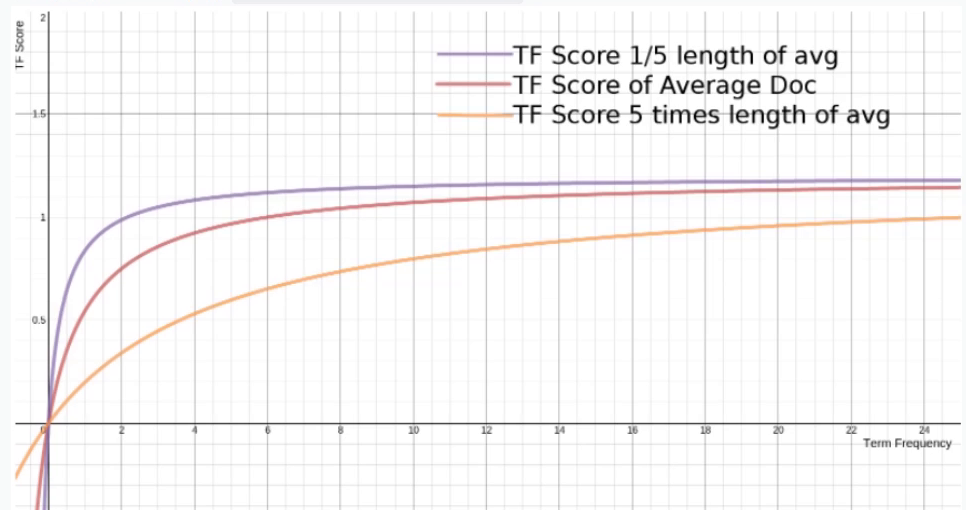
下图是不同 L下,S(qi,D)随着词频的变化曲线


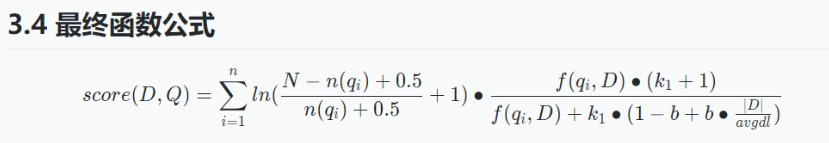
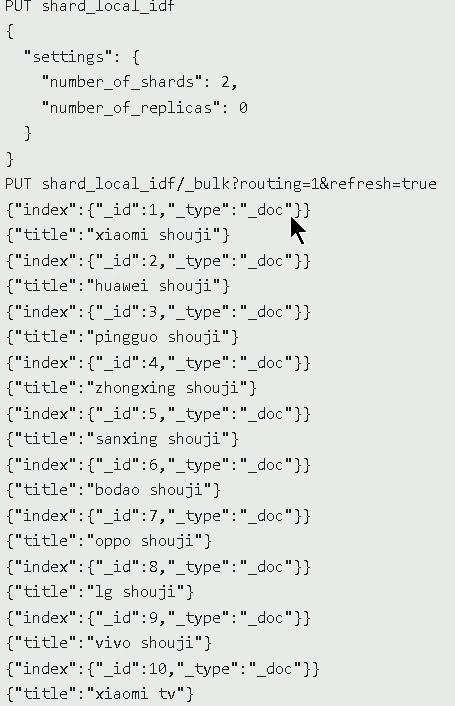
----SHard Local IDF-------
数据:
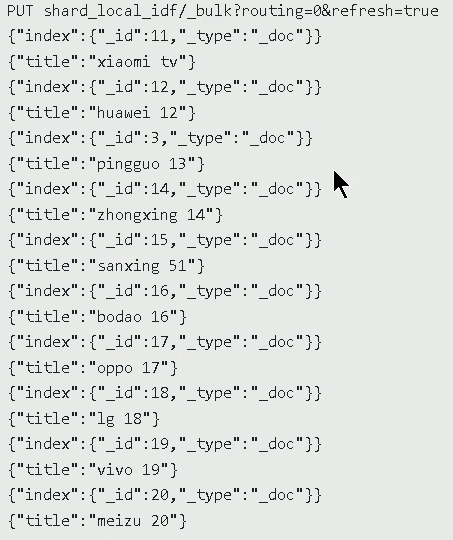
--查询结果:不是我们想要的--
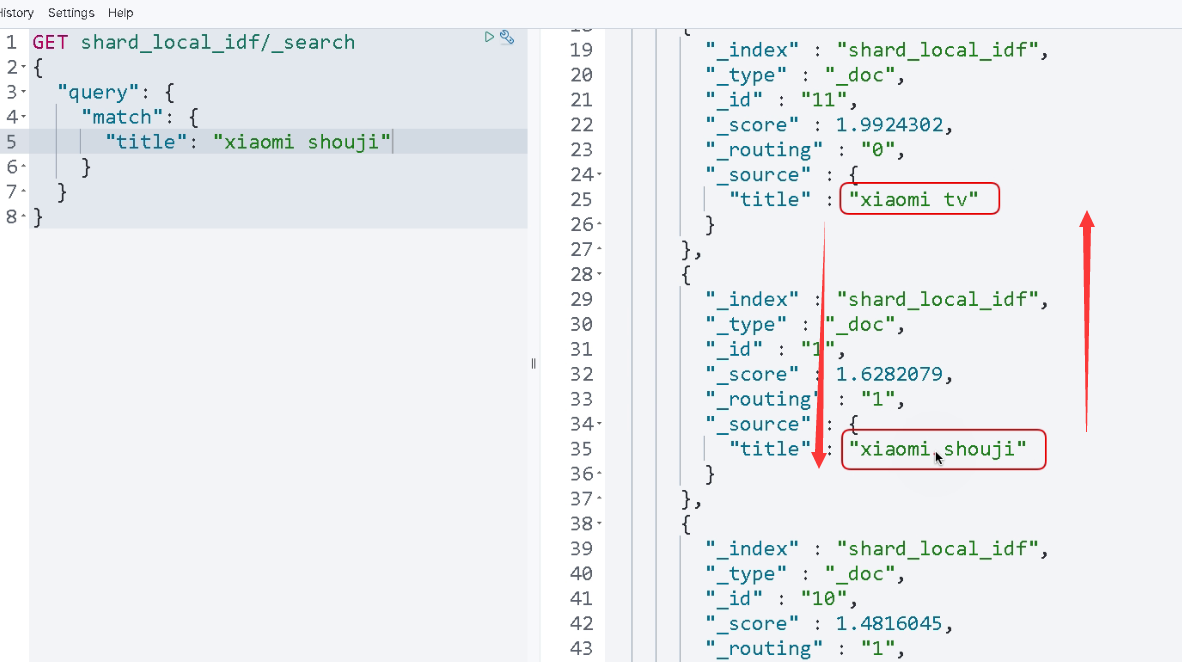

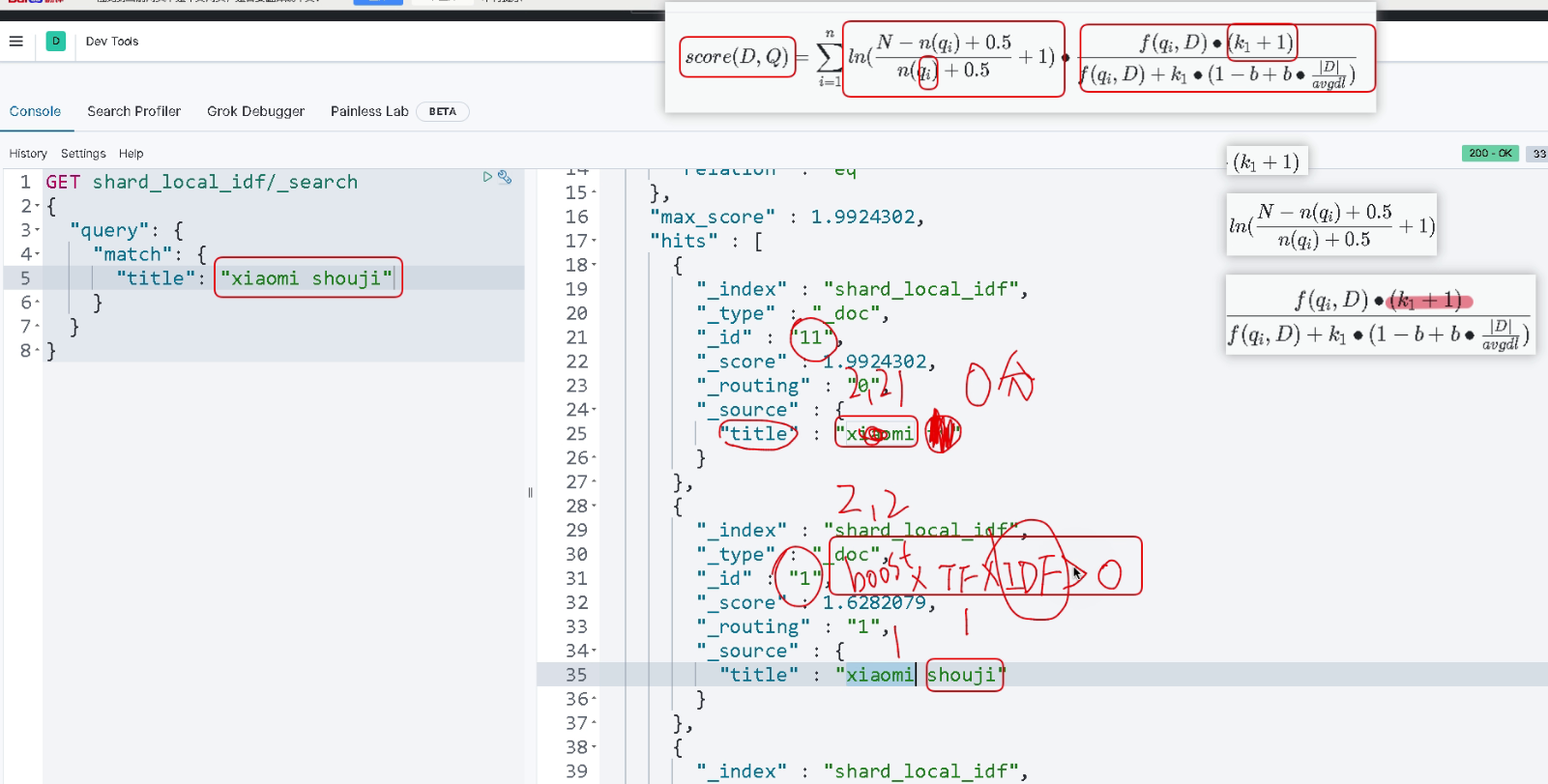
通过explain分析计算以下得分,如下
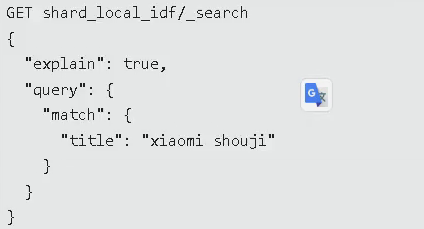
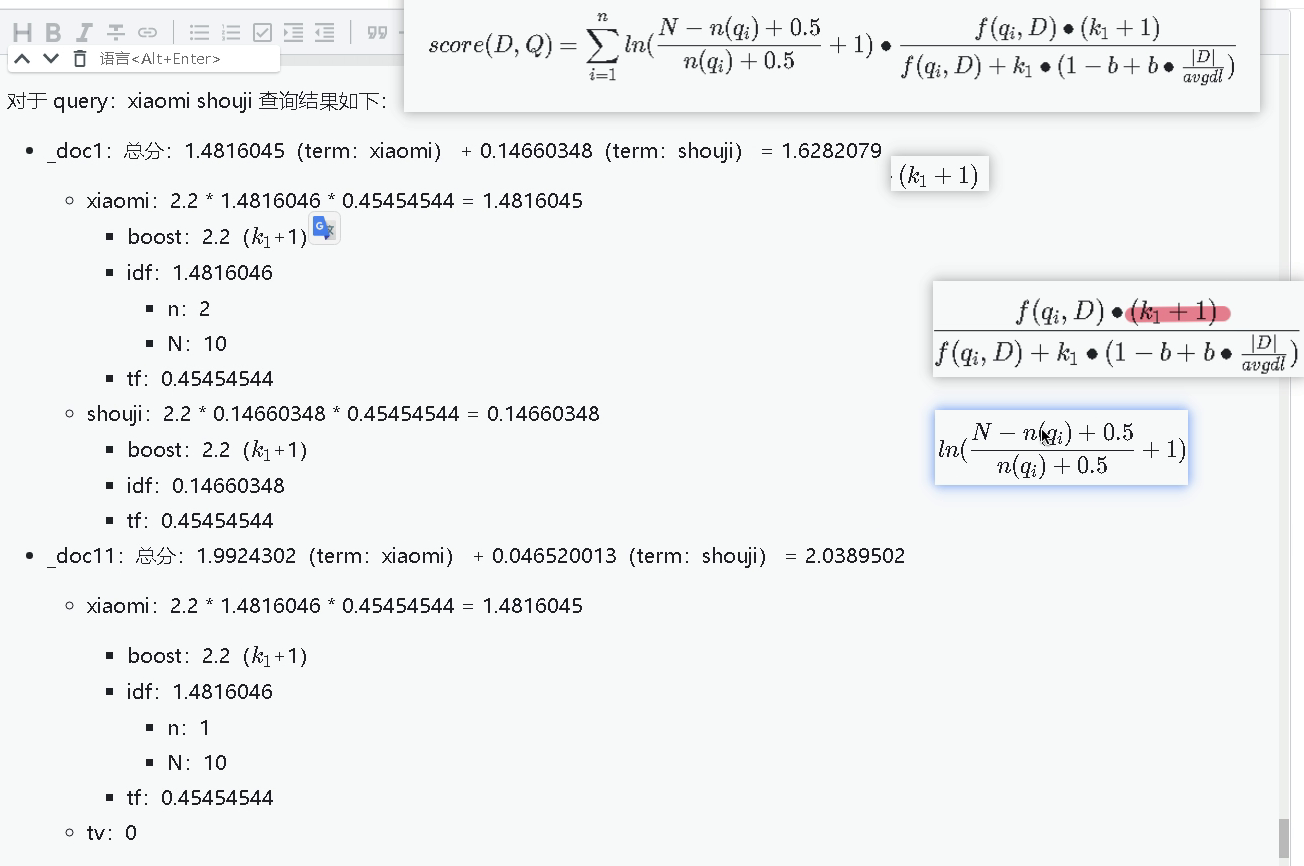
4.4解决方案
4.4.1开发和灰度环境或数据量不大的情况
search_type
dfs_query_then_fetch: 使用从运行搜索的所有分片收集的信息,全局计算分布式词频。虽然此选项提高了评分的准确性,但它增加了每个分片的往返行程,这可能会导致搜索速度变慢。
query_then_fetch: (默认)为每个运行搜索的分片本地计算分布式词频。我们建议使用此选项进行更快的搜索,但评分可能不太准确。
测试环境设置:search_ype = dfs query_then_fetch 即表示在计算df的分值的时候,对全局进行计算,而不是local shard 。会牺牲一部分性能,换取准确性。这种方式适合于本地开发环境或者测试环境,或者生产环境中数据不对的情况下。
4.4.2对千生产环境
对于生产环境,一般分布式数据库数据都不会太少,既然设计了多个分片,必然要考虑海量数据的情况。一般来说用 query_then_fetch 不太合适,会影响检索速度,牺牲用户体验。
生产环境真正的做法是避免分片不均衡,包括分片的大小、节点分片的分配数量、文档的均衡分配等。ES 本身通过shard reblance 实现分片自动均衡策略,但是如果人工通过 routing 的方式分配数据,务必要保证数据按照某种机制,如分布式哈希表来控制数据的均衡分配,以避免这种情况的产生。总结:在不了解分布式文档路由原理的前提下,不要随意使用 routing 来指定文档的分配机制。以免挖坑。
总结:在不了解分布式文档路由原理的前提下,不要随意使用routing 来指定文档的分配机制。以免挖坑。

控制评分的常见方法
- boost
- boosting query
- function score
- constant score
- disjunction max query
Boost 增加搜索条件权重
mapping设置

查询设置

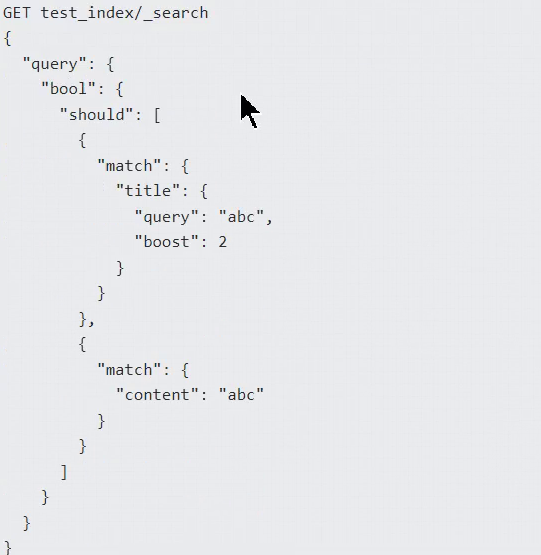
此方式仅适用于 term query 不适用于 prefix,range 和 fuzzy queries
总结
- 不推荐在索引时定义权重,因为如果不重建索引,无法修改器设置的索引时权重值.
- 定义索时权重会影响评分结果的计算。
5.2 boosting query
有些时候,我们需要将某些搜索结果降级,但又不想完全从搜索结果中剔除它们。在这种情况下,可以对其降低权重,可以使用 boosting query
例如: 下面搜索表示从 title 匹配 abc efg 的搜索结果中,对 content 包含 456 的结果权重降低为原来的 0.1倍

- positive: 必须满足的查询条件(必需,查询对象)
- negative (必填,查询对象) : 需要降低评分权重的过滤器
- negative_boost (必填,float): 权重降低因子,值设置多少,negative 中匹配的文档权重就是原来的多少倍
5.3 function_score
和 boosting query 相反,有些时候希望提升某些查询的权重,就需要用到 function_score
如:以下查询表示,title 中匹配

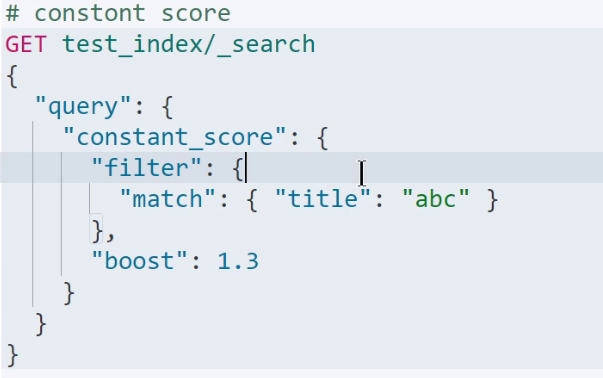
5.4constant score
如果需要直接指定某些查询结果的评分为具体数值而不是设置其权重,可通过 constant score 来实现
如: 以下代码表示 title 字段中匹配 abc 的结果,其评分值为 1.3
5.5 disjunction max query
这个在多字段检索课程中详细介绍过,此处不再赘述
也可参阅老师的博客: ES中的Multi match深入解读一文中关于 best fields 策略的详细讲解。

本文来自博客园,作者:孙龙-程序员,转载请注明原文链接:https://www.cnblogs.com/sunlong88/p/17399623.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号