
聚合查询:Aggregations
- 分桶聚合:Bucket agregations
- 指标聚合:Metrics agregations
- 管道聚合:Pipeline agregations
分桶聚合:Bucket agregations
指标聚合:Metrics agregations

管道聚合:Pipeline agregations
- 概念:对聚合的结果二次聚合
- 分类:父级和兄弟级
- 语法:buckets_path
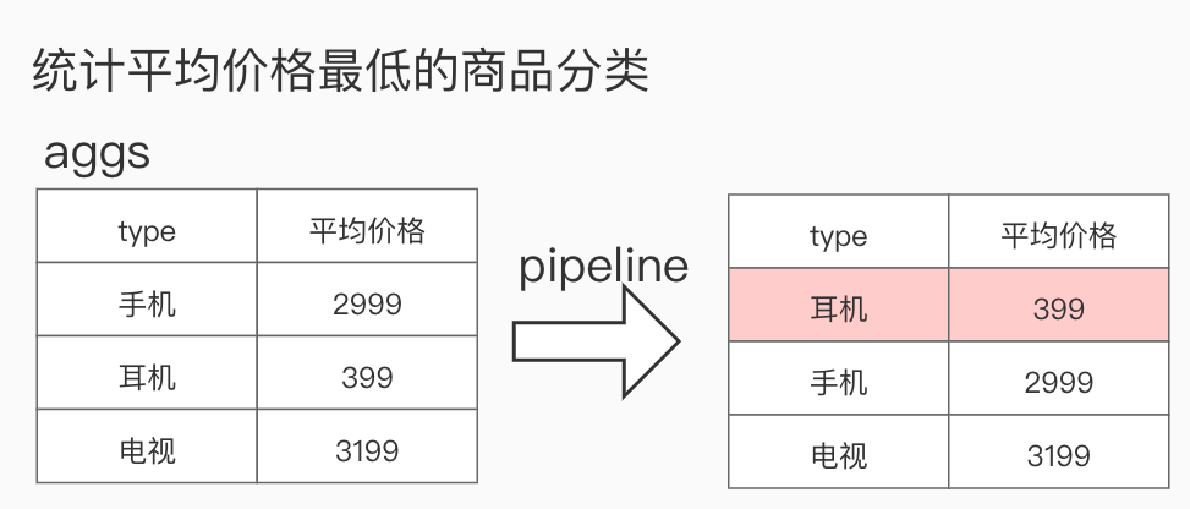
语法学习:
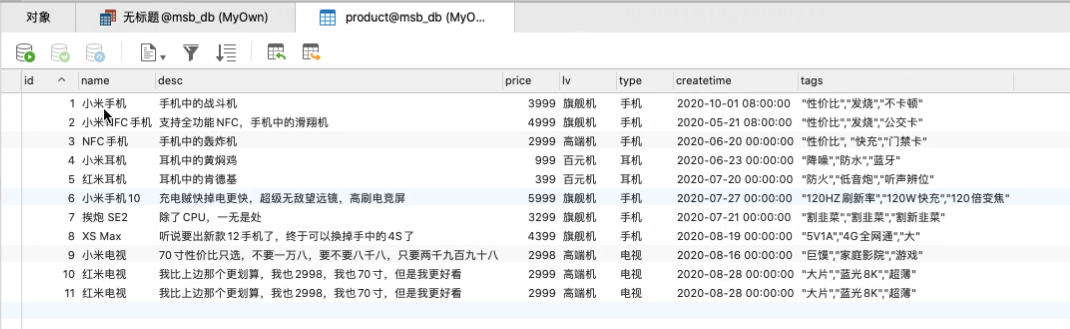
数据准备:
# 聚合查询 DELETE product ## 数据 PUT product { "mappings" : { "properties" : { "createtime" : { "type" : "date" }, "date" : { "type" : "date" }, "desc" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } }, "analyzer":"ik_max_word" }, "lv" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "name" : { "type" : "text", "analyzer":"ik_max_word", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "price" : { "type" : "long" }, "tags" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "type" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } } } } } PUT /product/_doc/1 { "name" : "小米手机", "desc" : "手机中的战斗机", "price" : 3999, "lv":"旗舰机", "type":"手机", "createtime":"2020-10-01T08:00:00Z", "tags": [ "性价比", "发烧", "不卡顿" ] } PUT /product/_doc/2 { "name" : "小米NFC手机", "desc" : "支持全功能NFC,手机中的滑翔机", "price" : 4999, "lv":"旗舰机", "type":"手机", "createtime":"2020-05-21T08:00:00Z", "tags": [ "性价比", "发烧", "公交卡" ] } PUT /product/_doc/3 { "name" : "NFC手机", "desc" : "手机中的轰炸机", "price" : 2999, "lv":"高端机", "type":"手机", "createtime":"2020-06-20", "tags": [ "性价比", "快充", "门禁卡" ] } PUT /product/_doc/4 { "name" : "小米耳机", "desc" : "耳机中的黄焖鸡", "price" : 999, "lv":"百元机", "type":"耳机", "createtime":"2020-06-23", "tags": [ "降噪", "防水", "蓝牙" ] } PUT /product/_doc/5 { "name" : "红米耳机", "desc" : "耳机中的肯德基", "price" : 399, "type":"耳机", "lv":"百元机", "createtime":"2020-07-20", "tags": [ "防火", "低音炮", "听声辨位" ] } PUT /product/_doc/6 { "name" : "小米手机10", "desc" : "充电贼快掉电更快,超级无敌望远镜,高刷电竞屏", "price" : "", "lv":"旗舰机", "type":"手机", "createtime":"2020-07-27", "tags": [ "120HZ刷新率", "120W快充", "120倍变焦" ] } PUT /product/_doc/7 { "name" : "挨炮 SE2", "desc" : "除了CPU,一无是处", "price" : "3299", "lv":"旗舰机", "type":"手机", "createtime":"2020-07-21", "tags": [ "割韭菜", "割韭菜", "割新韭菜" ] } PUT /product/_doc/8 { "name" : "XS Max", "desc" : "听说要出新款12手机了,终于可以换掉手中的4S了", "price" : 4399, "lv":"旗舰机", "type":"手机", "createtime":"2020-08-19", "tags": [ "5V1A", "4G全网通", "大" ] } PUT /product/_doc/9 { "name" : "小米电视", "desc" : "70寸性价比只选,不要一万八,要不要八千八,只要两千九百九十八", "price" : 2998, "lv":"高端机", "type":"耳机", "createtime":"2020-08-16", "tags": [ "巨馍", "家庭影院", "游戏" ] } PUT /product/_doc/10 { "name" : "红米电视", "desc" : "我比上边那个更划算,我也2998,我也70寸,但是我更好看", "price" : 2999, "type":"电视", "lv":"高端机", "createtime":"2020-08-28", "tags": [ "大片", "蓝光8K", "超薄" ] } PUT /product/_doc/11 { "name": "红米电视", "desc": "我比上边那个更划算,我也2998,我也70寸,但是我更好看", "price": 2998, "type": "电视", "lv": "高端机", "createtime": "2020-08-28", "tags": [ "大片", "蓝光8K", "超薄" ] }
基础语法 分桶聚合
## 语法 GET product/_search { "aggs": { "<aggs_name>": { "<agg_type>": { "field": "<field_name>" } } } } ## 桶聚合 例:统计不同标签的商品数量 GET product/_search { "aggs": { "tag_bucket": { "terms": { "field": "tags.keyword" } } } } ## 不显示hits数据:size:0 GET product/_search { "size": 0, "aggs": { "tag_bucket": { "terms": { "field": "tags.keyword" } } } } ## 排序 GET product/_search { "size": 0, "aggs": { "tag_bucket": { "terms": { "field": "tags.keyword", "size": 3, "order": { "_count": "desc" } } } } }
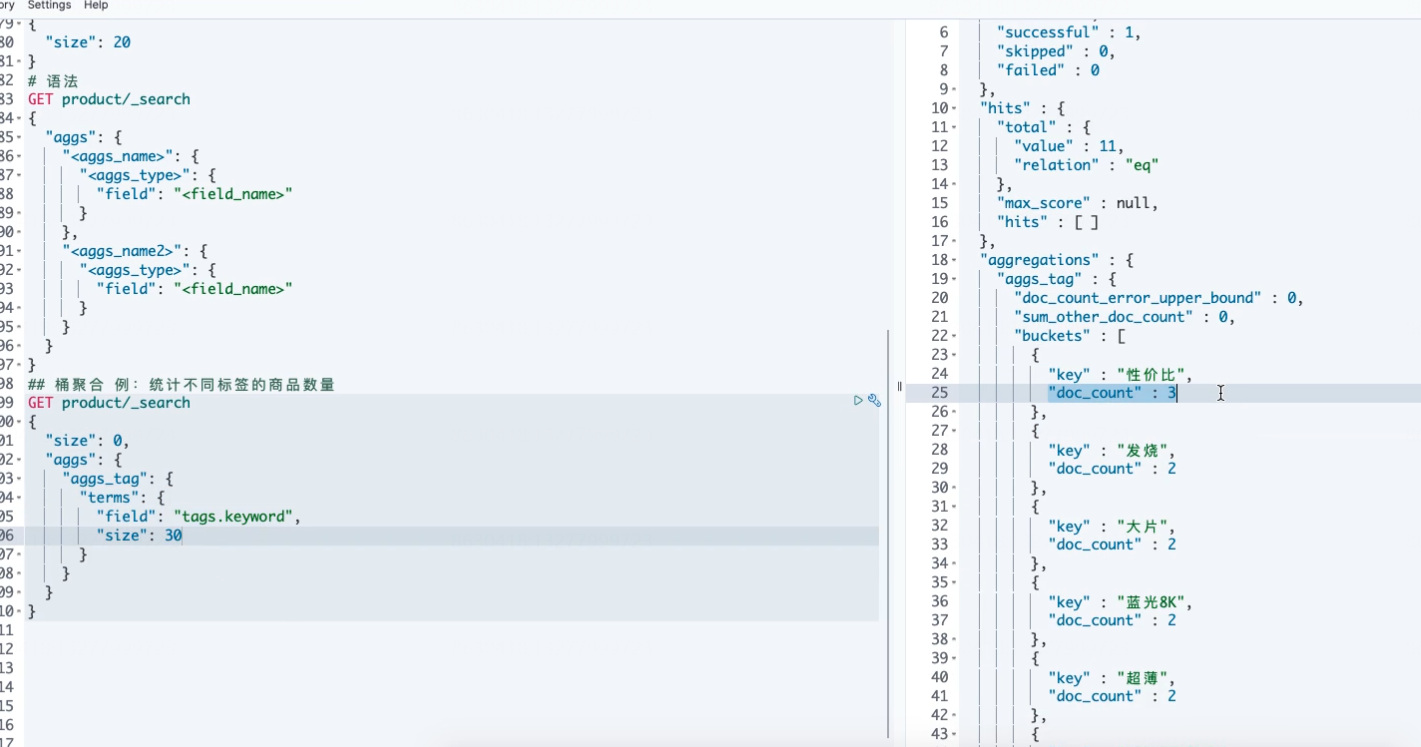
查询的时候为啥要用xxx.keyword ? 数据结构。。。
keyword:适用于索引结构化的字段,可以用于过滤、排序、聚合。keyword类型的字段只能通过精确值(exact value)搜索到。Id应该用keyword
text:当一个字段是要被全文搜索的,比如Email内容、产品描述,这些字段应该使用text类型。设置text类型以后,字段内容会被分析,在生成倒排索 引以前,字符串会被分析器分成一个一个词项。text类型的字段不用于排序,很少用于聚合。
(解释一下为啥不会为text创建正排索引:大量堆空间,尤其是 在加载高基数text字段时。字段数据一旦加载到堆中,就在该段的生命周期内保持在那里。同样,加载字段数据是一个昂贵的过程,可能导致用户遇到延迟问 题。
这就是默认情况下禁用字段数据的原因)
fields:给field创建多字段,用于不同目的(全文检索或者聚合分析排序)
doc_values:(正排索引)为了提升排序和聚合效率,默认true,如果确定不需要对字段进行排序或聚合,也不需要通过脚本访问字段值,则可以禁用doc值以节省磁盘 空间(不支持text和annotated_text)--基于磁盘----
fielddata:查询时内存数据结构,在首次用当前字段聚合、排序或者在脚本中使用时,需要字段为fielddata数据结构,并且创建倒排索引保存到堆中,---基于内存---- 数据量大会导致内存溢出
----------------------------------------------------------------------------------------------------------------------------------------
只有字段doc_values为true才支持聚合查询,keyword默认就是true
如果非要在text字段上聚合查询怎么办?
## doc_values和field_data GET product/_search { "size": 0, "aggs": { "tag_bucket": { "terms": { "field": "name" } } } } GET product/_search { "size": 0, "aggs": { "tag_bucket": { "terms": { "field": "name.keyword" } } } }
#修改text类型字段的fielddata为true POST product/_mapping { "properties": { "name": { "type": "text", "analyzer": "ik_max_word", "fielddata": true } } } GET product/_search { "size": 0, "aggs": { "tag_bucket": { "terms": { "size": 20, "field": "name" } } } }
使用fielddata:true缺点,会导致内存溢出。
指标聚合
1,
#***************************************** ## 指标聚合 ## 例:最贵、最便宜和平均价格三个指标 GET product/_search { "size": 0, "aggs": { "max_price": { "max": { "field": "price" } }, "min_price": { "min": { "field": "price" } }, "avg_price": { "avg": { "field": "price" } } } }
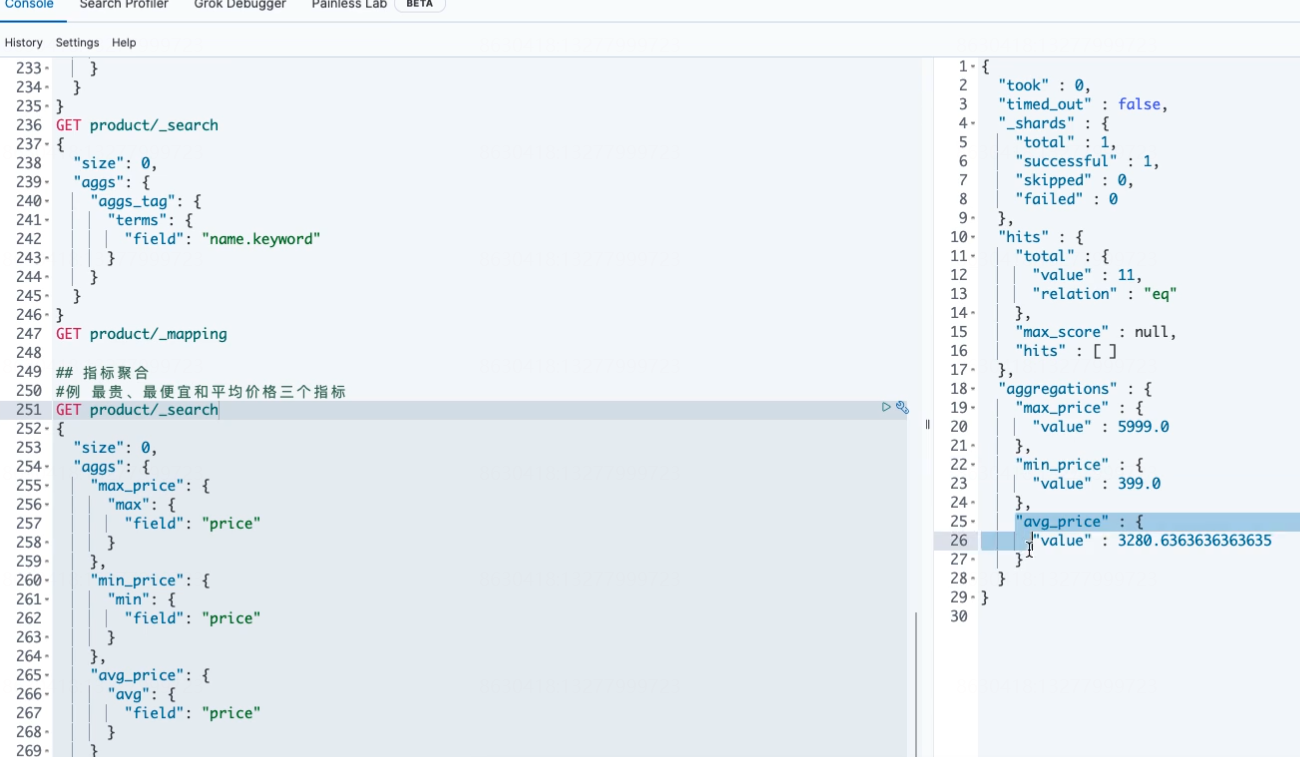
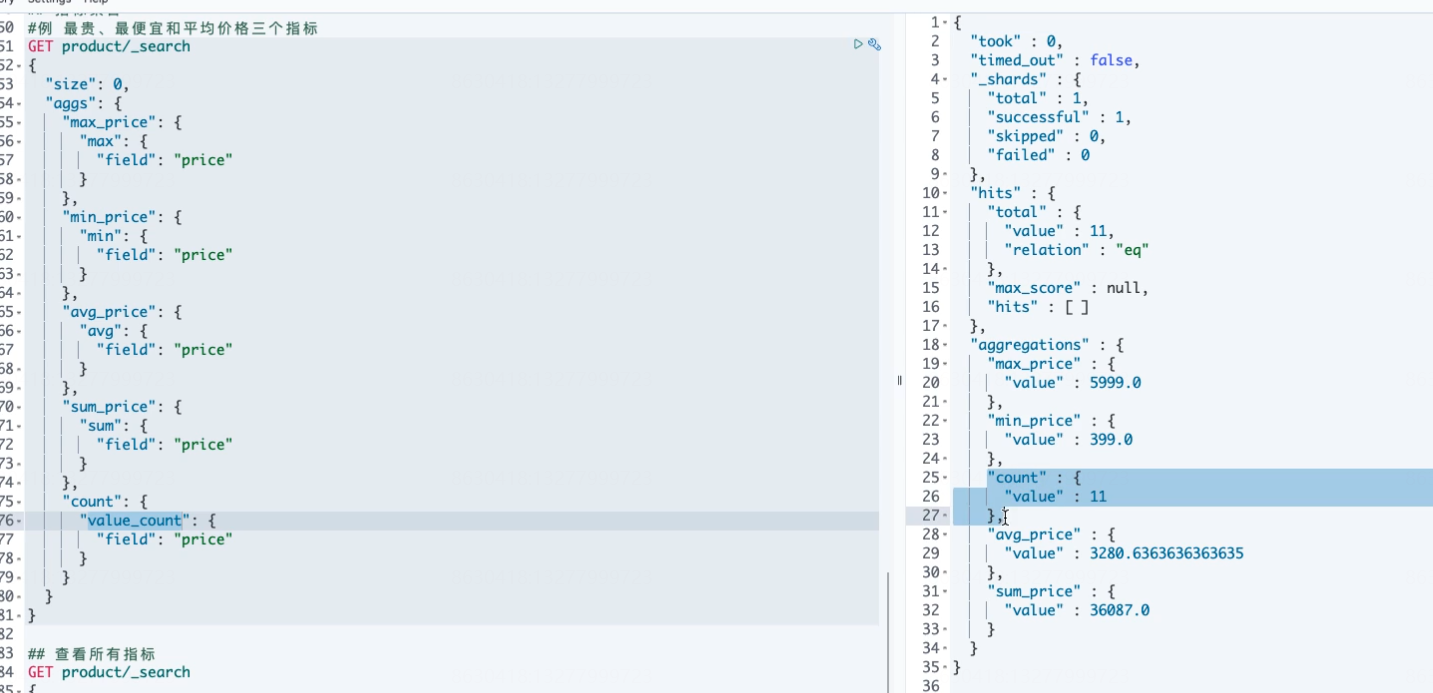
2,单个聚合查询所有指标
## 单个聚合查询所有指标 GET product/_search { "size": 0, "aggs": { "price_stats": { "stats": { "field": "price" } } } }
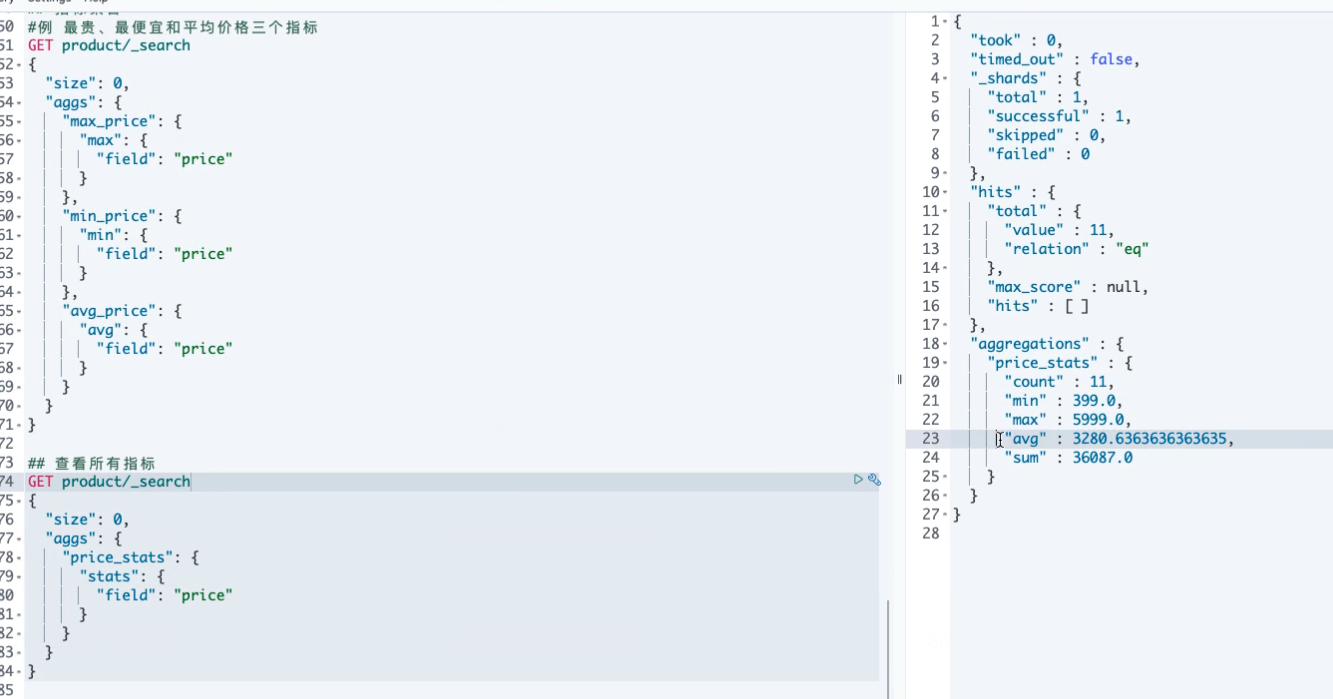
##按照name去重的数量
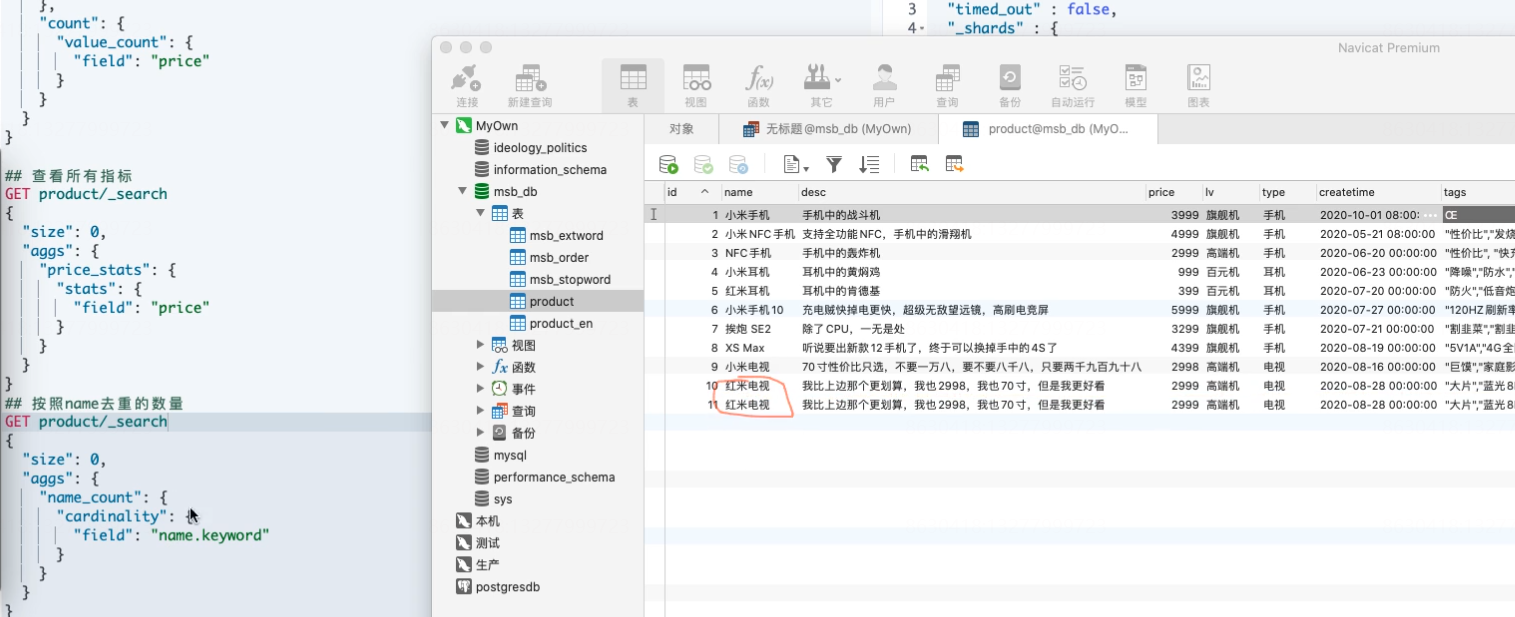
#name分词后的 返回15条记录 GET product/_search { "size": 0, "aggs": { "type_count": { "cardinality": { "field": "name" } } } }
#name不分词 精确 返回10条记录 GET product/_search { "size": 0, "aggs": { "type_count": { "cardinality": { "field": "name.keyword" } } } }
##对type计算去重后数量
GET product/_search
{
"size": 0,
"aggs": {
"type_count": {
"cardinality": {
"field": "lv.keyword"
}
}
}
}
管道聚合 二次聚合
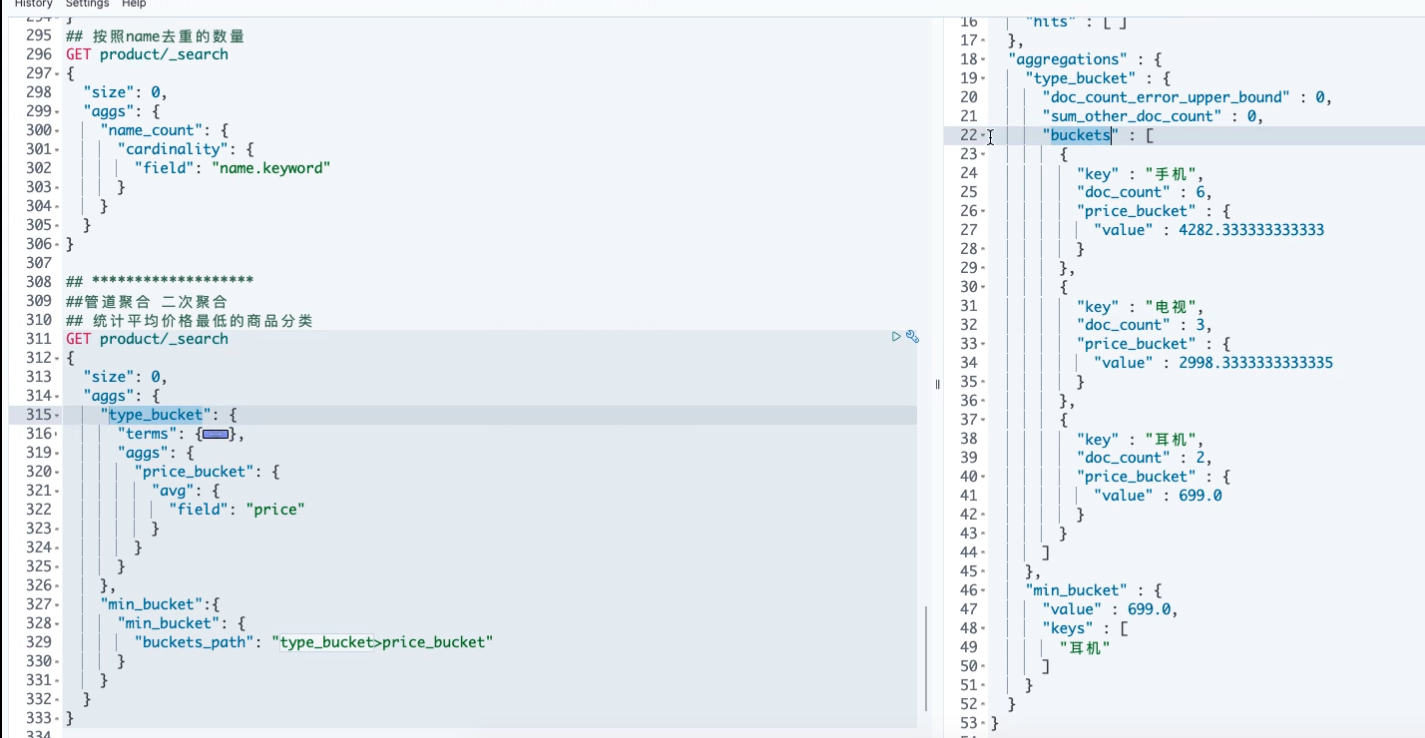
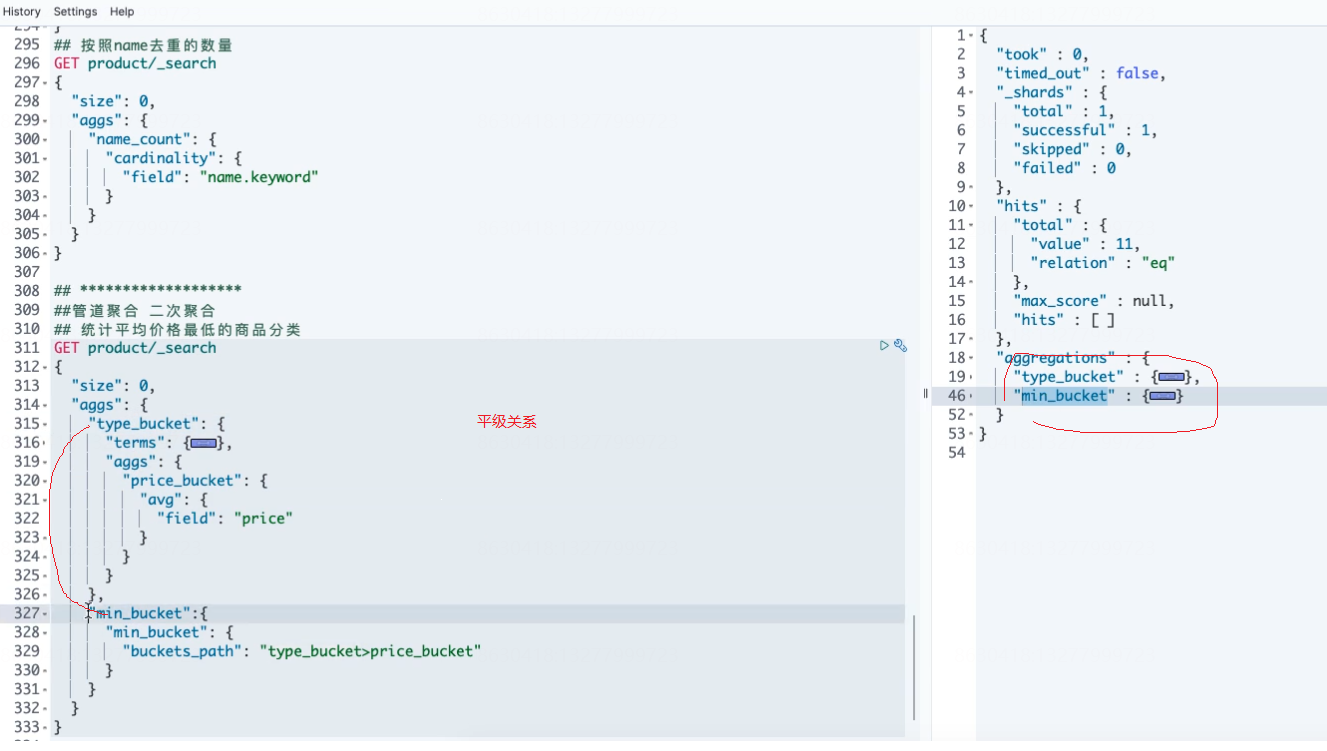
##********************************************* ## 管道聚合 二次聚合 ## 例:统计平均价格最低的商品分类 GET product/_search { "size": 0, "aggs": { "type_bucket": { "terms": {#计算商品分类 按照商品类别 "field": "type.keyword" }, "aggs": {#在上层结果中 计算第二层嵌套,计算平均值 "price_bucket": { "avg": { "field": "price" } } } }, "min_bucket":{ "min_bucket": { "buckets_path": "type_bucket>price_bucket" } } } }
第一层:1 terms 计算商品分类 按照商品类别
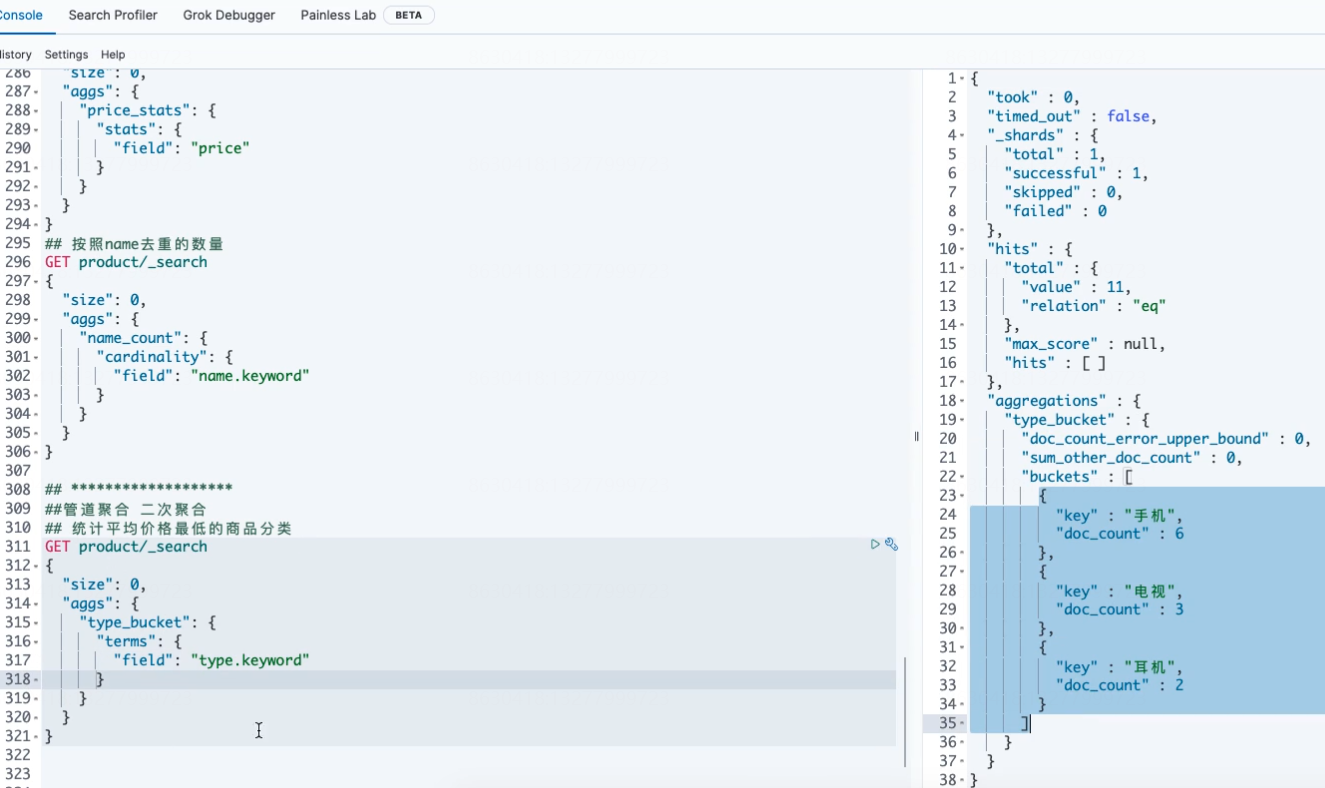
第二层:计算平均价格aggs
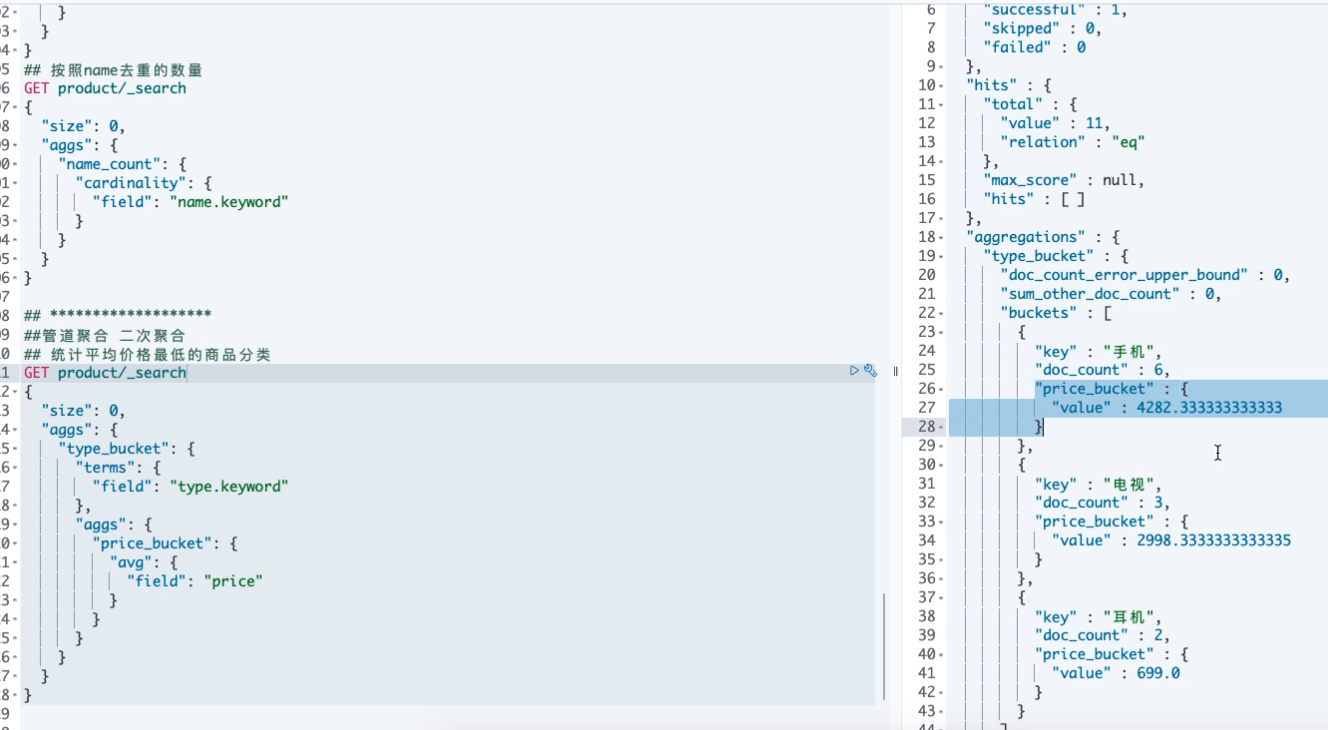
第3步 计算最低的
嵌套聚合
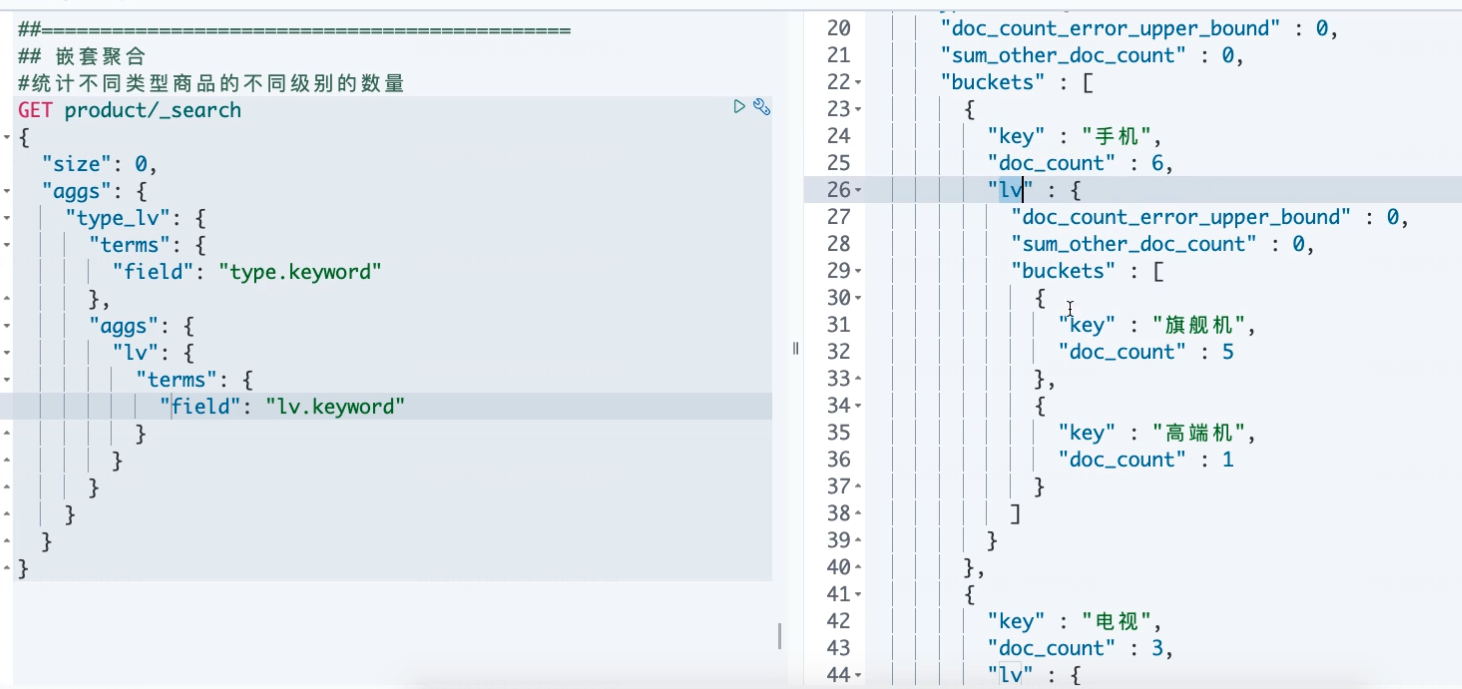
# 例:统计不同类型商品的不同级别的数量 GET product/_search { "size": 0, "aggs": { "type_lv": { "terms": { "field": "type.keyword" }, "aggs": { "lv": { "terms": { "field": "lv.keyword" } } } } } }
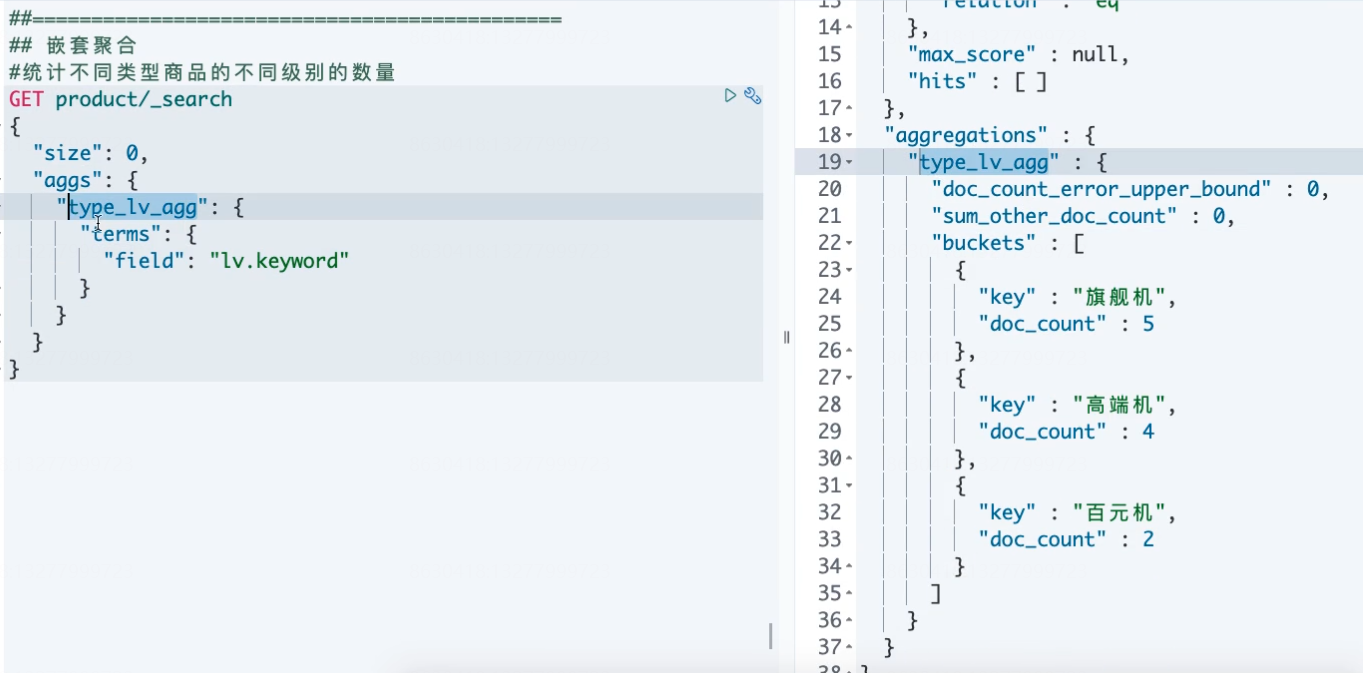
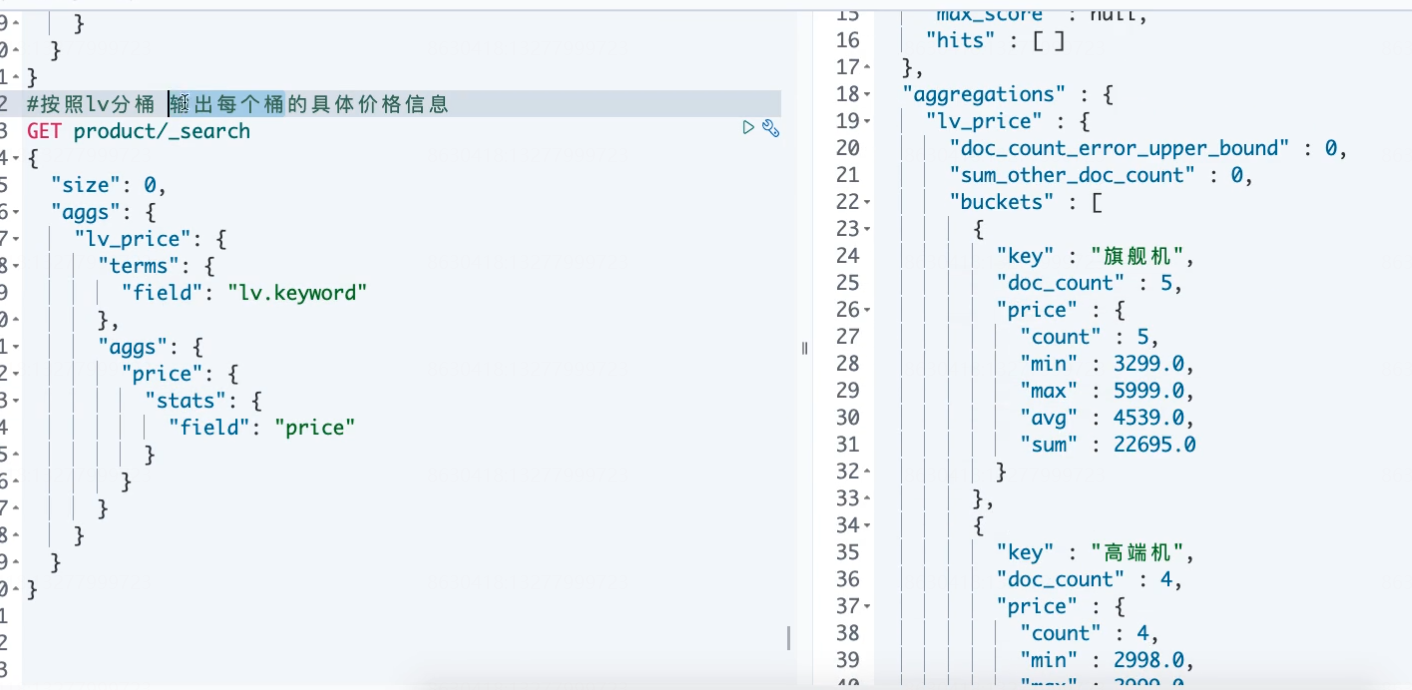
按照lv字段分桶 输出每个桶的具体价格信息
#按照lv字段分桶 输出每个桶的具体价格信息 GET product/_search { "size": 0, "aggs": { "lv_price": { "terms": { "field": "lv.keyword" }, "aggs": { "price": { "stats": { "field": "price" } } } } } }
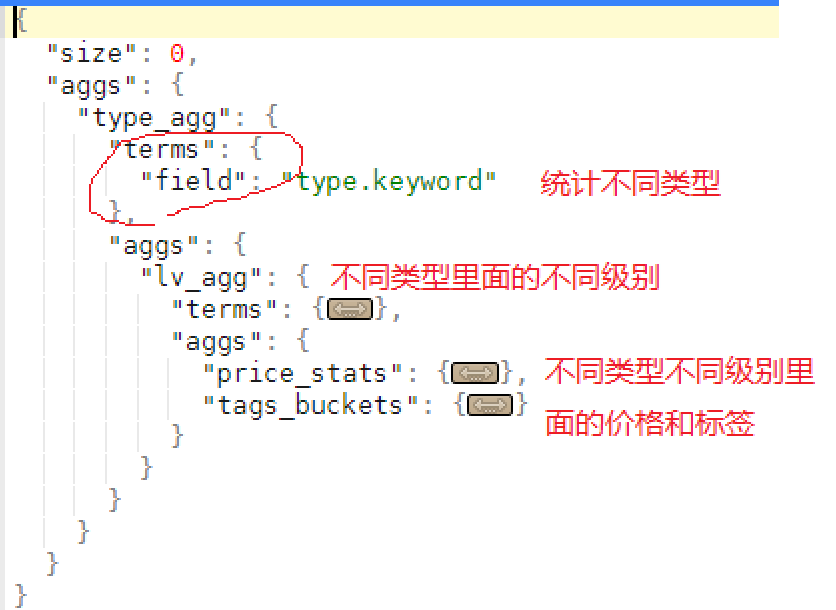
--------------------------------复杂的案例演示------------------------------------------------------------------------------
##结合了上面两个例子
##统计不同类型商品 不同档次的 价格信息 标签信息
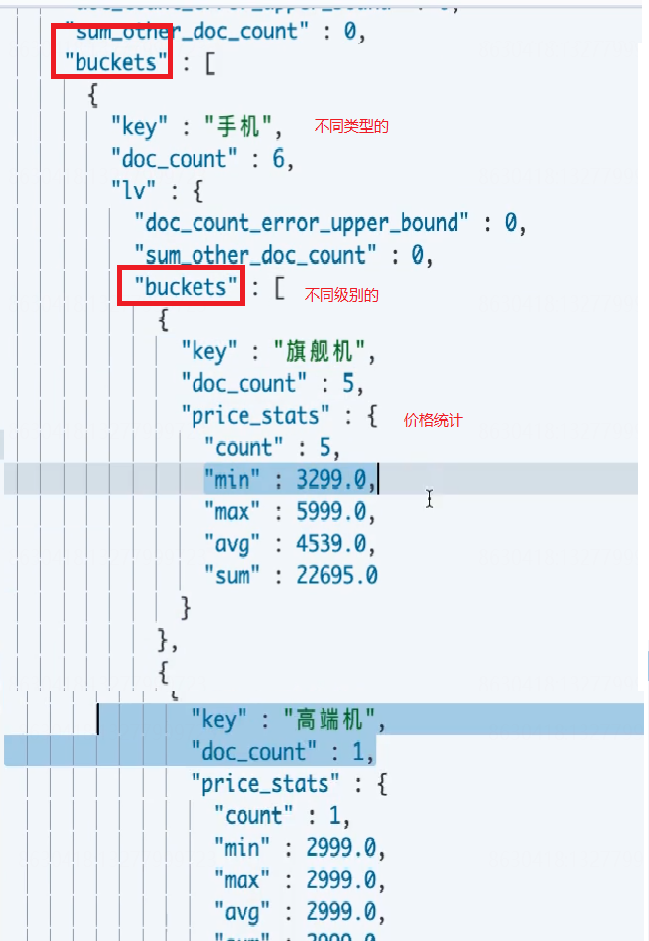
##结合了上面两个例子 ##统计不同类型商品 不同档次的 价格信息 标签信息 GET product/_search { "size": 0, "aggs": { "type_agg": { "terms": { "field": "type.keyword" }, "aggs": { "lv_agg": { "terms": { "field": "lv.keyword" }, "aggs": { "price_stats": { "stats": { "field": "price" } }, "tags_buckets": { "terms": { "field": "tags.keyword" } } } } } } } }
统计每个商品类型中 不同档次分类商品中 平均价格最低的档次
## 统计每个商品类型中 不同档次分类商品中 平均价格最低的档次 GET product/_search { "size": 0, "aggs": { "type_bucket": { "terms": { "field": "type.keyword" }, "aggs": { "lv_bucket": { "terms": { "field": "lv.keyword" }, "aggs": { "price_avg": { "avg": { "field": "price" } } } }, "min_bucket": { #在lv字段基础上计算 ,平级 "min_bucket": { "buckets_path": "lv_bucket>price_avg" } } } } } }
--------------------------------------以上都是基于结果的聚合 --------------------------------------

-----------------基于查询结果的聚合--------------------
#基于查询结果的聚合 GET product/_search { "size": 0, "query": { "range": { "price": { "gte": 5000 } } }, "aggs": { "tags_bucket": { "terms": { "field": "tags.keyword" } } } }
返回结果:

基于filter的aggs
GET product/_search { "query": { "constant_score": { "filter": { "range": { "price": { "gte": 5000 } } } } }, "aggs": { "tags_bucket": { "terms": { "field": "tags.keyword" } } } }
返回:

bool查询
GET product/_search { "query": { "bool": { "filter": { "range": { "price": { "gte": 5000 } } } } }, "aggs": { "tags_bucket": { "terms": { "field": "tags.keyword" } } } }
返回:

--基于聚合的查询--
post_filter不影响聚合内容,聚合后再过滤聚合结果
GET product/_search { "aggs": { "tags_bucket": { "terms": { "field": "tags.keyword" } } }, "post_filter": { "term": { "tags.keyword": "性价比" } } }
取消查询条件
查询条件嵌套
最贵、最便宜和平均价格三个指标
GET product/_search { "size": 10, "query": { "range": { "price": { "gte": 4000 #查询价格大于4000的 } } }, "aggs": { "max_price": { #基于上面价格大于4000的查询结果基础上 "max": { "field": "price" } }, "min_price": { #基于上面价格大于4000的查询结果基础上 "min": { "field": "price" } }, "avg_price": { #基于上面价格大于4000的查询结果基础上 "avg": { "field": "price" } }, "all_avg_price": { "global": {},#取消外层查询条件,查询所有数据。 "aggs": { "avg_price": { "avg": { "field": "price" } } } }, "muti_avg_price": { "filter": { "range": { "price": { "lte": 4500 #和外层价格大于4000 取交集。 价格大于4000 并且 价格小于4500 查询无结果 } } }, "aggs": { "avg_price": { "avg": { "field": "price" } } } } } }
聚合和查询的相互关系
-
基于query或filter的聚合
语法:
GET product/_search { "query": { ... }, "aggs": { ... } }
-
注意:以上语法,执行顺序为先query后aggs,顺序和谁在上谁在下没有关系。query中可以是查询、也可以是filter、或者bool query
-
基于聚合结果的查询、
GET product/_search { "aggs": { ... }, "post_filter": { ... } }
-
注意:以上语法,执行顺序为先aggs后post_filter,顺序和谁在上谁在下没有关系。
-
查询条件的作用域
GET product/_search { "size": 10, "query": { ... }, "aggs": { "avg_price": { ... }, "all_avg_price": { "global": {}, "aggs": { ... } } } }
-
上面例子中,avg_price的计算结果是基于query的查询结果的,而all_avg_price的聚合是基于all data的
-
-
聚合排序
-
排序规则:
order_type:_count(数量) _key(聚合结果的key值) _term(废弃但是仍然可用,使用_key代替
-
GET product/_search { "aggs": { "type_agg": { "terms": { "field": "tags", "order": { "<order_type>": "desc" }, "size": 10 } } } }
多级排序:即排序的优先级,按照外层优先的顺序
GET product/_search?size=0 { "aggs": { "first_sort": { ... "aggs": { "second_sort": { ... } } } } }
-
上例中,先按照first_sort排序,再按照second_sort排序
-
多层排序:即按照多层聚合中的里层某个聚合的结果进行排序
GET product/_search { "size": 0, "aggs": { "tag_avg_price": { "terms": { "field": "type.keyword", "order": { "agg_stats>my_stats.sum": "desc" } }, "aggs": { "agg_stats": { ... "aggs": { "my_stats": { "extended_stats": { ... } } } } } } } }
上例中,按照里层聚合“my_stats”进行排序
常用的查询函数
-
histogram:直方图或柱状图统计
用途:用于区间统计,如不同价格商品区间的销售情况
语法:
GET product/_search?size=0 { "aggs": { "<histogram_name>": { "histogram": { "field": "price", #字段名称 "interval": 1000, #区间间隔 "keyed": true, #返回数据的结构化类型 "min_doc_count": <num>, #返回桶的最小文档数阈值,即文档数小于num的桶不会被输出 "missing": 1999 #空值的替换值,即如果文档对应字段的值为空,则默认输出1999(参数值) } } } }
date-histogram:基于日期的直方图,比如统计一年每个月的销售额
语法:
GET product/_search?size=0
{
"aggs": {
"my_date_histogram": {
"date_histogram": {
"field": "createtime", #字段需为date类型
"<interval_type>": "month", #时间间隔的参数可选项
"format": "yyyy-MM", #日期的格式化输出
"extended_bounds": { #输出空桶
"min": "2020-01",
"max": "2020-12"
}
}
}
}
}
-
interval_type:时间间隔的参数可选项
fixed_interval:ms(毫秒)、s(秒)、 m(分钟)、h(小时)、d(天),注意单位需要带上具体的数值,如2d为两天。需要当心当单位过小,会 导致输出桶过多而导致服务崩溃。
calendar_interval:month、year
interval:(废弃,但是仍然可用)
-
percentile 百分位统计 或者 饼状图
-
percentiles:用于评估当前数值分布情况,比如99 percentile 是 1000 , 是指 99%的数值都在1000以内。常见的一个场景就是我们制定 SLA 的时候常说 99% 的请求延迟都在100ms 以内,这个时候你就可以用 99 percentile 来查一下,看一下 99 percenttile 的值如果在 100ms 以内,就代表SLA达标了。
语法:
-
GET product/_search?size=0 { "aggs": { "<percentiles_name>": { "percentiles": { "field": "price", "percents": [ percent1, #区间的数值,如5、10、30、50、99 即代表5%、10%、30%、50%、99%的数值分布 percent2, ... ] } } } }
percentile_ranks: percentile rank 其实就是percentiles的反向查询,比如我想看一下 1000、3000 在当前数值中处于哪一个范围内,你查一下它的 rank,发现是95,99,那么说明有95%的数值都在1000以内,99%的数值都在3000以内。
GET product/_search?size=0 { "aggs": { "<percentiles_name>": { "percentile_ranks": { "field": "<field_value>", "values": [ rank1, rank2, ... ] } } } }
#======================================================
#基于查询结果的聚合
GET product/_search { "size": 0, "query": { "range": { "price": { "gte": 5000 } } }, "aggs": { "tags_bucket": { "terms": { "field": "tags.keyword" } } } } #基于filter的aggs GET product/_search { "query": { "constant_score": { "filter": { "range": { "price": { "gte": 5000 } } } } }, "aggs": { "tags_bucket": { "terms": { "field": "tags.keyword" } } } } GET product/_search { "query": { "bool": { "filter": { "range": { "price": { "gte": 5000 } } } } }, "aggs": { "tags_bucket": { "terms": { "field": "tags.keyword" } } } }
#基于聚合的查询 GET product/_search { "aggs": { "tags_bucket": { "terms": { "field": "tags.keyword" } } }, "post_filter": { "term": { "tags.keyword": "性价比" } } } #取消查询条件&&查询条件嵌套 ## 例:最贵、最便宜和平均价格三个指标 GET product/_search { "size": 10, "query": { "range": { "price": { "gte": 4000 } } }, "aggs": { "max_price": { "max": { "field": "price" } }, "min_price": { "min": { "field": "price" } }, "avg_price": { "avg": { "field": "price" } }, "all_avg_price": { "global": {}, "aggs": { "avg_price": { "avg": { "field": "price" } } } }, "muti_avg_price": { "filter": { "range": { "price": { "lte": 4500 } } }, "aggs": { "avg_price": { "avg": { "field": "price" } } } } } }
#===============================================
#聚合排序_count _key _term
#=============================================== #聚合排序_count _key _term GET product/_search { "size": 0, "aggs": { "type_agg": { "terms": { "field": "tags", "order": { "_count": "desc" }, "size": 10 } } } } #多级排序 GET product/_search?size=0 { "aggs": { "first_sort": { "terms": { "field": "type.keyword", "order": { "_count": "desc" } }, "aggs": { "second_sort": { "terms": { "field": "lv.keyword", "order": { "_count": "asc" } } } } } } } #多层排序 GET product/_search { "size": 0, "aggs": { "tag_avg_price": { "terms": { "field": "type.keyword", "order": { "agg_stats>stats.sum": "desc" } }, "aggs": { "agg_stats": { "filter": { "terms": { "type.keyword": [ "耳机","手机","电视" ] } }, "aggs": { "stats": { "extended_stats": { "field": "price" } } } } } } } }
常用的查询函数
=========================================================== # 常用的查询函数 ## histogram 直方图 或者 柱状图 GET product/_search { "aggs": { "price_range": { "range": { "field": "price", "ranges": [ { "from": 0, "to": 1000 }, { "from": 1000, "to": 2000 }, { "from": 3000, "to": 4000 }, { "from": 4000, "to": 5000 } ] } } } } GET product/_search?size=0 { "aggs": { "price_range": { "range": { "field": "createtime", "ranges": [ { "from": "2020-05-01", "to": "2020-05-31" }, { "from": "2020-06-01", "to": "2020-06-30" }, { "from": "2020-07-01", "to": "2020-07-31" }, { "from": "2020-08-01" } ] } } } } #空值的处理逻辑 对字段的空值赋予默认值 GET product/_search?size=0 { "aggs": { "price_histogram": { "histogram": { "field": "price", "interval": 1000, "keyed": true, "min_doc_count": 0, "missing": 1999 } } } } #date-histogram #ms s m h d GET product/_search?size=0 { "aggs": { "my_date_histogram": { "date_histogram": { "field": "createtime", "calendar_interval": "month", "min_doc_count": 0, "format": "yyyy-MM", "extended_bounds": { "min": "2020-01", "max": "2020-12" }, "order": { "_count": "desc" } } } } } GET product/_search?size=0 { "aggs": { "my_auto_histogram": { "auto_date_histogram": { "field": "createtime", "format": "yyyy-MM-dd", "buckets": 180 } } } } #cumulative_sum GET product/_search?size=0 { "aggs": { "my_date_histogram": { "date_histogram": { "field": "createtime", "calendar_interval": "month", "min_doc_count": 0, "format": "yyyy-MM", "extended_bounds": { "min": "2020-01", "max": "2020-12" } }, "aggs": { "sum_agg": { "sum": { "field": "price" } }, "my_cumulative_sum":{ "cumulative_sum": { "buckets_path": "sum_agg" } } } } } } ## percentile 百分位统计 或者 饼状图 ## https://www.elastic.co/guide/en/elasticsearch/reference/7.10/search-aggregations-metrics-percentile-aggregation.html GET product/_search?size=0 { "aggs": { "price_percentiles": { "percentiles": { "field": "price", "percents": [ 1, 5, 25, 50, 75, 95, 99 ] } } } } #percentile_ranks #TDigest GET product/_search?size=0 { "aggs": { "price_percentiles": { "percentile_ranks": { "field": "price", "values": [ 1000, 2000, 3000, 4000, 5000, 6000 ] } } } }
本文来自博客园,作者:孙龙-程序员,转载请注明原文链接:https://www.cnblogs.com/sunlong88/p/17093717.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号