
gobing并行编程3-sync
传统的线程模型(通常在编写 Java、C++ 和Python 程序时使用)程序员在线程之间通信需要使用共享内存。通常,共享数据结构由锁保护,线程将争用这些锁来访问数据。
在某些情况下,通过使用线程安全的数据结构(如 Python 的Queue),这会变得更容易。 Go 的并发原语 goroutines 和 channels 为构造并发软件提供了一种优雅而独特的方法。
Go 没有显式地使用锁来协调对共享数据的访问,而是鼓励使用 chan 在 goroutine 之间传递对数据的引用。这种方法确保在给定的时间只有一个 goroutine 可以访问数据。
Do not communicate by sharing memory; instead, share memory by communicating. 3/6.go

data race 是两个或多个 goroutine 访问同一个资源(如变量或数据结构),并尝试对该资源进行读写而不考虑其他 goroutine。这种类型的代码可以创建您见过的最疯狂和最随机的 bug。通常需要大量的日志记录和运气才能找到这些类型的bug。
早在6月份的 Go 1.1中,Go 工具引入了一个 race detector。竞争检测器是在构建过程中内置到程序中的代码。
然后,一旦你的程序运行,它就能够检测并报告它发现的任何竞争条件。它非常酷,并且在识别罪魁祸首的代码方面做了令人难以置信的工作。
3/8.go go build -race go test -race
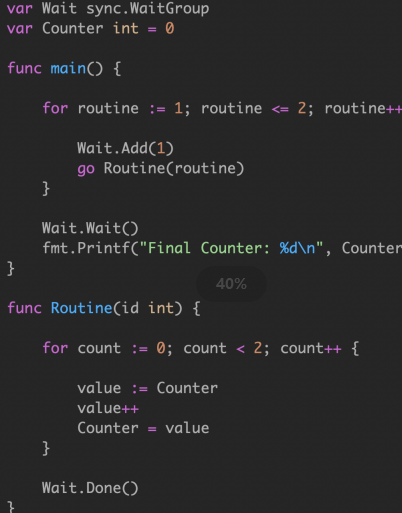
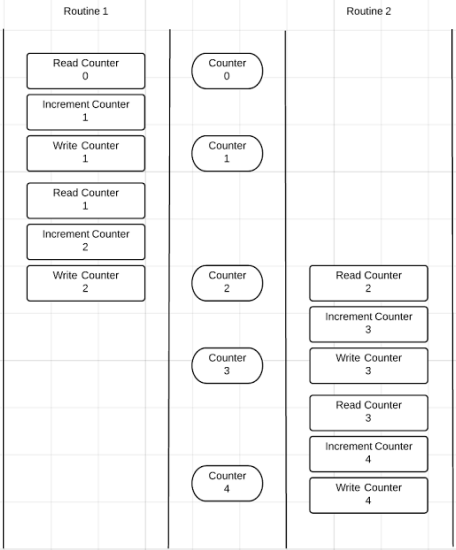
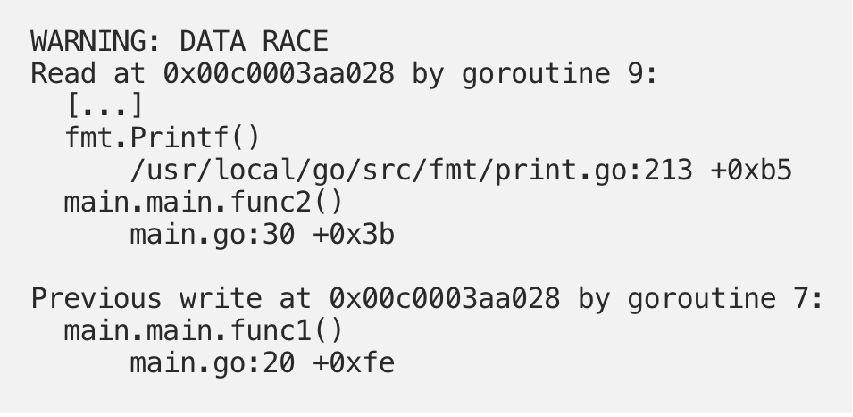
工具似乎检测到代码的争用条件。如果您查看race condition 报告下面,您可以看到程序的输出: 全局计数器变量的值为 2 或者 4。
|
|
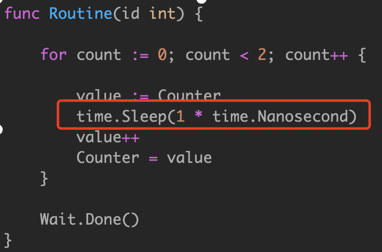
试图通过 i++ 方式来解决原子赋值的问题,但是我们通过查看底层汇编:

实际上有三行汇编代码在执行以增加计数器。这三行汇编代码看起来很像原始的 Go 代码。在这三行汇编代码之后可能有一个上下文切换。尽管程序现在正在运行,但从技术上讲,这个 bug 仍然存在。我们的 Go 代码看起来像是在安全地访问资源,而实际上底层的程序集代码根本就不安全。 我们应该使用 Go 同步语义: Mutex、Atomic
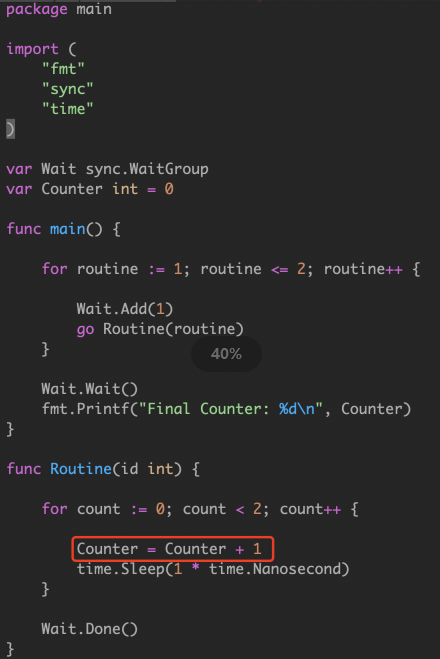
3/7.go 我们第一感觉是 single machine word 应该是原子赋值,为啥 -race 会乱报。我们执行这个代码看看会发生什么。

|
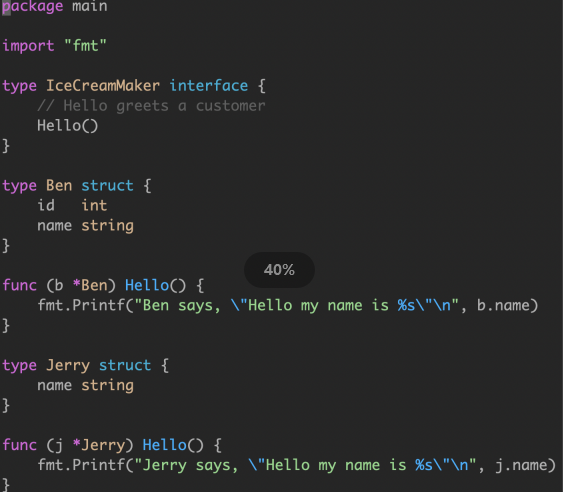
|
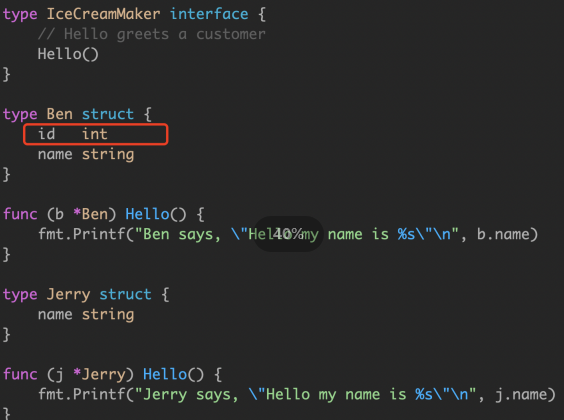
Type 指向实现了接口的 struct,Data 指向了实际的值。Data 作为通过 interface 中任何方法调用的接收方传递。 对于语句 var maker IceCreamMaker=ben,编译器将生成执行以下操作的代码。
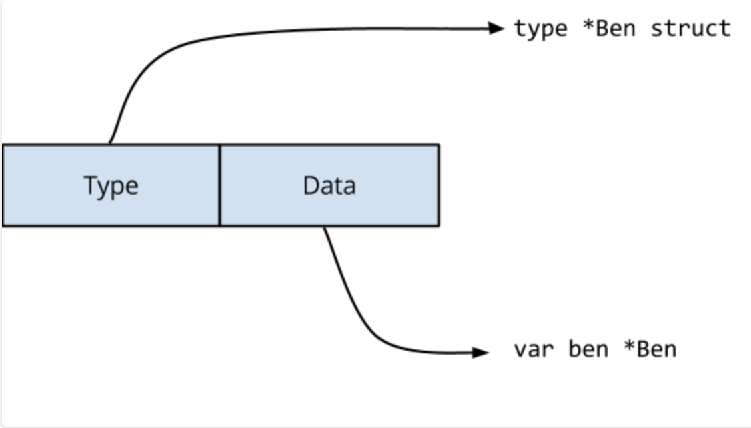
当 loop1() 执行 maker=jerry 语句时,必须更新接口值的两个字段。
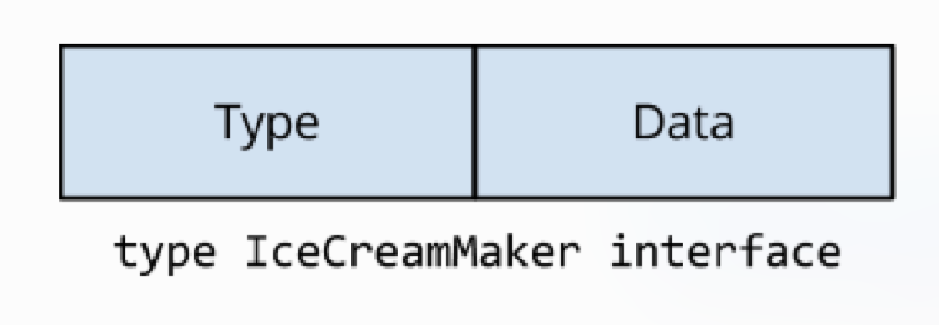

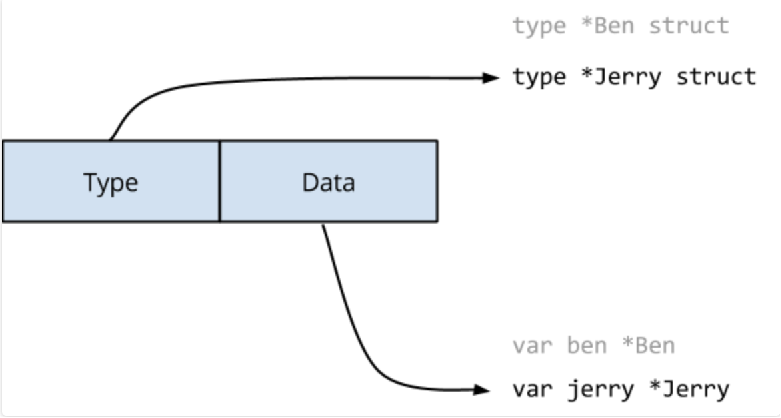
Go memory model 提到过: 表示写入单个 machine word 将是原子的,但 interface 内部是是两个 machine word 的值。另一个goroutine 可能在更改接口值时观察到它的内容。 在这个例子中,Ben 和 Jerry 内存结构布局是相同的,因此它们在某种意义上是兼容的。想象一下,如果他们有不同的内存布局会发生什么混乱?
如果是一个普通的指针、map、slice 可以安全的更新吗? 没有安全的 data race(safe data race)。您的程序要么没有 data race,要么其操作未定义。 原子性 可见行
sync.atomic
cfg 作为包级全局对象,在这个例子中被多个 goroutine 同时访问,因此这里存在 data race,会看到不连续的内存输出。


Benchmark 是出结果真相的真理,即便我们知道可能 Mutex vs Atomic 的情况里,Mutex 相对更重。因为涉及到更多的 goroutine 之间的上下文切换 pack blocking goroutine,以及唤醒
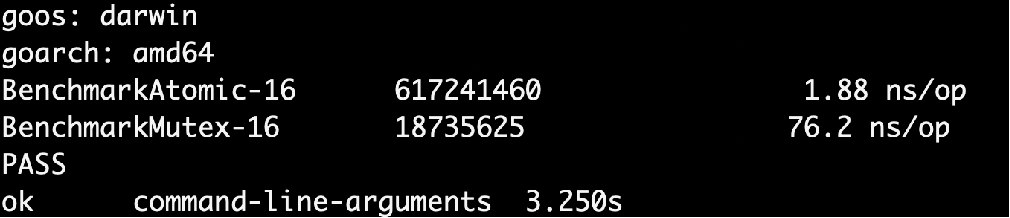
go test -bench=.
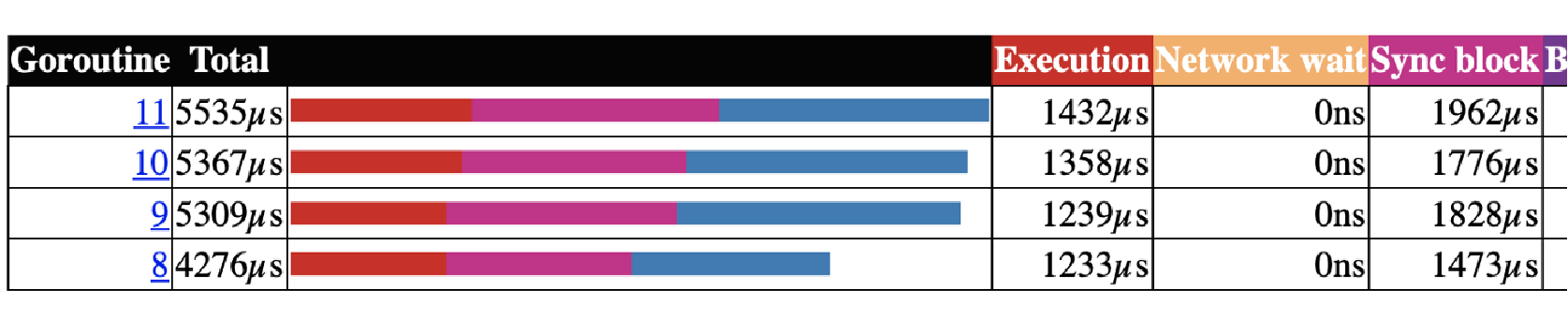
Copy-On-Write 思路在微服务降级或者 local cache 场景中经常使用。写时复制指的是,写操作时候复制全量老数据到一个新的对象中,携带上本次新写的数据,之后利用原子替换(atomic.Value),更新调用者的变量。来完成无锁访问共享数据。


Mutex
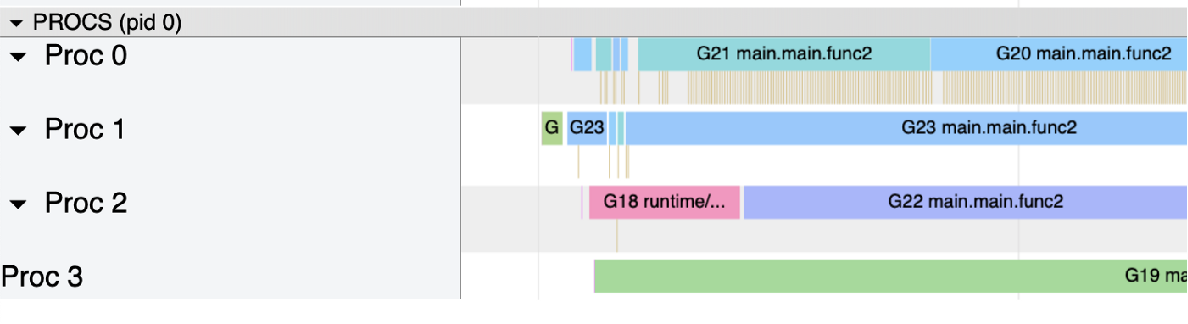
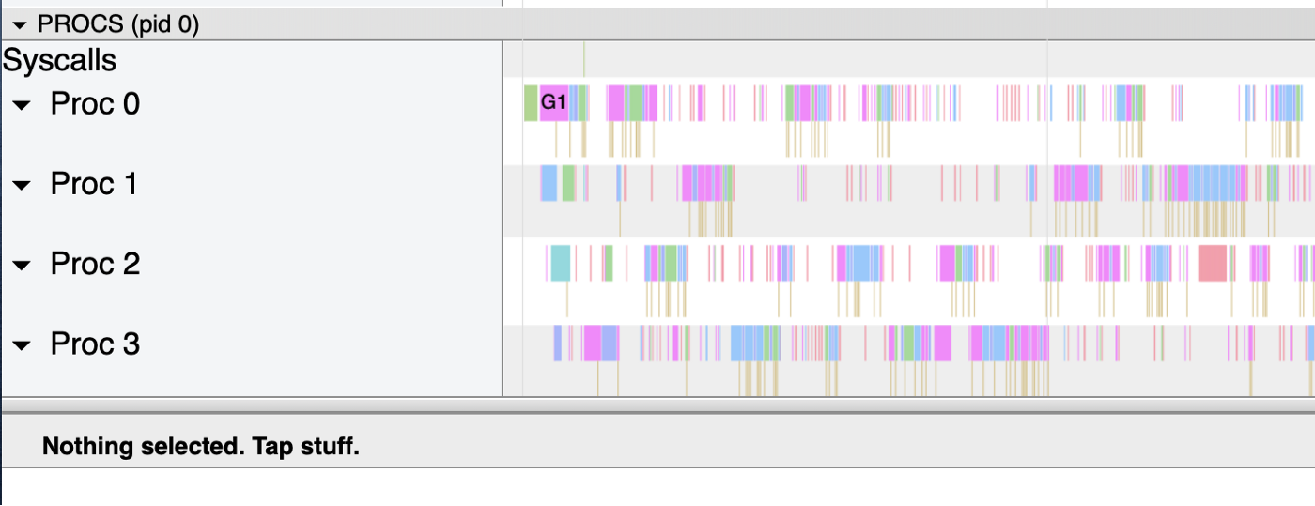
这个案例基于两个 goroutine: goroutine 1 持有锁很长时间 goroutine 2 每100ms 持有一次锁 都是100ms 的周期,但是由于 goroutine 1 不断的请求锁,可预期它会更频繁的持续到锁。我们基于 Go 1.8 循环了10次,下面是锁的请求占用分布:

Mutex 被 g1 获取了700多万次,而 g2 只获取了10次。

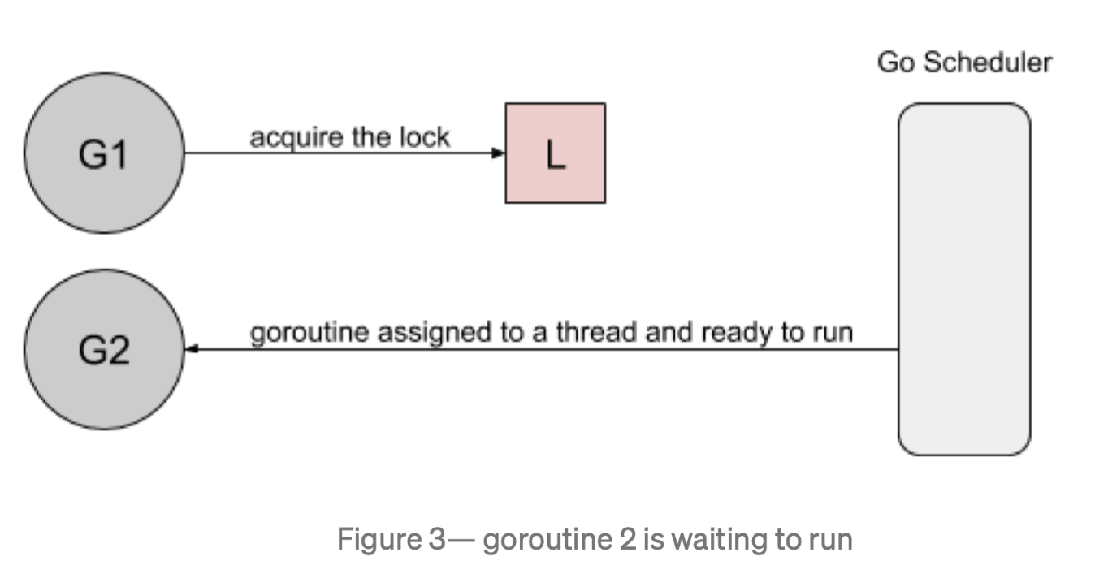
首先,goroutine1 将获得锁并休眠100ms。当goroutine2 试图获取锁时,它将被添加到锁的队列中- FIFO 顺序,goroutine 将进入等待状态。 然后,当 goroutine1 完成它的工作时,它将释放锁。此版本将通知队列唤醒 goroutine2。goroutine2 将被标记为可运行的,并且正在等待 Go 调度程序在线程上运行。
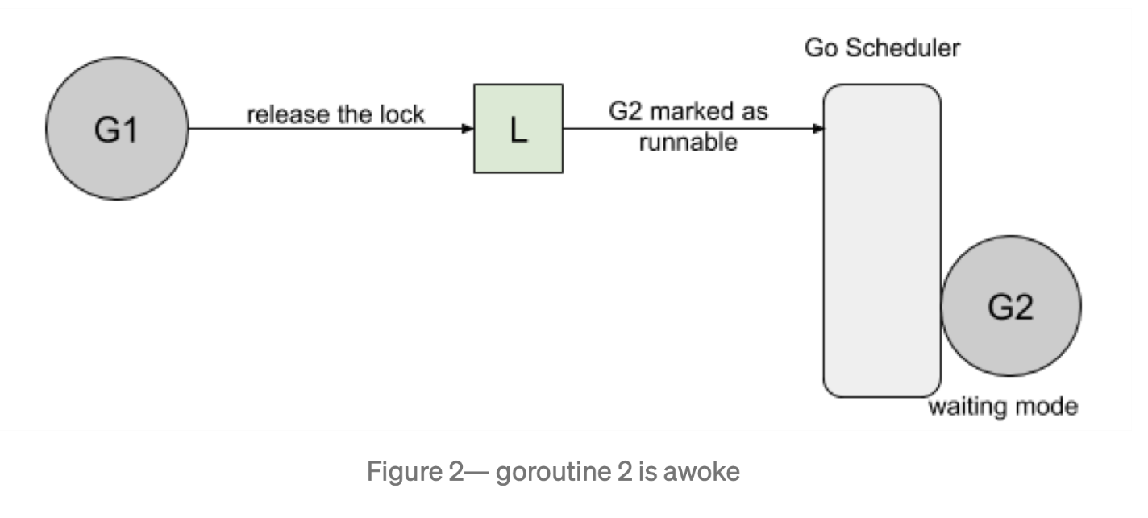
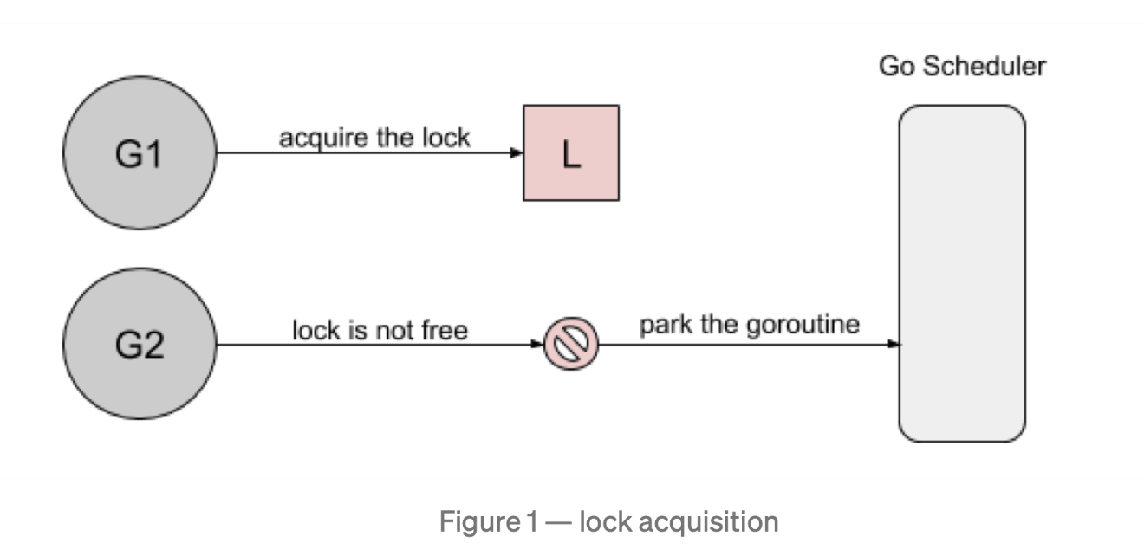
然而,当 goroutine2 等待运行时,goroutine1将再次请求锁。 goroutine2 尝试去获取锁,结果悲剧的发现锁又被人持有了,它自己继续进入到等待模式。
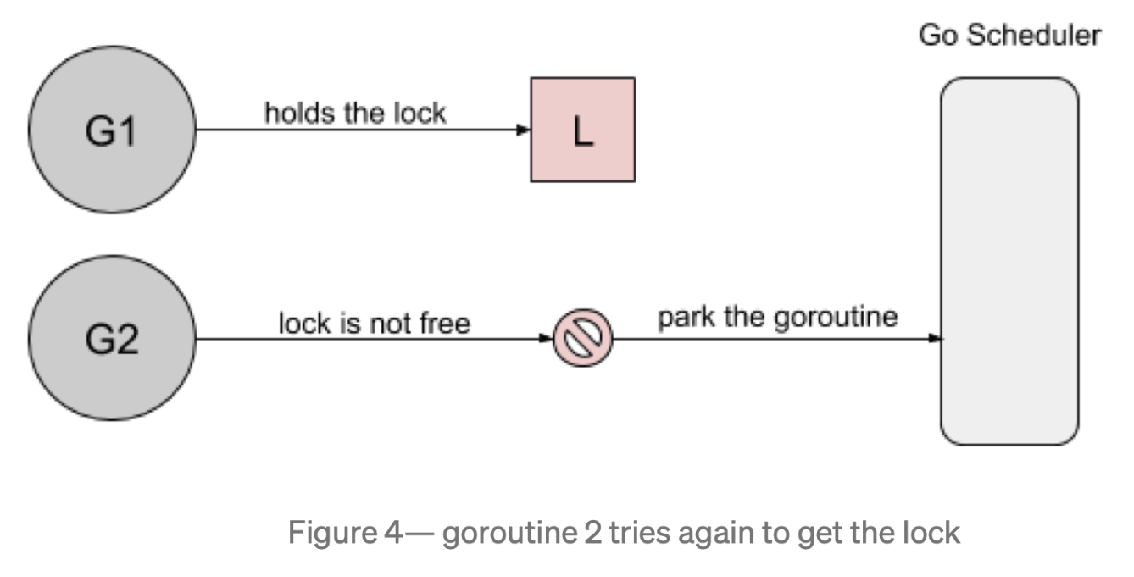
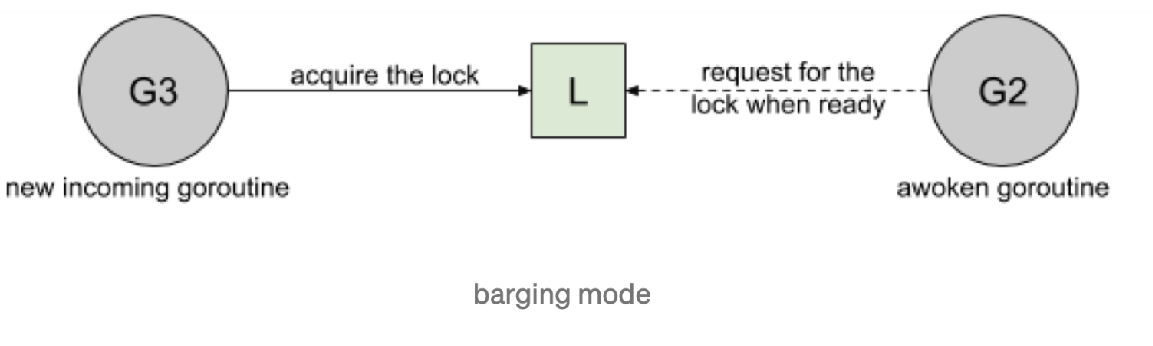
我们看看几种 Mutex 锁的实现: Barging. 这种模式是为了提高吞吐量,当锁被释放时,它会唤醒第一个等待者,然后把锁给第一个等待者或者给第一个请求锁的人。
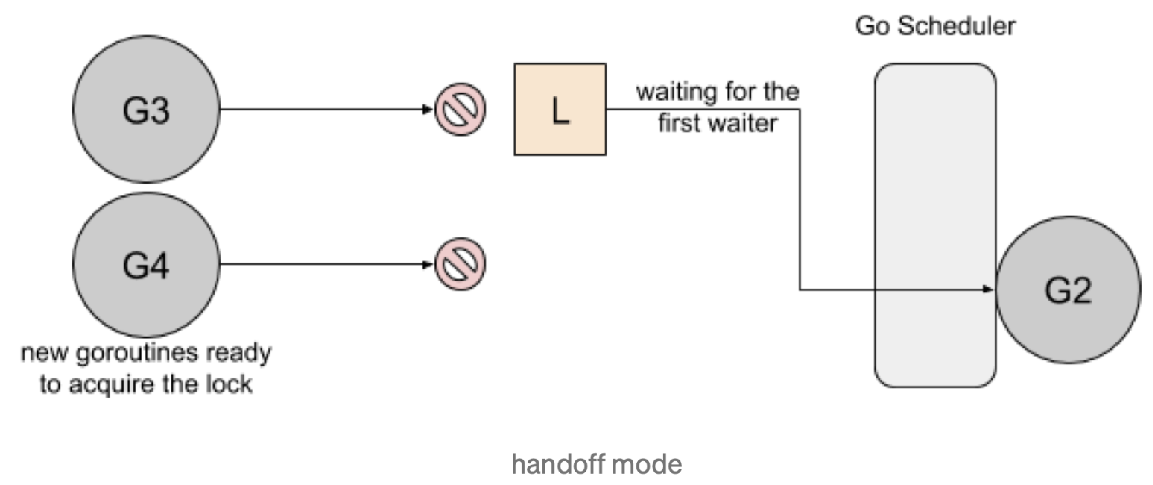
Handsoff. 当锁释放时候,锁会一直持有直到第一个等待者准备好获取锁。它降低了吞吐量,因为锁被持有,即使另一个 goroutine 准备获取它。
一个互斥锁的 handsoff 会完美地平衡两个goroutine 之间的锁分配,但是会降低性能,因为它会迫使第一个 goroutine 等待锁。
Spinning. 自旋在等待队列为空或者应用程序重度使用锁时效果不错。parking 和 unparking goroutines 有不低的性能成本开销,相比自旋来说要慢得多。
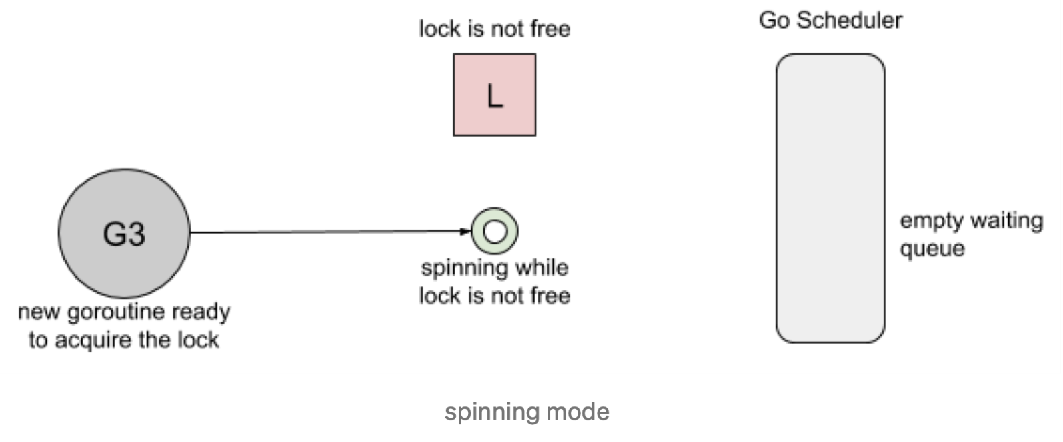
Go 1.8 使用了 Barging 和 Spining 的结合实现。当试图获取已经被持有的锁时,如果本地队列为空并且 P 的数量大于1,goroutine 将自旋几次(用一个 P 旋转会阻塞程序)。自旋后,goroutine park。在程序高频使用锁的情况下,它充当了一个快速路径。
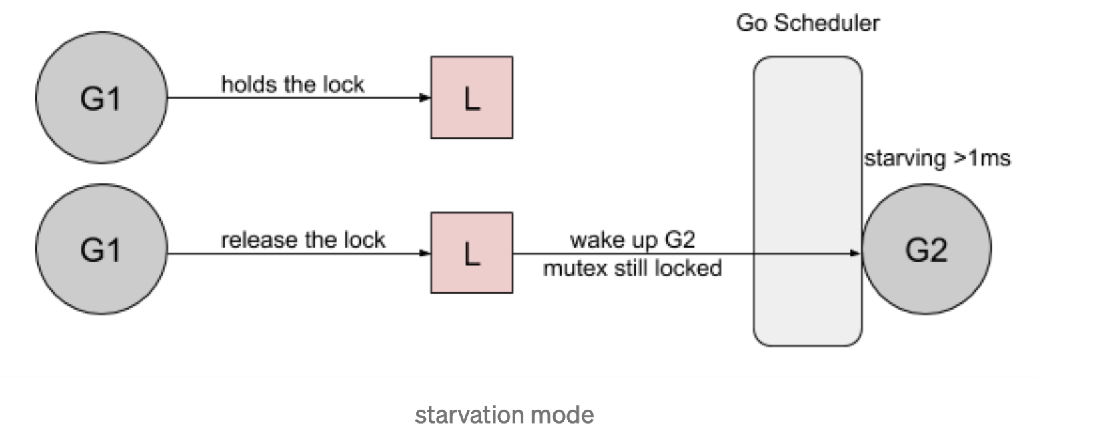
Go 1.9 通过添加一个新的饥饿模式来解决先前解释的问题,该模式将会在释放时候触发 handsoff。所有等待锁超过一毫秒的 goroutine(也称为有界等待)将被诊断为饥饿。当被标记为饥饿状态时,unlock 方法会 handsoff 把锁直接扔给第一个等待者。
在饥饿模式下,自旋也被停用,因为传入的goroutines 将没有机会获取为下一个等待者保留的锁

errgroup
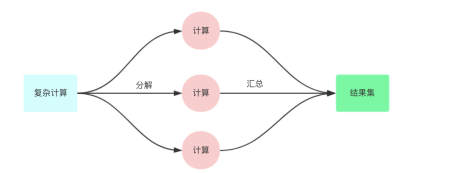
我们把一个复杂的任务,尤其是依赖多个微服务 rpc 需要聚合数据的任务,分解为依赖和并行,依赖的意思为: 需要上游 a 的数据才能访问下游 b 的数据进行组合。但是并行的意思为: 分解为多个小任务并行执行,最终等全部执行完毕。
https://pkg.go.dev/golang.org/x/sync/errgroup
核心原理: 利用 sync.Waitgroup 管理并行执行的 goroutine。
并行工作流
错误处理 或者 优雅降级
context 传播和取消
利用局部变量+闭包
sync.Pool
sync.Pool 的场景是用来保存和复用临时对象,以减少内存分配,降低 GC 压力(Request-Driven 特别合适)。
et 返回 Pool 中的任意一个对象。如果 Pool 为空,则调用 New 返回一个新创建的对象。
放进 Pool 中的对象,会在说不准什么时候被回收掉。所以如果事先 Put 进去 100 个对象,下次 Get 的时候发现 Pool 是空也是有可能的。不过这个特性的一个好处就在于不用担心 Pool 会一直增长,因为 Go 已经帮你在 Pool 中做了回收机制。
这个清理过程是在每次垃圾回收之前做的。之前每次GC 时都会清空 pool,而在1.13版本中引入了 victim cache,会将 pool 内数据拷贝一份,避免 GC 将其清空,即使没有引用的内容也可以保留最多两轮 GC。

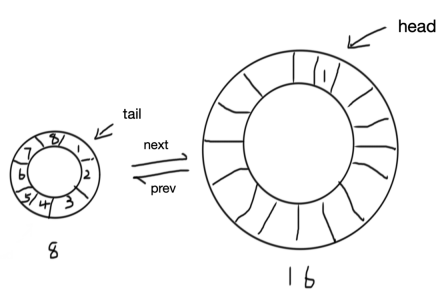
ring buffer(定长 FIFO) + 双向链表的方式,头部只能写入,尾部可以并发读取
本文来自博客园,作者:孙龙-程序员,转载请注明原文链接:https://www.cnblogs.com/sunlong88/p/16141530.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号