
golang 并发编程 通道用例大全
在阅读本文之前,请先阅读通道一文。 那篇文章详细地解释了通道类型和通道值,以及各种通道操作的规则细节。 一个Go新手程序员可能需要反复多次阅读那篇文章和当前这篇文章来精通Go通道编程。
本文余下的内容将展示很多通道用例。 希望这篇文章能够说服你接收下面的观点:- 使用通道进行异步和并发编程是简单和惬意的;
- 通道同步技术比被很多其它语言采用的其它同步方案(比如角色模型和async/await模式)有着更多的应用场景和更多的使用变种。
请注意,本文的目的是展示尽量多的通道用例。但是,我们应该知道通道并不是Go支持的唯一同步技术,并且通道并不是在任何情况下都是最佳的同步技术。 请阅读原子操作和其它并发同步技术来了解更多的Go支持的同步技术。
将通道用做future/promise
很多其它流行语言支持future/promise来实现异步(并发)编程。 Future/promise常常用在请求/回应场合。
返回单向接收通道做为函数返回结果
在下面这个例子中,sumSquares函数调用的两个实参请求并发进行。 每个通道读取操作将阻塞到请求返回结果为止。 两个实参总共需要大约3秒钟(而不是6秒钟)准备完毕(以较慢的一个为准)。
package main import ( "time" "math/rand" "fmt" ) func longTimeRequest() <-chan int32 { r := make(chan int32) go func() { time.Sleep(time.Second * 3) // 模拟一个工作负载 r <- rand.Int31n(100) }() return r } func sumSquares(a, b int32) int32 { return a*a + b*b } func main() { rand.Seed(time.Now().UnixNano()) a, b := longTimeRequest(), longTimeRequest() fmt.Println(sumSquares(<-a, <-b)) }
将单向发送通道类型用做函数实参
和上例一样,在下面这个例子中,sumSquares函数调用的两个实参的请求也是并发进行的。 和上例不同的是longTimeRequest函数接收一个单向发送通道类型参数而不是返回一个单向接收通道结果。
package main import ( "time" "math/rand" "fmt" ) func longTimeRequest(r chan<- int32) { time.Sleep(time.Second * 3) // 模拟一个工作负载 r <- rand.Int31n(100) } func sumSquares(a, b int32) int32 { return a*a + b*b } func main() { rand.Seed(time.Now().UnixNano()) ra, rb := make(chan int32), make(chan int32) go longTimeRequest(ra) go longTimeRequest(rb) fmt.Println(sumSquares(<-ra, <-rb)) }
对于上面这个特定的例子,我们可以只使用一个通道来接收回应结果,因为两个参数的作用是对等的。
... results := make(chan int32, 2) // 缓冲与否不重要 go longTimeRequest(results) go longTimeRequest(results) fmt.Println(sumSquares(<-results, <-results)) }
这可以看作是后面将要提到的数据聚合的一个应用。
采用最快回应
本用例可以看作是上例中只使用一个通道变种的增强。
有时候,一份数据可能同时从多个数据源获取。这些数据源将返回相同的数据。 因为各种因素,这些数据源的回应速度参差不一,甚至某个特定数据源的多次回应速度之间也可能相差很大。 同时从多个数据源获取一份相同的数据可以有效保障低延迟。我们只需采用最快的回应并舍弃其它较慢回应。
注意:如果有N个数据源,为了防止被舍弃的回应对应的协程永久阻塞,则传输数据用的通道必须为一个容量至少为N-1的缓冲通道。
package main import ( "fmt" "time" "math/rand" ) func source(c chan<- int32) { ra, rb := rand.Int31(), rand.Intn(3) + 1 // 睡眠1秒/2秒/3秒 time.Sleep(time.Duration(rb) * time.Second) c <- ra } func main() { rand.Seed(time.Now().UnixNano()) startTime := time.Now() c := make(chan int32, 5) // 必须用一个缓冲通道 for i := 0; i < cap(c); i++ { go source(c) } rnd := <- c // 只有第一个回应被使用了 fmt.Println(time.Since(startTime)) fmt.Println(rnd) }
“采用最快回应”用例还有一些其它实现方式,本文后面将会谈及。
更多“请求/回应”用例变种
做为函数参数和返回结果使用的通道可以是缓冲的,从而使得请求协程不需阻塞到它所发送的数据被接收为止。
有时,一个请求可能并不保证返回一份有效的数据。对于这种情形,我们可以使用一个形如struct{v T; err error}的结构体类型或者一个空接口类型做为通道的元素类型以用来区分回应的值是否有效。
有时,一个请求可能需要比预期更长的用时才能回应,甚至永远都得不到回应。 我们可以使用本文后面将要介绍的超时机制来应对这样的情况。
有时,回应方可能会不断地返回一系列值,这也同时属于后面将要介绍的数据流的一个用例。
使用通道实现通知
通知可以被看作是特殊的请求/回应用例。在一个通知用例中,我们并不关心回应的值,我们只关心回应是否已发生。 所以我们常常使用空结构体类型struct{}来做为通道的元素类型,因为空结构体类型的尺寸为零,能够节省一些内存(虽然常常很少量)。
向一个通道发送一个值来实现单对单通知
我们已知道,如果一个通道中无值可接收,则此通道上的下一个接收操作将阻塞到另一个协程发送一个值到此通道为止。 所以一个协程可以向此通道发送一个值来通知另一个等待着从此通道接收数据的协程。
在下面这个例子中,通道done被用来做为一个信号通道来实现单对单通知。package main import ( "crypto/rand" "fmt" "os" "sort" ) func main() { values := make([]byte, 32 * 1024 * 1024) if _, err := rand.Read(values); err != nil { fmt.Println(err) os.Exit(1) } done := make(chan struct{}) // 也可以是缓冲的 // 排序协程 go func() { sort.Slice(values, func(i, j int) bool { return values[i] < values[j] }) done <- struct{}{} // 通知排序已完成 }() // 并发地做一些其它事情... <- done // 等待通知 fmt.Println(values[0], values[len(values)-1]) }
从一个通道接收一个值来实现单对单通知
如果一个通道的数据缓冲队列已满(非缓冲的通道的数据缓冲队列总是满的)但它的发送协程队列为空,则向此通道发送一个值将阻塞,直到另外一个协程从此通道接收一个值为止。 所以我们可以通过从一个通道接收数据来实现单对单通知。一般我们使用非缓冲通道来实现这样的通知。
这种通知方式不如上例中介绍的方式使用得广泛。
package main import ( "fmt" "time" ) func main() { done := make(chan struct{}) // 此信号通道也可以缓冲为1。如果这样,则在下面 // 这个协程创建之前,我们必须向其中写入一个值。 go func() { fmt.Print("Hello") // 模拟一个工作负载。 time.Sleep(time.Second * 2) // 使用一个接收操作来通知主协程。 <- done }() done <- struct{}{} // 阻塞在此,等待通知 fmt.Println(" world!") }
另一个事实是,上面的两种单对单通知方式其实并没有本质的区别。 它们都可以被概括为较快者等待较慢者发出通知。
多对单和单对多通知
package main import "log" import "time" type T = struct{} func worker(id int, ready <-chan T, done chan<- T) { <-ready // 阻塞在此,等待通知 log.Print("Worker#", id, "开始工作") // 模拟一个工作负载。 time.Sleep(time.Second * time.Duration(id+1)) log.Print("Worker#", id, "工作完成") done <- T{} // 通知主协程(N-to-1) } func main() { log.SetFlags(0) ready, done := make(chan T), make(chan T) go worker(0, ready, done) go worker(1, ready, done) go worker(2, ready, done) // 模拟一个初始化过程 time.Sleep(time.Second * 3 / 2) // 单对多通知 ready <- T{}; ready <- T{}; ready <- T{} // 等待被多对单通知 <-done; <-done; <-done }
事实上,上例中展示的多对单和单对多通知实现方式在实践中用的并不多。 在实践中,我们多使用sync.WaitGroup来实现多对单通知,使用关闭一个通道的方式来实现单对多通知(详见下一个用例)。
通过关闭一个通道来实现群发通知
上一个用例中的单对多通知实现在实践中很少用,因为通过关闭一个通道的方式在来实现单对多通知的方式更简单。 我们已经知道,从一个已关闭的通道可以接收到无穷个值,我们可以利用这一特性来实现群发通知。
我们可以把上一个例子中的三个数据发送操作ready <- struct{}{}替换为一个通道关闭操作close(ready)来达到同样的单对多通知效果。
... close(ready) // 群发通知 ...
当然,我们也可以通过关闭一个通道来实现单对单通知。事实上,关闭通道来是实践中用得最多通知实现方式。
从一个已关闭的通道可以接收到无穷个值这一特性也将被用在很多其它在后面将要介绍的用例中。
定时通知(timer)
package main import ( "fmt" "time" ) func AfterDuration(d time.Duration) <- chan struct{} { c := make(chan struct{}, 1) go func() { time.Sleep(d) c <- struct{}{} }() return c } func main() { fmt.Println("Hi!") <- AfterDuration(time.Second) fmt.Println("Hello!") <- AfterDuration(time.Second) fmt.Println("Bye!") }
事实上,time标准库包中的After函数提供了和上例中AfterDuration同样的功能。 在实践中,我们应该尽量使用time.After函数以使代码看上去更干净。
注意,操作<-time.After(aDuration)将使当前协程进入阻塞状态,而一个time.Sleep(aDuration)函数调用不会如此。
<-time.After(aDuration)经常被使用在后面将要介绍的超时机制实现中。
将通道用做互斥锁(mutex)
上面的某个例子提到了容量为1的缓冲通道可以用做一次性二元信号量。 事实上,容量为1的缓冲通道也可以用做多次性二元信号量(即互斥锁)尽管这样的互斥锁效率不如sync标准库包中提供的互斥锁高效。
- 通过发送操作来加锁,通过接收操作来解锁;
- 通过接收操作来加锁,通过发送操作来解锁。
下面是一个通过发送操作来加锁的例子。
package main import "fmt" func main() { mutex := make(chan struct{}, 1) // 容量必须为1 counter := 0 increase := func() { mutex <- struct{}{} // 加锁 counter++ <-mutex // 解锁 } increase1000 := func(done chan<- struct{}) { for i := 0; i < 1000; i++ { increase() } done <- struct{}{} } done := make(chan struct{}) go increase1000(done) go increase1000(done) <-done; <-done fmt.Println(counter) // 2000 }
下面是一个通过接收操作来加锁的例子,其中只显示了相对于上例而修改了的部分。
... func main() { mutex := make(chan struct{}, 1) mutex <- struct{}{} // 此行是必需的 counter := 0 increase := func() { <-mutex // 加锁 counter++ mutex <- struct{}{} // 解锁 } ...
将通道用做计数信号量(counting semaphore)
缓冲通道可以被用做计数信号量。 计数信号量可以被视为多主锁。如果一个缓冲通道的容量为N,那么它可以被看作是一个在任何时刻最多可有N个主人的锁。 上面提到的二元信号量是特殊的计数信号量,每个二元信号量在任一时刻最多只能有一个主人。
计数信号量经常被使用于限制最大并发数。
和将通道用做互斥锁一样,也有两种方式用来获取一个用做计数信号量的通道的一份所有权。- 通过发送操作来获取所有权,通过接收操作来释放所有权;
- 通过接收操作来获取所有权,通过发送操作来释放所有权。
package main import ( "log" "time" "math/rand" ) type Seat int type Bar chan Seat func (bar Bar) ServeCustomer(c int) { log.Print("顾客#", c, "进入酒吧") seat := <- bar // 需要一个位子来喝酒 log.Print("++ customer#", c, " drinks at seat#", seat) log.Print("++ 顾客#", c, "在第", seat, "个座位开始饮酒") time.Sleep(time.Second * time.Duration(2 + rand.Intn(6))) log.Print("-- 顾客#", c, "离开了第", seat, "个座位") bar <- seat // 释放座位,离开酒吧 } func main() { rand.Seed(time.Now().UnixNano()) bar24x7 := make(Bar, 10) // 此酒吧有10个座位 // 摆放10个座位。 for seatId := 0; seatId < cap(bar24x7); seatId++ { bar24x7 <- Seat(seatId) // 均不会阻塞 } for customerId := 0; ; customerId++ { time.Sleep(time.Second) go bar24x7.ServeCustomer(customerId) } for {time.Sleep(time.Second)} // 睡眠不属于阻塞状态 }
在上例中,只有获得一个座位的顾客才能开始饮酒。 所以在任一时刻同时在喝酒的顾客数不会超过座位数10。
上例main函数中的最后一行for循环是为了防止程序退出。 后面将介绍一种更好的实现此目的的方法。
在上例中,尽管在任一时刻同时在喝酒的顾客数不会超过座位数10,但是在某一时刻可能有多于10个顾客进入了酒吧,因为某些顾客在排队等位子。 在上例中,每个顾客对应着一个协程。虽然协程的开销比系统线程小得多,但是如果协程的数量很多,则它们的总体开销还是不能忽略不计的。 所以,最好当有空位的时候才创建顾客协程。
... // 省略了和上例相同的代码 func (bar Bar) ServeCustomerAtSeat(c int, seat Seat) { log.Print("++ 顾客#", c, "在第", seat, "个座位开始饮酒") time.Sleep(time.Second * time.Duration(2 + rand.Intn(6))) log.Print("-- 顾客#", c, "离开了第", seat, "个座位") bar <- seat // 释放座位,离开酒吧 } func main() { rand.Seed(time.Now().UnixNano()) bar24x7 := make(Bar, 10) for seatId := 0; seatId < cap(bar24x7); seatId++ { bar24x7 <- Seat(seatId) } // 这个for循环和上例不一样。 for customerId := 0; ; customerId++ { time.Sleep(time.Second) seat := <- bar24x7 // 需要一个空位招待顾客 go bar24x7.ServeCustomerAtSeat(customerId, seat) } for {time.Sleep(time.Second)} }
在上面这个修改后的例子中,在任一时刻最多只有10个顾客协程在运行。
通过发送操作来获取所有权的实现相对简单一些,省去了摆放座位的步骤。
package main import ( "log" "time" "math/rand" ) type Customer struct{id int} type Bar chan Customer func (bar Bar) ServeCustomer(c Customer) { log.Print("++ 顾客#", c.id, "开始饮酒") time.Sleep(time.Second * time.Duration(3 + rand.Intn(16))) log.Print("-- 顾客#", c.id, "离开酒吧") <- bar // 离开酒吧,腾出位子 } func main() { rand.Seed(time.Now().UnixNano()) bar24x7 := make(Bar, 10) // 最对同时服务10位顾客 for customerId := 0; ; customerId++ { time.Sleep(time.Second * 2) customer := Customer{customerId} bar24x7 <- customer // 等待进入酒吧 go bar24x7.ServeCustomer(customer) } for {time.Sleep(time.Second)} }
对话(或称乒乓)
package main import "fmt" import "time" import "os" type Ball uint64 func Play(playerName string, table chan Ball) { var lastValue Ball = 1 for { ball := <- table // 接球 fmt.Println(playerName, ball) ball += lastValue if ball < lastValue { // 溢出结束 os.Exit(0) } lastValue = ball table <- ball // 回球 time.Sleep(time.Second) } } func main() { table := make(chan Ball) go func() { table <- 1 // (裁判)发球 }() go Play("A:", table) Play("B:", table) }
使用通道传送传输通道
chan<- int是另一个通道类型chan chan<- int的元素类型。package main import "fmt" var counter = func (n int) chan<- chan<- int { requests := make(chan chan<- int) go func() { for request := range requests { if request == nil { n++ // 递增计数 } else { request <- n // 返回当前计数 } } }() return requests // 隐式转换到类型chan<- (chan<- int) }(0) func main() { increase1000 := func(done chan<- struct{}) { for i := 0; i < 1000; i++ { counter <- nil } done <- struct{}{} } done := make(chan struct{}) go increase1000(done) go increase1000(done) <-done; <-done request := make(chan int, 1) counter <- request fmt.Println(<-request) // 2000 }
尽管对于上面这个用例来说,使用通道传送传输通道这种方式并非是最有效的实现方式,但是这种方式肯定有最适合它的用武之地。
检查通道的长度和容量
我们可以使用内置函数cap和len来查看一个通道的容量和当前长度。 但是在实践中我们很少这样做。我们很少使用内置函数cap的原因是一个通道的容量常常是已知的或者不重要的。 我们很少使用内置函数len的原因是一个len调用的结果并不能总能准确地反映出的一个通道的当前长度。
for len(c) > 0 { value := <-c // 使用value ... }
我们也可以用本文后面将要介绍的尝试接收机制来实现这一需求。两者的运行效率差不多,但尝试接收机制的优点是多个协程可以并发地进行读取操作。
有时一个协程欲将一个缓冲通道写满而又不阻塞,在确保只有此一个协程向此通道发送数据的情况下,我们可以用下面的代码实现这一目的:
for len(c) < cap(c) { c <- aValue }
当然,我们也可以使用后面将要介绍的尝试发送机制来实现这一需求。
使当前协程永久阻塞
Go中的选择机制(select)是一个非常独特的特性。它给并发编程带来了很多新的模式和技巧。
我们可以用一个无分支的select流程控制代码块使当前协程永久处于阻塞状态。 这是select流程控制的最简单的应用。 事实上,上面很多例子中的for {time.Sleep(time.Second)}都可以换为select{}。
一般,select{}用在主协程中以防止程序退出。
package main import "runtime" func DoSomething() { for { // 做点什么... runtime.Gosched() // 防止本协程霸占CPU不放 } } func main() { go DoSomething() go DoSomething() select{} }
顺便说一句,另外还有一些使当前协程永久阻塞的方法,但是select{}是最简单的方法。
尝试发送和尝试接收
default分支和一个case分支的select代码块可以被用做一个尝试发送或者尝试接收操作,取决于case关键字后跟随的是一个发送操作还是一个接收操作。
- 如果
case关键字后跟随的是一个发送操作,则此select代码块为一个尝试发送操作。 如果case分支的发送操作是阻塞的,则default分支将被执行,发送失败;否则发送成功,case分支得到执行。 - 如果
case关键字后跟随的是一个接收操作,则此select代码块为一个尝试接收操作。 如果case分支的接收操作是阻塞的,则default分支将被执行,接收失败;否则接收成功,case分支得到执行。
尝试发送和尝试接收代码块永不阻塞。
标准编译器对尝试发送和尝试接收代码块做了特别的优化,使得它们的执行效率比多case分支的普通select代码块执行效率高得多。
package main import "fmt" func main() { type Book struct{id int} bookshelf := make(chan Book, 3) for i := 0; i < cap(bookshelf) * 2; i++ { select { case bookshelf <- Book{id: i}: fmt.Println("成功将书放在书架上", i) default: fmt.Println("书架已经被占满了") } } for i := 0; i < cap(bookshelf) * 2; i++ { select { case book := <-bookshelf: fmt.Println("成功从书架上取下一本书", book.id) default: fmt.Println("书架上已经没有书了") } } }
输出结果:
成功将书放在书架上 0 成功将书放在书架上 1 成功将书放在书架上 2 书架已经被占满了 书架已经被占满了 书架已经被占满了 成功从书架上取下一本书 0 成功从书架上取下一本书 1 成功从书架上取下一本书 2 书架上已经没有书了 书架上已经没有书了 书架上已经没有书了
后面的很多用例还要用到尝试发送和尝试接收代码块。
无阻塞地检查一个通道是否已经关闭
func IsClosed(c chan T) bool { select { case <-c: return true default: } return false }
此方法常用来查看某个期待中的通知是否已经来临。此通知将由另一个协程通过关闭一个通道来发送。 峰值限制(peak/burst limiting) 将通道用做计数信号量用例和通道尝试(发送或者接收)操作结合起来可用实现峰值限制。 峰值限制的目的是防止过大的并发请求数。 下面是对将通道用做计数信号量一节中的最后一个例子的简单修改,从而使得顾客不再等待而是离去或者寻找其它酒吧。
... bar24x7 := make(Bar, 10) // 此酒吧只能同时招待10个顾客 for customerId := 0; ; customerId++ { time.Sleep(time.Second) consumer := Consumer{customerId} select { case bar24x7 <- consumer: // 试图进入此酒吧 go bar24x7.ServeConsumer(consumer) default: log.Print("顾客#", customerId, "不愿等待而离去") } } ...
另一种“采用最快回应”的实现方式
package main import ( "fmt" "math/rand" "time" ) func source(c chan<- int32) { ra, rb := rand.Int31(), rand.Intn(3)+1 // 休眠1秒/2秒/3秒 time.Sleep(time.Duration(rb) * time.Second) select { case c <- ra: default: } } func main() { rand.Seed(time.Now().UnixNano()) c := make(chan int32, 1) // 此通道容量必须至少为1 for i := 0; i < 5; i++ { go source(c) } rnd := <-c // 只采用第一个成功发送的回应数据 fmt.Println(rnd) }
注意,使用选择机制来实现“采用最快回应”的代码中使用的通道的容量必须至少为1,以保证最快回应总能够发送成功。 否则,如果数据请求者因为种种原因未及时准备好接收,则所有回应者的尝试发送都将失败,从而所有回应的数据都将被错过。
第三种“采用最快回应”的实现方式
select代码块来同时接收这三个通道。 示例代码如下:package main import ( "fmt" "math/rand" "time" ) func source() <-chan int32 { c := make(chan int32, 1) // 必须为一个缓冲通道 go func() { ra, rb := rand.Int31(), rand.Intn(3)+1 time.Sleep(time.Duration(rb) * time.Second) c <- ra }() return c } func main() { rand.Seed(time.Now().UnixNano()) var rnd int32 // 阻塞在此直到某个数据源率先回应。 select{ case rnd = <-source(): case rnd = <-source(): case rnd = <-source(): } fmt.Println(rnd) }
注意:如果上例中使用的通道是非缓冲的,未被选中的case分支对应的两个source函数调用中开辟的协程将处于永久阻塞状态,从而造成内存泄露。
本小节和上一小节中展示的两种方法也可以用来实现多对单通知。
超时机制(timeout)
在一些请求/回应用例中,一个请求可能因为种种原因导致需要超出预期的时长才能得到回应,有时甚至永远得不到回应。 对于这样的情形,我们可以使用一个超时方案给请求者返回一个错误信息。 使用选择机制可以很轻松地实现这样的一个超时方案。
下面这个例子展示了如何实现一个支持超时设置的请求:func requestWithTimeout(timeout time.Duration) (int, error) { c := make(chan int) go doRequest(c) // 可能需要超出预期的时长回应 select { case data := <-c: return data, nil case <-time.After(timeout): return 0, errors.New("超时了!") } }
脉搏器(ticker)
package main import "fmt" import "time" func Tick(d time.Duration) <-chan struct{} { c := make(chan struct{}, 1) // 容量最好为1 go func() { for { time.Sleep(d) select { case c <- struct{}{}: default: } } }() return c } func main() { t := time.Now() for range Tick(time.Second) { fmt.Println(time.Since(t)) } }
事实上,time标准库包中的Tick函数提供了同样的功能,但效率更高。 我们应该尽量使用标准库包中的实现。
速率限制(rate limiting)
上面已经展示了如何使用尝试发送实现峰值限制。 同样地,我们也可以使用使用尝试机制来实现速率限制,但需要前面刚提到的定时器实现的配合。 速率限制常用来限制吞吐和确保在一段时间内的资源使用不会超标。
下面的例子借鉴了官方Go维基中的例子。 在此例中,任何一分钟时段内处理的请求数不会超过200。package main import "fmt" import "time" type Request interface{} func handle(r Request) {fmt.Println(r.(int))} const RateLimitPeriod = time.Minute const RateLimit = 200 // 任何一分钟内最多处理200个请求 func handleRequests(requests <-chan Request) { quotas := make(chan time.Time, RateLimit) go func() { tick := time.NewTicker(RateLimitPeriod / RateLimit) defer tick.Stop() for t := range tick.C { select { case quotas <- t: default: } } }() for r := range requests { <-quotas go handle(r) } } func main() { requests := make(chan Request) go handleRequests(requests) // time.Sleep(time.Minute) for i := 0; ; i++ {requests <- i} }
上例的代码虽然可以保证任何一分钟时段内处理的请求数不会超过200,但是如果在开始的一分钟内没有任何请求,则接下来的某个瞬时时间点可能会同时处理最多200个请求(试着将time.Sleep行的注释去掉看看)。 这可能会造成卡顿情况。我们可以将速率限制和峰值限制一并使用来避免出现这样的情况。
开关
通道一文提到了向一个nil通道发送数据或者从中接收数据都属于阻塞操作。 利用这一事实,我们可以将一个select流程控制中的case操作中涉及的通道设置为不同的值,以使此select流程控制选择执行不同的分支。
case操作中的通道有且只有一个为nil,所以只能是不为nil的通道对应的分支被选中。 每个循环步将对调这两个case操作中的通道,从而改变两个分支的可被选中状态。
package main import "fmt" import "time" import "os" type Ball uint8 func Play(playerName string, table chan Ball, serve bool) { var receive, send chan Ball if serve { receive, send = nil, table } else { receive, send = table, nil } var lastValue Ball = 1 for { select { case send <- lastValue: case value := <- receive: fmt.Println(playerName, value) value += lastValue if value < lastValue { // 溢出了 os.Exit(0) } lastValue = value } receive, send = send, receive // 开关切换 time.Sleep(time.Second) } } func main() { table := make(chan Ball) go Play("A:", table, false) Play("B:", table, true) }
下面是另一个也展示了开关效果的但简单得多的(非并发的)小例子。 此程序将不断打印出1212...。 它在实践中没有太多实用价值,这里只是为了学习的目的才展示之。
package main import "fmt" import "time" func main() { for c := make(chan struct{}, 1); true; { select { case c <- struct{}{}: fmt.Print("1") case <-c: fmt.Print("2") } time.Sleep(time.Second) } }
控制代码被执行的几率
我们可以通过在一个select流程控制中使用重复的case操作来增加对应分支中的代码的执行几率。
package main import "fmt" func main() { foo, bar := make(chan struct{}), make(chan struct{}) close(foo); close(bar) // 仅为演示目的 x, y := 0.0, 0.0 f := func(){x++} g := func(){y++} for i := 0; i < 100000; i++ { select { case <-foo: f() case <-foo: f() case <-bar: g() } } fmt.Println(x/y) // 大致为2 }
在上面这个例子中,函数f的调用执行几率大致为函数g的两倍。
从动态数量的分支中选择
每个select控制流程中的分支数量在运行中是固定的,但是我们可以使用reflect标准库包中提供的功能在运行时刻来构建动态分支数量的select控制流程。 但是请注意:一个select控制流程中的分支越多,此select控制流程的执行效率就越低(这是我们常常只使用不多于三个分支的select控制流程的原因)。
reflect标准库包中也提供了模拟尝试发送和尝试接收代码块的TrySend和TryRecv函数。
数据流操纵
本节将介绍一些使用通道进行数据流处理的用例。
一般来说,一个数据流处理程序由多个模块组成。不同的模块执行分配给它们的不同的任务。 每个模块由一个或者数个并行工作的协程组成。实践中常见的工作任务包括:- 数据生成/搜集/加载;
- 数据服务/存盘;
- 数据计算/处理;
- 数据验证/过滤;
- 数据聚合/分流;
- 数据组合/拆分;
- 数据复制/增殖;
- 等等。
一个模块中的工作协程从一些其它模块接收数据做为输入,并向另一些模块发送输出数据。 换句话数,一个模块可能同时兼任数据消费者和数据产生者的角色。
多个模块一起组成了一个数据流处理系统。
下面将展示一些模块工作协程的实现。这些实现仅仅是为了解释目的,所以它们都很简单,并且它们可能并不高效。
数据生成/搜集/加载
- 加载一个文件、或者读取一个数据库、或者用爬虫抓取网页数据;
- 从一个软件或者硬件系统搜集各种数据;
- 产生一系列随机数;
- 等等。
import ( "crypto/rand" "encoding/binary" ) func RandomGenerator() <-chan uint64 { c := make(chan uint64) go func() { rnds := make([]byte, 8) for { _, err := rand.Read(rnds) if err != nil { close(c) break } c <- binary.BigEndian.Uint64(rnds) } }() return c }
事实上,此随机数产生器是一个多返回值的future/promise。
一个数据产生者可以在任何时刻关闭返回的通道以结束数据生成。
数据聚合
int64,下面这个函数将任意数量的数据流合为一个。func Aggregator(inputs ...<-chan uint64) <-chan uint64 { out := make(chan uint64) for _, in := range inputs { go func(in <-chan uint64) { for { out <- <-in // <=> out <- (<-in) } }(in) } return out }
一个更完美的实现需要考虑一个输入数据流是否已经关闭。(下面要介绍的其它工作协程同理。)
import "sync" func Aggregator(inputs ...<-chan uint64) <-chan uint64 { output := make(chan uint64) var wg sync.WaitGroup for _, in := range inputs { wg.Add(1) go func(int <-chan uint64) { defer wg.Done() // 如果通道in被关闭,此循环将最终结束。 for x := range in { output <- x } }(in) } go func() { wg.Wait() close(output) }() return output }
如果被聚合的数据流的数量很小,我们也可以使用一个select控制流程代码块来聚合这些数据流。
// 假设数据流的数量为2。 ... output := make(chan uint64) go func() { inA, inB := inputs[0], inputs[1] for { select { case v := <- inA: output <- v case v := <- inB: output <- v } } } ...
数据分流
func Divisor(input <-chan uint64, outputs ...chan<- uint64) { for _, out := range outputs { go func(o chan<- uint64) { for { o <- <-input // <=> o <- (<-input) } }(out) } }
数据合成
数据合成将多个数据流中读取的数据合成一个。
下面是一个数据合成工作函数的实现中,从两个不同数据流读取的两个uint64值组成了一个新的uint64值。 当然,在实践中,数据的组合比这复杂得多。func Composor(inA, inB <-chan uint64) <-chan uint64 { output := make(chan uint64) go func() { for { a1, b, a2 := <-inA, <-inB, <-inA output <- a1 ^ b & a2 } }() return output }
数据分解
数据复制/增殖
数据复制(增殖)可以看作是特殊的数据分解。一份输入数据将被复制多份并输出给多个数据流。
一个例子:func Duplicator(in <-chan uint64) (<-chan uint64, <-chan uint64) { outA, outB := make(chan uint64), make(chan uint64) go func() { for x := range in { outA <- x outB <- x } }() return outA, outB }
数据计算/分析
数据计算和数据分析模块的功能因具体程序不同而有很大的差异。 一般来说,数据分析者接收一份数据并对之加工处理后转换为另一份数据。
下面的简单示例中,每个输入的uint64值将被进行位反转后输出。func Calculator(in <-chan uint64, out chan uint64) (<-chan uint64) { if out == nil { out = make(chan uint64) } go func() { for x := range in { out <- ^x } }() return out }
数据验证/过滤
import "math/big" func Filter0(input <-chan uint64, output chan uint64) <-chan uint64 { if output == nil { output = make(chan uint64) } go func() { bigInt := big.NewInt(0) for x := range input { bigInt.SetUint64(x) if bigInt.ProbablyPrime(1) { output <- x } } }() return output } func Filter(input <-chan uint64) <-chan uint64 { return Filter0(input, nil) }
请注意这两个函数版本分别被本文下面最后展示的两个例子所使用。
数据服务/存盘
import "fmt" func Printer(input <-chan uint64) { for x := range input { fmt.Println(x) } }
组装数据流系统
现在,让我们使用上面的模块工作者函数实现来组装一些数据流系统。 组装数据流仅仅是创建一些工作者协程函数调用,并为这些调用指定输入数据流和输出数据流。
数据流系统例子1(一个流线型系统)package main ... // 上面的模块工作者函数实现 func main() { Printer( Filter( Calculator( RandomGenerator(), nil, ), ), ) }
上面这个流线型系统描绘在下图中:

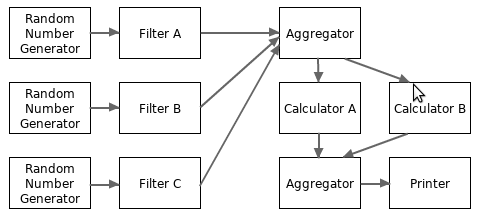
数据流系统例子2(一个单向无环图系统):
package main ... // 上面的模块工作者函数实现 func main() { filterA := Filter(RandomGenerator()) filterB := Filter(RandomGenerator()) filterC := Filter(RandomGenerator()) filter := Aggregator(filterA, filterB, filterC) calculatorA := Calculator(filter, nil) calculatorB := Calculator(filter, nil) calculator := Aggregator(calculatorA, calculatorB) Printer(calculator) }
上面这个单向无环图系统描绘在下图中:
更复杂的数据流系统可以表示为任何拓扑结构的图。比如一个复杂的数据流系统可能有多个输出模块。 但是有环拓扑结构的数据流系统在实践中很少用。
从上面两个例子可以看出,使用通道来构建数据流系统是很简单和直观的。
从上例可以看出,通过使用数据聚合模块,我们可以很轻松地实现各个模块的工作协程数量的扇入(fan-in)和扇出(fan-out)。
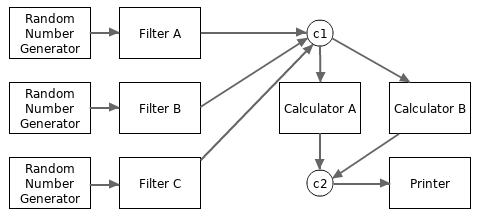
事实上,我们也可以使用一个简单的通道来代替数据聚合模块的角色。比如,下面的代码使用两个通道代替了上例中的两个数据聚合器。
package main ... // 上面的模块工作者函数实现 func main() { c1 := make(chan uint64, 100) Filter0(RandomGenerator(), c1) // filterA Filter0(RandomGenerator(), c1) // filterB Filter0(RandomGenerator(), c1) // filterC c2 := make(chan uint64, 100) Calculator(c1, c2) // calculatorA Calculator(c1, c2) // calculatorB Printer(c2) }
修改后的数据流的拓扑结构如下图所示:
上面的代码示例并没有太多考虑如何关闭一个数据流。请阅读此篇文章来了解如何优雅地关闭通道。
转载自:https://gfw.go101.org/article/channel-use-cases.html
本文来自博客园,作者:孙龙-程序员,转载请注明原文链接:https://www.cnblogs.com/sunlong88/p/13553036.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号