
Elasticsearch 篇之Search API 介绍
Search API功能
Search API 实现了对es中存储的数据进行查询分析,endpoint为 _search

第一种是对es中所有的数据进行查询
第二种是对指定的index查询
第三种是对多个index同时查询
第四种是对指定通配符的index进行查询
查询的两种形式
URI Search
操作简便,方便通过命令进行测试,仅包含部分查询语法

Request Body Search
es提供的完备查询语法 Query DSL

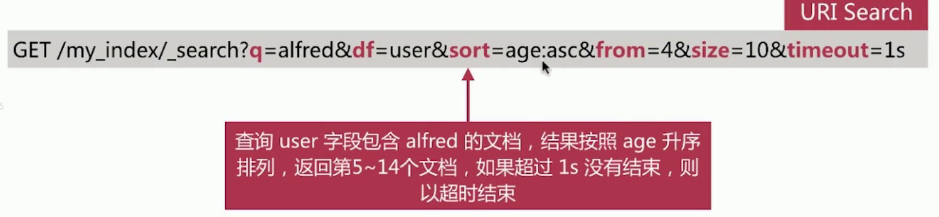
URI Search
URI Search就是通过拼接关键字来进行搜索的。
参数
q:指定查询语句,语法遵循 Query String Syntax
df:q中不指定字段时默认的查询字段,如果不指定,es会查询所有字段
sort:排序
timeout:指定超时时间,默认不超时
from,size:用于分页
Query String Syntax
查询方式


以上三种查询分别代表什么意思?
alftred way "alftred way" (alftred way)
alftred way 表示,字段包含alftred 后面是范查询(或者其它所有字段包含way)的文档
"alftred way" 表示 字段中包含alftred way的文档
(alftred way) 表示 字段中包含alftred或者包含way 不会去做范查询
实例
首先创建索引:
PUT test_search_index { "settings": { "index": { "number_of_shards": "1" } } }
创建测试文档:
POST test_search_index/doc/_bulk { "index": { "_id": "1" } } { "username": "alfred way", "job": "java enginner", "agr": 18, "birth": "1999-1-1", "isMarried": false } { "index": { "_id": "2" } } { "username": "alfred", "job": "java senior and java test", "age": 29, "birth": "1989-1-1", "isMarried": true } { "index": { "_id": "3" } } { "username": "lee", "job": "java senior and ruby test", "age": 10, "birth": "2010-1-1", "isMarried": false } { "index": { "_id": "4" } } { "username": "alfred jr way", "job": "ruby test", "age": 1, "birth": "2019-1-1", "isMarried": false }
一个泛查询:
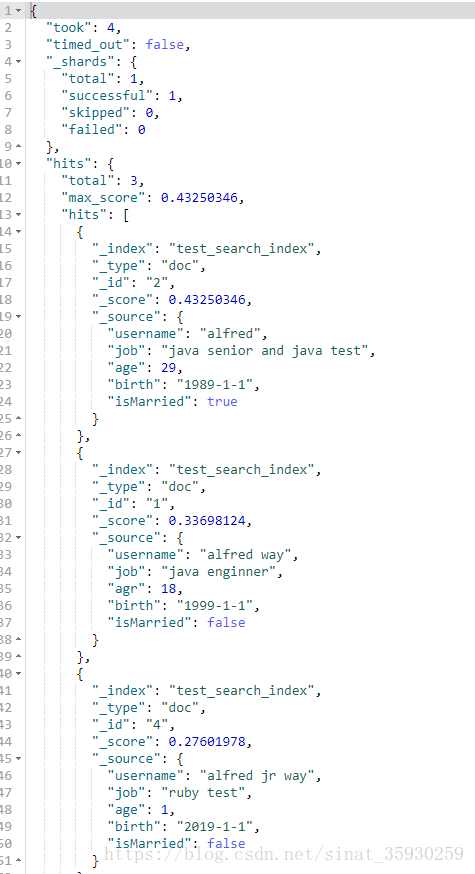
// 在所有字段中,只要包含alfred的字段的文档就返回 GET test_search_index/_search?q=alfred

查看查询语句的执行过程
GET test_search_index/_search?q=alfred { "profile": true }
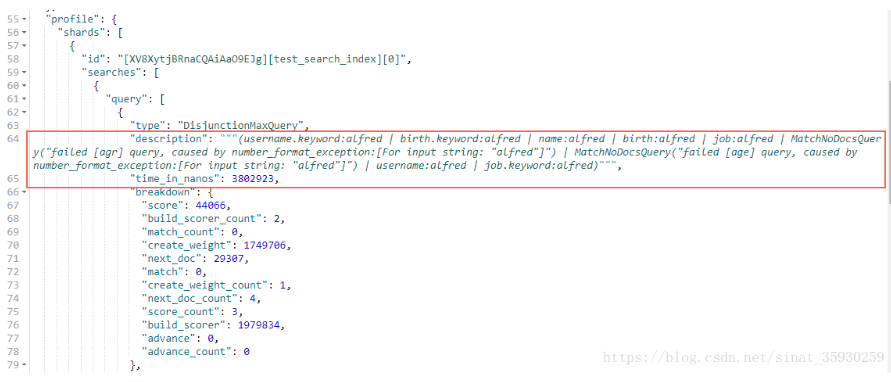
一般用来做查询语句调优
指定字段的查询
// 只返回username字段包含alfred的文档 GET test_search_index/_search?q=username:alfred
如果指定的关键字为下面的情况:
GET test_search_index/_search?q=username:alfred way
它表示返回username包含alfred或者所有字段匹配到way(后面是范查询)的文档,所以返回的结果和上面一样,通过查看具体查询过程可以看出来

词语查询
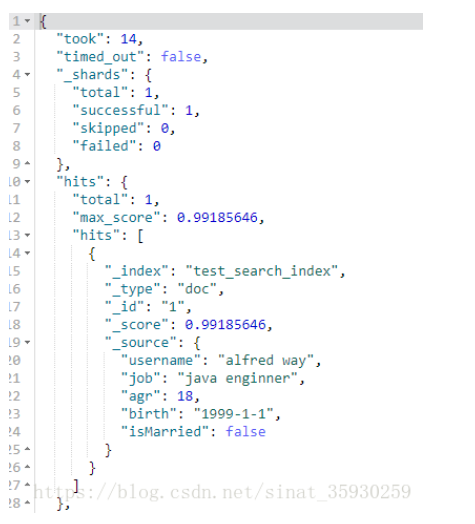
// 需要在查询的词语上添加双引号 GET test_search_index/_search?q=username:"alfred way"
组查询
// 通过添加括号表示匹配username为alfred或way字段的文档 GET test_search_index/_search?q=username:(alfred way)
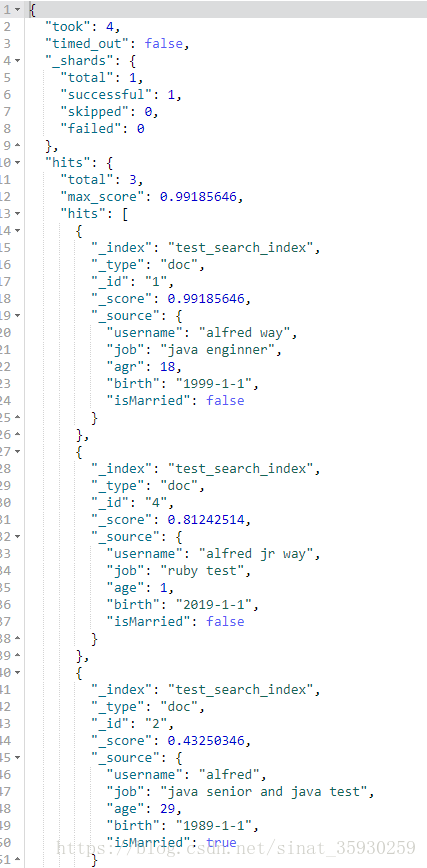
这个和之前指定字段查询的区别是,在查询中只会匹配username为alfred或username为way的字段,而不会做泛查询。

布尔查询
GET test_search_index/_search?q=username:alfred AND way
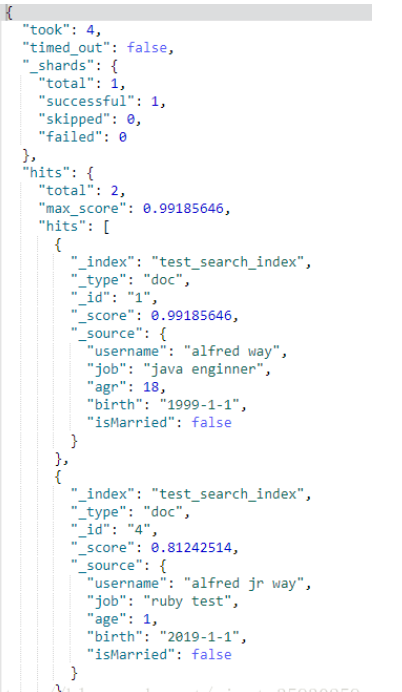
但是这样写表示返回匹配到username为alfred,泛查询全部字段匹配到way的文档。
想要返回只匹配username字段匹配到alfred和way的文档就加一个括号:
GET test_search_index/_search?q=username:(alfred AND way)
这里由于先前文档录入的时候没能体现这点的区别所以两种查询语句的结果相同,但是在实际中很大可能两种语句的查询结果是不同的。
// 返回username中不要有way但是可以由alfred的文档 GET test_search_index/_search?q=username:(alfred NOT way)

然后看一下 + 的情况:
// 返回username中可以由alfred但必须有way的文档 GET test_search_index/_search?q=username:(alfred +way)
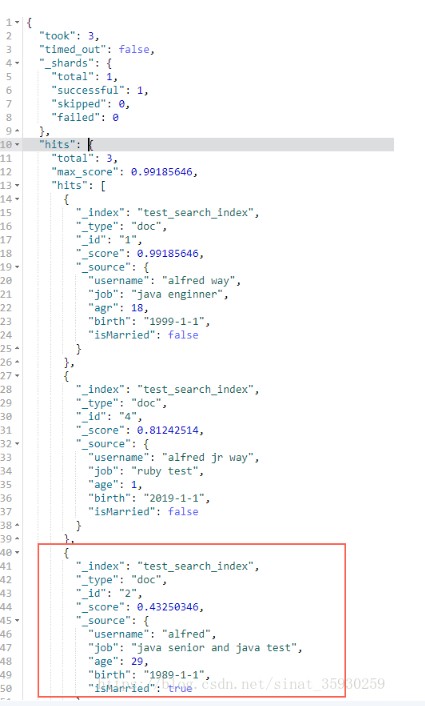
可以看到最后一个文档并不符合我们的预期,因为在html中,加号被解析为空格,所以需要使用%2B代替加号
// 返回username中可以由alfred但必须有way的文档 GET test_search_index/_search?q=username:(alfred %2Bway)


范围查询
// 查询username包含alfred或age大于20的文档 GET test_search_index/_search?q=username:alfred age:> 20

// 查询username包含alfred且age大于18的文档 GET test_search_index/_search?q=username:alfred AND age:>18

// 查询birth在1980到2000之间的文档 GET test_search_index/_search?q=birth:(>1980 AND <2000)
通配符查询

通配符查询
// 查询username以 alf来头的所有的文档 GET test_search_index/_search?q=username:alf*
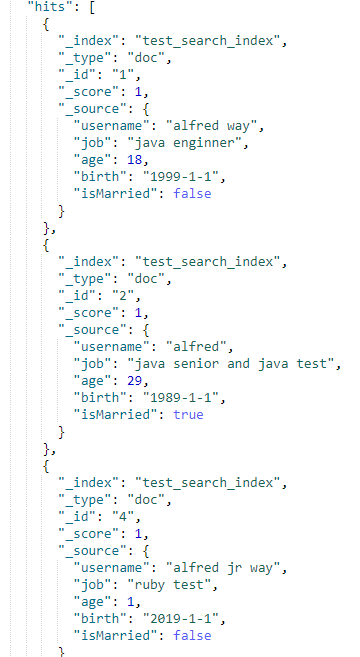
正则表达式匹配
// 匹配 [a]?l.* 这个正则匹配到的所有文档 GET test_search_index/_search?q=username:/[a]?l.*/
正则表达式匹配也比较吃内存,所以在文档数较多的时候应减少使用正则匹配
模糊匹配和相似度查询

模糊匹配和相似度查询
// 查询与alfed有N个单位偏差的文档,波浪线后边的数字表示允许偏差的个数 GET test_search_index/_search?q=username:alfed~1 GET test_search_index/_search?q=username:alfed GET test_search_index/_search?q=username:alfd~2
词语查询也可以做到相似度查询:
GET test_search_index/_search?q=job:"java test"~1

本文来自博客园,作者:孙龙-程序员,转载请注明原文链接:https://www.cnblogs.com/sunlong88/p/12833268.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号