SQL Server索引的执行计划
如何知道索引有问题,最直接的方法就是查看执行计划。通过执行计划,可以回答表上的索引是否被使用的问题。
(1)包含索引:避免书签查找
常见的索引方面的性能问题就是书签查找,书签查找分为RID查找和键值查找。
当非聚集索引被用于查找数据,但又不能覆盖查询时,就会引起书签查找。此时优化器会借助堆上的RID或者聚集索引上的聚集索引键来查找所需的额外数据,前者叫做RID,后者叫做键值查找。
书签查找就是为了找额外的列,如果数据量少并不是什么问题,但是当数据量很大,额外的列很多时,往往会带来额外的I/O开销,影响性能。
select sod.ProductID,sod.OrderQty,sod.UnitPrice from Sales.SalesOrderDetail sod where sod.ProductID=897
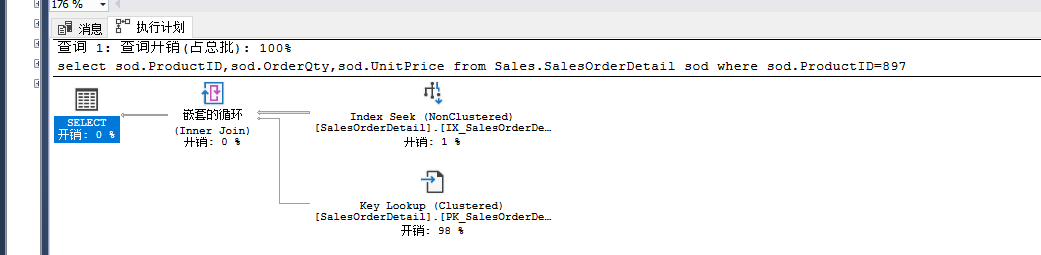
这个的性能根源----其实就是在键值查找上。对策,尽量使用查询在一个索引中完成,这一步可以通过覆盖索引和包含索引来实现。
if exists (select * from sys.indexes where object_id=OBJECT_ID(N'Sales.SalesOrderDetail') and name=N'IX_SalesOrderDetail_ProductID') drop index IX_SalesOrderDetail_ProductID on Sales.SalesOrderDetail with (online=off);
创建索引:
create nonclustered index IX_SalesOrderDetail_ProductID on Sales.SalesOrderDetail(ProductID asc) include (OrderQty,UnitPrice) with (PAD_Index=off,STATISTICS_NORECOMPUTE=off,SORT_IN_TEMPDB=off, IGNORE_DUP_KEY=off,DROP_EXISTING=off,ONLINE=off,ALLOW_ROW_LOCKS=on,ALLOW_PAGE_LOCKS=ON) ON [PRIMARY];
再次执行上述语句,执行计划如下:

逻辑读从1240下降到3次,是一个很大的提升,从实践来说,书签查找是常见的性能问题标志,当出现这个操作符,且百分比相对较高时,就必须分析是否有必要调整优化。
(2)索引选择度
对于每个索引,优化器都会自定创建统计信息来描述这个索引的数据分布情况。在后续的使用中,优化器会根据这些统计信息来决定查询是否使用这些索引。
通过以下语句可以查看统计信息:
dbcc show_Statistics('Sales.SalesOrderDetail','IX_SalesOrderDetail_ProductID')
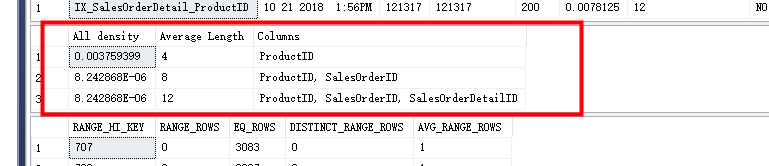
这个索引上的ProductID的密度为0.0037593999,是非常低的值也就是选择度很高,最优可能被使用,而其他两行是聚集索引的列,由于非聚集索引的叶子节点会指向聚集索引键,这里的统计信息会包含这两列,并同时给出对应的密度。如果表上没有聚集索引,那么非聚集索引会指向数据本身。如果选择度很低,优化器会放弃索引。
select sod.OrderQty,sod.SalesOrderID, sod.SalesOrderDetailID,sod.LineTotal from Sales.SalesOrderDetail sod where sod.OrderQty=10;

优化器使用了聚集索引扫描来实现WHERE条件的筛选操作。对这个列加上索引。
create nonclustered Index IX_SalesOrderDetail_OrderQty on Sales.SalesOrderDetail(orderQty asc) with (PAD_Index=off,STATISTICS_NORECOMPUTE=off,SORT_IN_TEMPDB=off, IGNORE_DUP_KEY=off,DROP_EXISTING=off,ONLINE=off,ALLOW_ROW_LOCKS=on,ALLOW_PAGE_LOCKS=ON) on [Primary]
查看统计信息:
dbcc SHOW_STATISTICS('Sales.SalesOrderDetail','IX_SalesOrderDetail_OrderQty')
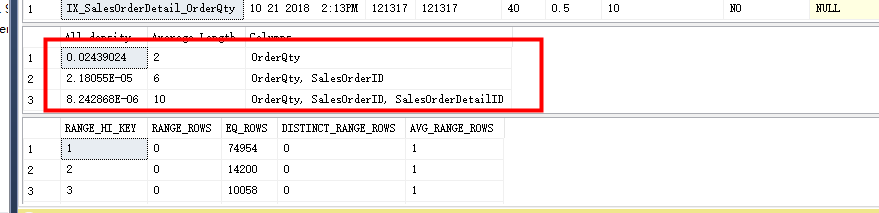
这个选择度不高,如果再次执行查询语句,可以看到执行计划中依旧会使用原有计划。

如果选择度不高,优化器依旧会放弃上面的索引。
删除新建的索引:
drop index Sales.SalesOrderDetail.IX_SalesOrderDetail_OrderQty
(3)统计信息和索引
优化器会对每个索引创建统计信息,如果统计信息过时,优化器同样可能不选择“有用索引”。
if EXISTS (select * from sys.objects where object_id=OBJECT_ID('N[NewOrders]') and type in (N'U'))
drop table[NewOrders]
go
select * into NewOrders from Sales.SalesOrderDetail
go
create index IX_NewOrders_ProductID on NewOrders(ProductID)
使用一个简答的查询生成预估执行计划,接着在事物中更新数据,影响ProductID列上的数据分布,让其选择度变低。最后获取实际执行计划。
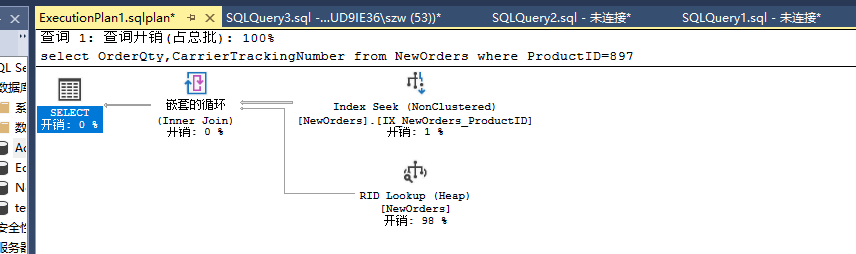
set showplan_xml on go select OrderQty,CarrierTrackingNumber from NewOrders where ProductID=897 go set showplan_xml off
预估执行计划:
begin tran update NewOrders set ProductID=897 where ProductID between 800 and 900 --实际的执行计划 set statistics xml on go select OrderQty,CarrierTrackingNumber from NewOrders where ProductID=897 rollback tran go set statistics xml off
实际执行计划:
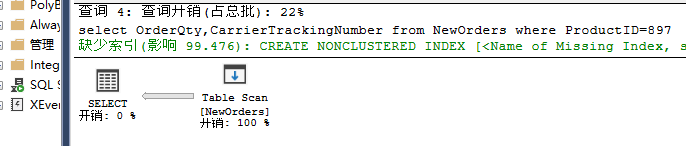
由于统计信息得变更,优化器对同一个查询选择不同的执行计划。更新操作使得列上的数据分布发生改变,选择度降低,优化器会“觉得”使用扫描操作时开销更低。因此,确保统计信息得实时性及有效性对性能的提升非常重要。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号