SQLServer 表连接种类
SQLServer 有3种物理连接:Nested Loop(嵌套循环)、Merge Join(合并联接)、Hash Join(哈希联接)。
T-SQL中的inner/left/right/full join等在进行优化的过程中会转换成上面3种物理连接。
1.Nested Loop(嵌套循环)
SELECT e.BusinessEntityID FROM HumanResources.Employee AS e INNER JOIN Sales.SalesPerson AS s ON e.BusinessEntityID =s.BusinessEntityID
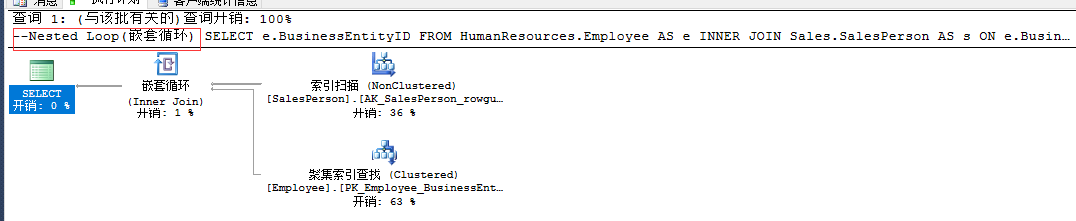
处于上方的输入叫做外部输入,处于下方的输入叫做内部输入,SalesPerson为外部输入,Employee为内部输入
外部循环逐行处理外部输入表,内部循环会针对每个外部行在内部输入表中进行搜索,已找出匹配行
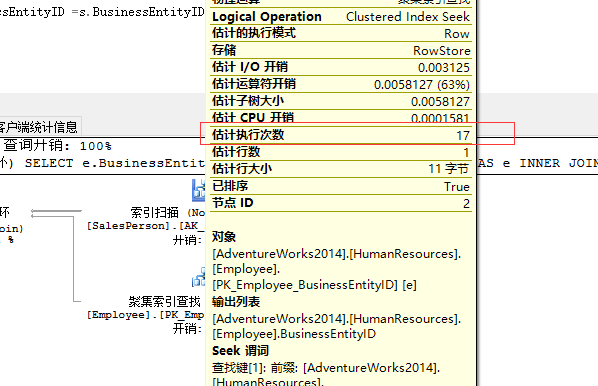
通过聚集索引查找,返回17行数据,也就是说外部输入要进行17次匹配。
当外部连接很小,并且内部连接在连接列上有索引时,优化器会倾向使用这种算法。
2.Merge Join(合并连接)
SELECT s.Name FROM sales.store AS s
JOIN sales.Customer AS c
ON s.BusinessEntityID =c.CustomerID
WHERE c.TerritoryID=6
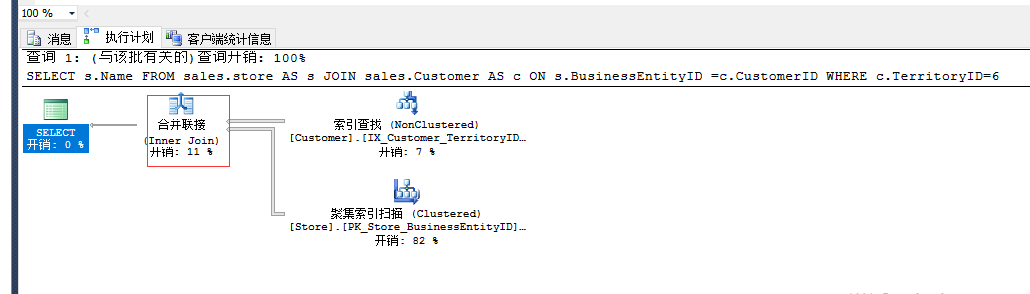
合并链接也分为外部输入和内部输入,外部输入和内部输入只会执行一次。合并联接要求两个输入都在合并列上排序,而合并列由联接谓词的等效(on)子句定义。
合并联接本身的速度很快,但如果需要排序操作,选择合并联接就会非常费时,然而,数据量很大且能够从现有B树索引中获得预排序的所需数据,则合并联接通常最快
的可用联接算法。
3.Hash Join(哈希联接)
SELECT pv.ProductID,v.BusinessEntityID,v.Name FROM Purchasing.ProductVendor pv JOIN Purchasing.Vendor v ON (pv.BusinessEntityID=v.BusinessEntityID) WHERE pv.StandardPrice >$10
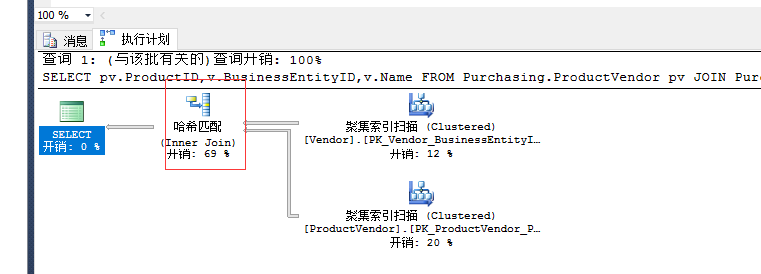
哈希联接有两种输入:生成输入和探测输入。查询优化器使用两个输入中较小的那个作为生成输入
用于多种设置匹配操作:内部联接、左外部联接、右外部联接、和完全外部联接,左半联接、和右半联接,交集、并集和差异。某种变形可以进行重复删除和分组。
二:数据访问操作:
1.扫描操作将针对整个结构来进行,可能是一个堆表、一个聚集索引、和一个非聚集索引。
2.查找操作是从索引中查找所需的数据,不需要扫描整个结构,只发生在聚集索引和非聚集索引上。
堆表:表扫描、不存在查找
聚集索引:聚集索引扫描、聚集索引查找
非聚集索引:索引扫描、索引查找
1.扫描(堆表)
SELECT * FROM dbo.DatabaseLog
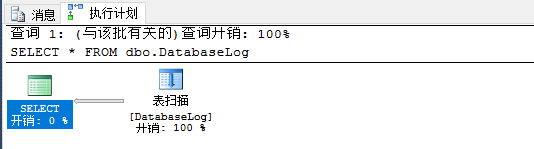
2.聚集索引扫描
SELECT * FROM Person.Address
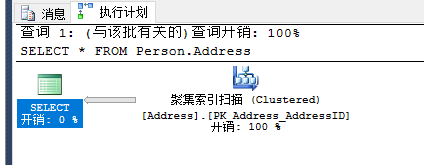
3.非聚集索引扫描(索引扫描)
SELECT AddressID,City,StateProvinceID FROM Person.Address
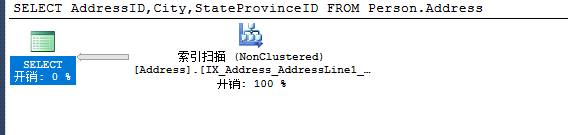
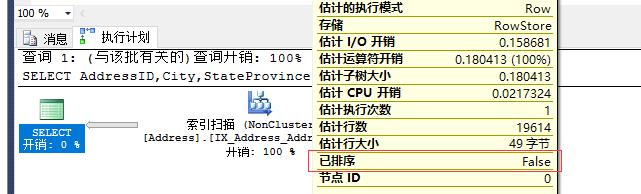
想知道数据是否有排序,可以看加框部分,它为true证明数据已经排序
二:查找(堆表上不存在查找操作,所以查找操作特指索引的操作)
查找操作不需要扫描整个索引,它是通过B-Tree结构来快速定位所需的数据
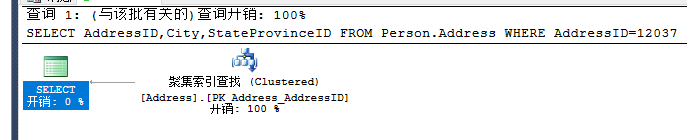
聚集索引查找
SELECT AddressID,City,StateProvinceID FROM Person.Address WHERE AddressID=12037
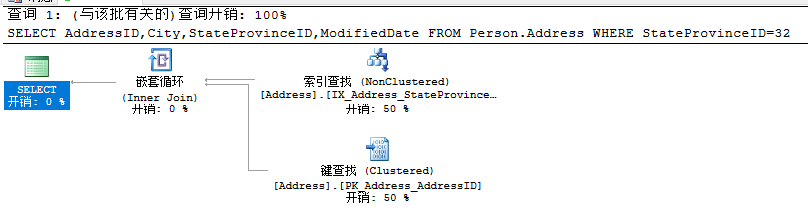
非聚集索引扫描:
SELECT AddressID,StateProvinceID FROM Person.Address WHERE StateProvinceID=32

3.书签(键)查找
一个非聚集索引被优化器选为访问数据的索引,但是这个索引不能覆盖所有的列,导致非聚集索引必须借助聚集索引键或者堆上的RID来定位其他数据
SELECT AddressID,City,StateProvinceID,ModifiedDate FROM Person.Address WHERE StateProvinceID=32
键值查找操作符的tooltips:
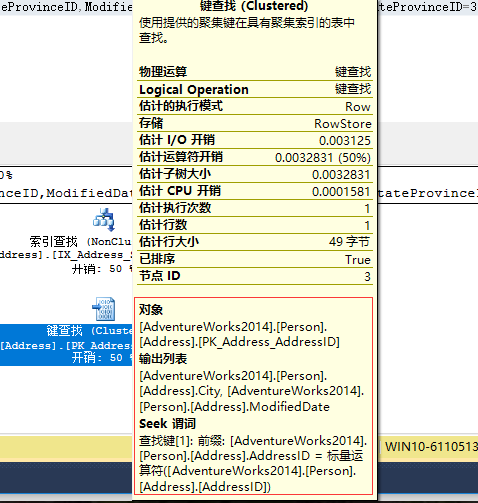
键查找(Key Lookup属于书签查找的一种)由于AddressID不包含在非聚集索引中,查询又需要用到它,所以需要通过聚集索引来获取相关的数据。
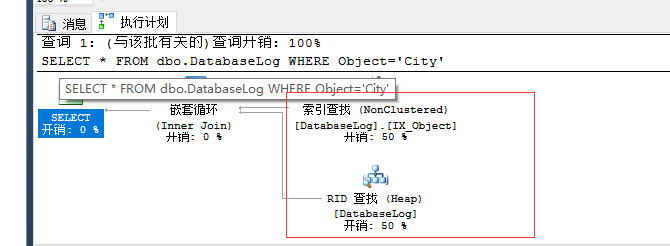
如果表上没有相关的聚集索引,会出现RID查找,RID Lookup和Key Lookup统称为书签查找。
不能覆盖查询的非聚集索引,所以创建了一个非聚集索引在堆表上,以便进行查询
--创建非聚集索引
CREATE INDEX IX_Object ON dbo.DatabaseLog(Object)
--RID
SELECT * FROM dbo.DatabaseLog WHERE Object='City'
三:聚合操作:
有两种操作实现聚合:流聚合(Stream Aggregate)和哈希聚合(Hash Aggregate)
1.排序和哈希
2.流聚合
指使用了聚合函数,但没有Group By子句并返回一个单一值的查询。
如果带有聚合函数,但没有Group By子句,叫做标量聚合。标量聚合由流聚合操作来返回一个数据。
SELECT AVG(ListPrice) FROM Production.Product

--带有Group By的聚合
SELECT ProductLine,COUNT(*) FROM Production.Product GROUP BY ProductLine

3.Hash聚合
在执行计划中以Hash Match作为物理操作符,当优化器发现一个没有排序的大表需要聚合,预估只有少量的组时,就会选择Hash聚合
SELECT TerritoryID,COUNT(*) FROM sales.SalesOrderHeader GROUP BY TerritoryID

哈希聚合是针对未排序的数据,一旦加上索引,是可以转换成流聚合的。
CREATE INDEX IX_ContactID ON Sales.SalesOrderHeader(TerritoryID) SELECT TerritoryID,COUNT(*) FROM Sales.SalesOrderHeader GROUP BY TerritoryID

四:检查统计对象
可以通过sys.stats目录视图来查看某个对象的统计信息
SELECT * FROM sys.stats WHERE object_id=OBJECT_ID('Sales.SalesOrderDetail')
也可以用DBCC SHOW_STATISRICS命令来显示某列上的统计信息
DBCC SHOW_STATISTICS('Sales.SalesOrderDetail',UnitPrice)

只需要用以下这个列:
SELECT * FROM sales.SalesOrderDetail WHERE UnitPrice=35
再次执行:
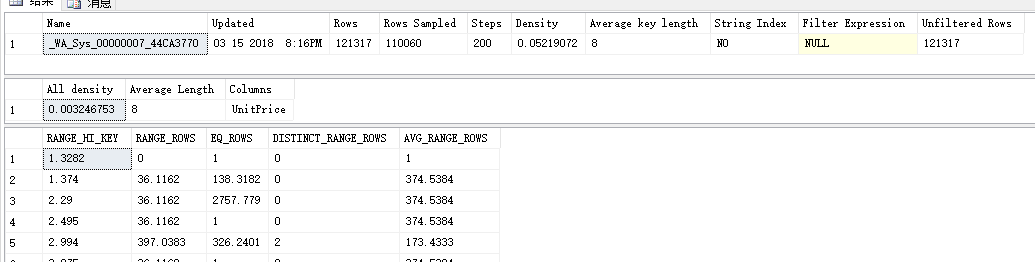
检查一个非聚集索引上的统计信息,只关注密度信息部分:
DBCC SHOW_STATISTICS('Sales.SalesOrderDetail',IX_SalesOrderDetail_ProductID)
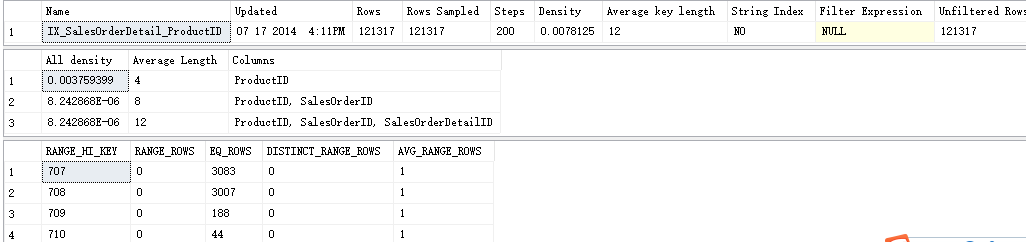
手工计算密度矢量:
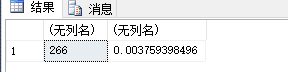
SELECT COUNT (DISTINCT ProductID) ,1.0/COUNT (DISTINCT ProductID) FROM Sales.SalesOrderDetail
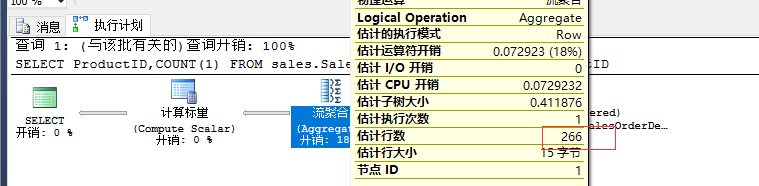
执行以下语句,看看执行计划中是否真的使用了266行预估行数
SELECT ProductID,COUNT(1) FROM sales.SalesOrderDetail GROUP BY ProductID
使用以下语句查看对象的统计信息情况:
SELECT name,auto_created,STATS_DATE(object_id,stats_id) AS update_date
FROM sys.stats WHERE object_id=OBJECT_ID(N'表名')
重建索引:
ALTER INDEX ix_ProductID ON dbo.SalesOrderDetail REBUILD
计算列:
SELECT * FROM sales.SalesOrderDetail WHERE OrderQty * UnitPrice>10000
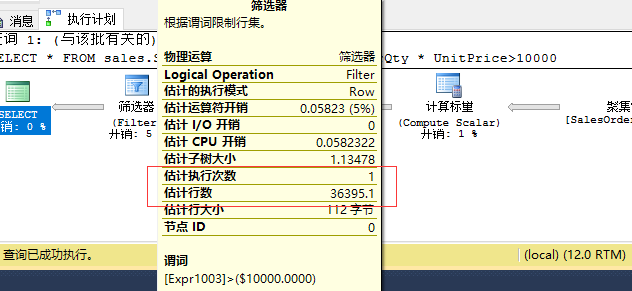
创建一个计算列:
ALTER TABLE sales.SalesOrderDetail ADD cc AS OrderQty * UnitPrice
重新运行上面的语句,预估行数和实际函数相对较接近:
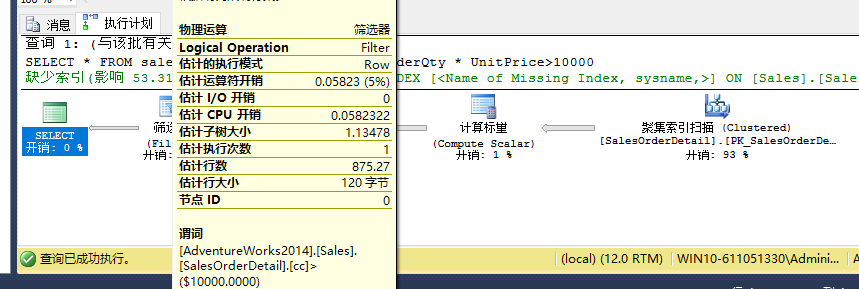
删除上述列:
ALTER TABLE sales.SalesOrderDetail DROP COLUMN cc
4.过滤索引上的统计信息
这种统计信息不是全表创建的,而是针对一个表的子集创建的,当创建过滤索引时,会自动创建对应的统计信息。
SELECT * FROM Person.Address WHERE City='Los Angeles'
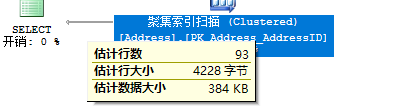
SELECT * FROM Person.Address WHERE StateProvinceID=9
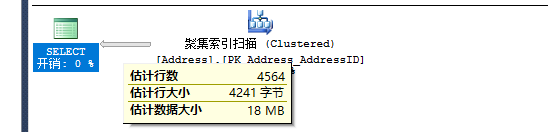
两个查询的预估行数和实际行数是一样的。
组合Where条件之后的执行计划:
SELECT * FROM person.Address WHERE City='Los Angeles' AND StateProvinceID=9
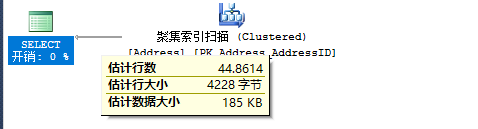
SQL Server 首先把两个查询的结果集行数相乘,然后 除以表中的总行数。
提高预估的准确性,可以创建一个统计信息
CREATE STATISTICS California ON Person.Address(City) WHERE StateProvinceID=9
清空缓存,执行查询语句:
DBCC FREEPROCCACHE
GO
SELECT * FROM person.Address WHERE City='Los Angeles' AND StateProvinceID=9
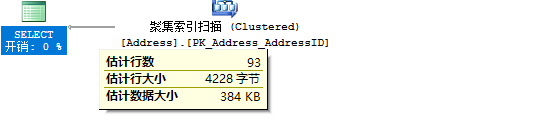
只返回头信息的方法查询:
DBCC SHOW_STATISTICS('Person.Address',California)
WITH stat_header

也可以用下面的语句进行查询:
SELECT * FROM sys.stats WHERE filter_definition IS NOT NULL

六: 预估数据错误:
错误预估行数会导致优化器不合适的执行计划影响性能,可以通过检查执行计划发现。
SET STATISTICS PROFILE ON
GO
SELECT * FROM Sales.SalesOrderDetail
WHERE OrderQty * UnitPrice >10000
GO
SET STATISTICS PROFILE OFF
七:优化器工作过程
工作过程:简化、简单计划优化和完整计划优化
1.简化,在这个阶段,查询会被重写,一些逻辑写法会被重写成优化器能读懂的内容
(一):子查询会被转换成join
(二):多余的inner/outer join会被移除
(三):Where条件中的筛选部分会被处理
SELECT pp.ProductID--,ppc.Name FROM Production.Product pp INNER JOIN production.ProductSubcategory pps ON pps.ProductSubcategoryID=pp.ProductSubcategoryID INNER JOIN Production.ProductCategory ppc ON ppc.ProductCategoryID =pps.ProductCategoryID
去掉注释和不去注释分别执行,查看执行计划,注释了一个字段,会少一个表关联。
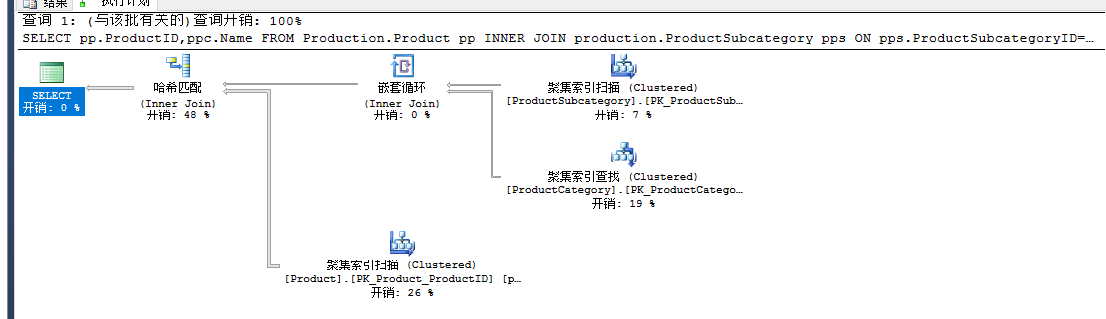

禁用外键:
ALTER TABLE Production.ProductSubcategory NOCHECK CONSTRAINT FK_ProductSubcategory_ProductCategory_ProductCategoryID

因为外键的作用消失,所以需要引入第三个表
恢复外键
ALTER TABLE Production.ProductSubcategory WITH CHECK CHECK CONSTRAINT FK_ProductSubcategory_ProductCategory_ProductCategoryID
2.简单计划优化
3.完整计划优化

 浙公网安备 33010602011771号
浙公网安备 33010602011771号