SqlServer性能优化分割提升性能分布式视图(七)
分布式视图:
1.将大表分割到多个服务器上存储
2.物理上与逻辑上都存在多个表
3.通过视图实现对分布到多个服务器表进行访问
4.整合网络负载平衡
链接两台数据库:
建立同样的数据结构:
create table Sales(c1 int not null,c2 int) alter table Sales add constraint pk_Sales_c1 primary key (c1) alter table Sales add constraint ck_Sales_c1 check(c1 between 1 and 100)
--后一太数据库 101---200
点击新建链接服务器:
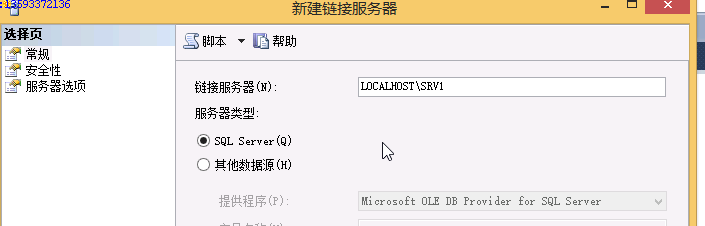
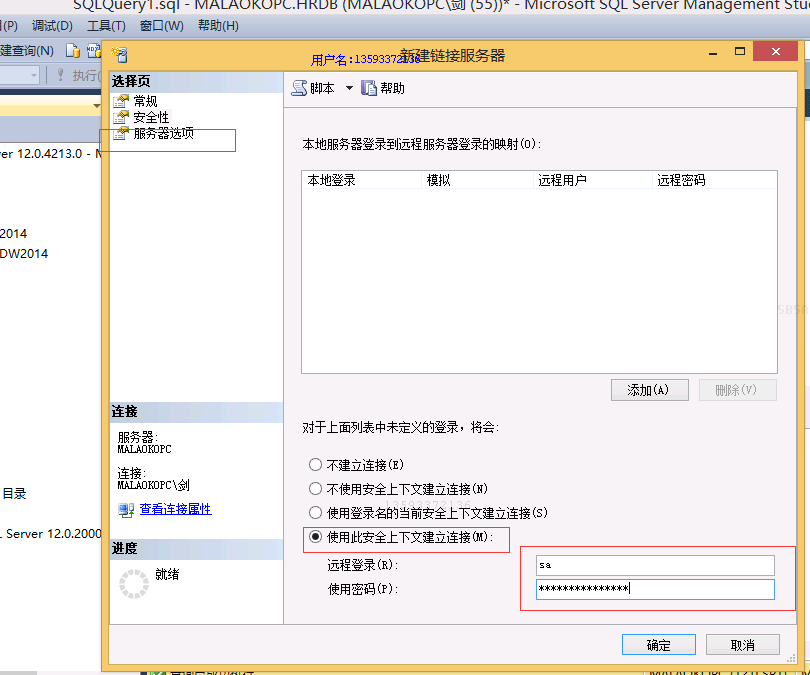
创建视图:
create view v_sales as select * from Sales union all select * from [localhost\Src1] HRDB.dbo.Sales
在第二台服务器上建立与第一台服务器的链接 和上面的步骤一样
执行下面的语句:
insert v_sales values (2,2) insert v_sales values(200,200)
报错:(保证分布式事物可用)
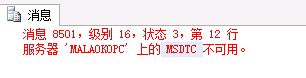
开启:

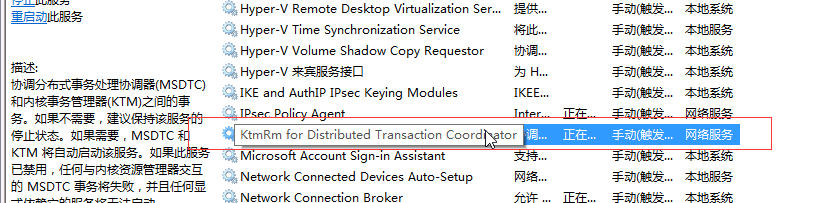

在次执行报错:

改成这样:
set xact_abort on insert v_sales values (2,2) insert v_sales values(200,200)
执行下面的语句:
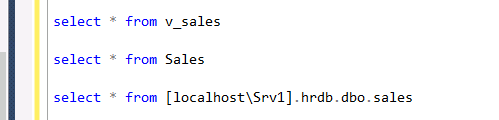
结果如下:
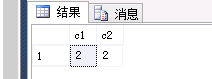
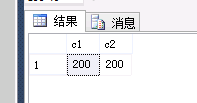
执行下面的更新语句:

第一台服务器没有全在第二台服务器上:
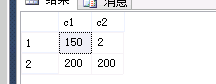
由此可见:分布式视图可以有效的解决系统性能问题,将大表不同的记录范围---分在不同的服务器上,然后通过视图进行表的操作,有效的平衡服务器负载的流量
分割提升数据的访问:
数据的放置:
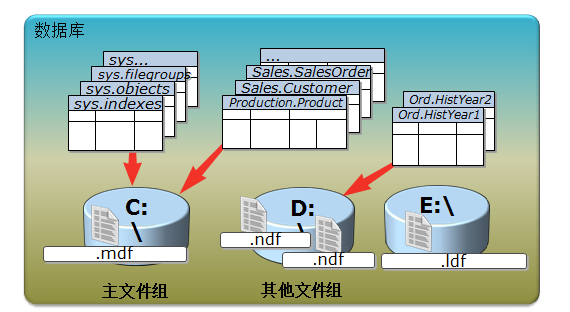
1.数据放置的原则:
1.在不同的无力磁盘或RAID上创建文件组
2.将常用的连接查询中的表放置到不同的文件组
3.将访问频繁的大表放置到不同的文件组
4.日志文件存放在单独的磁盘
5.将Tempdb数据库放置到快速的磁盘或RAID上
创建分区函数:
create partition function fn_SalesOrderdetial (int) as range left for values(10000,50000)
创建文件组:
alter database HRDB add filegroup fg1 alter database HRDB add filegroup fg2 alter database HRDB add filegroup fg3
指定关联:
alter database HRDB add file ( name='data1', filename='e:\data1.ndf' )to filegroup fg1 alter database HRDB add file ( name='data2', filename='e:\data2.ndf' )to filegroup fg2 alter database HRDB add file ( name='data3', filename='f:\data1.ndf' )to filegroup fg3
创建分区方案:
--创建分区方案 create partition scheme sch_SalesOrderDetail --使用的分区函数 as partition fn_SalesOrderdetial --放入的文件夹 to(fg1,fg2,fg3)
插入表数据:
insert into SalesOrderDetail(OrderDetailID, UnitPrice,Qry ) select SalesOrderDetailID,UnitPrice,OrderQty from OrderDetail
查询:
set statistics io on select OrderDetailID,UnitPrice,Qry from SalesOrderDetail where UnitPrice>200 --0.419 set statistics io off

创建索引:
create nonclustered index nc_Salesorderdetail_UnitPrice on
SalesOrderDetail(UnitPrice ) include (OrderDetailID,Qry)
再次执行:
set statistics io on select OrderDetailID,UnitPrice,Qry from SalesOrderDetail where UnitPrice>200 --0.193 set statistics io off

加上条件:
set statistics io on select OrderDetailID,UnitPrice,Qry from SalesOrderDetail where UnitPrice>200 and OrderDetailID=6000 --0.07 set statistics io off

创建另外一个非聚集索引对OrderDetailID进行物理排序:
create nonclustered index nc_SalseOrderDetail_OrderDetaillID on SalesOrderDetail(OrderDetailID) include(unitprice,Qry)
执行:
set statistics io on select OrderDetailID,UnitPrice,Qry from SalesOrderDetail where UnitPrice>200 and OrderDetailID=6000 --0.07 set statistics io off


 浙公网安备 33010602011771号
浙公网安备 33010602011771号