
Oracle学习笔记(十一)索引
索引的结构图:

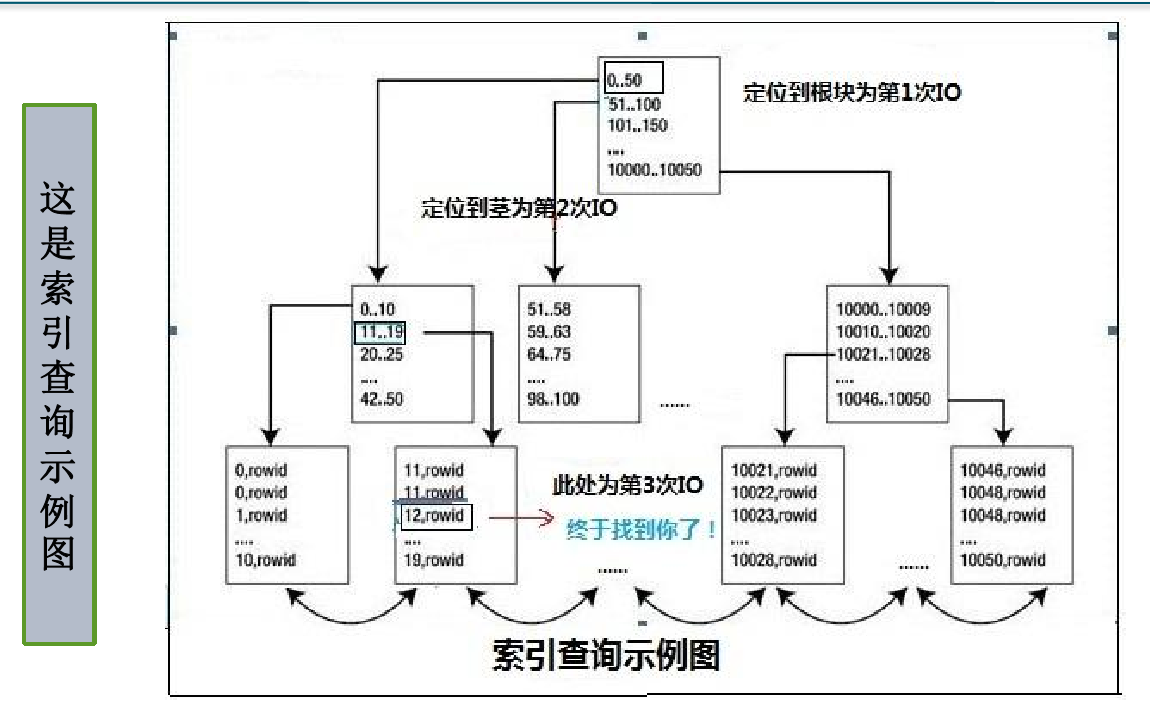
索引查询示例图:
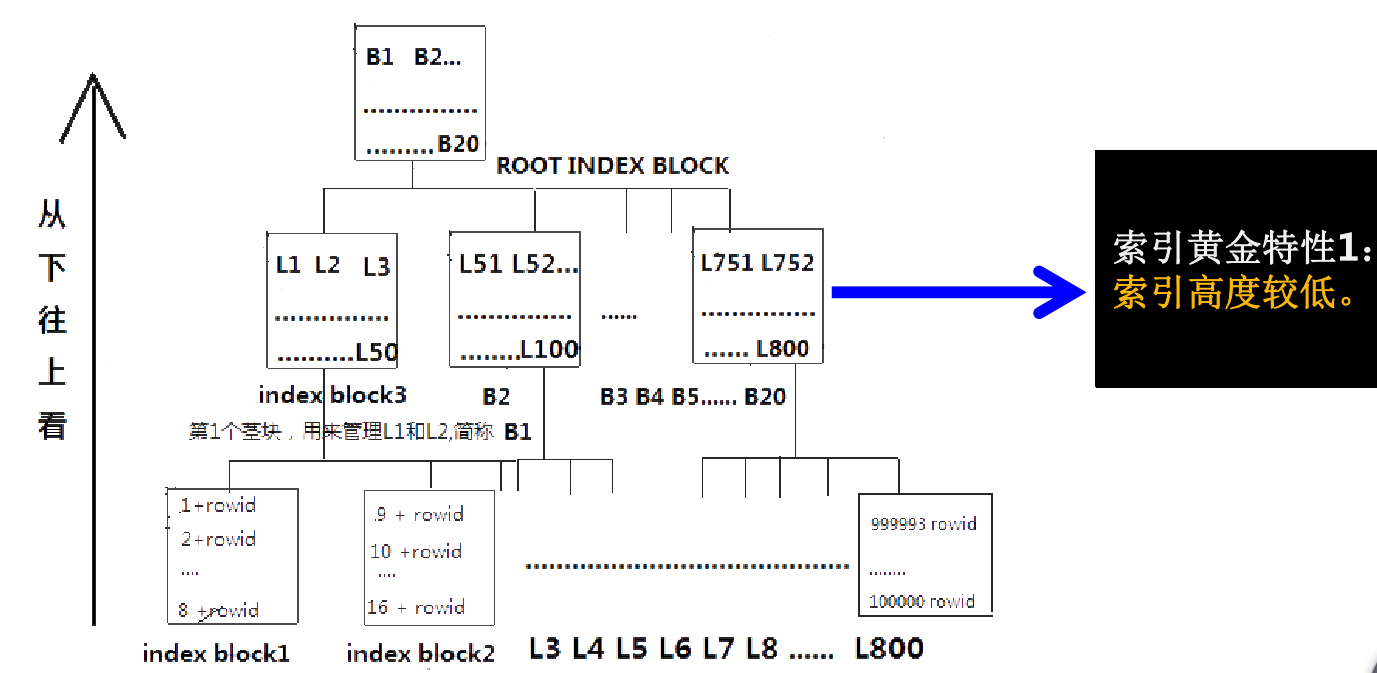
索引的特性:
1.索引高度比较低.
索引特性之高度较低的验证体会
drop table t1 purge;
drop table t2 purge;
drop table t3 purge;
drop table t4 purge;
drop table t5 purge;
drop table t6 purge;
drop table t7 purge;
create table t1 as select rownum as id ,rownum+1 as id2,rpad('*',1000,'*') as contents from dual connect by level<=1;
create table t2 as select rownum as id ,rownum+1 as id2,rpad('*',1000,'*') as contents from dual connect by level<=10;
create table t3 as select rownum as id ,rownum+1 as id2,rpad('*',1000,'*') as contents from dual connect by level<=100;
create table t4 as select rownum as id ,rownum+1 as id2,rpad('*',1000,'*') as contents from dual connect by level<=1000;
create table t5 as select rownum as id ,rownum+1 as id2,rpad('*',1000,'*') as contents from dual connect by level<=10000;
create table t6 as select rownum as id ,rownum+1 as id2,rpad('*',1000,'*') as contents from dual connect by level<=100000;
create table t7 as select rownum as id ,rownum+1 as id2,rpad('*',1000,'*') as contents from dual connect by level<=1000000;
create index idx_id_t1 on t1(id);
create index idx_id_t2 on t2(id);
create index idx_id_t3 on t3(id);
create index idx_id_t4 on t4(id);
create index idx_id_t5 on t5(id);
create index idx_id_t6 on t6(id);
create index idx_id_t7 on t7(id);
set linesize 1000
set autotrace off
select index_name,
blevel,
leaf_blocks,
num_rows,
distinct_keys,
clustering_factor
from user_ind_statistics
where table_name in( 'T1','T2','T3','T4','T5','T6','T7');
INDEX_NAME BLEVEL LEAF_BLOCKS NUM_ROWS DISTINCT_KEYS CLUSTERING_FACTOR
------------------ ----------- ---------- ------------- -----------------
IDX_ID_T1 0 1 1 1 1
IDX_ID_T2 0 1 10 10 2
IDX_ID_T3 0 1 100 100 15
IDX_ID_T4 1 3 1000 1000 143
IDX_ID_T5 1 21 10000 10000 1429
IDX_ID_T6 1 222 100000 100000 14286
IDX_ID_T7 2 2226 1000000 1000000 142858
索引特性之高度较低是优化利器
drop table t1 purge;
drop table t2 purge;
drop table t3 purge;
drop table t4 purge;
drop table t5 purge;
drop table t6 purge;
drop table t7 purge;
create table t1 as select rownum as id ,rownum+1 as id2,rpad('*',1000,'*') as contents from dual connect by level<=1;
create table t2 as select rownum as id ,rownum+1 as id2,rpad('*',1000,'*') as contents from dual connect by level<=10;
create table t3 as select rownum as id ,rownum+1 as id2,rpad('*',1000,'*') as contents from dual connect by level<=100;
create table t4 as select rownum as id ,rownum+1 as id2,rpad('*',1000,'*') as contents from dual connect by level<=1000;
create table t5 as select rownum as id ,rownum+1 as id2,rpad('*',1000,'*') as contents from dual connect by level<=10000;
create table t6 as select rownum as id ,rownum+1 as id2,rpad('*',1000,'*') as contents from dual connect by level<=100000;
create table t7 as select rownum as id ,rownum+1 as id2,rpad('*',1000,'*') as contents from dual connect by level<=1000000;
create index idx_id_t1 on t1(id);
create index idx_id_t2 on t2(id);
create index idx_id_t3 on t3(id);
create index idx_id_t4 on t4(id);
create index idx_id_t5 on t5(id);
create index idx_id_t6 on t6(id);
create index idx_id_t7 on t7(id);
set linesize 1000
select index_name,
blevel,
leaf_blocks,
num_rows,
distinct_keys,
clustering_factor
from user_ind_statistics
where table_name in( 'T1','T2','T3','T4','T5','T6','T7');
INDEX_NAME BLEVEL LEAF_BLOCKS NUM_ROWS DISTINCT_KEYS CLUSTERING_FACTOR
------------------ ----------- ---------- ------------- -----------------
IDX_ID_T1 0 1 1 1 1
IDX_ID_T2 0 1 10 10 2
IDX_ID_T3 0 1 100 100 15
IDX_ID_T4 1 3 1000 1000 143
IDX_ID_T5 1 21 10000 10000 1429
IDX_ID_T6 1 222 100000 100000 14286
IDX_ID_T7 2 2226 1000000 1000000 142858
set autotrace traceonly statistics
set linesize 1000
--以下注意观察逻辑读的次数,另外注意尽量每条语句执行2遍以上,观察第2遍的结果。
select * from t1 where id=1;
统计信息
-----------------------------------------
0 recursive calls
0 db block gets
2 consistent gets
select /*+full(t1)*/ * from t1 where id=1;
统计信息
-------------------------------
0 recursive calls
0 db block gets
3 consistent gets
select * from t2 where id=1;
统计信息
-----------------------------
0 recursive calls
0 db block gets
3 consistent gets
select /*+full(t2)*/ * from t2 where id=1;
统计信息
-----------------------------
0 recursive calls
0 db block gets
5 consistent gets
select * from t3 where id=1;
统计信息
-----------------------------
0 recursive calls
0 db block gets
3 consistent gets
select /*+full(t3)*/ * from t3 where id=1;
统计信息
----------------------------
0 recursive calls
0 db block gets
19 consistent gets
select * from t4 where id=1;
统计信息
-----------------------------
0 recursive calls
0 db block gets
4 consistent gets
select /*+full(t4)*/ * from t4 where id=1;
统计信息
----------------------------
0 recursive calls
0 db block gets
148 consistent gets
select * from t5 where id=1;
统计信息
------------------------------
0 recursive calls
0 db block gets
4 consistent gets
select /*+full(t5)*/ * from t5 where id=1;
统计信息
-----------------------------
0 recursive calls
0 db block gets
1435 consistent gets
select * from t6 where id=1;
统计信息
-----------------------------
0 recursive calls
0 db block gets
4 consistent gets
select /*+full(t6)*/ * from t6 where id=1;
统计信息
-----------------------------
0 recursive calls
0 db block gets
14298 consistent gets
select * from t7 where id=1;
统计信息
-----------------------------
0 recursive calls
0 db block gets
5 consistent gets
select /*+full(t7)*/ * from t7 where id=1;
统计信息
-----------------------------
0 recursive calls
0 db block gets
142866 consistent gets
/*
规律:
从t1到t7(表记录依次增大10倍,从1到1000000),索引读的逻辑读是 2,3,3,4,4,4,5
从t1到t7(表记录依次增大10倍,从1到1000000)全表扫描的逻辑读是 3,5,19,148,1435,14298,142866
full(表)的目的是 括号里的表将会使用全表扫描
*/
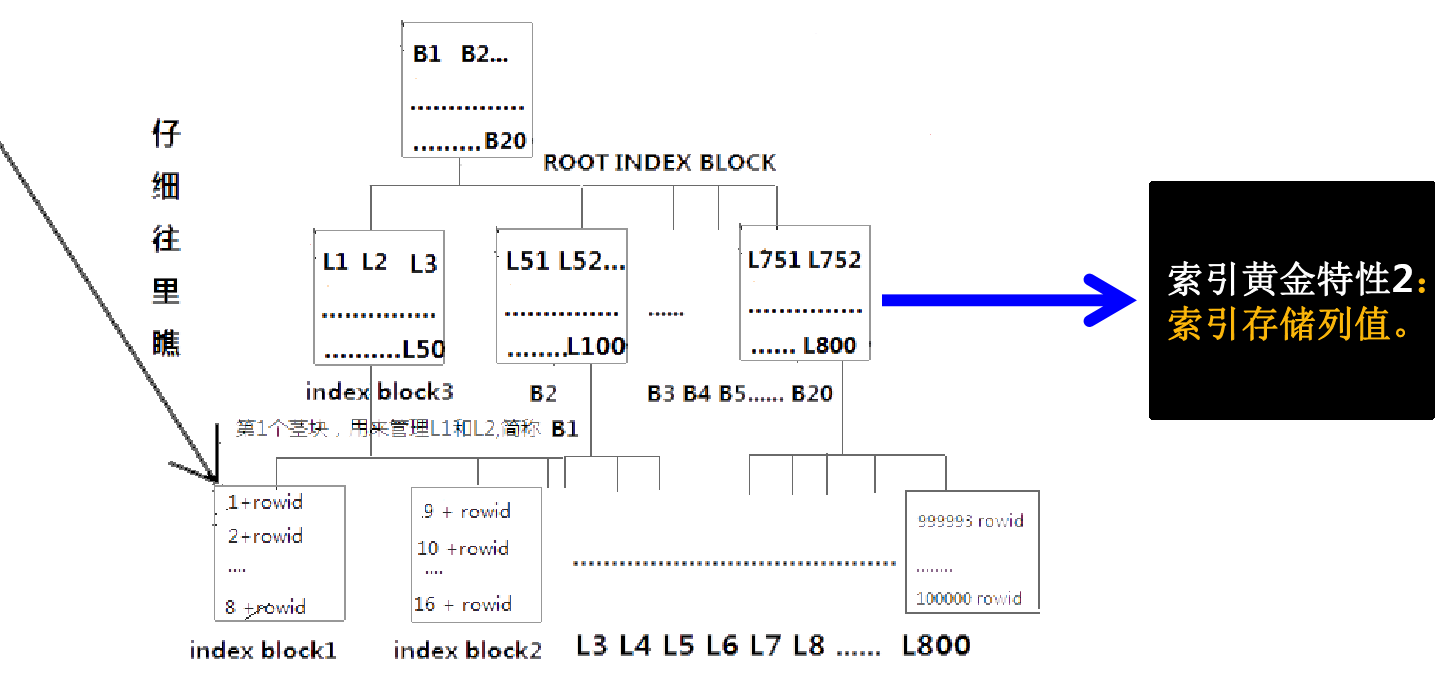
索引特性之存列值优化count:
--要领:只要索引能回答问题,索引就可以当成一个"瘦表",访问路径就会减少。另外切记不存储空值
drop table t purge;
create table t as select * from dba_objects;
update t set object_id=rownum;
commit;
create index idx1_object_id on t(object_id);
set autotrace on
select count(*) from t;
执行计划
-------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
-------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 292 (1)| 00:00:04 |
| 1 | SORT AGGREGATE | | 1 | | |
| 2 | TABLE ACCESS FULL| T | 69485 | 292 (1)| 00:00:04 |
-------------------------------------------------------------------
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
1048 consistent gets
--为啥用不到索引,因为索引不能存储空值,所以加上一个is not null,再试验看看
select count(*) from t where object_id is not null;
执行计划
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 50 (2)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 13 | | |
|* 2 | INDEX FAST FULL SCAN| IDX1_OBJECT_ID | 69485 | 882K| 50 (2)| 00:00:01 |
----------------------------------------------------------------------------------------
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
170 consistent gets
--也可以不加is not null,直接把列的属性设置为not null,也成,继续试验如下:
alter table t modify OBJECT_ID not null;
select count(*) from t;
执行计划
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 49 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | | |
| 2 | INDEX FAST FULL SCAN| IDX1_OBJECT_ID | 69485 | 49 (0)| 00:00:01 |
--------------------------------------------------------------------------------
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
170 consistent gets
0 physical reads
0 redo size
425 bytes sent via SQL*Net to client
416 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
--如果是主键就无需定义列是否允许为空了。
drop table t purge;
create table t as select * from dba_objects;
update t set object_id=rownum;
alter table t add constraint pk1_object_id primary key (OBJECT_ID);
set autotrace on
select count(*) from t;
执行计划
-------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 46 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | | |
| 2 | INDEX FAST FULL SCAN| PK1_OBJECT_ID | 69485 | 46 (0)| 00:00:01 |
-------------------------------------------------------------------------------
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
160 consistent gets
索引特性之存列值优化sum avg:
SUM/AVG的优化
drop table t purge;
create table t as select * from dba_objects;
create index idx1_object_id on t(object_id);
set autotrace on
set linesize 1000
set timing on
select sum(object_id) from t;
执行计划
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 49 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 13 | | |
| 2 | INDEX FAST FULL SCAN| IDX1_OBJECT_ID | 92407 | 1173K| 49 (0)| 00:00:01 |
----------------------------------------------------------------------------------------
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
170 consistent gets
0 physical reads
0 redo size
432 bytes sent via SQL*Net to client
415 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
--比较一下假如不走索引的代价,体会一下这个索引的重要性
select /*+full(t)*/ sum(object_id) from t;
SUM(OBJECT_ID)
--------------
2732093100
执行计划
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 292 (1)| 00:00:04 |
| 1 | SORT AGGREGATE | | 1 | 13 | | |
| 2 | TABLE ACCESS FULL| T | 92407 | 1173K| 292 (1)| 00:00:04 |
---------------------------------------------------------------------------
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
1047 consistent gets
0 physical reads
0 redo size
432 bytes sent via SQL*Net to client
415 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
--起来类似的比如AVG,和SUM是一样的,如下:
select avg(object_id) from t;
AVG(OBJECT_ID)
--------------
37365.5338
执行计划
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 49 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 13 | | |
| 2 | INDEX FAST FULL SCAN| IDX1_OBJECT_ID | 92407 | 1173K| 49 (0)| 00:00:01 |
----------------------------------------------------------------------------------------
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
170 consistent gets
0 physical reads
0 redo size
448 bytes sent via SQL*Net to client
415 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
--不知大家注意到没,这里的试验已经告诉我们了,OBJECT_ID列是否为空,也不影响SUM/AVG等聚合的结果。
3.索引本身有序
索引特性之有序优化order by:(索引 本身就排序了)
--索引与排序
drop table t purge;
create table t as select * from dba_objects ;
set autotrace traceonly
--oracle还算智能,不会傻到这里都去排序,做了查询转换,忽略了这个排序
select count(*) from t order by object_id;
---以下语句说明排序
set autotrace traceonly
set linesize 1000
drop table t purge;
create table t as select * from dba_objects;
--以下语句没有索引又有order by ,必然产生排序
select * from t where object_id>2 order by object_id;
执行计划
-----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
-----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 92407 | 18M| | 4454 (1)| 00:00:54 |
| 1 | SORT ORDER BY | | 92407 | 18M| 21M| 4454 (1)| 00:00:54 |
|* 2 | TABLE ACCESS FULL| T | 92407 | 18M| | 294 (2)| 00:00:04 |
-----------------------------------------------------------------------------------
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
1047 consistent gets
0 physical reads
0 redo size
3513923 bytes sent via SQL*Net to client
54029 bytes received via SQL*Net from client
4876 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
73117 rows processed
---新增索引后,Oracle就有可能利用索引本身就有序的特点,利用索引来避免排序,如下:
create index idx_t_object_id on t(object_id);
set autotrace traceonly
select * from t where object_id>2 order by object_id;
执行计划
-----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 92407 | 18M| 1302 (1)| 00:00:16 |
| 1 | TABLE ACCESS BY INDEX ROWID| T | 92407 | 18M| 1302 (1)| 00:00:16 |
|* 2 | INDEX RANGE SCAN | IDX_T_OBJECT_ID | 92407 | | 177 (1)| 00:00:03 |
-----------------------------------------------------------------------------------------------
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
10952 consistent gets
0 physical reads
0 redo size
8115221 bytes sent via SQL*Net to client
54029 bytes received via SQL*Net from client
4876 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
73117 rows processed
--如下情况Oracle肯定毫不犹豫的选择用索引,因为回表取消了 !
select object_id from t where object_id>2 order by object_id;
执行计划
------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 92407 | 1173K| 177 (1)| 00:00:03 |
|* 1 | INDEX RANGE SCAN| IDX_T_OBJECT_ID | 92407 | 1173K| 177 (1)| 00:00:03 |
------------------------------------------------------------------------------------
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
5027 consistent gets
0 physical reads
0 redo size
1062289 bytes sent via SQL*Net to client
54029 bytes received via SQL*Net from client
4876 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
73117 rows processed
--另外,如果是如下语句,Oracle打死也不用索引了。
select object_id from t where object_id>2;
索引特性之有序与存列值优化max:
--MAX/MIN 的索引优化
drop table t purge;
create table t as select * from dba_objects;
update t set object_id=rownum;
alter table t add constraint pk_object_id primary key (OBJECT_ID);
set autotrace on
set linesize 1000
select max(object_id) from t;
执行计划
-------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 2 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 13 | | |
| 2 | INDEX FULL SCAN (MIN/MAX)| PK_OBJECT_ID | 1 | 13 | 2 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
2 consistent gets
0 physical reads
0 redo size
431 bytes sent via SQL*Net to client
415 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
--最小值试验就无需展现执行计划结果了,必然和最大值的执行计划一样!
select min(object_id) from t;
--如果没用到索引的情况是如下,请看看执行计划有何不同,请看看代价和逻辑读的差异!
select /*+full(t)*/ max(object_id) from t;
执行计划
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 292 (1)| 00:00:04 |
| 1 | SORT AGGREGATE | | 1 | 13 | | |
| 2 | TABLE ACCESS FULL| T | 92407 | 1173K| 292 (1)| 00:00:04 |
---------------------------------------------------------------------------
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
1047 consistent gets
0 physical reads
0 redo size
431 bytes sent via SQL*Net to client
415 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
---另外,可以做如下试验观察在有索引的情况下,随这记录数增加,性能差异是否明显?
set autotrace off
drop table t_max purge;
create table t_max as select * from dba_objects;
insert into t_max select * from t_max;
insert into t_max select * from t_max;
insert into t_max select * from t_max;
insert into t_max select * from t_max;
insert into t_max select * from t_max;
select count(*) from t_max;
create index idx_t_max_obj on t_max(object_id);
set autotrace on
select max(object_id) from t_max;
执行计划
--------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 3 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 13 | | |
| 2 | INDEX FULL SCAN (MIN/MAX)| IDX_T_MAX_OBJ | 1 | 13 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------------------------
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
3 consistent gets
0 physical reads
0 redo size
431 bytes sent via SQL*Net to client
415 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
/*
object_id如果允许为空,加个索引后,会走INDEX FULL SCAN (MIN/MAX)高效算法吗,
当然会了!取最大最小还怕啥空值?
*/
drop table t purge;
create table t as select * from dba_objects ;
create index idx_object_id on t(object_id);
set autotrace on
set linesize 1000
select max(object_id) from t;
索引特性之有序优化distinct:
--DISTINCT测试前的准备
drop table t purge;
create table t as select * from dba_objects;
update t set object_id=rownum;
alter table T modify OBJECT_ID not null;
update t set object_id=2;
update t set object_id=3 where rownum<=25000;
commit;
/*
在oracle10g的R2环境之后,DISTINCT由于其 HASH UNIQUE的算法导致其不会产生排序,其调整的
ALTER SESSION SET "_gby_hash_aggregation_enabled" = FALSE
*/
set linesize 1000
set autotrace traceonly
select distinct object_id from t ;
执行计划
-----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
-----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 88780 | 1127K| | 717 (1)| 00:00:09 |
| 1 | HASH UNIQUE | | 88780 | 1127K| 1752K| 717 (1)| 00:00:09 |
| 2 | TABLE ACCESS FULL| T | 88780 | 1127K| | 292 (1)| 00:00:04 |
-----------------------------------------------------------------------------------
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
1047 consistent gets
0 physical reads
0 redo size
462 bytes sent via SQL*Net to client
416 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
2 rows processed
/*不过虽然没有排序,通过观察TempSpc可知distinct消耗PGA内存进行HASH UNIQUE运算,
接下来看看建了索引后的情况,TempSpc关键字立即消失,COST也立即下降许多,具体如下*/
--为T表的object_id列建索引
create index idx_t_object_id on t(object_id);
set linesize 1000
set autotrace traceonly
select /*+index(t)*/ distinct object_id from t ;
执行计划
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 88780 | 1127K| 582 (1)| 00:00:07 |
| 1 | SORT UNIQUE NOSORT| | 88780 | 1127K| 582 (1)| 00:00:07 |
| 2 | INDEX FULL SCAN | IDX_T_OBJECT_ID | 88780 | 1127K| 158 (1)| 00:00:02 |
--------------------------------------------------------------------------------------
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
145 consistent gets
0 physical reads
0 redo size
462 bytes sent via SQL*Net to client
416 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
2 rows processed
索引特性之有序难优化union:
----UNION 是需要排序的
drop table t1 purge;
create table t1 as select * from dba_objects where object_id is not null;
alter table t1 modify OBJECT_ID not null;
drop table t2 purge;
create table t2 as select * from dba_objects where object_id is not null;
alter table t2 modify OBJECT_ID not null;
set linesize 1000
set autotrace traceonly
select object_id from t1
union
select object_id from t2;
执行计划
------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 136K| 1732K| | 1241 (55)| 00:00:15 |
| 1 | SORT UNIQUE | | 136K| 1732K| 2705K| 1241 (55)| 00:00:15 |
| 2 | UNION-ALL | | | | | | |
| 3 | TABLE ACCESS FULL| T1 | 57994 | 736K| | 292 (1)| 00:00:04 |
| 4 | TABLE ACCESS FULL| T2 | 78456 | 996K| | 292 (1)| 00:00:04 |
------------------------------------------------------------------------------------
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
2094 consistent gets
0 physical reads
0 redo size
1062305 bytes sent via SQL*Net to client
54029 bytes received via SQL*Net from client
4876 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
73120 rows processed
--发现索引无法消除UNION 排序(INDEX FAST FULL SCAN)
create index idx_t1_object_id on t1(object_id);
create index idx_t2_object_id on t2(object_id);
set autotrace traceonly
set linesize 1000
select object_id from t1
union
select object_id from t2;
执行计划
---------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 136K| 1732K| | 755 (57)| 00:00:10 |
| 1 | SORT UNIQUE | | 136K| 1732K| 2705K| 755 (57)| 00:00:10 |
| 2 | UNION-ALL | | | | | | |
| 3 | INDEX FAST FULL SCAN| IDX_T1_OBJECT_ID | 57994 | 736K| | 49 (0)| 00:00:01 |
| 4 | INDEX FAST FULL SCAN| IDX_T2_OBJECT_ID | 78456 | 996K| | 49 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------------
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
340 consistent gets
0 physical reads
0 redo size
1062305 bytes sent via SQL*Net to client
54029 bytes received via SQL*Net from client
4876 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
73120 rows processed
--INDEX FULL SCAN的索引依然无法消除UNION排序
select /*+index(t1)*/ object_id from t1
union
select /*+index(t2)*/ object_id from t2;
执行计划
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 136K| 1732K| | 1010 (56)| 00:00:13 |
| 1 | SORT UNIQUE | | 136K| 1732K| 2705K| 1010 (56)| 00:00:13 |
| 2 | UNION-ALL | | | | | | |
| 3 | INDEX FULL SCAN| IDX_T1_OBJECT_ID | 57994 | 736K| | 177 (1)| 00:00:03 |
| 4 | INDEX FULL SCAN| IDX_T2_OBJECT_ID | 78456 | 996K| | 177 (1)| 00:00:03 |
----------------------------------------------------------------------------------------------
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
326 consistent gets
0 physical reads
0 redo size
1062305 bytes sent via SQL*Net to client
54029 bytes received via SQL*Net from client
4876 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
73120 rows processed
--结论:索引无法消除UNION 排序,一般来说在使用UNION时要确定必要性,在数据不会重复时只需UNION ALL即可。
回表与聚合因子:
回表是索引优化的要点之一:
--索引回表读(TABLE ACCESS BY INDEX ROWID)的例子
drop table t purge;
create table t as select * from dba_objects;
create index idx1_object_id on t(object_id);
--试验1
set autotrace traceonly
set linesize 1000
set timing on
select * from t where object_id<=5;
执行计划
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 4 | 828 | 3 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| T | 4 | 828 | 3 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX1_OBJECT_ID | 4 | | 2 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
5 consistent gets
0 physical reads
0 redo size
1666 bytes sent via SQL*Net to client
415 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
4 rows processed
--比较消除TABLE ACCESS BY INDEX ROWID回表后的性能,将select * from改为select object_id from
set autotrace traceonly
set linesize 1000
set timing on
select object_id from t where object_id<=5;
执行计划
-----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 4 | 52 | 2 (0)| 00:00:01 |
|* 1 | INDEX RANGE SCAN| IDX1_OBJECT_ID | 4 | 52 | 2 (0)| 00:00:01 |
-----------------------------------------------------------------------------------
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
3 consistent gets
0 physical reads
0 redo size
478 bytes sent via SQL*Net to client
415 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
4 rows processed
--试验2:通过构造联合索引,再观察一个消除TABLE ACCESS BY INDEX ROWID的例子
set autotrace traceonly
set linesize 1000
select object_id,object_name from t where object_id<=5;
执行计划
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 4 | 316 | 3 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| T | 4 | 316 | 3 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX1_OBJECT_ID | 4 | | 2 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
5 consistent gets
0 physical reads
0 redo size
567 bytes sent via SQL*Net to client
415 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
4 rows processed
--准备工作,对t表建联合索引
create index idx_un_objid_objname on t(object_id,object_name);
--该联合索引建完后,产生功效了!消除了TABLE ACCESS BY INDEX ROWID
select object_id,object_name from t where object_id<=5;
执行计划
-----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 12 | 948 | 2 (0)| 00:00:01 |
|* 1 | INDEX RANGE SCAN| IDX_UN_OBJID_OBJNAME | 12 | 948 | 2 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
3 consistent gets
0 physical reads
0 redo size
567 bytes sent via SQL*Net to client
415 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
4 rows processed
聚合因子也是索引优化要点:
--colocated表根据x列有一定的物理顺序
drop table colocated purge;
create table colocated ( x int, y varchar2(80) );
begin
for i in 1 .. 100000
loop
insert into colocated(x,y)
values (i, rpad(dbms_random.random,75,'*') );
end loop;
end;
/
alter table colocated
add constraint colocated_pk
primary key(x);
begin
dbms_stats.gather_table_stats( user, 'COLOCATED', cascade=>true );
end;
/
--disorganized 表数据根据x列完全无序
drop table disorganized purge;
create table disorganized
as
select x,y
from colocated
order by y;
alter table disorganized
add constraint disorganized_pk
primary key (x);
begin
dbms_stats.gather_table_stats( user, 'DISORGANIZED', cascade=>true );
end;
/
set autotrace off
alter session set statistics_level=all;
set linesize 1000
---两者性能差异显著
select /*+ index( colocated colocated_pk ) */ * from colocated where x between 20000 and 40000;
SELECT * FROM table(dbms_xplan.display_cursor(NULL,NULL,'runstats_last'));
------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 20001 |00:00:00.05 | 2900 |
| 1 | TABLE ACCESS BY INDEX ROWID| COLOCATED | 1 | 20002 | 20001 |00:00:00.05 | 2900 |
|* 2 | INDEX RANGE SCAN | COLOCATED_PK | 1 | 20002 | 20001 |00:00:00.03 | 1375 |
------------------------------------------------------------------------------------------------------
select /*+ index( disorganized disorganized_pk ) */* from disorganized where x between 20000 and 40000;
SELECT * FROM table(dbms_xplan.display_cursor(NULL,NULL,'runstats_last'));
---------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
---------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 20001 |00:00:00.09 | 21360 |
| 1 | TABLE ACCESS BY INDEX ROWID| DISORGANIZED | 1 | 20002 | 20001 |00:00:00.09 | 21360 |
|* 2 | INDEX RANGE SCAN | DISORGANIZED_PK | 1 | 20002 | 20001 |00:00:00.03 | 1375 |
---------------------------------------------------------------------------------------------------------
---看聚合因子,就明白真正的原因了。
select a.index_name,
b.num_rows,
b.blocks,
a.clustering_factor
from user_indexes a, user_tables b
where index_name in ('COLOCATED_PK', 'DISORGANIZED_PK' )
and a.table_name = b.table_name;
INDEX_NAME NUM_ROWS BLOCKS CLUSTERING_FACTOR
------------------------------ ---------- ---------- -----------------
COLOCATED_PK 100000 1252 1190
DISORGANIZED_PK 100000 1219 99899

