Python网络爬虫与信息提取(二)——HTTP协议及Requests库的方法
HTTP协议及Requests库的方法
HTTP: Hypertext Transfer Protocol,超文本传输协议
HTTP是一个基于“请求与响应”模式的、无状态的应用层协议。也就是用户发出请求,服务器给出响应。无状态是指第一次请求与第二次请求之间并没有相关关联。应用层协议工作在TCP协议之上。
HTTP协议采用URL作为定位网络资源的标识。
URL格式:http://host[:port][path]
host域合法的Internet主机域名或IP地址
port域:端口号(可省),缺省端口为80
path域:请求资源的路径。资源在这样的主机或IP地址的服务器上所包含的内部路径
eg: http://www.bit.edu.cn 表示北京理工大学的校园网的首页
http://220.181.111.188/duty 指的是这样一台IP主机上,duty目录下的相关资源
HTTP URL的理解:URL是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源。就像电脑的一个文件一样,不过这个资源不在电脑上,而在Internet上。
HTTP协议对资源的操作
|
方法 |
说明 |
|
GET |
请求获取URL位置的资源 |
|
HEAD |
请求获取URL位置资源的响应消息报告,即获得该资源的头部信息(当资源很大时,难以完全拿下或者拿下的代价很大时,可以请求HEAD,能够获得头部信息,并且分析资源的大概内容) |
|
POST |
请求向URL位置的资源后附加新的数据。不改变URL位置现有的内容,在后面新增用户提交的资源 |
|
PUT |
请求向URL位置存储一个资源,覆盖原URL位置的资源 |
|
PATCH |
请求局部更新URL位置的资源,即改变该处资源的部分内容 |
|
DELETE |
请求删除URL位置储存的资源 |
这6个方法就是requests库提供的6个主要函数所对应的功能。
HTTP通过这6中方法对资源进行管理,每次操作时是独立的,无状态的。
在HTTP协议的世界里,网络通道和服务器都是黑盒子,它能看到的就是URL链接,以及对URL链接的相关操作。
理解PATCH和PUT的区别:
假设URL位置有一组数据UsreInfo,包括UserI、UserName等20个字段。
需求:用户修改了UserName,其他不变
1:采用PATCH,仅向URL提交UserName的局部更新请求。
2:采用PUT,必须将所有20个字段一并提交到URL,未提交字段将被删除
PATCH最主要好处:节省网络带宽
HTTP协议与Requests库
|
HTTP协议方法 |
Requests库方法 |
功能一致性 |
|
GET |
requests.get() |
一致 |
|
HEAD |
requests.head() |
一致 |
|
POST |
requests.post() |
一致 |
|
PUT |
requests.put() |
一致 |
|
DELETE |
requests.delete() |
一致 |
|
PATCH |
requests.patch() |
一致 |
Requests库的head()方法
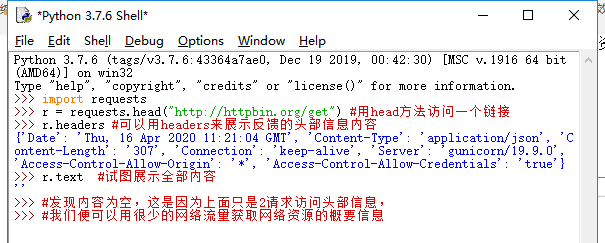
注:倒数第二行多打了一个2(⊙﹏⊙)
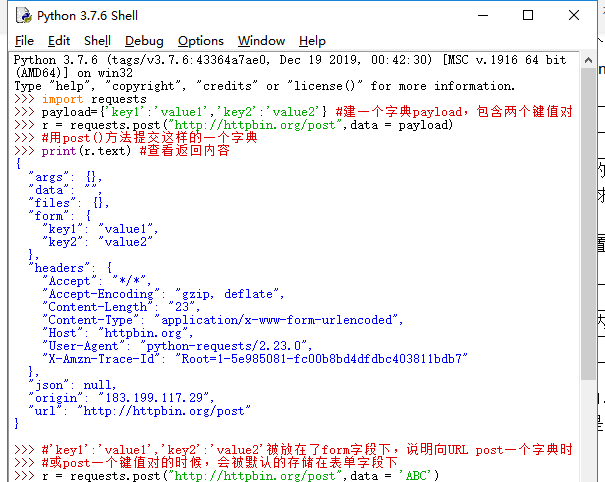
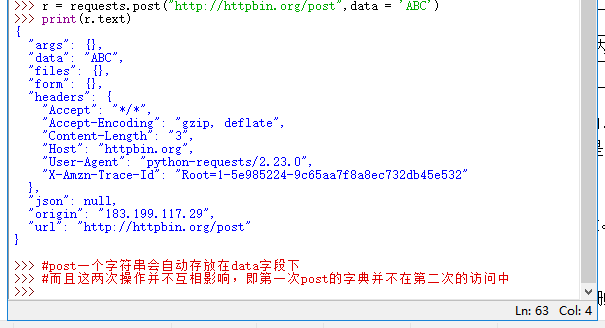
Requests库的post()方法
requests.request(method,url,**kwargs)
method: 请求方式,对应get/put/post等7种
url : 拟获取页面的URL链接
**kwargs: 控制访问参数,共13个
method:请求方式
r=requests.request(‘GET’,url,**kwargs)
r=requests.request(‘HEAD’,url,**kwargs)
r=requests.request(‘POST’,url,**kwargs)
r=requests.request(‘PUT’,url,**kwargs)
r=requests.request(‘PATCH’,url,**kwargs)
r=requests.request(‘delete’,url,**kwargs)
r=requests.request(‘OPTIONS’,url,**kwargs)
OPTIONS:向服务器获取跟服务器打交道的参数,并不与获取资源直接相关,因此使用较少
**kwargs:控制访问参数(13个),均为可选项
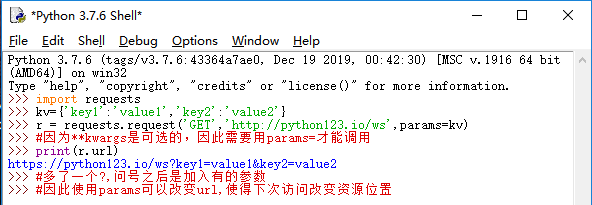
1:params 字典或字节序列,作为参数增加到url中
2:data 字典、字节序列或文件对象,作为Request的内容
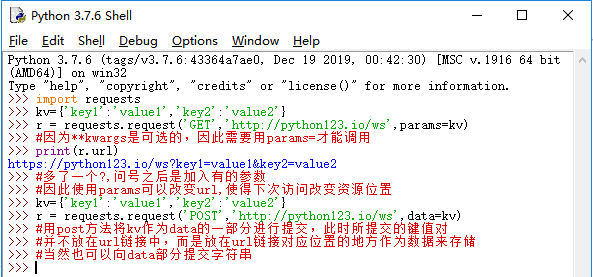
3:json : JSON格式的数据,作为Request的内容,向服务器提交
JSON是HTTP,HTML相关的web开发中非常常见,也是HTTP协议最经常使用的数据格式

4:headers : 字典,HTTP定制头。对应于向某个url访问时所发起的HTTP的头字段。
就是可以使用这个字段来定制访问某一个url的HTTP协议头

5:cookies: 字典或CookieJar,Request中的cookie
6:auth : 元组,支持HTTP认证功能
7:files :字典类型,向服务器传输文件
fs={‘file’:open(‘data.xls’,’rb’)} #用file与对应的文件做键值对,用open()方式打开这个文件
r=requests.request(‘POST’,’http://python123.io/ws’,file=fs) #可以向某一个链接提交一个文件
8:timeout: 设定的超时时间,以秒为单位

9: proxies : 字典类型,为爬取网页设定相关的访问代理服务器,可以增加登陆认证
pxs={‘http’:’http://user:pass@10.10.10.1:1234’,’https’:’https://10.10.10.1:4321’}
r=requests.request(‘GET’,’http://www.baidu.com’,proxies=pxs)
#增加两个代理,一个是http访问时使用的代理,在这代理中可以增加用户名和密码的设置;再增加一个https的代理服务器,这样在访问百度时,我们所使用的IP地址就是代理服务器的IP地址,使用这个字段可以有效地隐藏用户爬取网页的原的IP地址信息,能够有效的防止对爬虫的逆追踪
虽然我写的时候显示TimeoutError: [WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。(⊙﹏⊙)
10:allow_redirects : True/False,默认为True,重定向开关,表示是否允许对url进行重定向
11:stream : True/False ,默认为True,获取内容立即下载开关,表示对获取的内容是否立即下载
12: verify : True/False,默认为True,认证SSl证书开关,
13: cert: 保存本里SSL证书路径的字段
requests.get(url,params=None,**kwargs)
Url :拟获取页面的url链接
params :url中的额外参数,字典或字节流格式,可选
**kwargs :12个控制访问参数(除params外),与request()完全一样
requests.head(url,**kwargs)
**kwargs:13个控制访问参数,与request()一样
requests.post(url,data=None,json=None,**kwargs)
**kwargs:除data,json外,与request()一样
requests.put(url,data=None,**kwargs)
**kwargs:除data外,与request()一样
requests.patch(url,data=None,**kwargs)
**kwargs:除data外,与request()一样
requests.delete(url,**kwargs)
**kwargs: 与request()一样
其实这6个方法都可以使用request()直接实现,不过每个要实现的操作都有经常使用的控制访问参数,那么这6个方式就是将经常使用的控制访问参数显式化
作者:孙建钊
出处:http://www.cnblogs.com/sunjianzhao/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号