


spark dataframe 将null 改为 nan
由于我要叠加rdd某列的数据,如果加数中出现nan,结果也需要是nan,nan可以做到,但我要处理的数据源中的nan是以null的形式出现的,null不能叠加,而且我也不能删掉含null的行,于是我用了sparksql 的 ISNULL和CASE WHEN方法:
Case When 方法:
如果obs_PRE_1h列有值则不变,没有则变为nan,注意这里的nan需要写成 float(‘NaN’)
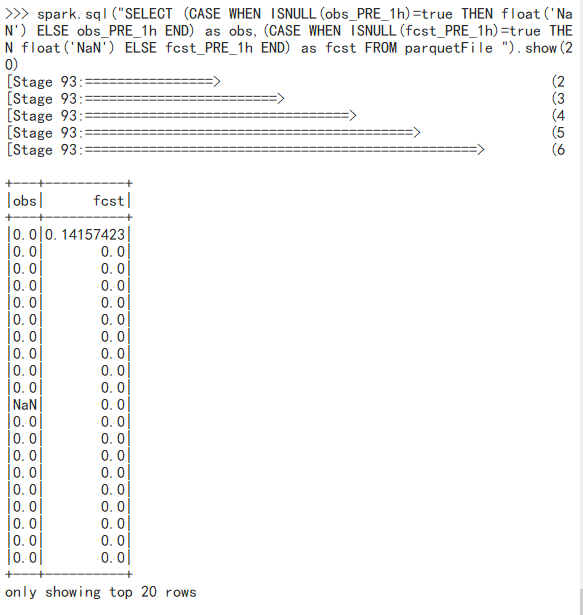
SELECT (CASE WHEN ISNULL(obs_PRE_1h)=true THEN float('NaN') ELSE obs_PRE_1h END) as obs,(CASE WHEN ISNULL(fcst_PRE_1h)=true THEN float('NaN') ELSE fcst_PRE_1h END) as fcst FROM parquetFile
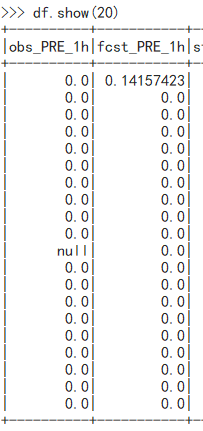
源dataframe是这样的:
结果:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!