进程与线程
什么是进程?
进程是一堆资源的集合,例如:进程里面可以包含变量 内存地址,线程等. 一个进程里面包含一个主线程
程序并不能单独运行,只有将程序装载到内存中,系统为它分配资源才能运行,而这种执行的程序就称之为进程。程序和进程的区别就在于:程序是指令的集合,它是进程运行的静态描述文本;进程是程序的一次执行活动,属于动态概念。
在多道编程中,我们允许多个程序同时加载到内存中,在操作系统的调度下,可以实现并发地执行。这是这样的设计,大大提高了CPU的利用率。进程的出现让每个用户感觉到自己独享CPU,因此,进程就是为了在CPU上实现多道编程而提出的。
什么是线程?
线程是执行的指令集,是操作系统能够进行运算调度的最小单位。一个线程就是一堆指令集合
它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务
线程启动速度快,进程启动速度慢 但是运行时没有可比性 进程是最少包含一个线程
线程可以共享内存空间资源,进程的内存是独立的
同一个进程的线程之间可以直接交流,两个进程想通信,必须通过一个中间代理进程来实现
创建新线程很简单,创建新进程需要对其父进程进行一次克隆
一个线程可以控制和操作同一进程里的其他线程,但是进程只能操作子进程
修改主线程有可能会影响到其他线程,对于一个父进程的修改不会影响到子进程
主线程是程序本身
pythob GIL全局解释器锁
CPython implementation detail: In CPython, due to the Global Interpreter Lock, only one thread can execute Python code at once (even though certain performance-oriented libraries might overcome this limitation). If you want your application to make better use of the computational resources of multi-core machines, you are advised to use multiprocessing. However, threading is still an appropriate model if you want to run multiple I/O-bound tasks simultaneously.


# -*-coding:utf-8-*- # Author:sunhao import time,threading start_time = time.time() def run(n): summ=0 for i in range(n): summ+=i print(summ) # # t1=threading.Thread(target=run,args=(10000000,)) # # # t2=threading.Thread(target=run,args=(20000000,)) # 多线程执行比串行还慢:是因为多线程在进行上下文切换时也要消耗时间 在python解释器中同一时间只能通过一个线程 #是因为python解释器加了GIL全局解释器锁 # # t1.start() # t2.start() # t1.join() # t2.join() run(10000000) run(20000000) end_time = time.time() print(end_time - start_time)
在python里:
如果任务是IO密集型的 可以用多线程
如果是CPU计算密集型的 可以考虑多进程
Threading多线程模块
直接调用
实例1:
import threading import time def sayhi(num): #定义每个线程要运行的函数 print("running on number:%s" %num) time.sleep(3) if __name__ == '__main__': t1 = threading.Thread(target=sayhi,args=(1,)) #生成一个线程实例 t2 = threading.Thread(target=sayhi,args=(2,)) #生成另一个线程实例 t1.start() #启动线程 t2.start() #启动另一个线程 print(t1.getName()) #获取线程名 print(t2.getName())
继承式调用:
import threading import time class MyThread(threading.Thread): def __init__(self,num): threading.Thread.__init__(self) self.num = num def run(self):#定义每个线程要运行的函数 print("running on number:%s" %self.num) time.sleep(3) if __name__ == '__main__': t1 = MyThread(1) t2 = MyThread(2) t1.start() t2.start()
Join方法和setDaemon方法
join()方法
逐个执行每个线程,每个线程执行完毕后再继续执行下一个线程 该方法使得多线程变得无意义
# -*-coding:utf-8-*- # Author:sunhao import threading import time def run(n): print("run",n) time.sleep(3) start_time=time.time() t_objs=[] # 存线程实例 for i in range(50): t=threading.Thread(target=run,args=('t%s'%i,)) # t1 = threading.Thread(target=run, args=('t1',)) # t2=threading.Thread(target=run,args=('t2',)) t.start() t_objs.append(t) #为了不阻塞后面线程的启动,不在这里join,先放到一个列表里 for t in t_objs: #循环线程实例列表,等待所有线程执行完毕 print(t) t.join() #等待线程执行结束 print("--------all threads has finished",threading.current_thread(),threading.active_count()) print("cost_time:%s"%(time.time()-start_time)) # t1.start() # t2.start() # run("t1") # run("t2")
thread 模块提供的其他方法: # threading.currentThread(): 返回当前的线程变量。 # threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。 # threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。 # 除了使用方法外,线程模块同样提供了Thread类来处理线程,Thread类提供了以下方法: # run(): 用以表示线程活动的方法。 # start():启动线程活动。 # join([time]): 等待至线程中止。这阻塞调用线程直至线程的join() 方法被调用中止-正常退出或者抛出未处理的异常-或者是可选的超时发生。 # isAlive(): 返回线程是否活动的。 # getName(): 返回线程名。 # setName(): 设置线程名。
setDaemon(True):
将线程声明为守护线程,必须在start() 方法调用之前设置, 如果不设置为守护线程程序会被无限挂起。这个方法基本和join是相反的。当我们 在程序运行中,执行一个主线程,如果主线程又创建一个子线程,主线程和子线程 就分兵两路,分别运行,那么当主线程完成想退出时,会检验子线程是否完成。如 果子线程未完成,则主线程会等待子线程完成后再退出。但是有时候我们需要的是 只要主线程完成了,不管子线程是否完成,都要和主线程一起退出,这时就可以 用setDaemon方法啦
# -*-coding:utf-8-*- # Author:sunhao # -*-coding:utf-8-*- # Author:sunhao import threading import time def run(n): print("run",n) time.sleep(2) print("task done",threading.current_thread()) start_time=time.time() t_objs=[] #存线程实例 for i in range(50): t=threading.Thread(target=run,args=('t%s'%i,)) t.setDaemon(True) #就是把当前线程设置为守护线程 t.start() t_objs.append(t) #为了不阻塞后面线程的启动,不在这里join,先放到一个列表里 # # for t in t_objs: #循环线程实例列表,等待所有线程执行完毕 # print(t) # t.join() time.sleep(2) print("--------all threads has finished",threading.current_thread(),threading.active_count()) print("cost_time:%s"%(time.time()-start_time)) # t1.start() # t2.start() # run("t1") # run("t2")
线程锁(互斥锁)
一个进程下可以启动多个线程,多个线程共享父进程的内存空间,也就意味着每个线程可以访问同一份数据,此时,如果2个线程同时要修改同一份数据,会出现什么状况?
# -*-coding:utf-8-*- # Author:sunhao import threading,time def run(): lock.acquire() global num num +=1 #time.sleep(1) lock.release() lock = threading.Lock() #生成一个实例锁 num = 0 t_objs=[] for i in range(100): t=threading.Thread(target=run) t.start() t_objs.append(t) # #为了不阻塞后面线程的启动,不在这里join,先放到一个列表里 for t in t_objs: t.join() print("num:",num)
GIL全局解释器锁与LOCK区别
Python已经有一个GIL来保证同一时间只能有一个线程来执行了,为什么这里还需要lock?
注意啦,这里的lock是用户级的lock,跟那个GIL没关系 ,具体看下图
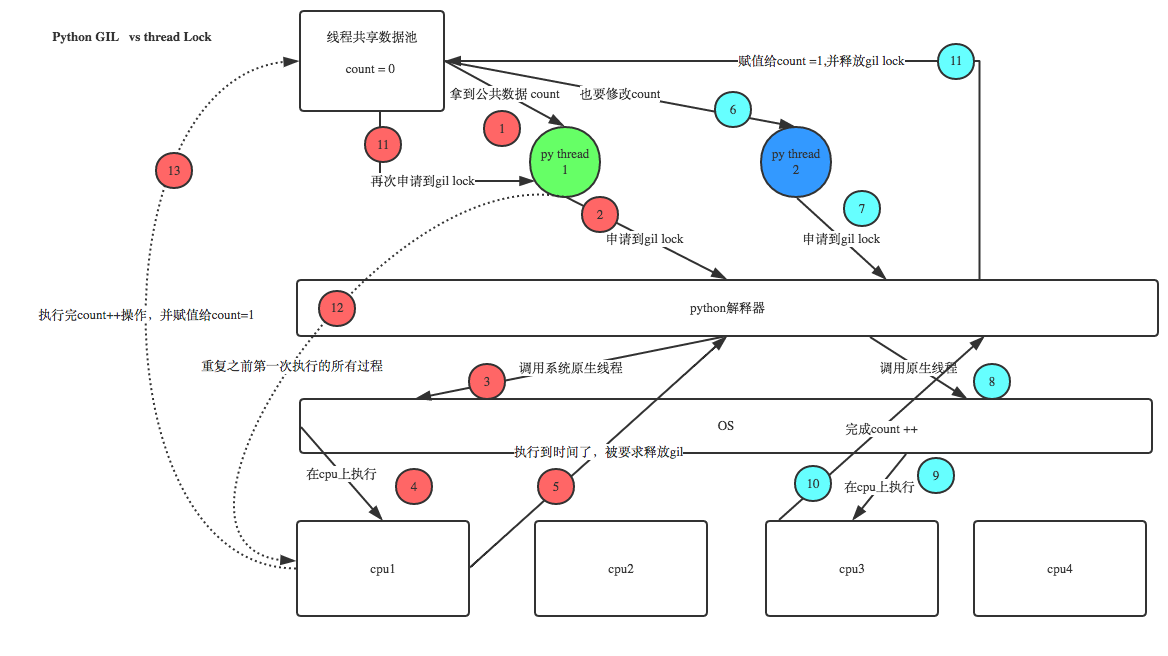
全局解释器锁是保证同一时间只有一个线程进入解释器里执行,而用户级锁是保证同一时间只有一个线程在修改数据,防止线程切来不及执行完毕换造成冲突,加锁其实就是仅把计算那一小段代码串行了,其他还是并行 多线程执行比串行还慢:是因为多线程在进行上下文切换时也要消耗时间 在python解释器中同一时间只能通过一个线程
递归锁
说白了就是在一个大锁中还要再包含子锁
# -*-coding:utf-8-*- # Author:sunhao import threading, time def run1(): print("grab the first part data") lock.acquire() global num num += 1 lock.release() return num def run2(): print("grab the second part data") lock.acquire() global num2 num2 += 1 lock.release() return num2 def run3(): lock.acquire() res = run1() print('--------between run1 and run2-----') res2 = run2() lock.release() print(res, res2) if __name__ == '__main__': num, num2 = 0, 0 lock = threading.RLock() t_obj=[] for i in range(10): t = threading.Thread(target=run3) t.start() t_obj.append(t) for t in t_obj: t.join() while threading.active_count() != 1: print(threading.active_count()) else: print('----all threads done---') print(num, num2)
信号量
互斥锁 同时只允许一个线程更改数据,而Semaphore是同时允许一定数量的线程更改数据
# -*-coding:utf-8-*- # Author:sunhao import threading,time def run(n): semaphore.acquire() time.sleep(1) print("run the thread:%s\n"%n) semaphore.release() if __name__=="__main__": semaphore=threading.BoundedSemaphore(5) #最多允许5个线程同时运行 信号量 for i in range(23): t=threading.Thread(target=run,args=(i,)) t.start() while threading.active_count() !=1: pass else: print("all threading done")
Event(事件)
python线程的事件用于主线程控制其他线程的执行,事件主要提供了三个方法 set、wait、clear。
通过Event来实现两个或多个线程间的交互
事件处理的机制:全局定义了一个“Flag”,如果“Flag”值为 False,那么当程序执行 event.wait 方法时就会阻塞,如果“Flag”值为True,那么event.wait 方法时便不再阻塞。
- clear:将“Flag”设置为False
- set:将“Flag”设置为True
# -*-coding:utf-8-*- # Author:sunhao import threading,time event=threading.Event() def lighter(): count = 0 event.set() while True: if count > 10 and count <= 20: event.clear() print("\033[31;1mred light: \033[0m",count) elif count > 20: event.set() print("\033[32;1mgreen light \033[0m",count) count=0 else: print("\033[32;1mgreen light \033[0m",count) time.sleep(1) count+=1 def car(name): while True: if event.is_set(): # 代表绿灯 print("[%s] runing"%name) time.sleep(1) else: print("[%s] waiting"%name) event.wait() light=threading.Thread(target=lighter) light.start() car1=threading.Thread(target=car,args=('tesla',)) car1.start()
Queue队列
队列的作用:解耦,使程序实现松耦合,提高处理效率
创建一个“队列”对象
import Queue
q = Queue.Queue(maxsize = 10)
Queue.Queue类即是一个队列的同步实现。队列长度可为无限或者有限。可通过Queue的构造函数的可选参数maxsize来设定队列长度。如果maxsize小于1就表示队列长度无限。
将一个值放入队列中
q.put(10)
调用队列对象的put()方法在队尾插入一个项目。put()有两个参数,第一个item为必需的,为插入项目的值;第二个block为可选参数,默认为
1。如果队列当前为空且block为1,put()方法就使调用线程暂停,直到空出一个数据单元。如果block为0,put方法将引发Full异常。
将一个值从队列中取出
q.get()
调用队列对象的get()方法从队头删除并返回一个项目。可选参数为block,默认为True。如果队列为空且block为True,get()就使调用线程暂停,直至有项目可用。如果队列为空且block为False,队列将引发Empty异常。
Python Queue模块有三种队列及构造函数:
1、Python Queue模块的FIFO队列先进先出。 class queue.Queue(maxsize)
2、LIFO类似于堆,即先进后出。 class queue.LifoQueue(maxsize)
3、还有一种是优先级队列级别越低越先出来。 class queue.PriorityQueue(maxsize)
此包中的常用方法(q = Queue.Queue()):
q.qsize() 返回队列的大小
q.empty() 如果队列为空,返回True,反之False
q.full() 如果队列满了,返回True,反之False
q.full 与 maxsize 大小对应
q.get([block[, timeout]]) 获取队列,timeout等待时间
q.get_nowait() 相当q.get(False)
非阻塞 q.put(item) 写入队列,timeout等待时间
q.put_nowait(item) 相当q.put(item, False)
q.task_done() 在完成一项工作之后,q.task_done() 函数向任务已经完成的队列发送一个信号
q.join() 实际上意味着等到队列为空,再执行别的操作
# -*-coding:utf-8-*- # Author:sunhao import queue q=queue.Queue() #先进先出 q.put('disk1') q.put('disk2') q1=queue.LifoQueue() #后进先出 q2=queue.PriorityQueue() #优先级 q2.put((-1,'mayun')) #从小到大排列 q2.put((9,'jim')) q2.put((3,'lucy')) q2.put((2,'lily')) print(q.qsize()) print(q2.get()) print(q2.get()) print(q2.get())
实例:
# -*-coding:utf-8-*- # Author:sunhao import threading,time import queue q = queue.Queue() def producer(name): count=1 while True: q.put("骨头%s"%count) print("生产了骨头",count) count+=1 time.sleep(0.5) def consumer(name): while True: print("%s 取到 %s"%(name,q.get())) t1=threading.Thread(target=producer,args=("jim",)) c=threading.Thread(target=consumer,args=('lucy',)) c1=threading.Thread(target=consumer,args=('lily',)) c2=threading.Thread(target=consumer,args=('Tom',)) t1.start() c.start() c1.start() c2.start()
import time,random import queue,threading q = queue.Queue() def Producer(name): count = 0 while count <20: time.sleep(random.randrange(3)) q.put(count) print('Producer %s has produced %s baozi..' %(name, count)) count +=1 def Consumer(name): count = 0 while count <20: time.sleep(random.randrange(4)) if not q.empty(): data = q.get() print(data) print('\033[32;1mConsumer %s has eat %s baozi...\033[0m' %(name, data)) else: print("-----no baozi anymore----") count +=1 p1 = threading.Thread(target=Producer, args=('A',)) c1 = threading.Thread(target=Consumer, args=('B',)) p1.start() c1.start()
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
生产者消费者模型: 一边放数据,一边取数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号