
一、深浅拷贝
1、数字和字符串
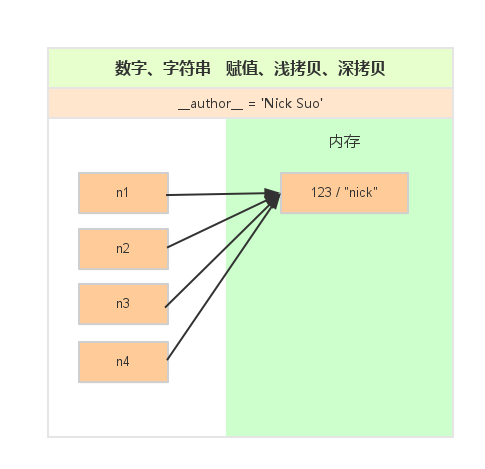
对于 数字 和 字符串 而言,赋值、浅拷贝和深拷贝无意义,因为其永远指向同一个内存地址。
import copy # 定义变量 数字、字符串 # n1 = 123 n1 = 'jack' print(id(n1)) # 赋值 n2 = n1 print(id(n2)) # 浅拷贝 n3 = copy.copy(n1) print(id(n3)) # 深拷贝 n4 = copy.deepcopy(n1) print(id(n4))
二、字典、元组、列表
对于字典、元祖、列表 而言,进行赋值、浅拷贝和深拷贝时,其内存地址的变化是不同的。
创建一个变量,该变量指向原来内存地址
n1 = {"k1": "allen", "k2": 123, "k3": ["jenny", 666]}
n2 = n1

1、浅拷贝
在内存中只拷贝第一层数据
#浅拷贝 import copy n1 = {"k1": "allen", "k2": 123, "k3": ["jenny", 666]} n2 = copy.copy(n1) print(n1) print(n2) # 输出:{'k1': 'allen', 'k2': 123, 'k3': ['jenny', 666]} # {'k1': 'allen', 'k2': 123, 'k3': ['jenny', 666]} n1['k2']='456' n1['k3'][0]="Tom" print(n1) print(n2) # 输出:{'k1': 'allen', 'k2': '456', 'k3': ['Tom', 666]} # {'k1': 'allen', 'k2': 123, 'k3': ['Tom', 666]}
2、深拷贝
在内存中将所有的数据重新创建一份(排除最后一层,即:python内部对字符串和数字的优化)
#深拷贝 import copy n1 = {"k1": "allen", "k2": 123, "k3": ["jenny", 666]} n2 = copy.deepcopy(n1) print(n1) print(n2) # 输出:{'k1': 'allen', 'k2': 123, 'k3': ['jenny', 666]} # {'k1': 'allen', 'k2': 123, 'k3': ['jenny', 666]} n1['k2']='456' n1['k3'][0]="Tom" print(n1) print(n2) # 输出:{'k1': 'allen', 'k2': '456', 'k3': ['Tom', 666]} # {'k1': 'allen', 'k2': 123, 'k3': ['jenny', 666]}
二、变量
变量是命名的内存地址空间
1、声明变量
#-*- coding:utf-8 -*- name ='Tom'
上述代码声明了一个变量,变量名为: name,变量name的值为:"Tom"
变量定义的规则:
- 变量名只能是 字母、数字或下划线的任意组合
- 变量名的第一个字符不能是数字
- 以下关键字不能声明为变量名
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
2、变量的赋值
name='Tom' name1=name print(name,name1) name='lily' print(name,name1)
这时name1的值是多少?
答案:
Tom Tom
lily Tom
3、局部变量
就是在函数内部定义的变量
不同的函数:可以定义相同的名字的局部变量,但是各用各的,相互之间不会产生影响
局部变量的作用:为了临时保存数据需要在函数中定义变量来进行存储,这就是它的作用
def test1(): a=100 def test2(): print("a=%d"%a) test1() #调用test1() test2() #结果是打印a 因为变量a没定义 所以出现错误
除了字符串和整数不可以在函数里边改
列表,字典,集合可以在函数里改
names=['Jim','Tom','Rain'] def change_name(): names[0]='王者荣耀' print('--函数里面--',names) change_name() print(names) 输出: --函数里面-- ['王者荣耀', 'Tom', 'Rain'] ['王者荣耀', 'Tom', 'Rain']
4、全局变量
在函数外边定义,在任何函数里边都可以使用
a=100 #全局变量a def test1(): print('a=%d'%a) #函数中如果没有定义变量 它会去全局中寻找该变量 def test2(): print('a=%d'%a) test1() test2()
5、局部变量和全局变量的区别
def get_wendu(): wendu=33 return wendu def print_wendu(wendu): print("温度是%d"%wendu) result=get_wendu() print_wendu(result) #如果一个函数有返回值,但是没有在调用函数之前用个变量保存的话,那么没有任何作用
使用global声明全局变量
wendu=0 #定义一个全局变量,wendu def get_wendu(): global wendu #使用global用来对声明一个全局变量
wendu=33 def print_wendu(): print("温度是%d"%wendu) get_wendu() print_wendu()
name="Jim" def outer(): name="Lucy" def inner(): global name #global是全局变量 name="Lily" inner() print(name) #此处打印的是outer函数中的name print(name) outer() print(name) #输出:Jim # Lucy # Lily


name="Jim" def outer(): name="Lucy" def inner(): nonlocal name #指定上一级的变量 name="Lily" inner() print(name) print(name) outer() print(name) #输出:Jim # Lily # Jim
三、函数
函数是什么?
函数一词来源于数学,但编程中的「函数」概念,与数学中的函数是有很大不同的,具体区别,我们后面会讲,编程中的函数在英文中也有很多不同的叫法。在BASIC中叫做subroutine(子过程或子程序),在Pascal中叫做procedure(过程)和function,在C中只有function,在Java里面叫做method。
1 什么是函数? 2 为什么要用函数? 3 函数的分类:内置函数与自定义函数 4 如何自定义函数 语法 定义有参数函数,及有参函数的应用场景 定义无参数函数,及无参函数的应用场景 定义空函数,及空函数的应用场景 5 调用函数 如何调用函数 函数的返回值 函数参数的应用:形参和实参,位置参数,关键字参数,默认参数,*args,**kwargs 6 高阶函数(函数对象) 7 函数嵌套 8 作用域与名称空间 9 装饰器 10 迭代器与生成器及协程函数 11 三元运算,列表解析、生成器表达式 12 函数的递归调用 13 内置函数 14 面向过程编程与函数式编程
1、函数的分类
#1、内置函数 为了方便我们的开发,针对一些简单的功能,python解释器已经为我们定义好了的函数即内置函数。对于内置函数,我们可以拿来就用而无需事先定义,如len(),sum(),max() ps:我们将会在最后详细介绍常用的内置函数。 #2、自定义函数 很明显内置函数所能提供的功能是有限的,这就需要我们自己根据需求,事先定制好我们自己的函数来实现某种功能,以后,在遇到应用场景时,调用自定义的函数即可。例如
2、函数的定义
#语法 def 函数名(参数1,参数2,参数3,...): '''注释''' 函数体 return 返回的值 #函数名要能反映其意义
#下面这段代码 a,b=2,4 c=a**b print(c) #改用函数写 def cal(x,y): result=x**y return result #返回函数执行结果 c=cal(a,b) #调用函数结果赋值给c变量 print(c)
3、函数使用的原则:先定义,再调用
函数即“变量”,“变量”必须先定义后引用。未定义而直接引用函数,就相当于在引用一个不存在的变量名 #测试一 def foo(): print('from foo') bar() foo() #报错 #测试二 def bar(): print('from bar') def foo(): print('from foo') bar() foo() #正常 #测试三 def foo(): print('from foo') bar() def bar(): print('from bar') foo() #会报错吗? 不会报错 #结论:函数的使用,必须遵循原则:先定义,后调用 #我们在使用函数时,一定要明确地区分定义阶段和调用阶段 #定义阶段 def foo(): print('from foo') bar() def bar(): print('from bar') #调用阶段 foo()
函数在定义阶段都干了哪些事?
#只检测语法,不执行代码 也就说,语法错误在函数定义阶段就会检测出来,而代码的逻辑错误只有在执行时才会知道
4、定义函数的三种形式
#1、无参:应用场景仅仅只是执行一些操作,比如与用户交互,打印 #2、有参:需要根据外部传进来的参数,才能执行相应的逻辑,比如统计长度,求最大值最小值 #3、空函数:设计代码结构
#定义阶段 def tell_tag(tag,n): #有参数 print(tag*n) def tell_msg(): #无参数 print('hello world') #调用阶段 tell_tag('*',12) tell_msg() tell_tag('*',12) ''' ************ hello world ************ ''' #结论: #1、定义时无参,意味着调用时也无需传入参数 #2、定义时有参,意味着调用时则必须传入参数
def auth(user,password): ''' auth function :param user: 用户名 :param password: 密码 :return: 认证结果 ''' pass def get(filename): ''' :param filename: :return: ''' pass def put(filename): ''' :param filename: :return: ''' def ls(dirname): ''' :param dirname: :return: ''' pass #程序的体系结构立见
5、函数return返回值
def test1(): print('in the test1') #没有return关键字返回None def test2(): print('in the test2') return 0 #返回0 def test3(): print('in the test3') return 1,'hello',['Tom','Jim'],{'age':18} #多个数值返回一个元组 x=test1() y=test2() z=test3() print(x) print(y) print(z) 输出: None 0 (1, 'hello', ['Tom', 'Jim'], {'age': 18})
总结: 返回值数=0:返回None 返回值数=1:返回object 返回值数>1:返回tuple元组 函数在执行过程中只要遇到return语句,就会停止执行并返回结果,so 也可以理解为 return 语句代表着函数的结束 如果未在函数中指定return,那这个函数的返回值为None
四、函数的参数
#1、位置参数:按照从左到右的顺序定义的参数 位置形参:必选参数 位置实参:按照位置给形参传值 #2、关键字参数:按照key=value的形式定义的实参 无需按照位置为形参传值 注意的问题: 1. 关键字实参必须在位置实参右面 2. 对同一个形参不能重复传值 #3、默认参数:形参在定义时就已经为其赋值 可以传值也可以不传值,经常需要变得参数定义成位置形参,变化较小的参数定义成默认参数(形参) 注意的问题: 1. 只在定义时赋值一次 2. 默认参数的定义应该在位置形参右面 3. 默认参数通常应该定义成不可变类型 #4、可变长参数: 可变长指的是实参值的个数不固定 而实参有按位置和按关键字两种形式定义,针对这两种形式的可变长,形参对应有两种解决方案来完整地存放它们,分别是*args,**kwargs
1、形参和实参
形参变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量
实参可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。因此应预先用赋值,输入等办法使参数获得确定值
def cal(x,y): #x,y为形参 result=**y return result c=cal(a,b) #调用函数a,b为实参 print(c)
2、默认参数
def stu_info(name, age, country, course): print("----注册学生信息------") print("姓名:", name) print("age:", age) print("国籍:", country) print("课程:", course) stu_info("王山炮", 22, "CN", "python_devops") stu_info("张叫春", 21, "CN", "linux") stu_info("刘老根", 25, "CN", "linux")
发现 country 这个参数 基本都 是"CN", 就像我们在网站上注册用户,像国籍这种信息,你不填写,默认就会是 中国, 这就是通过默认参数实现的,把country变成默认参数非常简单
def stu_info(name,age,course,country="CN"):
这样,这个参数在调用时不指定,那默认就是CN,指定了的话,就用你指定的值。
另外,在把country变成默认参数后,我同时把它的位置移到了最后面,为什么呢?
默认参数特点:调用函数的时候,默认参数非必须传递,默认参数的定义应该在位置形参右面
用途:默认安装值,连接数据库
3、关键参数
正常情况下,给函数传参数要按顺序,不想按顺序就可以用关键参数,只需指定参数名即可,但记住一个要求就是,关键参数必须放在位置参数之后。
#! /usr/bin/python def Func(x, y, z=2, w=4): print(x,y,z,w) if __name__ == '__main__': Func(1,2) #默认参数 Func(1,2 ,z=5, w=3) #关键字参数 #输出: 1 2 2 4 1 2 5 3
4、可变长参数(非固定参数)
若你的函数在定义时不确定用户想传入多少个参数,就可以使用非固定参数
def test(x,y,*args): # *args 会把多传入的位置参数变成一个元组形式 print(x,y,args) test(1,3) 输出: 1 3 () #后面这个()就是args,只是因为没传值,所以为空 test(1,2,3,4,5,6) 输出: 1 2 (3, 4, 5, 6)
def test(x,y,*args,**kwargs): # **kwargs 会把多传入的关键字参数变成一个字典形式 print(x,y,args,kwargs) test(1,2) 输出: 1 2 () {} #后面这个{}就是kwargs,只是因为没传值,所以为空
test(1,2,3,4,5,6,sex='female',name='Jim') 输出: 1 2 (3, 4, 5, 6) {'sex': 'female', 'name': 'Jim'}
5、把函数当做参数传递
def fun1(n): print(n) def fun2(name): print("my name is %s"%name) fun1(fun2('tom')) #把函数当做参数传递
五、lambda表达式
匿名函数 lambda
匿名函数:一次性使用,随时随时定义
应用:max,min,sorted,map,reduce,filter
######## 普 通 函 数 ######## # 定义函数(普通方式) def func(arg): return arg + 1 # 执行函数 result = func(123) ######## lambda 表 达 式 ######## # 定义函数(lambda表达式) my_lambda = lambda arg: arg + 1 # 执行函数 result1 = my_lambda(123) print(result,result1)
li = [11,15,9,21,1,2,68,95] s = sorted(map(lambda x:x if x > 11 else x * 9,li)) print(s) ###################### ret = sorted(filter(lambda x:x>22, [55,11,22,33,])) print(ret)
六、递归
递归调用是函数嵌套调用的一种特殊形式,函数在调用时,直接或间接调用了自身,就是递归调用
递归的特性:
1. 必须有一个明确的结束条件 2. 每次进入更深一层递归时,问题规模相比上次递归都应有所减少 3. 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
#直接调用本身 def func1(): print('from func1') func1() func1() #间接调用本身 def func1(): print('from func1') func2() def func2(): print('from func2') func1() func1()
调用函数会产生局部的名称空间,占用内存,因为上述这种调用会无需调用本身,python解释器的内存管理机制为了防止其无限制占用内存,对函数的递归调用做了最大的层级限制
import sys sys.getrecursionlimit() sys.setrecursionlimit(20) def f1(n): print('from f1',n) f1(n+1) f1(1) #虽然可以设置,但是因为不是尾递归,仍然要保存栈,内存大小一定,不可能无限递归,而且无限制地递归调用本身是毫无意义的,递归应该分为两个明确的阶段,回溯与递推
def cale(n): print(n) if int(n/2) ==0: return n return cale(int(n/2)) #终止条件 cale(10)
七、函数式编程
1、高阶函数
需要满足以下任意一个条件:
1、函数接收的参数是一个函数名。2、返回值中包含函数
#1、函数接收的参数是一个函数名 def fun1(n): print(n) def fun2(name): print("my name is %s"%name) fun1(fun2('tom')) #2、返回值中包含函数 def fun1(): print("from fun1") def fun2(): print("from fun2") return fun1() fun2()
2、map()方法
map()函数返回的是一个迭代器
map参数:第一个参数是一个函数,第二个函数是一个可迭代对象
number=[1,2,3,4,5,6] numbers=map(lambda x:x**2,number) # for num in numbers: # print(num) print(list(numbers))
3、filter()过滤方法
filter参数:第一个参数是一个函数(或者是匿名函数),第二个函数是一个可迭代对象
filter()函数返回的是一个迭代器
names=['jimwang','lilywang','Lucyli','Tomwang'] name=filter(lambda x:x.endswith('wang'),names) print(list(name))
#输出:['jimwang', 'lilywang', 'Tomwang']
3、reduce()方法
函数将一个数据集合(链表,元组等)中的所有数据进行下列操作:用传给 reduce 中的函数 function(有两个参数)先对集合中的第 1、2 个元素进行操作,得到的结果再与第三个数据用 function 函数运算,最后得到一个结果。
reduce参数:第一个参数是一个函数(或者是匿名函数),第二个函数是一个可迭代对象,第三个函数是传入函数计算的初始值
from functools import reduce numbers=[1,2,3,4] number=reduce(lambda x,y:x+y,numbers,3) #3+1+2+3+4 得到13 print(number) #输出:13
八、内置函数

#10除以3 divmod(10,3) #输出: (3,1)
expression="1+2*(3/2)" print(eval(expression))
#可hash的数据类型即不可变数据类型,不可hash的数据类型即可变数据类型 hash的特性: 1、不管传入的数据长度有多长,返回的结果数据长度不变 2、不可逆推算 print(hash("asdasdqqsqdqd"))
#拉链函数 #传入的参数必须是序列 list1=[1,2,3,4] list2=['a','b','c'] result=zip(list1,list2) for i in result: print(i) #输出:(1, 'a') # (2, 'b') # (3, 'c') info={'name':'Tom','age':18,'sex':'男'} result1=zip(info.keys(),info.values()) for n in result1: print(n) #输出: #('name', 'Tom') #('age', 18) #('sex', '男')
print(chr(100)) #输出:d
print(ord('$')) #输出:36
number=[1,2,3,4,5] print(list(reversed(number))) #输出:[5, 4, 3, 2, 1]
name="MyNameIsAllen" s=slice(3,5) #定义切片范围 print(name[s]) #等同于 print(name[3:5])
#判断一个对象是否是Iterable对象 from collections import Iterable a=isinstance([],Iterable) b=isinstance((),Iterable) c=isinstance({},Iterable) d=isinstance('abc',Iterable) e=isinstance((i for i in range(10)),Iterable) f=isinstance(100,Iterable) print(a) print(b) print(c) print(d) print(e) print(f) 输出: True True True True True False

 浙公网安备 33010602011771号
浙公网安备 33010602011771号