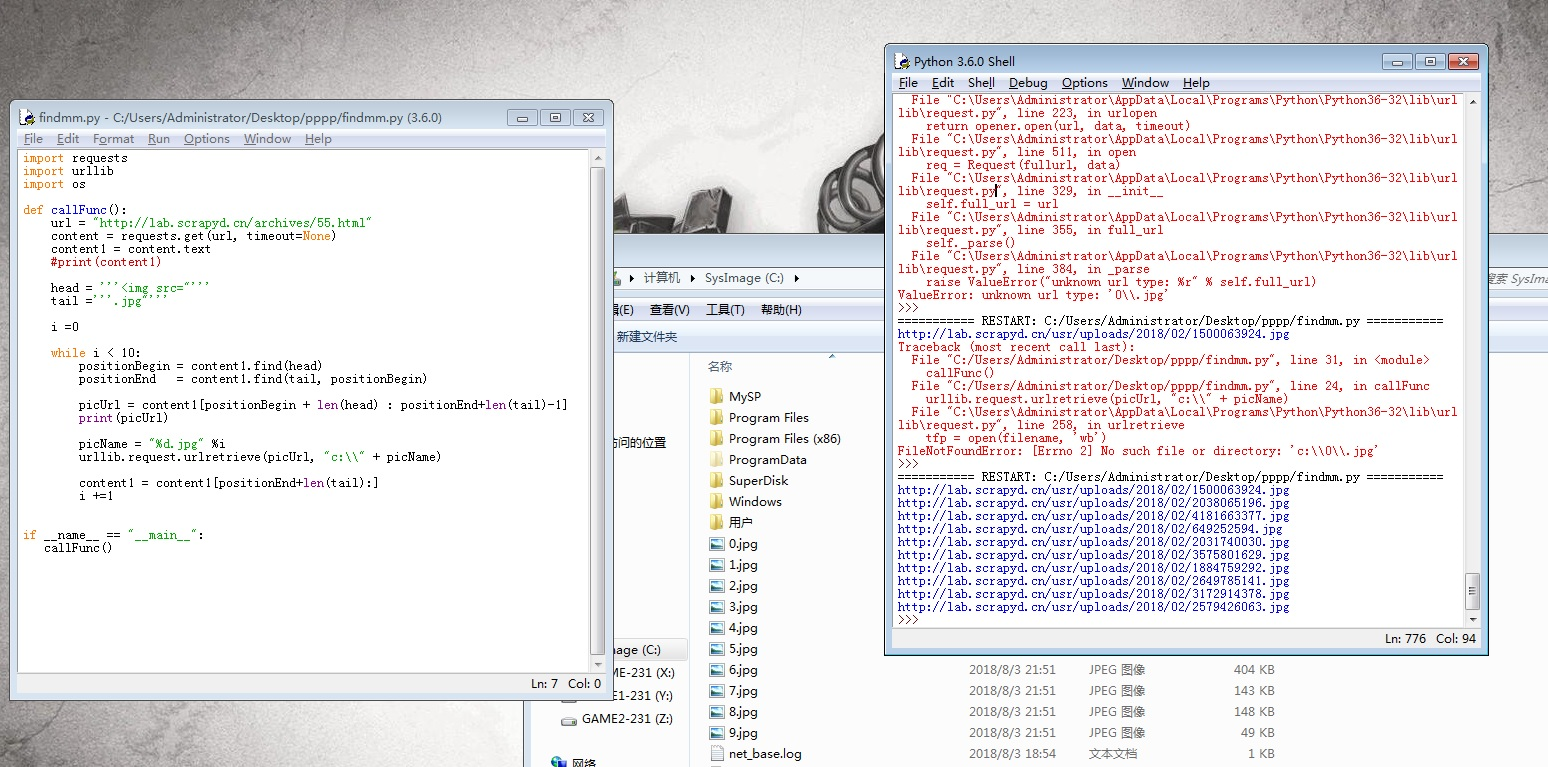
今天研究写了个简单的图片爬虫
代码:
1 import requests 2 import urllib 3 4 def callFunc(): 5 url = "http://lab.scrapyd.cn/archives/55.html" 6 content = requests.get(url, timeout=None) 7 content1 = content.text 8 #print(content1) 9 10 head = '''<img src="''' 11 tail ='''.jpg"''' 12 13 i =0 14 15 while i < 10: 16 positionBegin = content1.find(head) 17 positionEnd = content1.find(tail, positionBegin) 18 19 picUrl = content1[positionBegin + len(head) : positionEnd+len(tail)-1] 20 print(picUrl) 21 22 picName = "%d.jpg" %i 23 urllib.request.urlretrieve(picUrl, "c:\\" + picName) 24 25 content1 = content1[positionEnd+len(tail):] 26 i +=1 27 28 29 if __name__ == "__main__": 30 callFunc()