
storm并发度理解
1. 核心原理
一个运行中的拓扑是由什么组成的:worker进程,executors和tasks。Storm是按照下面3种主要的部分来区分Storm集群中一个实际运行的拓扑的:Worker进程、Executors (线程) 以及真正实施计算的Tasks(任务),先简单回顾一下storm几个核心概念:
- tuple :元组,数据结构,有序的元素列表。通常是任意类型的数据,使用","号分割,交给storm计算。
- Stream :一系列tuple。
- Spouts :水龙头。数据源。
- Bolts :转接头。逻辑处理单元,spout数据传给bolt,bolt处理后产生新的数据,可以filter、聚合、分组。接收数据 -> 处理 ->输出给bolt(多个).
- Topology :不会停止的,除非手动杀死。MR是会停止的。
- tasks :spout和bolt的执行过程就是task。spout和bolt都可以以多实例方式运行(在单独的线程中)
- workers :工作节点。storm在worker之间均衡分发任务。监听job,启动或者停止进程。
- stream grouping :控制tuple如何进行路由。
同时还有几个关键的组件:
- Nimubs : master node,在work node间分发数据,指派task给worker node,监控故障。
- Supervisor :接收nimbus的指令,有多个work进程,监督work进程,完成task。 spawn:孵化
- work process : 执行相关的task,本身不执行,创建executor(执行线程),可以有多个执行线程。
- executor : 执行线程,由work进程孵化的一个线程,运行一个或多task(有bolt/spout)
- task : 处理数据。
- zk : 维护状态。
下面给出一张经典的描述work,executor和task三个部分之间关系的示例图片
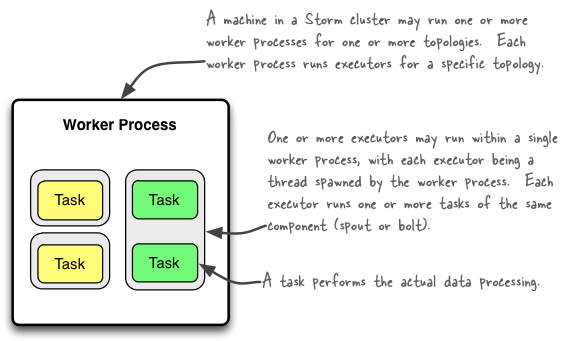
翻译一下大致意思就是:
- Storm集群中的其中1台机器可能运行着属于多个拓扑(可能为1个)的多个worker进程(可能为1个),每个worker进程运行着特定的某个拓扑的executors。
- 1个或多个excutor可能运行于1个单独的worker进程,每1个executor从属于1个被worker process生成的线程中(实际就是executor是worker中的摸一个线程),每1个executor运行着相同的组件(spout或bolt)的1个或多个task。
- 1个task执行着实际的数据处理
总结一下就是:一个work(进程)里可以包含多个executor(线程),一个executor内部可以包含一个或者多个task(任务),线程可以并行,但任务(task)只能串行执行
(1)1个worker进程执行一个拓扑的子集,1个worker进程从属于1个特定的拓扑,并运行着这个拓扑的1个或多个组件(spout或bolt)的1个或多个executor,一个运行中的拓扑包括集群中的许多台机器上的许多个这样的进程。
(2)1个executor是1个worker进程生成的1个线程,它可能运行着某个组件(spout或bolt)的1个或多个task
(3)task执行着实际的数据处理,你用代码实现的每一个spout或bolt就相当于分布于整个集群中的许多个task。在1个拓扑的生命周期中,1个组件的task的数量总是一样的,但是1个组件的executor(线程)的数量可以随着时间而改变。这意味着下面的条件总是成立:thread的数量 <= task的数量。默认情况下,task的数量与executor的数量一样,例如,Storm会在每1个线程运行1个task。
2. 实例说明
定义一个简单的拓扑
TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("readSpout" , new WordSpout()); builder.setBolt("splitBolt" , new WordSplit()).shuffleGrouping("readSpout" ); builder.setBolt("countBolt" , new WordCounter()).fieldsGrouping("splitBolt" , new Fields("word")); StormTopology topology = builder .createTopology();
在这段代码中,我们没有设置并发度,也没有设置worker的数量。Storm默认就会给这个Topology分配1个Worker(进程),在这个Worker启动三个线程,1个用来运行WordSpout,1个线程用来运行WordSplit,1个线程用来运行WordCounter。下面我们通过api设置该topology的并发度
builder.setBolt("splitBolt" , new WordSplit(),2).shuffleGrouping("readSpout" );
我们设置并行度为2的时候,意味着有2个 WordSplit实例,而Storm会分配2个executer来分别运行一个实例,表示有两个WordSplit线程同时执行分词操作,与此同时,我们也可以给WordSpout和WordCount设置并行度。
WordSpout: 在WordCount案例中,简单使用的是一个文本文件,如果我们给WordSpout设置并发度为10,那么就会有10个WordSpout去争抢读取该文本文件,最终导致我们的结果是实际的10倍,类似多线程售卖火车票。这实际上就是线程安全的问题,因为我们的数据源无法保证一行数据只被读取一次。
WordCounter:WordCounter是一个汇总的Bolt,统计个每个单词出现的次数,如果我们将其并发度设置为2甚至更高,最终会导致每个WordCounter实例的统计的只是实际结果的一部分,因此也是不合适的,一般情况下,我们如果我们的Topology中的最后一个Bolt如果是汇总型的,并发度一般都设置默认为1。
3. Storm分组策略
storm里面有6种类型的stream grouping:
(1) Shuffle Grouping: 随机分组, 随机派发stream里面的tuple, 保证每个bolt接收到的tuple数目相同。轮询,平均分配。
(2) Fields Grouping:按字段分组, 比如按userid来分组, 具有同样userid的tuple会被分到相同的Bolts, 而不同的userid则会被分配到不同的Bolts。
(3)All Grouping: 广播发送, 对于每一个tuple, 所有的Bolts都会收到。
(4)Global Grouping: 全局分组, 这个tuple被分配到storm中的一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task。
(5)Non Grouping: 不分组, 这个分组的意思是说stream不关心到底谁会收到它的tuple。目前这种分组和Shuffle grouping是一样的效果,不平均分配。
(6)Direct Grouping: 直接分组, 这是一种比较特别的分组方法,用这种分组意味着消息的发送者举鼎由消息接收者的哪个task处理这个消息。 只有被声明为Direct Stream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。消息处理者可以通过TopologyContext来或者处理它的消息的taskid(OutputCollector.emit方法也会返回taskid)
4. 总结
编程方式配置并行程度
-------------------------
(1) 设置工作进程数
Config.setNumWorkers(2); // 该Topology由两个worker(进程)执行,在分布式中,两个进程均衡的分别在storm集群的各个节点
(2) 设置executor数
TopologyBuiler builder = ... ;
bulder.setSpout(..,3); //设置Spout的执行线程数,表示该Spout由三条线程来执行
bulder.setBolt(..,3); //设置Bolt的执行线程数,表示该Bolt由三条线程来执行
(3)task数
builder.setSpout(..,2).setNumTasks(3); //设置Spout的task数,表示该Spout的两条线程来执行其3个任务,其中一条线程执行两个task,另外一个执行1个task,这说明task在executor内部是串行执行的
builder.setBolt(...,1).setNumTasks(3); //设置Bolt的task数,表示该Bolt的一条线程执行其3个task任务
默认情况下,如果没有指定task数量,每个执行线程执行一个task,并发程度 = spout's task + bolt's task.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号