


hadoop-eclipse环境搭建(二)
Eclipse插件配置
第一步:把我们的"hadoop-eclipse-plugin-1.0.0.jar"放到Eclipse的目录的"plugins"中,然后重新Eclipse即可生效。
上面是我的"hadoop-eclipse-plugin"插件放置的地方。重启Eclipse如下图:
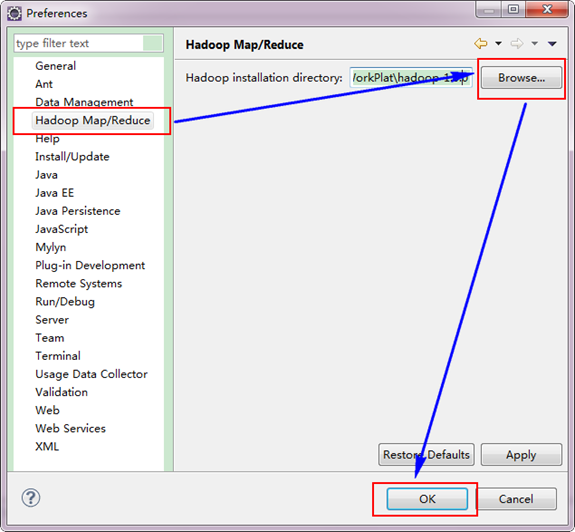
第二步:选择"Window"菜单下的"Preference",然后弹出一个窗体,在窗体的左侧,有一列选项,里面会多出"Hadoop Map/Reduce"选项,点击此选项,选择Hadoop的安装目录(如我的Hadoop目录:E:\HadoopWorkPlat\hadoop-1.0.0)。结果如下图:
第三步:切换"Map/Reduce"工作目录,有两种方法:
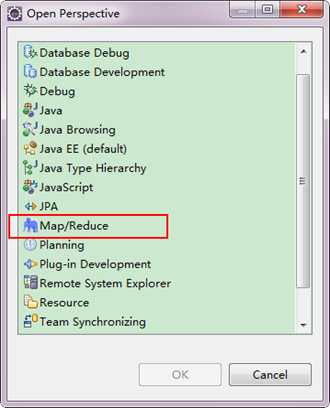
1)选择"Window"菜单下选择"Open Perspective",弹出一个窗体,从中选择"Map/Reduce"选项即可进行切换。
2)在Eclipse软件的右上角,点击图标" "中的"
"中的" ",点击"Other"选项,也可以弹出上图,从中选择"Map/Reduce",然后点击"OK"即可确定。
",点击"Other"选项,也可以弹出上图,从中选择"Map/Reduce",然后点击"OK"即可确定。
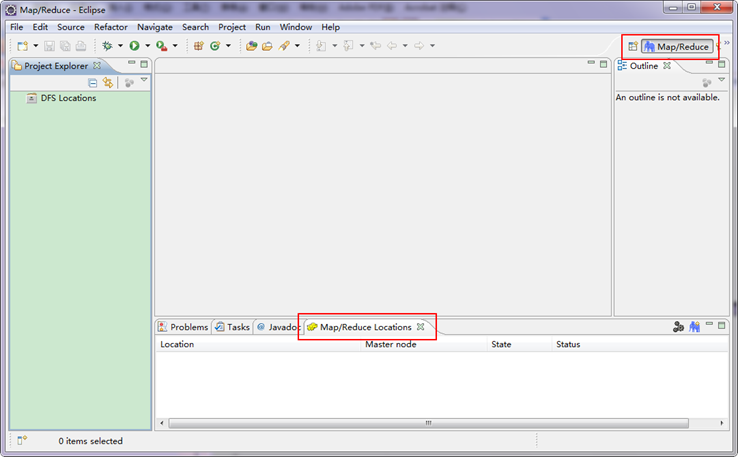
切换到"Map/Reduce"工作目录下的界面如下图所示。
第四步:建立与Hadoop集群的连接,在Eclipse软件下面的"Map/Reduce Locations"进行右击,弹出一个选项,选择"New Hadoop Location",然后弹出一个窗体。

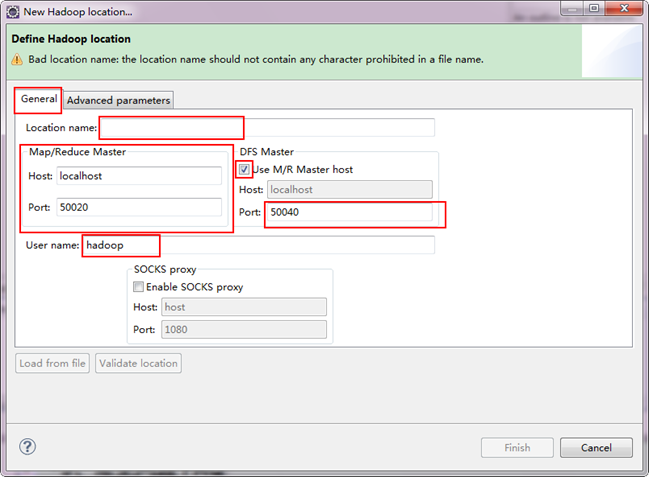
注意上图中的红色标注的地方,是需要我们关注的地方。
-
Location Name:可以任意其,标识一个"Map/Reduce Location"
-
Map/Reduce Master
Host:192.168.1.2(Master.Hadoop的IP地址)
Port:9001
-
DFS Master
Use M/R Master host:前面的勾上。(因为我们的NameNode和JobTracker都在一个机器上。)
Port:9000
-
User name:hadoop(默认为Win系统管理员名字,因为我们之前改了所以这里就变成了hadoop。)
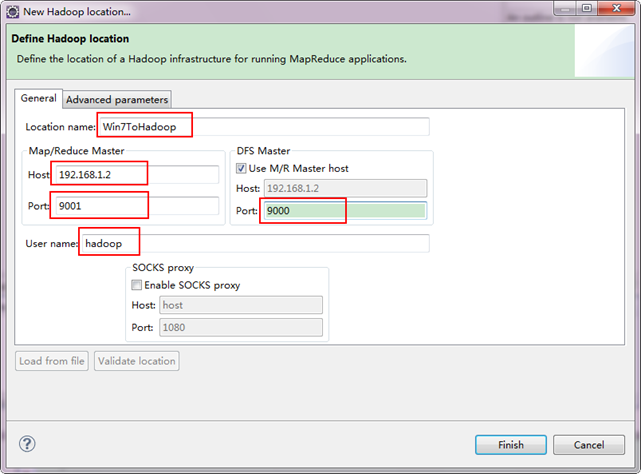
备注:这里面的Host、Port分别为你在mapred-site.xml、core-site.xml中配置的地址及端口。不清楚的可以参考"Hadoop集群_第5期_Hadoop安装配置_V1.0"进行查看。
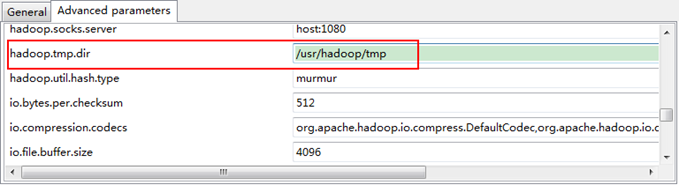
接着点击"Advanced parameters"从中找见"hadoop.tmp.dir",修改成为我们Hadoop集群中设置的地址,我们的Hadoop集群是"/usr/hadoop/tmp",这个参数在"core-site.xml"进行了配置。
点击"finish"之后,会发现Eclipse软件下面的"Map/Reduce Locations"出现一条信息,就是我们刚才建立的"Map/Reduce Location"。

第五步:查看HDFS文件系统,并尝试建立文件夹和上传文件。点击Eclipse软件左侧的"DFS Locations"下面的"Win7ToHadoop",就会展示出HDFS上的文件结构。
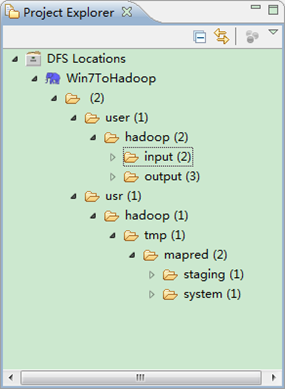
用SecureCRT远程登录"Master.Hadoop"服务器,用下面命令查看是否已经建立一个的文件夹。
hadoop fs -ls
到此为止,我们的Hadoop Eclipse开发环境已经配置完毕,不尽兴的同学可以上传点本地文件到HDFS分布式文件上,可以互相对比意见文件是否已经上传成功。
2、Eclipse上运行WordCount
创建MapReduce项目
从"File"菜单,选择"Other",找到"Map/Reduce Project",然后选择它。
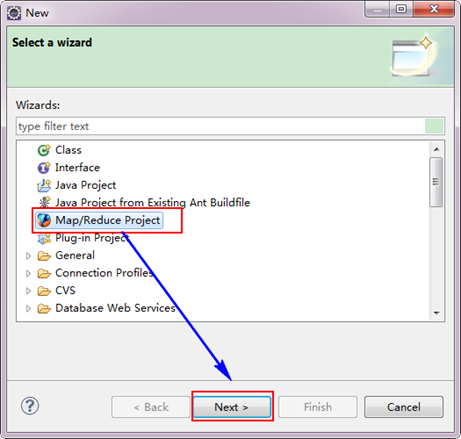
接着,填写MapReduce工程的名字为"WordCountProject",点击"finish"完成。
目前为止我们已经成功创建了MapReduce项目,我们发现在Eclipse软件的左侧多了我们的刚才建立的项目。
建立一个启动类 test包下面的A
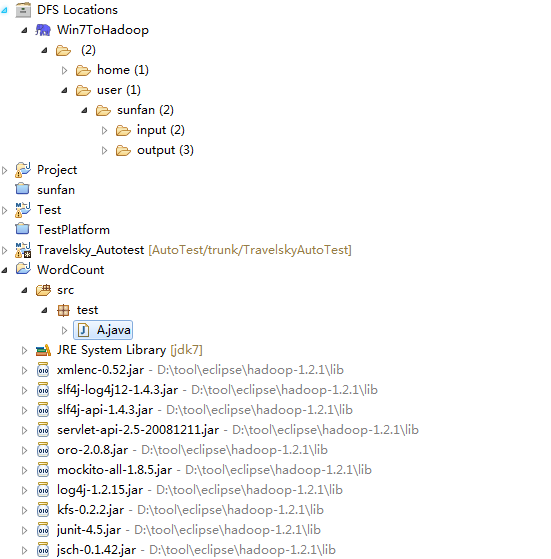
3.4 创建A类
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.examples.WordCount; import org.apache.hadoop.examples.WordCount.IntSumReducer; import org.apache.hadoop.examples.WordCount.TokenizerMapper; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class A { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.set("mapred.job.tracker", "192.168.1.100:9001"); String[] addrs = new String[] { "hdfs://192.168.1.100:9000/user/sunfan/input", "hdfs://192.168.1.100:9000/user/sunfan/out3" }; String[] otherArgs = new GenericOptionsParser(conf, addrs).getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage: wordcount <in> <out>"); System.exit(2); } Job job = new Job(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
运行
15/02/19 17:10:56 INFO input.FileInputFormat: Total input paths to process : 2 15/02/19 17:10:56 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 15/02/19 17:10:56 WARN snappy.LoadSnappy: Snappy native library not loaded 15/02/19 17:10:56 INFO mapred.JobClient: Running job: job_201502181818_0033 15/02/19 17:10:57 INFO mapred.JobClient: map 0% reduce 0% 15/02/19 17:11:00 INFO mapred.JobClient: map 50% reduce 0% 15/02/19 17:11:01 INFO mapred.JobClient: map 100% reduce 0% 15/02/19 17:11:07 INFO mapred.JobClient: map 100% reduce 33% 15/02/19 17:11:09 INFO mapred.JobClient: map 100% reduce 100% 15/02/19 17:11:09 INFO mapred.JobClient: Job complete: job_201502181818_0033 15/02/19 17:11:09 INFO mapred.JobClient: Counters: 29 15/02/19 17:11:09 INFO mapred.JobClient: Job Counters 15/02/19 17:11:09 INFO mapred.JobClient: Launched reduce tasks=1 15/02/19 17:11:09 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=4470 15/02/19 17:11:09 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0 15/02/19 17:11:09 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0 15/02/19 17:11:09 INFO mapred.JobClient: Launched map tasks=2 15/02/19 17:11:09 INFO mapred.JobClient: Data-local map tasks=2 15/02/19 17:11:09 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=8271 15/02/19 17:11:09 INFO mapred.JobClient: File Output Format Counters 15/02/19 17:11:09 INFO mapred.JobClient: Bytes Written=25 15/02/19 17:11:09 INFO mapred.JobClient: FileSystemCounters 15/02/19 17:11:09 INFO mapred.JobClient: FILE_BYTES_READ=55 15/02/19 17:11:09 INFO mapred.JobClient: HDFS_BYTES_READ=261 15/02/19 17:11:09 INFO mapred.JobClient: FILE_BYTES_WRITTEN=176890 15/02/19 17:11:09 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=25 15/02/19 17:11:09 INFO mapred.JobClient: File Input Format Counters 15/02/19 17:11:09 INFO mapred.JobClient: Bytes Read=25 15/02/19 17:11:09 INFO mapred.JobClient: Map-Reduce Framework 15/02/19 17:11:09 INFO mapred.JobClient: Map output materialized bytes=61 15/02/19 17:11:09 INFO mapred.JobClient: Map input records=2 15/02/19 17:11:09 INFO mapred.JobClient: Reduce shuffle bytes=61 15/02/19 17:11:09 INFO mapred.JobClient: Spilled Records=8 15/02/19 17:11:09 INFO mapred.JobClient: Map output bytes=41 15/02/19 17:11:09 INFO mapred.JobClient: CPU time spent (ms)=1110 15/02/19 17:11:09 INFO mapred.JobClient: Total committed heap usage (bytes)=336928768 15/02/19 17:11:09 INFO mapred.JobClient: Combine input records=4 15/02/19 17:11:09 INFO mapred.JobClient: SPLIT_RAW_BYTES=236 15/02/19 17:11:09 INFO mapred.JobClient: Reduce input records=4 15/02/19 17:11:09 INFO mapred.JobClient: Reduce input groups=3 15/02/19 17:11:09 INFO mapred.JobClient: Combine output records=4 15/02/19 17:11:09 INFO mapred.JobClient: Physical memory (bytes) snapshot=337612800 15/02/19 17:11:09 INFO mapred.JobClient: Reduce output records=3 15/02/19 17:11:09 INFO mapred.JobClient: Virtual memory (bytes) snapshot=1139060736 15/02/19 17:11:09 INFO mapred.JobClient: Map output records=4
本文前半部分引用 http://www.cnblogs.com/xia520pi/archive/2012/04/08/2437875.html,感谢原作者。
