ZooKeeper学习第八期——ZooKeeper伸缩性
一、ZooKeeper中Observer
1.1 ZooKeeper角色
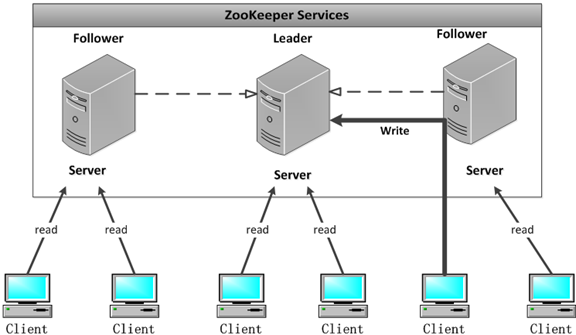
经过前面的介绍,我想大家都已经知道了在ZooKeeper集群当中有两种角色Leader和Follower。Leader可以接受client请求,也接收其他Server转发的写请求,负责更新系统状态。 Follower也可以接收client请求,如果是写请求将转发给Leader来更新系统状态,读请求则由Follower的内存数据库直接响应。 ZooKeeper集群如图1.1所示。
图 1.1 ZooKeeper集群服务
但在ZooKeeper的3.3.3版本以后,ZooKeeper中又添加了一种新角色Observer。Observer的作用同Follower类似,唯一区别就是它不参与选主过程。那么,我们就可以根据该特性将ZK集群中的Server分为两种:
(1) 投票Server:Leader、Follower
(2) 非投票Server:Observer
1.2 为什么引入Observer
(1) ZooKeeper可伸缩性
那么,ZooKeeper为什么要引入Observer这个角色呢?其实在ZooKeeper中引入Observer,主要是为了使ZooKeeper具有更好的可伸缩性。那么,何为可伸缩性?关于伸缩性,对于不同的人意味着不同的事情。 而在这里是说,如果我们的工作负载可以通过给系统分配更多的资源来分担,那么这个系统就是可伸缩的;一个不可伸缩的系统却无法通过增加资源来提升性能,甚至会在工作负载增加时,性能会急剧下降。
在Observer出现以前,ZooKeeper的伸缩性由Follower来实现,我们可以通过添加Follower节点的数量来保证ZooKeeper服务的读性能。但是随着Follower节点数量的增加,ZooKeeper服务的写性能受到了影响。为什么会出现这种情况?在此,我们需要首先了解一下这个"ZK服务"是如何工作的。
(2) ZK服务过程
ZooKeeper服务中的每个Server可服务于多个Client,并且Client可连接到ZK服务中的任一台Server来提交请求。若是读请求,则由每台Server的本地副本数据库直接响应。若是改变Server状态的写请求,需要通过一致性协议来处理,这个协议就是我们前面介绍的Zab协议。
简单来说,Zab协议规定:来自Client的所有写请求,都要转发给ZK服务中唯一的Server—Leader,由Leader根据该请求发起一个Proposal。然后,其他的Server对该Proposal进行Vote。之后,Leader对Vote进行收集,当Vote数量过半时Leader会向所有的Server发送一个通知消息。最后,当Client所连接的Server收到该消息时,会把该操作更新到内存中并对Client的写请求做出回应。该工作流程如下图1.2所示。
图1.2 ZK 写请求工作流程图
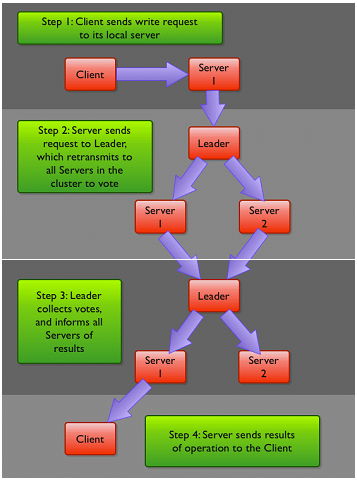
从图中我们可以看出, ZooKeeper 服务器在上述协议中实际扮演了两个职能。它们一方面从客户端接受连接与操作请求,另一方面对操作结果进行投票。这两个职能在 ZooKeeper集群扩展的时候彼此制约。例如,当我们希望增加 ZK服务中Client数量的时候,那么我们就需要增加Server的数量,来支持这么多的客户端。然而,从Zab协议对写请求的处理过程中我们可以发现,增加服务器的数量,则增加了对协议中投票过程的压力。因为Leader节点必须等待集群中过半Server响应投票,于是节点的增加使得部分计算机运行较慢,从而拖慢整个投票过程的可能性也随之提高,写操作也会随之下降。这正是我们在实际操作中看到的问题——随着 ZooKeeper 集群变大,写操作的吞吐量会下降。
(3) ZooKeeper扩展
所以,我们不得不,在增加Client数量的期望和我们希望保持较好吞吐性能的期望间进行权衡。要打破这一耦合关系,我们引入了不参与投票的服务器,称为 Observer。 Observer可以接受客户端的连接,并将写请求转发给Leader节点。但是,Leader节点不会要求 Observer参加投票。相反,Observer不参与投票过程,仅仅在上述第3歩那样,和其他服务节点一起得到投票结果。
图 1.3 Observer 写吞吐量测试
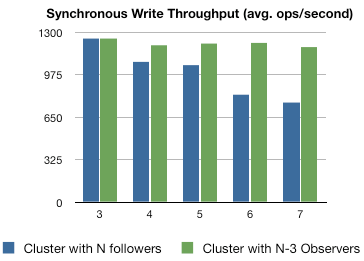
图1.3 显示了一个简单评测的结果。纵轴是,单一客户端能够发出的每秒钟同步写操作的数量。横轴是 ZooKeeper 集群的尺寸。蓝色的是每个服务器都是投票Server的情况,而绿色的则只有三个是投票Server,其它都是 Observer。从图中我们可以看出,我们在扩充 Observer时写性能几乎可以保持不便。但是,如果扩展投票Server的数量,写性能会明显下降,显然 Observers 是有效的。
这个简单的扩展,给 ZooKeeper 的可伸缩性带来了全新的镜像。我们现在可以加入很多 Observer 节点,而无须担心严重影响写吞吐量。但他并非是无懈可击的,因为协议中的通知阶段,仍然与服务器的数量呈线性关系。但是,这里的串行开销非常低。因此,我们可以认为在通知服务器阶段的开销无法成为主要瓶颈。
二、Observer应用
(1) Observer提升读性能的可伸缩性
应对Client的数量增加,是 Observer的一个重要用例,但是实际上它还给集群带来很多其它的好处。Observer作为ZooKeeper的一个优化,Observer服务器可以直接获取Leader的本地数据存储,而无需经过投票过程。但这也面临一定的"时光旅行"风险,也就是说:可能在读到新值之后又读到老值。但这只在服务器故障时才会发生事实上,在这种情况下,Client可以通过"sync"操作来保证下一个值是最新的。
因此,在大量读操作的工作负载下,Observer会使ZooKeeper的性能得到巨大提升。若要增加投票Server数量来承担读操作,那么就会影响ZooKeeper服务的写性能。而且Observer允许我们将读性能和写性能分开,这使ZooKeeper更适用于一些以读为主的应用场景。
(2) Observer提供了广域网能力
Observer还能做更多。Observer对于跨广域网连接的Client来说是很好的候选方案。Observer可作为候选方案,原因有三:
① 为了获得很好的读性能,有必要让客户端离服务器尽量近,这样往返时延不会太高。然而,将 ZooKeeper 集群分散到两个集群是非常不可取的设计,因为良好配置的 ZooKeeper 应该让投票服务器间用低时延连接互连——否则,我们将会遇到上面提到的低反映速度的问题。
② 而Observer 可以被部署在,需要访问 ZooKeeper 的任意数据中心中。这样,投票协议不会受到数据中心间链路的高时延的影响,性能得到提升。投票过程中 Observer 和领导节点间的消息远少于投票服务器和领导节点间的消息。这有助于在远程数据中心高写负载的情况下降低带宽需求。
③ 由于Observer即使失效也不会影响到投票集群,这样如果数据中心间链路发生故障,不会影响到服务本身的可用性。这种故障的发生概率要远高于一个数据中心中机架间的连接的故障概率,所以不依赖于这种链路是个优点。
三、ZooKeeper集群搭建案例
前面介绍了ZooKeeper集群中的几种角色,接下来给大家来介绍一下如何利用这些角色,来搭建一个性能良好的ZooKeeper集群。我以一个项目为例,给大家分析一下该如何规划我们的ZooKeeper集群。
假设我们的项目需要进行跨机房操作,我们的总部机房设在杭州,但他还要同美国,青岛等多个机房之间进行数据交互。但机房之间的网络延迟都比较大,比如中美机房走海底光缆有ping操作200ms的延迟,杭州和青岛机房有70ms的延迟。 为了提升系统的网络性能,我们在部署ZooKeeper网络时会在每个机房部署节点,多个机房之间再组成一个大的网络,来保证整个ZK集群数据一致性。
根据前面的介绍,最后的部署结构就会是:
(总部) 杭州机房 >=3台 :由Leader/Follower构成的投票集群
(分支) 青岛机房 >=1台 :由Observer构成的ZK集群
(分支) 美国机房 >=1台 : 由Observer构成的ZK集群
图 3.1 ZooKeeper集群部署图
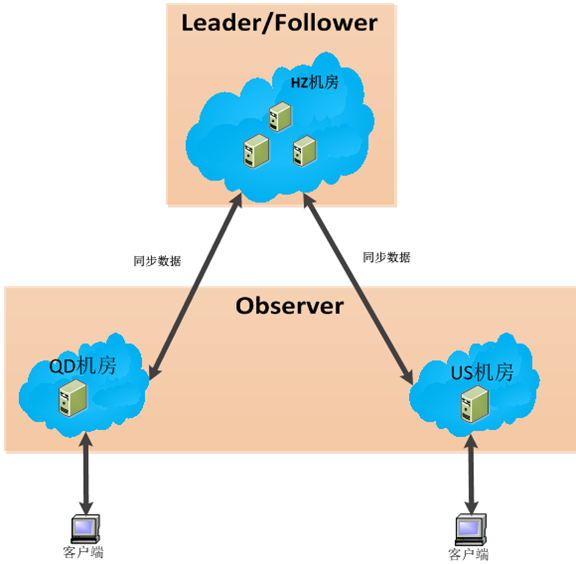
从图中我们可以看出,我们在单个机房内组成一个投票集群,外围的机房都会是一个Observer集群和投票集群进行数据交互。 至于这样部署的一些好处,大家自己根据我前面对ZooKeeper角色的介绍,对比着体会一下,我想这样更能帮助大家理解ZooKeeper。而且针对这样的部署结构,我们会引入一个优先集群问题: 比如在美国机房的Client,需要优先去访问本机房的ZK集群,访问不到才去访问HZ(总部)机房。
如果,您认为阅读这篇博客让您有些收获,不妨点击一下右下角的【推荐】。
如果,您希望更容易地发现我的新博客,不妨点击一下左下角的【关注我】。
如果,您对我的博客所讲述的内容有兴趣,请继续关注我的后续博客,我是【Sunddenly】。本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号