算法数据结构系列-理论篇-字符串匹配(一)
微信公众号:JavaTomStudio
1、字符串匹配:BF 算法
字符串匹配 BF 算法,其中的 BF 字符是对 Brute Force 的缩写,中文叫作暴力匹配算法,也叫朴素匹配算法。在主串中,检查起始位置分别是 0、1、2…n-m 且长度为 m 的 n-m+1 个子串,是否跟模式串匹配。其中,算法最坏情况时间复杂度是 O(n*m) 水平。

如果模式串长度为 m,主串长度为 n,则将主串拆分成 n-m+1 个长度为 m 的子串,只需要暴力地对比这 n-m+1 个子串与模式串,就可以找出主串与模式串匹配的子串。
private static int violenceMatch(char[] s, char[] p) {
int n = s.length, m = p.length;
int i = 0, j = 0;// i的索引指向主串 s, j的索引指向 模式串 p
while (i <= n - m) {
if (s[i] == p[j]) {
j++;
i++;
continue;
}
j = 0;
i = i - j + 1; // 匹配过程中 i 和 j 是对齐的,i-j 得到便是主串初始位置
}
//判断是否匹配成功(结果是按数组0开始计算)
if (j == m) {
return i;
}
return -1;
}
该方法易理解,实现起来不易出错满足 KISS(Keep it Simple and Stupid)设计原则。但是有太多不必要的重复,性能差。在模式串和主串不会太长的情况下,算法的效率一般可以满足实际要求。
2、字符串匹配:RK 算法
字符串匹配 RK 算法,全称叫 Rabin-Karp 算法,它是 BF 算法的升级版。在朴素的字符串匹配算法的基础上引入哈希算法,通过哈希算法对主串中的 n-m+1 个子串分别求哈希值,然后逐个与模式串的哈希值比较大小,来降低 BF 算法的时间复杂度。

整个 RK 算法包含两部分,计算 子串哈希值 和 模式串 哈希值与 子串 哈希值之间的比较。对于 模式串哈希值 与每个 子串哈希值 之间的比较的时间复杂度是 O(1),通过哈希算法计算子串的哈希值的时候,需要遍历子串中的每个字符。
如果设计的
Hash算法存在冲突,则在hash值相同时比较比一下子串和模式串本身,类似于 hashcode 和 equals 方法
为此,需要哈希算法设计的非常有技巧,可以通过设计特殊的哈希算法,只需要扫描一遍主串就能计算出所有子串的哈希值了,所以这部分的时间复杂度是 O(n)。
3、字符串匹配:BM 算法
字符串匹配 BM 算法,全称是 Boyer-Moore 算法,其核心思想是:在模式串中某个字符与主串不能匹配的时候,将模式串往后 多滑动几位,以此来减少不必要的字符比较,提高匹配的效率。

如上图所示,当遇到不匹配的字符时,对于 BF 匹配算法和 RK 匹配算法的做法是,模式串往后滑动一位,然后从模式串的第一个字符开始重新匹配。而优化后的 BM 算法,可以直接跳过不可能匹配成功的元素。
对于 BM 字符串匹配算法来说,其高效的秘诀,就在能够一次性能多滑动几位。为此,在真正进行字符串匹配匹配之前,先进行了一系列预处理操作,遵循:坏字符规则和好后缀规则。
3、字符串匹配:BM 算法-坏字符
按模式串 倒序匹配 过程中,把匹配失败时 主串中 的字符,叫作坏字符。然后在模式串中查找坏字符,若找到匹配字符,则将模式串中的 匹配字符 和 坏字符 对齐,否则直接将模式串滑动到 坏字符之后的一位,再重复进行上述过程。

把坏字符在模式串中的位置记为 si 值,如果 坏字符 在 模式串 中存在,将坏字符在模式串中的下标记作 xi 值,若不存在 xi 记作 -1,移动的位数就等于 si-xi 值。

如果 坏字符 在 模式串 里多处出现,那我们在计算 xi 的时候,选择 最靠后 的那个,因为这样不会让模式串 滑动过多,导致本来可能匹配的情况被滑动略过。
注意:单纯采用坏字符的策略,计算出来的移动位数有可能是负数,因此 BM 算法还需要使用好后缀规则来避免这种情况。因此,在该算法中可以省略坏字符规则,却不能省略好后缀规则。
3、字符串匹配:BM 算法-好后缀
按模式串 倒序匹配 过程中,失配点之后模式串中 匹配成功的那段字符-U ,为好后缀。好后缀规则在于,考虑能否根据 已经匹配成功 的字符,直接推算出下次移动的位置。
理论依据:如果 好后缀-U 在模式串找不到 另一个 匹配子串,只要 U-整体 还参与匹配,就肯定无法匹配,因为已经确定模式串中没有与和 U-整体 相同的字符串。但若 U-的部分后缀 和 模式串的前缀 有 重合 且相等,则有可能会完全匹配。

在 BM 算法中,先考察 整个好后缀-U 在模式串中能否找到了另一个 相匹配的子串-V 。若存在,则将 模式串 滑动到 子串-V 与 主串-U 对齐的位置。
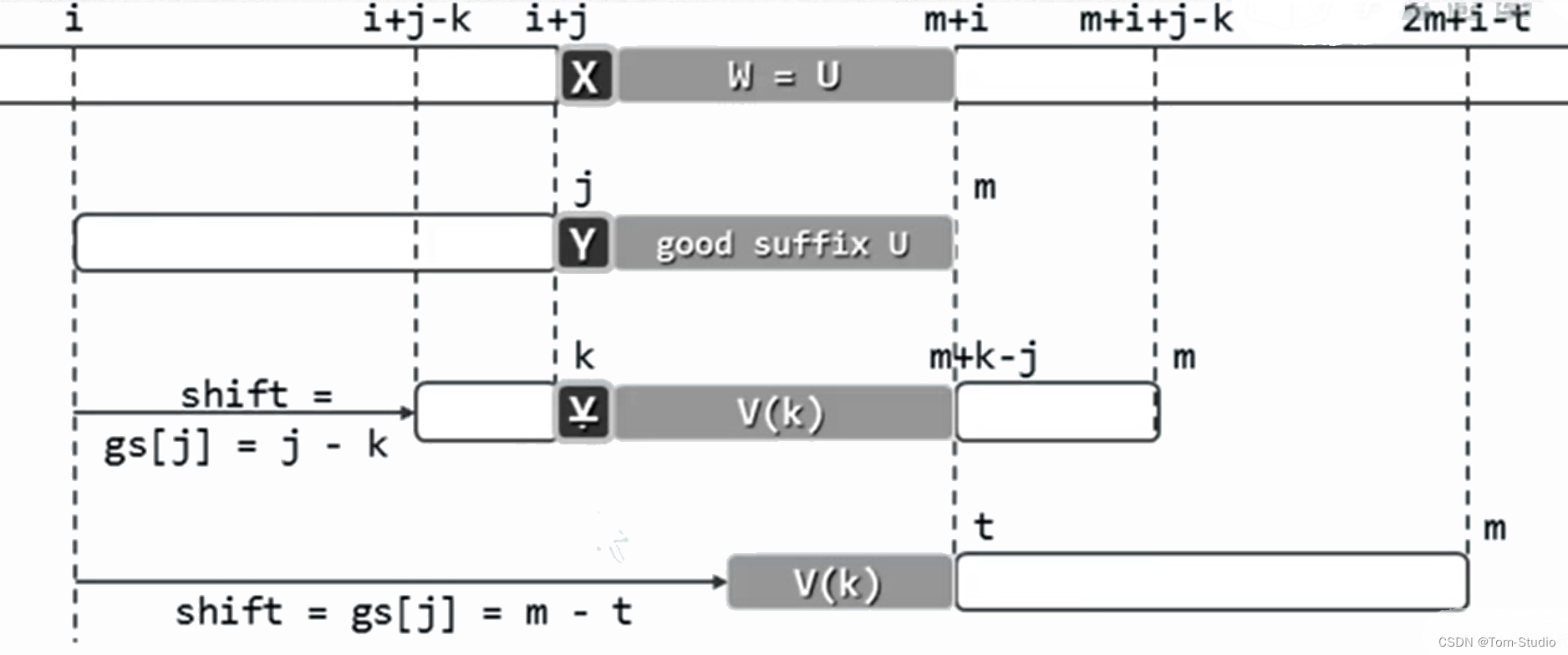
设变量 i 指向 主串 匹配的起始位置,变量 j 和模式串的结束位置 m-1 下标。这里的对齐,主要是靠 i+offset 实现的,而模式串每次都是从 m-1 位置后往前比对
如果不存在,则考察 好后缀的子串 中是否和 模式串的前缀串 匹配,如果匹配则直接让其后缀子串对齐。如果上述两个条件都不满足,则直接跳过整个模式串,将 模式串 滑动到 主串 的 好缀之后 位置。

上图是 只 基于 好后缀规则 的匹配过程,涉及 后缀整体匹配 和 后缀子串和模式串前缀 的匹配。而下图则是 坏字符+好后缀 两种规则的匹配方式,具体选哪种取决于可移动的最大距离。

好后缀规则,主要是看 好后缀本身 以及 好后缀的后缀子串 在 模式串 中能否找得到匹配串,考虑能否将这块信息提前算出来,这样每次匹配失败时,直接移动到正确位置,跳过不可能匹配成功的位置。
①
好后缀是匹配成功的字符,所以其既属于主串也属于模式串
② 由于好后缀本身就是模式串的子串,需要和其匹配的也是模式串,所以预处理部分只依赖模式串即可完成
由于 失配点 是针对 模式串 而言,模式串上 失配点之后 的 那段 字符,就是好后缀。因此,只需枚举出模式串中的所有失配点,即可 提前 算出每个 好后缀 的前后匹配信息,即 整个好后缀的匹配 都可以通过 预处理模式串 来解决。

在 BM 算法的实现上,引入 suffix 数组和 prefix 数组,数组 suffix[i] 的 下标 表示模式串 后缀子串的长度,值 为后缀子串在模式串中 可匹配的子串 的 起始下标。 数组 prefix[i] 表示模式串中长度为 i 后缀子串,是否有可匹配的前缀子串。
public class BoyerMooreStringMatch {
private static final int SIZE = 256; // 全局变量或成员变量
/**
* 根据模式串,生成字符位置查找表,方便查找坏字符的位置
*
* @param b 模式串
* @param bc 模式串对应的,每个字符的位置查找表
*/
private void generateBC(char[] b, int[] bc) {
for (int i = 0; i < SIZE; ++i) {
bc[i] = -1; // 初始化bc
}
for (int i = 0; i < b.length; ++i) {
int ascii = (int) b[i]; // 计算b[i]的ASCII值
bc[ascii] = i;
}
}
/**
* b表示模式串,m表示长度,suffix,prefix数组事先申请好了
* 枚举出的所有失配点位 0,1,2 .. m-2 位置, 如果 i=m-1 为失配点 则不存在好后缀了
* 因为随着i的不断循环,最新的suffix[k]会被覆盖,所以最终算出来一定是最靠后的,进而实现:避免模式串往后滑动得过头的功能
*/
private void generateGS(char[] b, int[] suffix, boolean[] prefix) {
Arrays.fill(suffix, -1);
Arrays.fill(prefix, false);
int m = b.length;
for (int i = 0; i < m - 1; i++){
int j = i;
int k = 0;
while (j >= 0 && b[j] == b[m - k - 1]){ // 前部分 和 后部分,都是从下标由大到小处理
--j;
++k;
suffix[k] = j + 1;
}
if (j == -1){
prefix[k] = true;
}
}
}
/**
* BM 算法:坏字符+好后缀
*
* @param a 主串, 长度为 n
* @param b 模式串,长度为 m
* @return 返回主串与模式串第一个匹配的字符的位置
*/
public int bm(char[] a, char[] b) {
int[] bc = new int[SIZE]; // 记录模式串中每个字符最后出现的位置
generateBC(b, bc); // 构建坏字符哈希表
int n = a.length, m = b.length;
int[] suffix = new int[m];
boolean[] prefix = new boolean[m];
generateGS(b, suffix, prefix);
int i = 0;
while (i <= n - m) { // i 表示主串匹配的起始位置
int j; // j 表示主串与模式串匹配的第一个字符
for (j = m - 1; j >= 0; --j) { // 由于模式串从后往前匹配,主串i要加上一个偏移在与之匹配
if (a[i + j] != b[j]) { // i+j 表示主串可匹配的最大位置,坏字符对应模式串中的下标是j
break;
}
}
if (j < 0) {
return i; // 匹配成功,返回主串与模式串第一个匹配的字符的位置
}
int x = j - bc[(int) a[i + j]]; // 坏字符规则,如果不存在则 x=j-(-1) = j+1, 则 i=i+j+1, 表示主串下次比较的初始位置,直接跳过j前面的字符
int y = 0;
if (j < m - 1) { // 如果有好后缀的话
y = moveByGS(j, m, suffix, prefix);
}
i = i + Math.max(x, y);
}
return -1;
}
// j表示坏字符对应的模式串中的字符下标; m表示模式串长度
private int moveByGS(int j, int m, int[] suffix, boolean[] prefix) {
int k = m - 1 - j; // 好后缀长度:m-1 - 失配位
if (suffix[k] != -1) { // 好后缀匹配串的起始位置
return j - suffix[k] + 1; // j-匹配串的起始 为距离
}
// j+1 以后的是整个好后缀,j+2 以后才是好后缀子串
for (int r = j + 2; r <= m - 1; ++r) {// 如果好后缀在 [0,j-1] 不存在,则要看后缀子串是否存在匹配的前缀子串
if (prefix[m - r]) { // m-1 -r + 1 为后缀长度
return r;// i+r 直接调到后缀子串位置,让主串好后缀子串 和 模式串的前缀对齐
}
}
return m; // 否则返回 m 跳过整个串
}
}
空间复杂度上,数组 bc 和字符集大小有关,而 suffix 和 prefix 数组跟模式串长度 m 有关。时间复杂度上,在 BC 策略最好情况下可以达到 O(n/m) 的时间复杂度,单次匹配成功概率越小,这种性能优势越明显,但最差情况的时间复杂度为O(nm)。
引入了
GS策略的BM算法,其最好情况时间复杂度 O(n/m),最坏情况O(n+m)
在 BM 算法中,好后缀规则 可以 独立于 坏字符规则 使用。因为坏字符规则的实现比较耗内存,为了节省内存,我们可以只用好后缀规则来实现 BM 算法。
4、字符串匹配:KMP 算法
对于 KMP 算法是根据三位作者(D.E.Knuth,J.H.Morris 和 V.R.Pratt)的名字来命名的,算法的全称是 Knuth Morris Pratt 算法,简称为 KMP 算法。

对于 Brute-Force 等传统算法,就是 每次失配 之后只右移一位。改进算法则是希望每次失配之后,移很多位,跳过那些不可能匹配成功的位置。
失配点之前的子串一定是匹配成功的串,该串也叫好前缀;
定义k-前缀为一个字符串的前k个字符;k-后缀为一个字符串的后k个字符;
通过观察可以发现,当 失配点 之前的 好前缀内部 存在:前后缀相同 的情况,即 好前缀 的 前部分 和 后部分 有重叠,则 下次匹配 可以从前面 相同 子串位置之后开始匹配,否则直接 跳过整个好前缀,模式串 从头开始 与主串进行匹配。

在 KMP 算法中,提前构建一个 next 数组,失效函数。用来存储 模式串 中 每个前缀子串 ,其 前后缀 能够可匹配的最大长度。当匹配失败时,通过已知 模版串 中的 失配点 ,推算出 待匹配串 中的 失配字符 应该再与 模版串 的第几个字符再来匹配。

关于 next 数组是对 模式串 而言的,模式串 P 的 next 数组定义为:next[i] 表示在 P[0] ~ P[i] 的子串当中,使得 前 k 个字符 恰等于后 k 个字符 的最大的 k 值。当下标 i 为 模式串 中的失配点,则前 next[i-1] 个字符与后 next[i-1] 个字符一样。

快速构建 next 数组基于 递推 或者 动态规则 来实现,初始 next[0] = 0 值。后续 next[x] 的求值依赖于 next[x-1] 结果,在求解过程中需要根据 P[x] 和 P[next[x-1]+1] 是否相等分情况处理。
前缀串A和后缀串B是相同的,求解
A-K-前缀=B-K-后缀的最大的K,其实就是求串A的最长公共前后缀的长度。
如果相同时,则直接在 next[x-1] 基础上直接扩一位即可。不相同时,则缩减 P[next[x-1]+1] 范围,需要对下标 next[x-1] 需要再次求 next 操作,考察 P[ next[next[x-1]] ] == P[x] 情况,直到 next 返回 0 值。
public class KMPStringMatch {
// b表示模式串,m表示模式串的长度
private static int[] getNexts(char[] b) {
int[] next = new int[b.length];
next[0] = 0;
int k = next[0];
for (int i = 1; i < b.length; ++i) { // 已知 next[0] 求 next[i], i=0,1,2,3,4,5
while (k != 0 && b[k + 1] != b[i]) {
k = next[k];
}
if (b[k + 1] == b[i]) {
++k;
}
next[i] = k;
}
return next;
}
// a, b分别是主串和模式串;n, m分别是主串和模式串的长度。
public static int kmp(char[] a, char[] b) {
int[] next = getNexts(b);
int j = 0;
int n = a.length, m = b.length;
for (int i = 0; i < n; ++i) { // i一直往后加,j可能进行回退,如果匹配失败
while (j > 0 && a[i] != b[j]) { // 一直找到a[i]和b[j]
j = 0 + next[j - 1];
}
if (a[i] == b[j]) {
++j;
}
if (j == m) { // 找到匹配模式串的了
return i - m + 1;
}
}
return -1;
}
}
整个算法分为两个部分:构建 next 数组和字符串匹配。构建 next 过程因为采用的递推的方式,对模式串的遍历没有频繁回溯,所以该阶段的复杂度为 O(M),整体为 O(M+N) 水平。
提示:对于 BM 算法可以达到 O(n/m) 主要原因是,主串下标 i 可以根据 suffix 和 prefix 进行跳跃,而 KMP 则不行,它对于主串的遍历的步张都是 1 值,而 next 数组都是确定 模式串 的下标。
参考文献
介绍 BM 算法的文档:https://www.cs.jhu.edu/~langmea/resources/lecture_notes/boyer_moore.pdf
数据结构-BM算法详解:https://blog.csdn.net/qq_44081639/article/details/120845392
字符串匹配之 BM 算法:https://www.jianshu.com/p/2118dc00d022/
如何更好地理解和掌握 KMP 算法:https://www.zhihu.com/question/21923021


 浙公网安备 33010602011771号
浙公网安备 33010602011771号